
Chapter 4. Build and Deploy Micro-Frontends
In this chapter, we discuss another commonality between micro-frontends and microservices: the importance of a solid automation strategy.
The microservices architecture adds great flexibility and scalability to our architecture, allowing our APIs to scale horizontally based on the traffic our infrastructure receives and allowing us to implement the right pattern for the right job instead of having a common solution applied to all our APIs as in a monolithic architecture.
Despite these great capabilities, microservices increase the complexity of managing the infrastructure, requiring an immense amount of repetitive actions to build and deploy them.
Any company embracing the microservices architecture, therefore, has to invest a considerable amount of time and effort on their continuous integration (CI) or continuous deployment (CD) pipelines (more on these below).
Given how fast a business can drift direction nowadays, improving a CI/CD pipeline is not only a concern at the beginning of a project; it’s a constant incremental improvement throughout the entire project lifecycle.
One of the key characteristics of a solid automation strategy is that it creates confidence in artifacts’ replicability and provides fast feedback loops for developers.
This is also true for micro-frontends.
Having solid automation pipelines will allow our micro-frontends projects to be successful, creating a reliable solution for developers to experiment, build, and deploy.
In fact, for certain projects, micro-frontends could proliferate in such a way that it would become non-trivial to manage them.
One of the key decisions listed in the micro-frontends decision framework, discussed in chapter 3, is the possibility to compose multiple micro-frontends in the same view (horizontal split) or having just one micro-frontend per time (vertical split). With the horizontal split, we could end up with tens, or even hundreds of artifacts to manage in our automation pipelines. Therefore, we have to invest in solutions to manage such scenarios.
Vertical splits also require work, but it’s near to the traditional way to set up automation for single page applications (SPAs). The major difference is you’ll have more than one artifact and potentially different ways to build and optimize your code.
We will deep dive into these challenges in this chapter, starting with the principles behind a solid and fast automation strategy, and how we can improve the developer experience with some simple but powerful tools. Then we’ll analyze best practices for continuous integration and micro-frontends deployment and conclude with an introduction to fitness functions for automating and testing architecture characteristics during different stages of the automation pipelines.
Automation Principles
Working with micro-frontends requires constantly improving the automation pipeline. Skipping this work may hamper the delivery speed of every team working on the project, and decrease their confidence to deploy in production or, worse, frustrate the developers as well as the business when the project fails.
Nailing the automation part is fundamental if you’re going to have a clear idea of how to build a successful continuous integration, continuous delivery, or continuous deployment strategy.
Note
Continuous Integration vs. Continuous Delivery vs. Continuous Deployment
An in-depth discussion about continuous integration, continuous delivery, and continuous deployment is beyond the scope of this book. However, it’s important to understand the differences between these three strategies.
Continuous Integration defines a strategy where an automation pipeline kicks in for every merge into the main branch, extensively testing the codebase before the code is merged in the release branch.
Continuous Delivery is an extension of continuous integration where after the tests, we generate the artifact ready to be deployed with a simple click from a deployment dashboard.
Continuous Deployment goes one step further, deploying in production the artifacts built every code committed in the version of control system.
If you are interested in learning more, I recommend reading Continuous Delivery, available on Safari Books Online.
To get automation speed and reliability right, we need to keep the following principles in mind:
-
Keep the feedback loop as fast as possible.
-
Iterate often to enhance the automation strategy.
-
Empower your teams to make the right decisions for the micro-frontends they are responsible for.
-
Identify some boundaries, also called guardrails, where teams operate and make decisions while maintaining tools standardization.
-
Define a solid testing strategy.
Let’s discuss these principles to get a better understanding of how to leverage them.
Keep a Feedback Loop Fast
One of the key features for a solid automation pipeline is fast execution.
Every automation pipeline provides feedback for developers.Having a quick turnaround on whether our code has broken the codebase is essential for developers for creating confidence in what they have written.
Good automation should run often and provide feedback in a matter of seconds or minutes, at the most. It’s important for developers to receive constant feedback so they will be encouraged to run the tests and checks within the automation pipeline more often.
It’s essential, then, to analyze which steps may be parallelized and which serialized. A technical solution that allows both is ideal.
For example, we may decide to parallelize the unit testing step so we can run our tests in small chunks instead of waiting for hundreds, if not thousands, of tests to pass before moving to the next step.
Yet some steps cannot be parallelized. So we need to understand how we can optimize these steps to be as fast as possible.
Working with micro-frontends, by definition, should simplify optimizing the automation strategy. Because we are dividing an entire application into smaller parts, there is less code to test and build, for instance, and every stage of a CI should be very fast.
However, there is a complexity factor to consider.
Due to maintaining many similar automation pipelines, we should embrace infrastructure as code (IaC) principles for spinning new pipelines without manually creating or modifying several pipelines.
In fact, IaC leverages the concept of automation for configuring and provisioning infrastructure in the same way we do for our code.
In this way, we can reliably create an infrastructure without the risk of forgetting a configuration or misconfiguring part of our infrastructure. Everything is mapped inside configuration files, or code, providing us with a concrete way to generate our automation pipelines when they need to be replicated.
This becomes critical when you work with large teams and especially with distributed teams, because you can release modules and scripts that are reusable between teams.
Iterate Often
An automation pipeline is not a piece of infrastructure that once defined remains as it is until the end of a lifecycle project.
Every automation pipeline has to be reviewed, challenged, and improved.
It’s essential to maintain a very quick automation pipeline to empower our developers to get fast feedback loops.
In order to constantly improve, we need to visualize our pipelines. Screens near the developers’ desks can show how long building artifacts take, making clear to everyone on the team how healthy the pipelines are (or aren’t) and immediately letting everyone know if a job failed or succeeded.
When we notice our pipelines take over 8-10 minutes, it’s time to review them and see if we can optimize certain practices of an automation strategy.
Review the automation strategy regularly: monthly if the pipelines are running slowly and then every 3-4 months once they’re healthy. Don’t stop reviewing your pipelines after defining the automation pipeline. Continue to improve and pursue better performance and a quicker feedback loop; this investment in time and effort will pay off very quickly.
Empower Your Teams
At several companies I worked for, the automation strategy was kept out of capable developers’ hands. Only a few people inside the organization were aware of how the entire automation system worked and even fewer were allowed to change the infrastructure or take steps to generate and deploy an artifact.
This is the worst nightmare of any developer working in an organization with one or more teams.
The developer job shouldn’t be just writing code; it should include a broad range of tasks, including how to set up and change the automation pipeline for the artifacts they are working on, whether it’s a library, a micro-frontend, or the entire application.
Empowering our teams when we are working with micro-frontends is essential because we cannot always rely on all the micro-frontends having the same build pipeline because of the possibility of maintaining multiple stacks at the same time.
Certainly, the deployment phase will be the same for all the micro-frontends in a project. However, the build pipeline may use different tools or different optimizations, and centralizing these decisions could result in a worse final result than one from enabling the developers to work in the automation pipeline.
Ideally, the organization should provide some guardrails for the development team. For instance, the CI/CD tool should be the company’s responsibility but all the scripts and steps to generate an artifact should be owned by the team because they know the best way to produce an optimized artifact with the code they have written.
This doesn’t mean creating silos between a team and the rest of the organization but empowering them for making certain decisions that would result in a better outcome.
Last but not least, encourage a culture of sharing and innovation by creating moments for the teams to share their ideas, proof of concepts, and solutions. This is especially important when you work in a distributed environment. Slack and Microsoft Teams meetings lack everyday, casual work conversations we have around the coffee machine.
Define Your Guardrails
An important principle for empowering teams and having a solid automation strategy is creating some guardrails for the teams, so we can make sure they are heading in the right direction.
Guardrails for the automation strategy are boundaries identified by tech leadership, in collaboration with architects and/or platform or cloud engineers, between which teams can operate and add value for the creation of micro-frontends.
Guardrails for the automation strategy are usually defined by architects and/or Platform or cloud engineers in collaboration with tech leaders.
In this situation, guardrails might include the tools used for running the automation strategy, the dashboard used for deployment in a continuous delivery strategy, or the fitness functions for enforcing architecture characteristics.
Introducing guardrails won’t mean reducing developers’ freedom. Instead, it will guide them toward using the company’s standards, abstracting them as much as we can from their world, and allowing the team to innovate inside these boundaries.
We need to find the right balance when we define these guardrails, and we need to make sure everyone understands the why of them more than the how. Usually creating documentation helps to scale and spread the information across teams and new employees.
As with other parts of the automation strategy, guardrails shouldn’t be static. They need to be revised, improved, or even removed, as the business evolves.
Define Your Test Strategy
Investing time on a solid testing strategy is essential, specifically end-to-end testing, for instance, imagine when we have multiple micro-frontends per view with multiple teams contributing to the final results and we want to ensure our application works end-to-end.
In this case we must also ensure that the transition between views is covered and works properly before deploying our artifacts in production.
While unit and integration testing are important, with micro-frontends there aren’t particular challenges to face. Instead end-to-end testing has to be revised for applying it to this architecture. Because every team owns a part of the application, we need to make sure the critical path of our applications is extensively covered and we achieve our final desired result. End-to-end testing will help ensure those things.
We will dig deeper into this topic later in this chapter, but bear in mind that automating your testing strategy guarantees your independent artifacts deployment won’t result in constant rollbacks or, worse, runtime bugs experienced by your users.
Developers Experience (DX)
A key consideration when working with micro-frontends is the developers experience (DX). While not all companies can support a DX team, even a virtual team across the organization can be helpful. Such a team is responsible for creating tools and improving the experience of working with micro-frontends to prevent frictions in developing new features.
At this stage, it should be clear that every team is responsible for part of the application and not for the entire codebase. Creating a frictionless developer experience will help our developers feel comfortable building, testing, and debugging the part of the application they are responsible for.
We need to guarantee a smooth experience for testing a micro-frontend in isolation, as well inside the overall web application, because there are always touch points between micro-frontends, no matter which architecture we decide to use.
A bonus would be creating an extensible experience that isn’t closed to the possibility of embracing new or different tools during the project lifecycle.
Many companies have created end-to-end solutions that they maintain alongside the projects they are working on, which more than fills the gaps of existing tools when needed. This seems like a great way to create the perfect developer experience for our organization, although businesses aren’t static, nor are tech communities. As a result, we need to account for the cost of maintaining our custom developers’ experience, as well as the cost of onboarding new employees.
It may still be the right decision for your company, depending on its size or the type of the project you are working, but I encourage you to analyze all the options before committing to building an in-house solution to make sure you maximize the investment.
Horizontal vs. Vertical split
The decision between a horizontal and vertical split with your new micro-frontends project will definitely impact the developers’ experience.
A vertical split will represent the micro-frontends as single HTML pages or SPAs owned by a single team, resulting in a developer experience very similar to the traditional development of an SPA. All the tools and workflows available for SPA will suit the developers in this case. You may want to create some additional tools specifically for testing your micro-frontend under certain conditions, as well. For instance, when you have an application shell loading a vertical micro-frontend, you may want to create a script or tool for testing the application shell version available on a specific environment to make sure your micro-frontend works with the latest or a specific version.
The testing phases are very similar to a normal SPA, where we can set unit, integration, and end-to-end testing without particular challenges. Therefore every team can test its own micro-frontends, as well as the transition between micro-frontends, such as when we need to make sure the next micro-frontend is fully loaded. However, we also need to make sure all micro-frontends are reachable and loadable inside the application shell. One solution I’ve seen work very well is having the team that owns the application shell do the end-to-end testing for routing between micro-frontends so they can perform the tests across all the micro-frontends.
Horizontal splits come with a different set of considerations.
When a team owns multiple micro-frontends that are part of one or more views, we need to provide tools for testing a micro-frontend inside the multiple views assembling the page at runtime. These tools need to allow developers to review the overall picture, potential dependencies clash, the communication with micro-frontends developed by other teams, and so on.
These aren’t standard tools, and many companies have had to develop custom tools to solve this challenge. Keep in mind that the right tools will vary, depending on the environment and context we operate in, so what worked in a company may not fit in another one.
Some solutions associated with the framework we decided to use will work, but more often than not we will need to customize some tools to provide our developers with a frictionless experience.
Another challenge with a horizontal split is how to run a solid testing strategy. We will need to identify which team will run the end-to-end testing for every view and how specifically the integration testing will work, given that an action happening in a micro-frontend may trigger a reaction with another.
We do have ways to solve these problems, but the governance behind them may be far from trivial.
The developer experience with micro-frontends is not always straightforward. The horizontal split in particular is challenging because we need to answer far more questions and make sure our tools are constantly up to date to simplify the life of our developers.
Frictionless Micro-Frontends blueprints
The micro-frontend developer experience isn’t only about development tools, of course, we must also consider how the new micro-frontends will be created.
The more micro-frontends we have and the more we have to create, the more speeding up and automating this process will become mandatory.
Creating a command-line tool for scaffolding a micro-frontend will not only cover implementation, allowing a team to have all the dependencies for starting writing code, but also take care of collecting and providing best practices and guardrails inside the company.
For instance, if we are using a specific library for observability or logging, adding the library to the scaffolding can speed up creating a micro-frontend—and it guarantees that your company’s standards will be in place and ready to be used.
Another important thing to provide out of the box would be a sample of the automation strategy, with all the key steps needed for building a micro-frontend. Imagine that we have decided to run static analysis and security testing inside our automation strategy. Providing a sample of how to configure it automatically for every micro-frontend would increase developers’ productivity and help get new employees up to speed faster.
This scaffolding would need to be maintained in collaboration with developers learning the challenges and solutions directly from the trenches. A sample can help communicate new practices and specific changes that arise during the development of new features or projects, further saving your team time and helping them work more efficiently.
Environments strategies
Another important consideration for the DX is enabling teams to work within the company’s environments strategy.
The most commonly used strategy across midsize to large organizations is a combination of testing, staging, and production environments.
The testing environment is often the most unstable of the three because it’s used for quick tries made by the developers. As a result, staging should resemble the production environment as much as possible, the production environment should be accessible only to a subset of people, and the DX team should create strict controls to prevent manual access to this environment, as well as provide a swift solution for promoting or deploying artifacts in production.
An interesting twist to the classic environment strategy is spinning up environments with a subset of a system for testing of any kind (end-to-end or visual regression, for instance) and then tearing them down when an operation finishes.
This particular strategy of on-demand environments is a great addition for the company because it helps not only with micro-frontends but also with microservices for testing in isolation end-to-end flows.
With this approach we can also think about end-to-end testing in isolation of an entire business subdomain, deploying only the microservices needed and having multiple on-demand environments, saving a considerable amount of money.
Another feature provided by on-demand environments is the possibility to preview an experiment or a specific branch containing a feature to the business or a product owner.
Nowadays many cloud providers like AWS can provide great savings using spot instances for a middle-of-the-road approach, where the infrastructure cost is by far cheaper than the normal offering because some machines aren’t available for a long time. Spot instances are a perfect fit for on-demand environments.
Version of Control
When we start to design an automation strategy, deciding a version of control and a branching strategy to adopt is a mandatory step.
Although there are valid alternatives, like Mercurial, Git is the most popular for a version of control system. I’ll use Git as a reference in my examples below, but know that all the approaches are applicable to Mercurial as well.
Working with a version of control means deciding which approach to use in terms of repositories.
Usually, the debate is between monorepo and polyrepo, also called multi-repo. There are benefits and pitfalls in both approaches., You can emply both, though, in your micro-frontend project, so you can use the right technique for your context.
Monorepo

Figure 4-1. 1 Monorepo example where all the projects live inside the same repository
Monorepo (figure 7.1) is based on the concept that all the teams are using the same repository, therefore all the projects are hosted together.
The main advantages of using monorepo are:
-
Code reusability: Sharing libraries becomes very natural with this approach. Because all of a project’s codebase lives in the same repository, we can smoothly create a new project, abstracting some code and making it available for all the projects that can benefit from it.
-
Easy collaboration across teams: Because the discoverability is completely frictionless, teams can contribute across projects. Having all the projects in the same place makes it easy to review a project’s codebase and understand the functionality of another project. This approach facilitates communication with the team responsible for the maintenance in order to improve or simply change the implementation pointing on a specific class or line of code without kicking off an abstract discussion.
-
Cohesive codebase with less technical debt: Working with monorepo encourages every team to be up-to-date with the latest dependencies versions, specifically APIs but generally with the latest solutions developed by other teams, too.
This would mean that our project may be broken and would require some refactoring when there is a breaking change, for instance. Monorepo forces us to continually refactor our codebase, improving the code quality, and reducing our tech debt. -
Simplified dependencies management: With monorepo, all the dependencies used by several projects are centralized, so we don’t need to download them every time for all our projects. And when we want to upgrade to the next major release, all the teams using a specific library will have to work together to update their codebase, reducing the technical debt that in other cases a team may accumulate.
Updating a library may cost a bit of coordination overhead, especially when you work with distributed teams or large organizations. -
Large-scale code refactoring: Monorepo is very useful for large-scale code refactoring. Because all the projects are in the same repository, refactoring them at the same time is trivial. Teams will need to coordinate or work with technical leaders, who have a strong high-level picture of the entire codebase and are responsible for refactoring or coordinating the refactor across multiple projects.
-
Easier onboarding for new hires: With monorepo a new employee can find code samples from other repositories very quickly.
Additionally, a developer can find inspiration from other approaches and quickly shape them inside the codebase.
Despite the undoubted benefits, embracing monorepo also brings some challenges:
-
Constant investment in automation tools: Monorepo requires a constant, critical investment in automation tools, especially for large organizations.
There are plenty of open-source tools available but not all are suitable for monorepo, particularly after some time on the same project, when the monorepo starts to grow exponentially. -
Many large organizations must constantly invest in improving their automation tools for monorepo to avoid their entire workforce being slowed down by intermittent commitment on improving the automation pipelines and reducing the time of this feedback loop for the developers.
-
Scaling tools when the codebase increases: Another important challenge is that automation pipelines must scale alongside the codebase.
Many whitepapers from Google, Facebook and Twitter claim that after a certain threshold, the investment in having a performant automation pipeline increases until the organization has several teams working exclusively on it.
Unsurprisingly, every company aforementioned has built its own version of build tools and released it as open-source, considering the unique challenges they face with thousands of developers working in the same repository. -
Projects are coupled together: Given that all the projects are easy to access and, more often than not, they are sharing libraries and dependencies, we risk having tightly coupled projects that can exist only when they are deployed together. We may, therefore, not be able to share our micro-frontends across multiple projects for different customers where the codebase lives in different monorepo. This is a key consideration to think before embracing the monorepo approach with micro-frontends.
-
Trunk-based development: Trunk-based development is the only option that makes sense with monorepo. This branching strategy is based on the assumption that all the developers commit to the same branch, called a trunk. Considering that all the projects live inside the same repository, the trunk main branch may have thousands of commits per day, so it’s essential to commit often with small commits instead of developing an entire feature per day before merging. This technique should force developers to commit smaller chunks of code, avoiding the “merge hell” of other branching strategies.
-
Although I am a huge fan of trunk-based development, it requires discipline and maturity across the entire organization to achieve good results.
-
Disciplined developers: We must have disciplined developers in order to maintain the codebase in a good state.
When tens, or even hundreds, of developers are working in the same repository, the git history, along with the codebase, could become messy very quickly.
Unfortunately, it’s almost impossible to have senior developers inside all the teams, and that lack of knowledge or discipline could compromise the repository quality and extend the blast radio from one project inside the monorepo to many, if not all, of them.
Using monorepo for micro-frontends is definitely an option, and tools like Lerna help with managing multiple projects inside the same repository. In fact, Lerna can install and hoist, if needed, all the dependencies across packages together and publish a package when a new version is ready to be released. However, we must understand that one of the main monorepo strengths is its code-sharing capability. It requires a significant commitment to maintain the quality of the codebase, and we must be careful to avoid coupling too many of our micro-frontends because we risk losing their nature of independent deployable artifacts.
Git has started to invest in reducing the operations time when a user invokes commands like git history or git status in large repositories. And as monorepo has become more popular, Git has been actively working on delivering additional functionalities for filtering what a user wants to clone into their machine without needing to clone the entire git history and all the projects folders.
Obviously, these enhancements will be beneficial for our CI/CD, as well, where we can overcome one of the main challenges of embracing a monorepo strategy.
We need to remember that using monorepo would mean investing in our tools, evangelizing and building discipline across our teams, and finally accepting a constant investment in improving the codebase. If these characteristics suit your organization, monorepo would likely allow you to successfully support your projects.
Many companies are using monorepo, specifically large organizations like Google and Facebook, where the investment in maintaining this paradigm is totally sustainable.
One of the most famous papers on monorepo was written by Google’s Rachel Potvin and Josh Levenberg. In their concluding paragraph they write:
Polyrepo
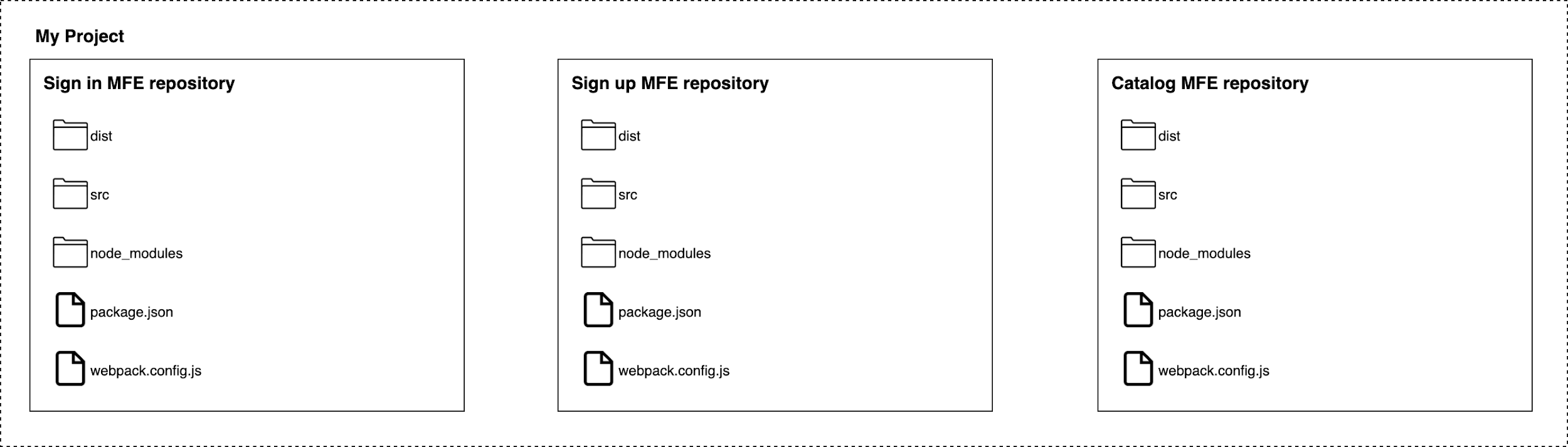
Figure 4-2. 2 Polyrepo example where we split the projects among multiple repositories
The opposite of a monorepo strategy is the polyrepo (figure 7.2), or multi-repo, where every single application lives in its own repository.
Some benefits of a polyrepo strategies are:
-
Different branching strategy per project: With monorepo, we should use trunk-based development, but with a polyrepo strategy we can use the right-branching strategy for the project we are working on.
Imagine, for instance, that we have a legacy project with a different release cadence than other projects that are in continuous deployment. With a polyrepo strategy, we can use git flow in just that project, providing a branching strategy specific for that context. -
No risk of blocking other teams: Another benefit of working with a polyrepo is that the blasting radius of our changes is strictly confined to our project. There isn’t any possibility of breaking other teams’ projects or negatively affecting them because they live in another repository.
-
Encourages thinking about contracts: In a polyrepo environment, the communication across projects has to be defined via APIs. This forces every team to identify the contracts between producers and consumers and to create governance for managing future releases and breaking changes.
-
Fine-grained access control: Large organizations are likely to work with contractors who should see only the repositories they are responsible for or to have a security strategy in place where only certain departments can see and work on a specific area of the codebase.
Polyrepo is the perfect strategy for achieving that fine-grained access control on different codebases, introducing roles, and identifying the level of access needed for every team or department. -
Less upfront and long-term investment in tooling: With a polyrepo strategy we can easily use any tool available out there. Usually, the repositories are not expanding at the same rate as monorepo repositories because fewer developers are committing to the codebase.
That means your investment upfront and in maintaining the build of a polyrepo environment is far less, especially when you automate your CI/CD pipeline using infrastructure as code or command-line scripts that can be reused across different teams.
Polyrepo also has some caveats:
-
Difficulties with project discoverability: By its nature, polyrepo makes it more difficult to discover other projects because every project is hosted in its own repository. Creating a solid naming convention that allows every developer to discover other projects easily can help mitigate this issue.
Unquestionably, however, polyrepo can make it difficult for new employees or for developers who are comparing different approaches to find other projects suitable for their researches. -
Code duplication: Another disadvantage of polyrepo is code duplication. For example, a team creates a library that will be used by other teams for standardizing certain approaches, but the tech department is not aware of that library.
Often, there are libraries that should be used across several micro-frontends, like logging or observability integration, but a polyrepo strategy doesn’t facilitate code-sharing if there isn’t good governance in place. It’s helpful, then, to identify the common aspects that may be beneficial for every team and coordinate the codesharing effort across teams. Architects and tech leaders are in the perfect position to do this, since they work with multiple teams and have a high-level picture of how the system works and what it requires. -
Naming convention: In polyrepo environments, I’ve often seen a proliferation of names without any specific convention; this quickly compounds the issue of tracking what is available and where.
Regulating a naming convention for every repository is critical in a polyrepo system because working with micro-frontends, and maybe with microservice as well, could result in a huge amount of repositories inside our version of control. -
Best practice maintenance: In a monorepo environment, we have just one repository to maintain and control. In a polyrepo environment, it may take a while before every repository is in line with a newly defined best practice.
Again, communication and process may mitigate this problem, but polyrepo requires you think this through upfront because finding out these problems during development will slow down your teams’ throughput.
Polyrepo is definitely a viable option for micro-frontends, though we risk having a proliferation of repositories. This complexity should be handled with clear and strong governance around naming conventions, repository discoverability, and processes.
Micro-frontends projects with a vertical split have far fewer issues using polyrepo than those with a horizontal split, where our application is composed of tens, if not hundreds, of different parts.
In the context of micro-frontends, polyrepo also makes it possible to use different approaches from a legacy project. In fact, we may introduce new tools or libraries just for the micro-frontends approach, while keeping the same one for the legacy project without the need of polluting the best practices in place in the legacy platform.
This flexibility has to be gauged against potential communication overhead and governance that has to be defined inside the organization; therefore if you decide to use polyrepo, be aware of where your initial investment should be: communication flows across teams and governance.
A possible future for a version of control systems
Any of the different paths we can take with a version of control systems won’t be a perfect solution, just the solution that works better in our context. It’s always a tradeoff.
However, we may want to try a hybrid approach, where we can minimize the pitfalls of both approaches and leverage their benefits.
Because micro-frontends and microservices should be designed using domain-driven design, we may follow the subdomain and bounded context divisions for bundling all the projects that are included on a specific subdomain (figure 7.3).
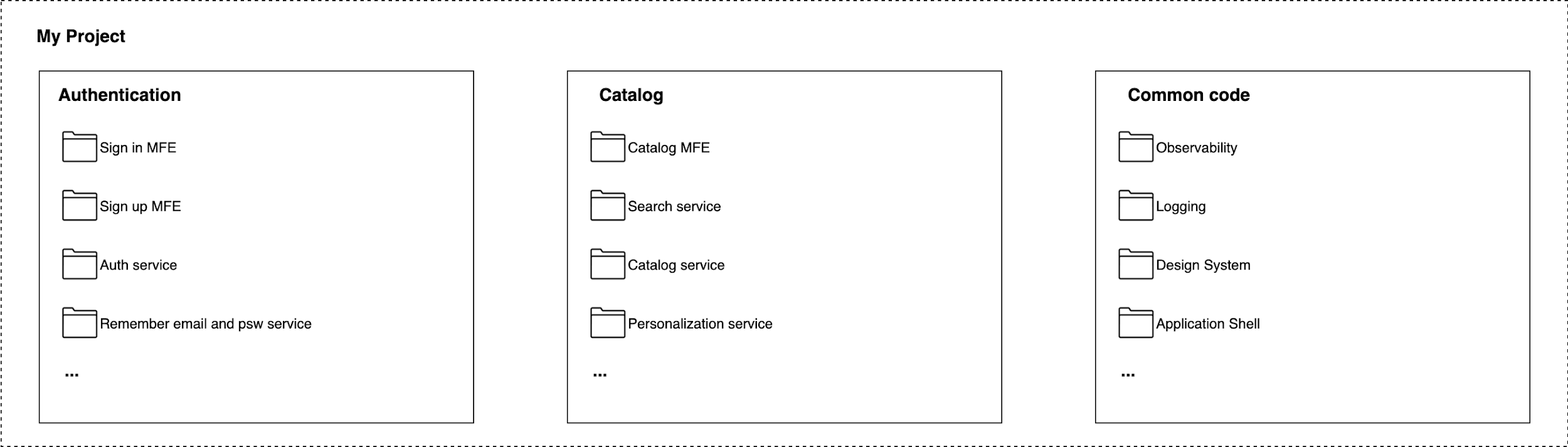
Figure 4-3. 3 A hybrid repositories approach, where we can combine monorepo and polyrepo strengths in a unique solution.
In this way, we can enforce the collaboration across teams responsible for different bounded contexts and work with contracts while benefiting from monorepo’s strengths across all the teams working in the same subdomain.
Thisapproach might result in new practices, new tools to use or build, and new challenges, but it’s an interesting solution worth exploring for micro-architectures.
Continuous Integration strategies
After identifying the version of the control strategy, we have to think about the continuous integration (CI) method.
Different CI implementations in different companies are the most successful and effective when owned by the developer teams rather than by an external guardian of the CI machines.
A lot of things have changed in the past few years. For one thing, developers, including frontend developers, have to become more aware of the infrastructure and tools needed for running their code because, in reality, building the application code in a reliable and quick pipeline is part of their job.
In the past I’ve seen many situations where the CI was delegated to other teams in the company, denying the developers a chance to change anything in the CI pipeline. As a result, the developers treated the automation pipeline as a black box— impossible to change but needed for deploying their artifacts to an environment.
More recently, thanks to the DevOps culture spreading across organizations, these situations are becoming increasingly rare.
Nowadays many companies are giving developers ownership of automation pipelines.
That doesn’t mean developers should be entitled to do whatever they want in the CI, but they definitely should have some skin in the game because how fast the feedback loop is closed depends mainly on them.
The tech leadership team (architects, platform team, DX, tech leaders, engineers managers, and so on) should provide the guidelines and the tools where the teams operate, while also providing certain flexibility inside those defined boundaries.
In a micro-frontends architecture, the CI is even more important because of the number of independent artifacts we need to build and deploy reliably.
The developers, however, are responsible for running the automation strategy for their micro-frontends, using the right tool for the right job.
This approach may seem like overkill considering that every micro-frontend may use a different set of tools. However, we usually end up having a couple of tools that perform similar tasks, and this approach allows also a healthy comparison of tools and approaches, helping teams to develop best practices.
More than once I would be walking the corridors and overhear conversations between engineers about how building tools like Rollup have some features or performances that the Webpack tool didn’t have in certain scenarios and vice versa. This, for me, is a sign of a great confrontation between tools tested in real scenarios rather than in a sandbox.
It’s also important to recognize that there isn’t a unique CI implementation for micro-frontends; a lot depends on the project, company standards, and the architectural approach.
For instance, when implementing micro-frontends with a vertical split, all the stages of a CI pipeline would resemble normal SPA stages.
End-to-end testing may be done before the deployment, if the automation strategy allows the creation of on demand environments, and after the test is completed, the environment can be turned off.
However, a horizontal split would require more thought on the right moment for performing a specific task. When performing end-to-end testing, we’d have to perform this phase in staging or production, otherwise every single pipeline would need to be aware of the entire composition of an application, retrieving every latest version of micro-frontends, and pushing to an ephemeral environment—a solution very hard to maintain and evolve.
Testing Micro-Frontends
Plenty of books discuss the importance of testing our code, catching bugs or defects as early as possible, and the micro-frontends approach is no different.
Working with micro-frontends doesn’t mean changing the way we are dealing with frontend testing practices, but they do create additional complexity in the CI pipeline when we perform end-to-end testing.
Since unit testing and integration testing are the same in terms of the micro-frontends architecture we decide to use for our project, we’ll focus here on end-to-end testing, as this is a bigger challenge in regards to micro-frontends.
End-to-End Testing
End-to-end testing is used to test whether the flow of an application from start to finish is behaving as expected. We perform them to identify system dependencies and ensure that data integrity is maintained between various system components and systems.
End-to-end testing may be performed before deploying our artifacts in production in an on-demand environment created at runtime just before tearing the environment down. Alternatively, when we don’t have this capability in-house, we should perform end-to-end tests in existing environments after the deployment or promotion of a new artifact.
In this case, the recommendation would be embracing testing in production when the application has implemented feature flags allowing to turn on and off a feature and granting the access to test for a set of users for performing the tests.
Testing in production brings its own challenges, especially when a system is integrating with 3rd party APIs.
However, it will save a lot of money on environment infrastructure, maintenance and developers’ resources.
I’m conscious not all the companies or the projects are suitable for this practice, therefore using the environments you have available is the last resort.
When you start a new project or you have the possibility to change an existing one, take in consideration the possibility to introduce features flags not only for reducing the risk of bugs in front of users but also for testing purposes.
Finally, some of the complexity brought in by micro-frontends may be mitigated with some good coordination across teams and solid governance overarching the testing process.
As discussed multiple times in this book, the complexity of end-to-end testing varies depending on whether we embrace a horizontal or vertical split for our application.
Vertical Split End-to-End Testing Challenges
When we work with a vertical split, one team is responsible for an entire business subdomain of the application. In this case, testing all the logic paths inside the subdomain is not far from what you would do in an SPA.
But we have some challenges to overcome when we need test use cases outside of the team’s control, such as the scenario in figure 7.4.
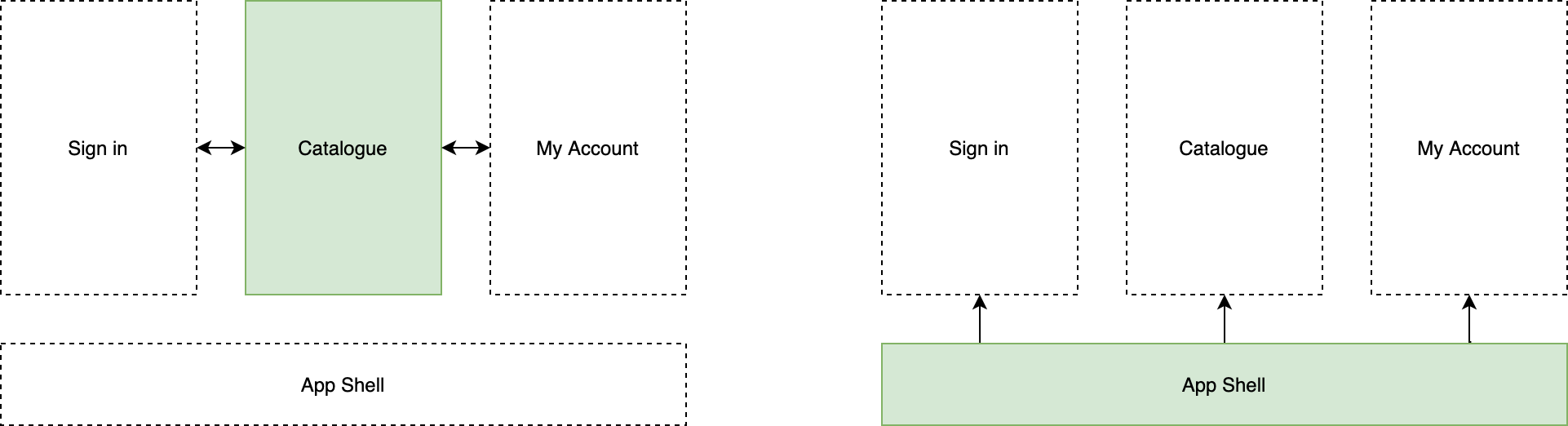
Figure 4-4. 4 - An end-to-end testing example with a vertical split architecture
The catalogue team is responsible for testing all the scenarios related to the catalogue, however, some scenarios involve areas not controlled by the catalogue team, like when the user signs out from the application and should be redirected to the sign-in micro-frontend or when a user wants to change something in their profile and should be redirected to the “my account” micro-frontend.
In these scenarios, the catalogue team will be responsible for writing tests that cross their domain boundary ensuring that the specific micro-frontend the user should be redirected to loads correctly.
In the same way, the teams responsible for the sign-in and “my account” micro-frontend will need to test their business domain and verify that the catalogue correctly loads as the user expects.
Another challenge is making sure our application behaves in cases of deep-linking requests or when we want to test different routing scenarios.
It always depends on how we have designed our routing strategy, but let’s take the example of having the routing logic in the application shell as in figure 7.4.
The application shell team should be responsible for these tests, ensuring that the entire route of the application loads correctly, that the key behaviours like signing in or out of work as expected and that the application shell is capable of loading the right micro-frontend when a user requests a specific URL.
Horizontal Split End-to-End Testing Challenges
Using a horizontal split architecture raises the question of who is responsible for end-to-end testing the final solution.
Technically speaking, what we have discussed for the vertical split architecture still stands, but we have a new level of complexity to manage.
For instance, if a team is responsible for a micro-frontend present in multiple views, is the team responsible for end-to-end testing all the scenarios where their micro-frontends is present?
Let’s try to shed some light on this with the example in figure 7.5.

Figure 4-5. 5 - An end-to-end testing example with a horizontal split architecture.
The payments team is responsible for providing all the micro-frontends needed for performing a payment inside the project. In the horizontal split architecture, their micro-frontends are available on multiple views. In figure 7.5, we can see the payment option micro-frontend that will lead the user to choose a payment method and finalize the payment when they’re ready to check out.
Therefore, the payment team is responsible for making sure the user will be able to pick a payment option and finalize the checkout, showing the interface needed for performing the monetary transaction with the selected payment option in the following view.
In this case, the payment team can perform the end-to-end test for this scenario, but we will need a lot of coordination and governance for analyzing all the end-to-end tests needed and then assigning them to the right teams to avoid duplication of intent, which is even more difficult to maintain in the long run.
The end-to-end tests also become more complex to maintain due to the fact that different teams are contributing to the final output of a view, and some tests may become invalid or broken the moment other teams are changing their micro-frontends.
That doesn’t mean we aren’t capable of doing end-to-end testing with a horizontal split, but it does require better organization and more thought before implementing.
Testing Technical Recommendations
For technically implementing end-to-end tests successfully for horizontal or vertical split architecture, we have three main possibilities.
The first one is running all the end-to-end tests in a stable environment where all the micro-frontends are present. We delay the feedback loop if our new micro-frontend works as expected, end to end.
Another option is using on-demand environments where we pull together all the resources needed for testing our scenarios. This option may become complicated in a large application, however, particularly when we use a horizontal split architecture. This option may also cost us a lot when it’s not properly configured (as described earlier).
Finally, we may decide to use a proxy server that will allow us to end-to-end test the micro-frontend we are responsible for. When we need to use any other part of the application involved in a test, we’ll just load the parts needed from an environment, either staging or production, in this case, the micro-frontends and the application shell not developed by our team.
In this way, we can reduce the risk of unstable versions or optimization for generating an on-demand environment. The team responsible for the end-to-end testing won’t have any external dependency to manage, either, but they will be completely able to test all the scenarios needed for ensuring the quality of their micro-frontend.
When the tool used for running the automation pipeline allows it, you can also set up your CI to run multiple tests in parallel instead of in sequence. This will speed up the results of your tests specifically when you are running many of them at once; it can also be split in parts and grouped in a sensible manner. If we have a thousand unit tests to run, for example, splitting the effort into multiple machines or containers may save us time and get us results faster.
This technique may be applied to other stages of our CI pipeline, as well. With just a little extra configuration by the development team, you can save time testing your code and gain confidence in it sooner.
Even tools that work well for us can be improved, and systems evolve over time. Be sure to analyze your tools and any potential alternatives regularly to ensure you have the best CI tools for your purposes.
Fitness Functions
In a distributed system world where multiple modules make up an entire platform, the architecture team should have a way to measure the impact of their architecture decisions and make sure these decisions are followed by all teams, whether they are co-located or distributed.
In their book Building Evolutionary Architecture, Neal Ford, Rebecca Parson, and Patrick Kua discuss how to test an architecture’s characteristics in CI with fitness functions.
A fitness function:
“provides an objective integrity assessment of some architectural characteristic(s).”
Many of the steps defined inside an automation pipeline are used to assess architecture characteristics such as static analyses in the shape of cyclomatic complexity, or the bundle size in the micro-frontends use case. Having a fitness function that assesses the bundle size of a micro-frontend is a good idea when a key characteristic of your micro-frontends architecture is the size of the data downloaded by users.
The architecture team may decide to introduce fitness functions inside the automation strategy, guaranteeing the agreed-up outcome and trade-off that a micro-frontends application should have.
Some key architecture characteristics I invite you to pay attention to when designing the automation pipeline for a micro-frontends project are:
-
Bundle size: Allocate a budget size per micro-frontend and analyze when this budget is exceeded and why. In the case of shared libraries, also review the size of all the libraries shared, not only the ones built with a micro-frontend.
-
Performance metrics: Tools like lighthouse and webperf allow us to validate whether a new version of our application has the same or higher standards than the current version.
-
Static analysis: There are plenty of tools for static analysis in the JavaScript ecosystem, with SonarQube probably being the most well-known. Implemented inside an automation pipeline, this tool will provide us insights like cyclomatic complexity of a project (in our case a micro-frontend). We may also want to enforce a high code-quality bar when setting a cyclomatic complexity threshold over which we don’t allow the pipeline to finish until the code is refactored.
-
Code coverage: Another example of a fitness function is making sure our codebase is tested extensively. Code coverage provides a percentage of tests run against our project, but bear in mind that this metric doesn’t provide us with the quality of the test, just a snapshot of tests written for public functions.
-
Security: Finally, we want to ensure our code won’t violate any regulation or rules defined by the security or architecture teams.
These are some architecture characteristics that we may want to test in our automation strategy when we work with micro-frontends.
While none of these metrics is likely new to you, in a distributed architecture like this one, they become fundamental for architects and tech leads to understand the quality of the product developed, to understand where the tech debt lays, and to enforce key architecture characteristics without having to chase every team or be part of any feature development.
Introducing and maintaining fitness functions inside the automation strategy will provide several benefits for helping the team provide a fast feedback loop on architecture characteristics and the company to achieve the goals agreed on the product quality.
Micro-frontends specific operations
Some automation pipelines for micro-frontends may require additional steps compared to traditional frontend automation pipelines.
The first one worth a mention would be checking that every micro-frontend is integrating specific libraries flagged as mandatory for every frontend artifact by the architecture team.
Let’s assume that we have developed a design system and we want to enforce that all our artifacts must contain the latest major version.
In the CI pipeline, we should have a step for verifying the package.json file, making sure the design system library contains the right version. If it doesn’t, it should notify the team or even block the build, failing the process.
The same approach may be feasible for other internal libraries we want to make sure are present in every micro-frontend, like analytics and observability.
Considering the modular nature of micro-frontends, this additional step is highly recommended, no matter the architecture style we decide to embrace in this paradigm, for guaranteeing the integrity of our artifacts across the entire organization.
Another interesting approach, mainly available for vertical split architecture, is the possibility of a server-side render at compile time instead of runtime when a user requests the page.
The main reason for doing this is saving computation resources and costs, such as when we have to merge data and user interfaces that don’t change very often.
Another reason is to provide a highly optimized, and fast-loading page with inline CSS and maybe even some JavaScript.
When our micro-frontend artifact results in an SPA with an HTML page as the entry point, we can generate a page skeleton with minimal CSS and HTML nodes inlined to suggest how a page would look, providing immediate feedback to the user while we are loading the rest of the resources needed for interacting with micro-frontend.
This isn’t an extensive list of possibilities an organization may want to evaluate for micro-frontends, because every organization has its own gotchas and requirements. However, these are all valuable approaches that are worth thinking about when we are designing an automation pipeline.
Deployment Strategies
The last stage of any automation strategy is the delivery of the artifacts created during the build phase.
Whether we decide to deploy our code via continuous deployment, shell script running on-prem, in a cloud provider, or via a user interface, understanding how we can deploy micro-frontends independently from each other is fundamental.
By their nature, micro-frontends should be independent. The moment we have to coordinate a deployment with multiple micro-frontends, we should question the decisions we made identifying their boundaries.
Coupling risks jeopardize the entire effort of embracing this architecture, generating more issues than value for the company due to the complicated way of deploying them.
With micro-architectures, we deploy only a small portion of code without impacting the entire codebase. As with micro-frontends and microservices, we may decide to move forward to avoid the possibility of breaking the application and, therefore, the user experience. We’ll present the new version of a micro-frontend to a smaller group of users instead of doing a big-bang release to all our users.
For this scope, the microservices world uses techniques like blue-green deployment and canary releases, where part of the traffic is redirected to a new microservice. Adapting these key techniques in any micro-frontends deployment strategy is worth considering.
Blue-Green Deployment versus Canary Releases
Blue-green deployment starts with the assumption that the last stage of our tests should be done in the production environment we are running for the rest of our platform.
After deploying a new version, we can test our new code in production without redirecting users to the new version while getting all the benefits of testing in the production environment.
When all the tests pass, we are ready to redirect 100% of our traffic to the new version of our micro-frontend.
This strategy reduces the risk of deploying new micro-frontends because we can do all the testing needed without impacting our user base.
Another benefit of this approach is that we may decide to provision only two environments, testing and production; considering that all the tests are running in production with a safe approach, we’re cutting infrastructure costs not having to support the staging environment.
As you can see in figure 7.6, we have a router that should aim for shaping the traffic toward the right version.
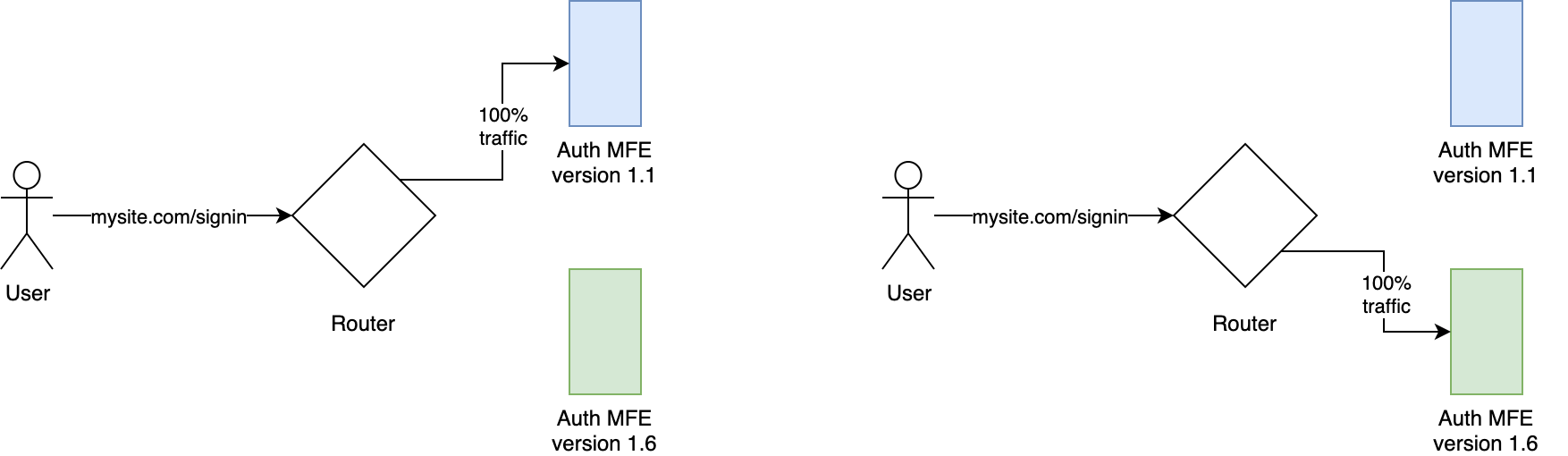
Figure 4-6. 6 Blue-green deployment
In canary releases, we don’t switch all of the traffic to a new version after all tests pass. Instead, we gradually ease the traffic to a new micro-frontend version. As we monitor the metrics from the live traffic consuming our new frontend, such as increased error rates or less user engagement), we may decide to increase or decrease the traffic accordingly (figure 7.7).
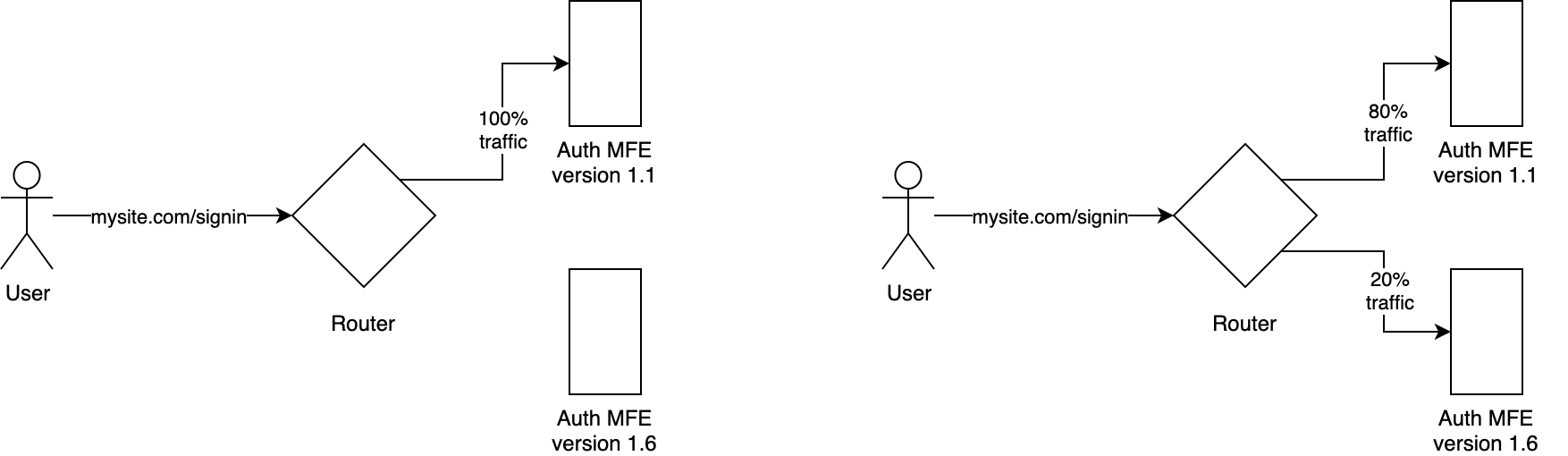
Figure 4-7. 7 Canary release
In both approaches, we need to have a router that shapes the traffic (for a canary release) or switches the traffic from one version to another (blue-green deployment).
The router could be some logic handled on the client side, server side, or edge side, depending on the architecture chosen.
We can summarize the options available in the following table (table 7.1).
| Blue-Green Deployment or Canary Release mechanism | |
| Client-side routing | Application shell Configuration passed via static JSON or backend APIs |
| Edge-side routing | Logic running at the edge (e.g. AWS Lambda@Edge) |
| Server-side routing | Application server logic API Gateway Load Balancer |
Table 7.1 This table shows the router options available for canary releases and blue-green deployments
Let’s explore some scenarios for leveraging these techniques in a micro-frontends architecture.
When we compose our micro-frontends at a client-side level using an application shell, for instance, we may extend the application shell logic, loading a configuration containing the micro-frontends versions available and the percentage of traffic to be presented with a specific version.
For instance, we may want to load a configuration similar to the following example for shaping the traffic, issuing a cookie or storing in web storage the version the user was assigned to and changing it to a different version when we are sure our micro-frontend doesn’t contain critical bugs.
{
"homepage":{
"v.1.1.0": {
"traffic": 20,
"url": "acme.com/mfes/homepage-1_1_0.html"
},
"v.1.2.2": {
"traffic": 80,
"url": "acme.com/mfes/homepage-1_2_2.html"
}
},
"signin":{
"v.4.0.0": {
"traffic": 90,
"url": "acme.com/mfes/signin-4_0_0.html"
},
"v.4.1.5": {
"traffic": 10,
"url": "acme.com/mfes/signin-4_1_5.html"
}
}
...
}
As you can see...
For another project, we may decide that introducing a canary release mechanism inside the application shell logic is not worth the effort, moving this logic to the edge using the lambda@edge, which is only available on AWS cloud.
The interesting part of moving the canary release mechanism to the edge is not only that the decision of which version to serve the user is made to the closest AWS region so latency is reduced but also, architecturally speaking, we are decoupling an infrastructure duty from the codebase of our application shell.
With a horizontal split implementation, where we assemble at runtime different micro-frontends, introducing either blue-green or canary should be performed at the application server level when we compose the page to be served.
We may decide to do it at the client-side level as well. However, as you can imagine, the amount of micro-frontends to handle may matter and mapping all of them may result in a large configuration to be loaded client-side. So we create a system for serving just the configuration needed for a given URL to the client-side.
Other options include releasing different compositions logic and testing them using an API gateway or a load balancer for shaping the traffic toward a server cluster hosting the new implementation and the one hosting the previous version.
In this way, we rely on the infrastructure to handle the logic for canary release or blue-green deployment instead of implementing, and maintaining, logic inside the application server.
As you can see, the concept of the router present in figures 7.6 and 7.7 may be expressed in different ways based on the architecture embraced and the context you are operating in.
Moreover, the context should drive the decision; there may be strong reasons for implementing the canary releases at a different infrastructure layer based on the environment we operate in.
Strangler pattern
Blue-green deployment and canary releases help when we have a micro-frontends architecture deployed in production.
But what if we are scaling an existing web application and introducing micro-frontends?
In this scenario, we have two options: we either wait until the entire application is rewritten with micro-frontends or we can apply the microservices ecosystem’s well-known strangler pattern to our frontend application.
The strangler pattern comes from the idea of generating incremental value for the business and the user by releasing parts of the application instead of waiting for the wholly new application to be ready.
Basically, with micro-frontends, we can tackle an area of the application where we think we may generate value for the business, build with micro-frontends, and deploy them in the production environment living alongside the legacy application.
In this way, we can provide value steadily, while the frequent releases allow you to monitor progress more carefully, drifting toward the right direction for our business and our final implementation.
Using the strangler pattern is very compelling for many businesses, mainly because it allows them to experiment and gather valuable data directly from production without relying solely on projections.
The initial investment for the developers teams is pretty low and can immediately generate benefit for the final user.
Moreover, this approach becomes very useful for the developers for understanding whether the reasoning behind releasing the first micro-frontends was correct or needs to be tweaked, because it forces the team to think about a problem smaller than the entire application and try the approach out end to end, from conception to release, learning along the way which stage they should improve, if any.
As we can see in figure 7.8, when a user requests a page living in the micro-frontends implementation, a router is responsible for serving it. When an area of the application is not yet ready for micro-frontends, the router would redirect the user to the legacy platform.
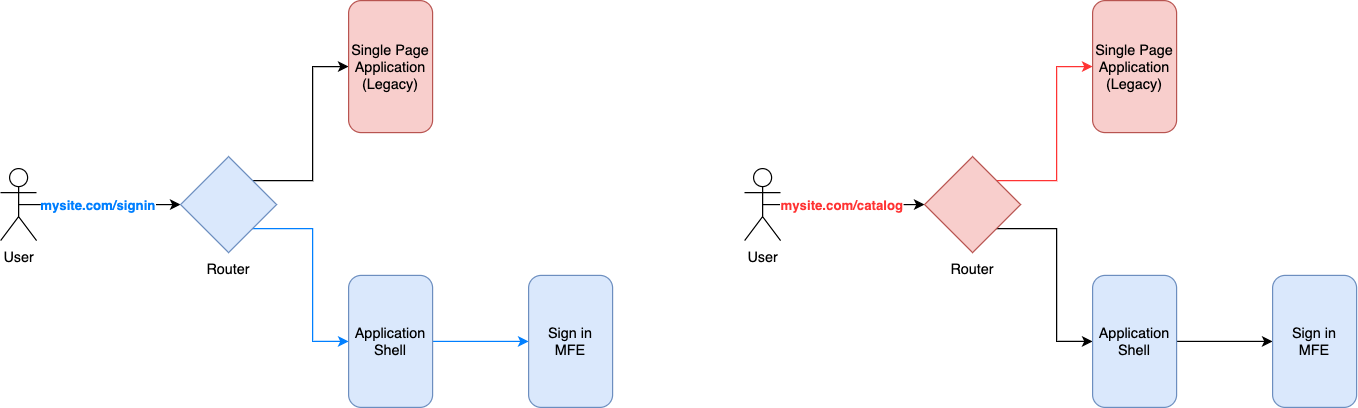
Figure 4-8. 8 A strangler pattern where the micro-frontends live alongside the legacy application so that we can create immediate value for the users and the company instead of waiting for the entire application to be developed.
Every time we develop a new part of the application, it will replace another part of the legacy application until the whole legacy application is completely replaced by the micro-frontends platform.
Implementing the strangler pattern has some challenges, of course. You’ll need to make some changes in the legacy application to make this mechanism work properly, particularly when the micro-frontends application isn’t living alongside the legacy application infrastructure but may live in a different subdomain.
For instance, the legacy application should be aware that the area covered by the micro-frontends implementation shouldn’t be served anymore from its codebase but should redirect the user to an absolute URL so the router logic will kick in again for redirecting the user to the right part of the application.
Another challenge is finding a way to quickly redirect users from micro-frontends to another in case of errors. A technique we used for rolling out our new micro-frontends platform was to maintain three versions of our application for a period of time: the legacy, the legacy modified for co-existing with the micro-frontends (called the hybrid), and the micro-frontends platform. With this approach, we could always serve the hybrid and the micro-frontends platform, and in the extreme case of an issue we weren’t able to fix quickly, we were able to redirect all the traffic to the legacy platform.
This configuration was maintained for several months until we were ready with other micro-frontends. During that time, we were able to improve the platform as expected by the business.
In some situations, this may look like an over-engineered solution, but our context didn’t allow us to have downtime in production, so we had to find a strategy for providing value for our users as well for the company. The strangler pattern let us explore the risks our company was comfortable taking and then, after analyzing them, design the right implementation.
Observability
The last important part to take into consideration in a successful micro-frontends architecture is the observability of our micro-frontends.
Moreover, observability closes the feedback loop when our code runs in a production environment, otherwise we would not beable to react quickly to any incidents happening during prime time.
In the last few years, many observability tools started to appear for the frontend ecosystem such as Sentry or LogRocket, these tools allow us to individuate the user journey before encountering a bug that may or may not prevent the user to complete its action.
Observability it’s not a nice to have feature, nowadays it should be part of any releasing strategy, even more important when we are implementing a micro-frontends architecture.
Every micro-frontend should report errors, custom and generic, for providing visibility when a live issue happens.
In that regard, Sentry or LogRocket can help in this task providing the visibility needed, in fact, these tools are retrieving the user journey, collecting the JavaScript stack trace of an exception, and clustering into groups.
We can configure the alerting of every type of error or warning in these tools dashboard and even plug these tools with alerting systems like pagerduty.
It’s very important to think about observability at a very early stage of the process because it plays a fundamental role in closing the feedback loop for developers especially when we are dealing with multiple micro-frontends composing the same view.
These tools will help us to debug and understand in which part of our codebase the problem is happening and quickly drive a team to the resolution providing some user’s context information like browser used, operating system, user’s country and so on.
All this information in combination with the stack trace provides a clear investigation path for any developer to resolve the problem without spending hours trying to reproduce a bug in the developer’s machine or in a testing environment.
Summary
We’ve covered a lot of ground here, so a recap is in order.
First, we defined the principles we want to achieve with automation pipelines, focusing on fast feedback and constant review based on the evolution of both tech and the company.
Then we talked about the developer experience. If we aren’t able to provide a frictionless experience, developers may try to game the system or use it only when it’s strictly necessary, reducing the benefits they can have with a well-designed CI/CD pipeline.
We next discussed implementing the automation strategy, including all the best practices, such as unit, integration, and end-to-end testing; bundle size checks; fitness functions; and many others that could be implemented in our automation strategy for guiding developers toward the right software quality.
After building our artifact and performing some additional quality reviews, we are ready to deploy our micro-frontends. We talked about testing the final results in production using canary or blue-green deployment to reduce the risk of presenting bugs to the users and releasing as quickly and as often as possible without fear of breaking the entire application.
Finally, we discussed using the strangler pattern when we have an existing application and want to provide immediate value to our business and users. Such a pattern will steadily reduce the functionalities served to the user by a legacy application and increase the one in our micro-frontends platform.