
Chapter 8. Structuring and Refactoring Your Code
Before we move on to the analyzing and visualizing aspects of data wrangling, it’s worth taking a brief “detour” to think about how we can make the most of the work we’ve done so far. In the last few chapters, we’ve explored how to access and parse data from a variety of data formats and sources, how to evaluate its quality in practical terms, and how to clean and augment it for eventual analysis. In the process, our relatively simple programs have evolved and changed, becoming — inevitably — more convoluted and complex.
While commenting our code can do a lot to help keep the logic of our scripts understandable — both to potential collaborators and our future selves — detailed documentation isn’t the only way that we can make our Python programs easy to follow. Just like other written documents, there are many useful ways that we can structure and organize our Python code to make it simpler to use — and even reuse — down the line.
In this chapter, we’re going to go cover the tools and concepts that will allow us to refine our programs so that we can get the most out of them with the least amount of effort. This refining and restructuring is another key way that using Python makes it possible to scale our data wrangling efforts in ways that are all but impossible using other approaches: instead of relying on the functionality that someone else has designed, we can create ones customized to exactly our own preferences and needs.
Revisiting Custom Functions
When we were covering the Python fundamentals way back in Chapter 2, one of the things we touched on was the concept of “custom” or user-defined functions (in this case, we are actually the “user”). In Example 2-1, we saw how a custom function could be used to encapsulate the simple task of printing out a greeting when a particular name was provided, but of course we can create custom functions that are as simple or as complex as we like. Before we dive into the mechanics of writing our own custom functions, however, let’s take a step back and review some of the design considerations that can help us decide when writing a custom function is likely to improve our code. Like all writing, there are few hard and fast rules, but a few heuristics can help you strike the right balance.
Will You Use It More Than Once?
Like variables, one way to identify parts of your code that could use refactoring into custom functions is to look for any particular task that gets done more than once. From validating input to formatting output and everything in between, if your current script includes lots of fiddly conditionals or repetitive steps, that’s the place to start when you’re thinking about designing custom functions. Keep in mind, too, that repeating within a single script isn’t strictly necessary for something to be worth refactoring into a custom function: if you find that there are particular tasks that you’re doing frequently across the scripts that you’re writing (for example, testing to see if a given day is a weekday), you can always pull the custom function into an external script and include it in new ones where you might use it, just as we did with our credentials files in Chapter 5.
Is It Ugly And Confusing?
I’ve put a lot of emphasis in this book on the importance of documenting your work, as a gift to both current collaborators and your future self (by which I mean: good documentation will save your $h!t sometimes). Still, thoroughly commenting your code to include not just the how but the why of your approach, can eventually make it a bit unwieldly to read. Making a piece of code truly comprehensible, then, is a balancing act between being providing enough detail to be comprehensive while being brief enough that your documentation actually gets read.
Folding more of your code into custom functions is a key way to help thread this needle: Like variables, custom functions can (and should!) have descriptive names. This means that just reading the function name can give whoever is looking at your code some essential information about what is happening. At the same time, because the documentation for that function is neatly tucked away in another part of the program, the casual reader can ignore it, while someone seeking more explanation can go elsewhere to find it. This means that the inline comments for our main script can become relatively concise without sacrificing the precision of more complete documentation.
Do You Just Really Hate The Default Functionality?
Ok, so this is maybe not the best reason to write a custom function, but it is a real one. Over time, you may find that there are tasks you need to complete over and over again as part of your data wrangling endeavors, and that there’s something about the existing functions and libraries that just bugs you. Maybe it’s a function name that you find confusin, so that you always have to remind yourself precisely what it’s called. Or maybe there’s a parameter you consistently forget to add that just makes everything more difficult (I’m looking at you, pd.read_csv()!). If you’re working alone or in a small team, it’s perfectly fine to write custom functions that just help make your life easier because — they do. You don’t need a grand rationale. If it will make your life easier, go ahead! That’s the power of being the programmer.
Of course, there are some limits to this. Unless you want to take a much more formal and involved approach to writing Python code, you can’t very effectively do things like define a new function that has the same name as an existing function, or make operators like + or - behave differently1. However, if you just really wish that an existing function you have to use all the time worked a little bit differently, go with it — just make sure you document the heck out of your version!
Understanding Scope
Now that we’ve gone over some of the reasons you might refactor your code with custom functions, it’s time to discuss the mechanics a little bit. Probably the most important concept to understand when you start writing custom functions is scope. Although we haven’t used this term before, scope is something that we’ve actually been working with since we declared our first variables way back in “What’s in a Name?”. In that example, we saw that we could:
-
Create and assign a value to a variable (
author = "Susan E. McGregor") -
Use that variable to pass refer to its contents later (
print(author))
At the same time, we know that if we created a program that simply consisted of the line:
print(author)
We’d get an error, because in the universe of our one-line script, there is no memory-box labeled author. So Python chucks an error at us and declines to go any further.
When we talk about scope in programming, what we’re actually talking about whatever currently exists in the “universe” from the perspective of a particular piece of code. An individual script has a scope that evolves as each line of code is read by the computer, from top to bottom, which is what leads to the (very much expected) behaviors of Example 8-1 and Example 8-2.
Example 8-1. No author variable in scope
# no variable called "author" exists in the "universe" where this line of code does; throw an error(author)
Just as every time we create a new variable a new “box” is created in the computer’s memory, each time we define a new custom function, a new little universe, or scope is created for it as well. This means that when we use custom functions, we are compartmentalizing our code not just visually, but logically and functionally. In other words, we can treat our own custom functions much the way we do the built-in Python methods and library functions that we’ve been using throughout this book: As “recipes” to which we provide “ingredients,” and which returns to us some freshly made Python object in return. The only difference is that with custom functions, we are the chefs!
To get a handle on what this all means in practice, let’s revisit the Example 2-1 example from Chapter 2, but with a couple of tweaks, as shown in Example 8-3.
Example 8-3. greet_me_revisited.py
# create a function that prints out a greeting to any name passed to the functiondefgreet_me(a_name):("Variable `a_name` in `greet_me`: "+a_name)("Hello "+a_name)# create a variable named authorauthor="Susan E. McGregor"# create another variable named editoreditor="Jeff Bleiel"a_name="Python"("Variable `a_name` in main script: "+a_name)# use my custom function, greet_me to output "Hello" messages to each persongreet_me(author)greet_me(editor)("Variable `a_name` in main script again: "+a_name)
This yields the output:
Variable `a_name` in main script: Python Variable `a_name` in `greet_me`: Susan E. McGregor Hello Susan E. McGregor Variable `a_name` in `greet_me`: Jeff Bleiel Hello Jeff Bleiel Variable `a_name` in main script again: Python
Because any custom function automatically gets its own scope, it only “sees” the variables and values that are explicitly passed into it, which are in turn “hidden” from the primary script. This means that when we write custom functions, we don’t need to worry about what variable names have been used in the primary script or vice versa. This reduces the number of unique variable names we need to come up as we write more complex pieces of code, and also means that once we have a custom function working as we expect, reusing its functionality becomes a matter of calling a single function rather than copying and adjusting several (or more!) lines of code.
Defining the Parameters for Function “Ingredients”
We already have a fair amount of experience with providing “ingredients” (also known as arguments) to the methods and functions built in to Python or made available through the many libraries we have used up to this point. As we begin to write custom functions, however, we need to look in more detail and the process of defining the parameters that those functions will accept2.
Unlike some programming languages, Python doesn’t require (or even really allow) you to insist that a function’s parameters have specific data types; if someone wants to pass entirely the wrong types of data into your function, they can absolutely do that. This means that as the function author, you need to decide how much time you want to spend validating the arguments or “ingredients” that have been passed in. In principle, there are three ways we can approach this:
-
Check the data types of all the arguments that have been passed into your function, and complain to the programmer if you find something you don’t like
-
Wrap your code in Python’s
try...exceptblocks so that you can capture certain types of errors without halting the entire program, or just to customize your description of what went wrong -
Not worry about it and let the function user fix any resulting errors using the default Python error messages
While it may seem a bit laissez faire, my primary recommendation at this point is actually to go with option three: don’t worry about it. Not because errors won’t happen (they will — you can revisit “Fast forward” if you want to refresher on what this looks like), but because our primary interest here is wrangling data, not writing enterprise-level Python. As with the scripts we wrote in Chapter 4, we want to strike a balance between what we try to handle programmatically, and what we rely on the programmer to investigate and handle for themselves. Especially since the programs we’re writing can’t really hurt anything if they fail (we might lose time, but they won’t bring down a website or corrupt the only copy of our data), relying on the programmer to check what type of data our functions expect and provide them what they need seems reasonable. Unsurprisingly, of course, I will strongly recommend that you document your functions clearly, which we’ll look at in more detail in “Documenting Your Custom Scripts and Functions with pydoc”.
What Are Your Options?
Even if we’re not trying to write custom functions that are used by thousands of people, we can still make them flexible and fully-featured. One of the simplest ways to do this is to write our functions to solve the most common version of our problem, but allow optional arguments — like those we’ve seen in pandas and other libraries — so that we don’t end up writing multiple functions that only differ slightly in functionality. For example, we could modify our greet_me function so that while “Hello” is the default greeting, that default can be overridden by an optional value passed in by the programmer. This let’s us craft and adapt our own functions so we can use them in many different contexts.
To get a look at how this works in practice, let’s look at a modified version of greet_me in Example 8-4.
Example 8-4. greet_me_options.py
# create a function that prints out a greeting to any namedefgreet_me(a_name,greeting="Hello"):(greeting+" "+a_name)# create a variable named authorauthor="Susan E. McGregor"# create another variable named editoreditor="Jeff Bleiel"# use my custom function, greet_me to output greeting messages to each person# say "Hello" by defaultgreet_me(author)# let the programmer specify "Hi" as the greetinggreet_me(editor,greeting="Hi")
As you can see, adding optional arguments is really as simple as specifying a default value in the function definition; if the programmer passes a different value, it will simply overwrite that default when the function is called.
Getting Into Arguments?
Providing a default value in the function declaration is not the only way to add optional arguments to your custom functions in Python. There are also two generic types of optional arguments: *args and **kwargs.
- *args
-
The *args parameter is useful when you want to be able to pass a list of several values into a function, and giving all of them names and/or default values would be tedious. These values are then accessed by writing a for…in loop to go through them one by one, e.g.
for arg in args. - **kwargs
-
The **kwargs parameter is similar to *args, except that it allows an arbitrary number of keyword arguments to be passed to the function without assigning any of them a default value as we did for
greetingin Example 8-4. Values passed this way can be accessed via thekwargs.get()method, e.g.my_var = kwargs.get("greeting")
If using *args and **kwargs seems like a handy way to (literally) leave your options open when writing custom functions, keeps in mind: it’s always better to write custom functions that address exactly the needs you have, and worry about adapting them (and possibly using one of these parameters, if absolutely necessary) later. Otherwise, you risk spending lots of time writing functionality that you might never need. In the meantime: we have data to wrangle!
Return Values
So far, our variations on a “greet_me” function have been pretty limited in what they accomplish; we’ve really just used them print (lightly) customized messages out to the console. Meanwhile, the functions we’ve used from external libraries are incredibly powerful: they can take a humble csv and transform it into a pandas dataframe, or convert an xls file into something that lets us easily access all kinds of information about the data it contains. While that level of Python programming is beyond the scope of this book, we can still create clean, super-useful custom functions by learning a bit more about function return values.
If parameters/arguments are the “ingredients” in our function “recipes”, then return values are the final dish — the outputs that get consumed by the rest of our program. Really, return values are just pieces of data; they can be literals (like the string “Hello”), or they can be variables. They are useful because they let us hand off to a function whatever it wants and get back whatever we need, without worrying (from the perspective — or scope — of the main program) how the proverbial sausage gets made. If we restructure the basic greet_me function in Example 8-3 to use a return value, it might look something like Example 8-5.
Example 8-5. make_greeting.py
# create a function that **returns** a greeting to any name passed indefmake_greeting(a_name):return("Hello "+a_name)# create a variable named authorauthor="Susan E. McGregor"# create another variable named editoreditor="Jeff Bleiel"# use my custom function, greet_me to create "Hello" messages to each personauthor_greeting=make_greeting(author)editor_greeting=make_greeting(editor)# print the gretting messages that were returned by each function call(author_greeting)(editor_greeting)
At first you might be thinking, “How did that help?” Our main program, of course, got longer. At the same time, it also arguably became a little bit more flexible and easier to understand. Because my make_greeting() function returns the greeting (rather than just printing it directly), I can do more things with it. Sure, I can just print it as we did in Example 8-5, but I can now also store its return value in a variable and do something else with it later. For example, I could add the line:
(editor_greeting+", how are you?")
While that new message might not seem so exciting, it does let me both compartmentalize some work into the function (adding “Hello” to any name), but also do different things with the output (add more text to one, but not the other).
Climbing the “Stack”
Of course, creating a whole new variable just to store a simple greeting (as we do with author_greeting), does seem like a little bit more trouble than it’s worth. And in fact, there’s no rule that says we have to stash the output from a function in a variable before passing it to another function — the first function’s output just becomes the next function’s input. So I could also rewrite Example 8-5 as shown in Example 8-6, and add a new function to add the “, how are you?” text as well.
Example 8-6. make_greeting_no_vars.py
# function that returns a greeting to any name passed indefmake_greeting(a_name):return("Hello "+a_name)# function that adds a question to any greetingdefadd_question(a_greeting):return(a_greeting+", how are you?")# create a variable named authorauthor="Susan E. McGregor"# create another variable named editoreditor="Jeff Bleiel"# print the greeting message(make_greeting(author))# pass the greeting message to the question function and print the result!(add_question(make_greeting(editor)))
While the code print(make_greeting(author)) is fairly easy to interpret, things start to get more complicated with print(add_question(make_greeting(editor))), illustrating that there’s a limit to how much you want to do this kind of function call nesting. As you nest more and more, the code gets increasingly difficult to read, even though the “order of operations” is quite straightforward: the “innermost” function is always executed first, and its return value “bubbles up” to become the input for the next function, whose return value bubbles up to the next function, and so on and so forth. In traditional programming terminology this is known as the function stack, where the innermost function is the “bottom” of the stack and the outermost is the “top”3. An illustration of the function stack for the last line of Example 8-6 is shown in Figure 8-1.
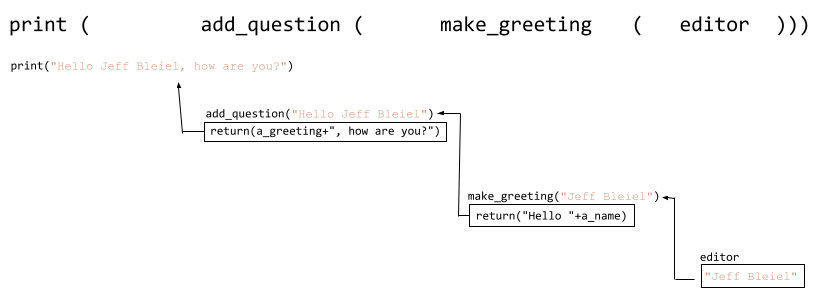
Figure 8-1. A nested function call stack
Refactoring For Fun and Profit
Now that we’ve explored some of the key programming principles associated with refactoring our code to use custom functions, let’s revisit some of the scripts from previous chapters that became a little unweildly as we added functionality, and see what happens when we repackage parts of them into custom functions. As we move through the examples below, keep in mind that choices about what to refactor and how (as with any kind of written document) are partly a matter of preference and style. For that reason, I’ll describe my reasoning below each example, so that you can get a sense of what you might consider as you develop your own refactoring practice.
A Function for Identifying Weekdays
In Example 7-3, we created a small script designed to read in our Citi Bike rides data, and output a new file containing only the rides that took place on a weekday. While there was nothing fundamentally wrong with the approach we used in that example, to me this is a candidate for refactoring for a couple of reasons:
-
The existing script relies on a couple of ugly and not-very-descriptive function calls. The first one is required to convert the available date string into an actual
datetimeformat that Python can evaluate meaningfully:the_date = datetime.strptime(a_row['starttime'], '%Y-%m-%d %H:%M:%S.%f')
While the built-in
weekday()method is reasonably straightforward (although it might be better-nameddayofweek()), we have to compare it to the “magic number” 4 in order to determine if the date we passed in is not a weekend day:if the_date.weekday() <= 4:
-
Checking whether a particular date-like string is a Monday-through-Friday weekday seems like the kind of task that might come up reasonably frequently. If I put this capability into a custom function, it will be easier to reuse in other scripts.
My refactored version of this script can be seen in Example 8-7.
Example 8-7. weekday_rides_refactored.py
# Objectives: Filter all September, 2020 Citi Bike rides, and output a new# file containing only weekday rides# Program Outline:# 1. Read in the data file: 202009-citibike-tripdata.csv# 2. Create a new output file, and write the header row to it.# 3. For each row in the file, make a date from the `starttime`:# a. if it's a weekday, write the row to our output file# 4. Close the output file# import the "csv" libraryimportcsv# import the "datetime" libraryfromdatetimeimportdatetimedefmain():# open our data file in "read" modesource_file=open("202009-citibike-tripdata.csv","r")# open our output file in "write" modeoutput_file=open("202009-citibike-weekday-tripdata.csv","w")# pass our source_file to the DictReader "recipe"# and store the result in a variable called `citibike_reader`citibike_reader=csv.DictReader(source_file)# create a corresponding DictWriter and specify that the fieldnames should# come from `citibike_reader`output_writer=csv.DictWriter(output_file,fieldnames=citibike_reader.fieldnames)# actually write the header row to the output fileoutput_writer.writeheader()# use a `for...in` loop to go through our `citibike_reader` list of rowsfora_rowincitibike_reader:# if the current 'starttime' value is a weekdayifis_weekday(a_row['starttime']):# write that row of data to our output fileoutput_writer.writerow(a_row)# close the output fileoutput_file.close()defis_weekday(date_string,date_format='%Y-%m-%d%H:%M:%S.%f'):# convert the value in the 'date_string' to datetime formatthe_date=datetime.strptime(date_string,date_format)# if `the_date` is a weekday (i.e. its integer value is 0-5)ifthe_date.weekday()<=4:return(True)else:return(False)if__name__=="__main__":main()
As you can see, while the bulk of the code (and even many of the comments) in Example 8-7 are the same as those in Example 7-3, things have been reorganized slightly:
The bulk of our script as now been wrapped into a function called “main().” This is a Python convention, but also serves an important functional purpose: because the computer reads Python top-to-bottom, if we don’t wrap this code in a function, then the computer won’t know what we’re talking about when it reaches
if is_weekday(a_row['starttime']), because it hasn’t gotten to the definition ofis_weekday()yet.
We can partition the finicky work of converting our value to a date string through the
is_weekday()function, while keeping the meaningful bulk of our code towards the top of the file, and making it more readable in the process.
This works because the computer reads both the
main()andis_weekday()functions as usual from top-to-bottom, but doesn’t actually try to execute anything of it until it reaches themain()function call.
What’s the main Frame?
If you’re wondering about the if statement at <3> above, the first thing to know is that is is also a Python convention, and is a programmatic shorthand for telling the computer “if this script is being run directly…”. The principal objective of this protective if statement is to prevent unexpected behaviors if you import one Python script into another4. While useful, I would generally recommend that as you accrue useful functions (as, perhaps our is_weekday() method from Example 8-7 may prove to be), you simply group these thematically and add them to descriptively-named files (e.g. “date_functions.py”), rather than importing scripts with distinct functionality into one another. While the if __name__ == "__main__": statement will help keep things runnning smoothly, as you adapt and refine your commonly-used functions, it will be easier to keep track of them if you keep them all in one (or a few) well-named places.
Metadata Without the Mess
In Example 7-5, we built on code from Example 4-6 and Example 7-4 to create a single script that both handled Microsoft Excel dates correctly and split our source data file into a metadata text file and a structured CSV. While the result was effective, the resulting code was leggy and hard to read, full of hard-to-interpret conditionals and obscure date-formatting function calls.
While we obviously still want to accomplish the same thing, we can clean things up a little bit by handling the formatting of the different types of row content (for the CSV or the TXT file, respectively) in separate functions. This requires rearranging (and clarifying) our logic somewhat, in addition to considering how to get the required information into our custom functions. One approach is ilustrated in Example 8-8.
Example 8-8. xls_meta_and_date_parsing_refactored.py
# Converting data in an .xls file with Python to csv + metadata file, with# functional date values using the "xrld" library.# First, pip install the xlrd library:# https://pypi.org/project/xlrd/2.0.1/# then, import the "xlrd" libraryimportxlrd# import the csv libraryimportcsv# needed to test if a given value is *some* type of numberfromnumbersimportNumber# for parsing/formatting our newly interpreted Excel datesfromdatetimeimportdatetimedefmain():# start by passing our source filename as an ingredient to the xlrd library's# open_workbook "recipe" and store the result in a variable called# `source_workbook`.source_workbook=xlrd.open_workbook("fredgraph.xls")globalthe_datemodethe_datemode=source_workbook.datemode# we'll probably only need one metadata file per workbook, though we could# easily move this inside the loop and create a per-sheet metadata file# if necessarysource_workbook_metadata=open("fredgraph_metadata.txt","w")# even though our example workbook only includes one worksheet, the# `open_workbook` recipe has generated a list of sheet names that we can loop# through. In the future, we could use this to create one `.csv`file per sheetforsheet_nameinsource_workbook.sheet_names():# we'll create a variable that points to the current worksheet by# passing the current value of `sheet_name` to the `sheet_by_name` recipecurrent_sheet=source_workbook.sheet_by_name(sheet_name)# for each sheet in our workbook, we'll create a separate `.csv` file# for clarity, we'll name it "xls_"+sheet_nameoutput_file=open("xls_"+sheet_name+"_dates.csv","w")# there is a "writer" recipe that lets us easily write `.csv`-formatted rowsoutput_writer=csv.writer(output_file)# we'll use a boolean (True/False) "flag" variable so that we know when# to start writing to our "data" file instead of our "metadata" fileis_table_data=False# now, we need to loop through every row in our sheetforrow_num,rowinenumerate(current_sheet.get_rows()):# pulling out the value in the first column of the current rowfirst_entry=current_sheet.row_values(row_num)[0]# if we've hit the header row of our data tableiffirst_entry=='observation_date':# it's time to switch our "flag" value to "True"is_table_data=True# if `is_table_data` is Trueifis_table_data:new_row=create_table_row(current_sheet,row_num)# write this new row to the data output fileoutput_writer.writerow(new_row)# otherwise, this row must be metadataelse:metadata_line=create_meta_text(current_sheet,row_num)source_workbook_metadata.write(metadata_line)# just for good measure, let's close our output filesoutput_file.close()source_workbook_metadata.close()defcreate_table_row(the_sheet,the_row_num):# extract the table-type data values into separate variablesthe_date_num=the_sheet.row_values(the_row_num)[0]U6_value=the_sheet.row_values(the_row_num)[1]new_row=[the_date_num,U6_value]# confirm the the value is a number, then the current row is *not*# the header row, so transform the dateifisinstance(the_date_num,Number):# if it is, use the xlrd library's `xldate_as_datetime` recipe# with the value + the workbook's datemode to generate a# Python datetime objectthe_date_num=xlrd.xldate.xldate_as_datetime(the_date_num,the_datemode)# create a new list containing the_date_num (formatted to MM/DD/YYYY# using the `strftime()` recipe) and the value in the second columnnew_row=[the_date_num.strftime('%m/%d/%Y'),U6_value]return(new_row)defcreate_meta_text(the_sheet,the_row_num):meta_line=""# since we'd like our metadata file to be nicely formatted, we# need to loop through the individual cells of each metadata rowforiteminthe_sheet.row(the_row_num):# write the value of the cell, followed by a tab charactermeta_line=meta_line+item.value+''# at the end of each line of metadata, add a newlinemeta_line=meta_line+''return(meta_line)if__name__=="__main__":main()
Though they should be used sparingly, creating a global variable called
the_datemode, means we don’t have to worry about passing around the entire spreadsheet object just to be able to format our dates correctly.For example, if we didn’t create a global variable, for the date mode, we would have to pass it as another argument to
create_table_row(), which feels a bit incongruous.(Callout text to come.)
If you compare Example 8-8 with Example 8-7, you’ll see they have several key features in common: instead of code that executes automatically, everything in this script has been containerized into functions, with the conventional main() function call protected by a if __name__ == "__main__": conditional. Example 8-8 also shares quite a bit, in terms of code and structure, with the original script in Example 7-5: the includes are all the same, and a large portion of the code — although it has been rearranged somewhat into three functions instead of a single, linear script — is the shared between the two.
Going Global?
In Python, global variables like the one used in Example 8-8 differ from typical variables in two ways:
-
Using the global keyword indicates that this variable can be accessed — and modified — from inside any function in our program.
-
A global variable (like
the_datemode) cannot be declared and assigned a value in the same code statement, the way we do with most variables (e.g.is_table_data = False). Instead, we have to declare it with the global keyword on one line, and assign a value to it on a subsequent line.
While global variables can be quite in certain circumstances (especially in a situation like this, where we’re forced to work with an older data format), they should be used with care. Though you might initially be thinking, “Hey, this global keyword is handy. Why don’t I just make all my variables global?”
In the short term, such an approach may seem appealing, because it helps minimizing how much you have to rewrite your existing code in order to effectively refactor it. At the same time, using lots of global variables basically erases many of the advantanges of refactoring — especially the ability to reuse variable names across functions and scripts. As you complete more and more data wrangling projects, you’ll almost certainly start to develop conventions of your own when it comes to naming variables, which can save you time and effort. As your collection of commonly-used functions grows, you’ll save even more time by reusing them across your scripts. But if in one of those scripts you create a global variable that shares a name with one used by your included function, then you’ll get you errors (if you’re lucky) or just wrong results (worse, really). Whichever way you discover something is wrong (and hopefully it will be you, and not someone reviewing your data, who discovers it), you’re then in for the bug-hunt of your life, because you’ll have to go through your code line-by-line in order to uncover the mix up. In other words, use global variables extremely sparingly — and not at all if you can avoid it!
Given all the reasons not to use global variables, why did I ultimately decide to use one here? First, there is only one possible value for source_workbook.datemode in the entire script, because there is only one datemode attribute per Excel spreadsheet data source. Even if a particular workbook had 20 sheets with 100 columns of data each, there would still only be a single, unchanging value for datemode, which would apply to all of them. In this sense, the value of datemode is conceptually “global”, and so it is reasonable to make the variable that holds this value global as well. And since the value of datemode will never need to be updated within the script, there is less risk of retrieving an unexpected value from it.
As with all writing, however, these choices are partly a matter of taste — and even our own taste can change over time. While at first I liked the symmetry of creating one function to “build” each row of table data and another function to “build” each line of metadata text, there’s also something to be said for breaking that symmetry and avoiding the use of the global datemode variable altogether, as shown in Example 8-9.
Example 8-9. xls_meta_and_date_parsing_refactored_again.py
# Converting data in an .xls file with Python to csv + metadata file, with# functional date values using the "xrld" library.# First, pip install the xlrd library:# https://pypi.org/project/xlrd/2.0.1/# then, import the "xlrd" libraryimportxlrd# import the csv libraryimportcsv# needed to test if a given value is *some* type of numberfromnumbersimportNumber# for parsing/formatting our newly interpreted Excel datesfromdatetimeimportdatetimedefmain():# start by passing our source filename as an ingredient to the xlrd library's# open_workbook "recipe" and store the result in a variable called# `source_workbook`.source_workbook=xlrd.open_workbook("fredgraph.xls")# we'll probably only need one metadata file per workbook, though we could# easily move this inside the loop and create a per-sheet metadata file# if necessarysource_workbook_metadata=open("fredgraph_metadata.txt","w")# even though our example workbook only includes one worksheet, the# `open_workbook` recipe has generated a list of sheet names that we can loop# through. In the future, we could use this to create one `.csv`file per sheetforsheet_nameinsource_workbook.sheet_names():# we'll create a variable that points to the current worksheet by# passing the current value of `sheet_name` to the `sheet_by_name` recipecurrent_sheet=source_workbook.sheet_by_name(sheet_name)# for each sheet in our workbook, we'll create a separate `.csv` file# for clarity, we'll name it "xls_"+sheet_nameoutput_file=open("xls_"+sheet_name+"_dates.csv","w")# there is a "writer" recipe that lets us easily write `.csv`-formatted rowsoutput_writer=csv.writer(output_file)# we'll use a boolean (True/False) "flag" variable so that we know when# to start writing to our "data" file instead of our "metadata" fileis_table_data=False# now, we need to loop through every row in our sheetforrow_num,rowinenumerate(current_sheet.get_rows()):# pulling out the value in the first column of the current rowfirst_entry=current_sheet.row_values(row_num)[0]# if we've hit the header row of our data tableiffirst_entry=='observation_date':# it's time to switch our "flag" value to "True"is_table_data=True# if `is_table_data` is Trueifis_table_data:# extract the table-type data values into separate variablesthe_date_num=current_sheet.row_values(row_num)[0]U6_value=current_sheet.row_values(row_num)[1]# if the value is a number, then the current row is *not*# the header row, so transform the dateifisinstance(the_date_num,Number):the_date_num=format_excel_date(the_date_num,source_workbook.datemode)# write this new row to the data output fileoutput_writer.writerow([the_date_num,U6_value])# otherwise, this row must be metadataelse:metadata_line=create_meta_text(current_sheet,row_num)source_workbook_metadata.write(metadata_line)# just for good measure, let's close our output filesoutput_file.close()source_workbook_metadata.close()defformat_excel_date(a_date_num,the_datemode):a_date_num=xlrd.xldate.xldate_as_datetime(a_date_num,the_datemode)# create a new list containing the_date_num (formatted to MM/DD/YYYY# using the `strftime()` recipe) and the value in the second columnformatted_date=a_date_num.strftime('%m/%d/%Y')return(formatted_date)defcreate_meta_text(the_sheet,the_row_num):meta_line=""# since we'd like our metadata file to be nicely formatted, we# need to loop through the individual cells of each metadata rowforiteminthe_sheet.row(the_row_num):# write the value of the cell, followed by a tab charactermeta_line=meta_line+item.value+''# at the end of each line of metadata, add a newlinemeta_line=meta_line+''return(meta_line)if__name__=="__main__":main()
Which of these is the better solution? As with all writing, it depends on your preferences, your use cases, and your audience. Some groups or institutions will be “opinionated” about the choice to use — or avoid — global variables; some will feel that shorter solutions are preferable, while others will prize structural symmetry, or resuability. While Example 8-9 sacrifices some of the structural symmetry of its predecessor, it generates a function that may be more broadly reusable. The choice of which is more important is, as always, up to you to decide.
Documenting Your Custom Scripts and Functions with pydoc
Up until now, we’ve taken a thorough—but fairly free-form—approach to documenting our code. There’s nothing wrong with this approach, but as your inventory of Python scripts expands, it becomes more useful to be able to review the functionality they contain without individually opening up and reading through the each and every script to find what you’re looking for. If nothing else, having lots of files open makes it that much more likely that a stray keystroke will introduce an error into one of them, which is a really quick way to ruin your day
Fortunately, with just a little bit of formatting, we can adapt our existing program descriptions and comments to work with a commannd-line function called pydoc, which will print out our script and function descriptions to the command line, without our having to open anything at all!
To see this in action, let’s start by refactoring one more script. In this case, we’ll revise Example 7-6 to make it a little bit more concise. In the process, I’ll also update the comments at the top of the script (and add some to our new function), to make them compatible with the pydoc command. You can see what this looks like in Example 8-10.
Example 8-10. fixed_width_strip_parsing_refactored.py
""" NOAA data formatterReads data from an NOAA fixed-width data file with Python and outputs a well-formatted CSV file. The source file for this example comes from the NOAA, and can be accessed here: https://www1.ncdc.noaa.gov/pub/data/ghcn/daily/ghcnd-stations.txt The metadata for the file can be found here: https://www1.ncdc.noaa.gov/pub/data/ghcn/daily/readme.txt Available functions ------------------- * convert_to_columns: Converts a line of text to a list Requirements ------------ * csv module """# we'll start by importing the "csv" libraryimportcsvdefmain():# variable to match our output filename to the input filenamefilename="ghcnd-stations"# we'll just open the file in read format ("r") as usualsource_file=open(filename+".txt","r")# the "readlines()" method converts a text file to a list of linesstations_list=source_file.readlines()# as usual, we'll create an output file to write tooutput_file=open(filename+".csv","w")# and we'll use the `csv` library to create a "writer" that gives us handy# "recipe" functions for creating our new file in csv formatoutput_writer=csv.writer(output_file)# since we don't have column headers within these file we have to "hard code"# these based on the information in the `readme.txt` fileheaders=["ID","LATITUDE","LONGITUDE","ELEVATION","STATE","NAME","GSN_FLAG","HCNCRN_FLAG","WMO_ID"]column_ranges=[(1,11),(13,20),(22,30),(32,37),(39,40),(42,71),(73,75),(77,79),(81,85)]# write our headers to the output fileoutput_writer.writerow(headers)# loop through each line of our fileforlineinstations_list:# send our data to be formattednew_row=convert_to_columns(line,column_ranges)# use the `writerow` function to write new_row to our output fileoutput_writer.writerow(new_row)# just for good measure, let's close the `.csv` file we just createdoutput_file.close()defconvert_to_columns(data_line,column_info,zero_index=False):"""Converts a line of text to a list based on the index pairs provided Parameters ---------- data_line : str The line of text to be parsed column_info : list of tuples Each tuple provides the start and end index of a data column zero_index: boolean, optional If False (default), reduces starting index position by one Returns ------- list a list of data values, stripped of surrounding whitespace """new_row=[]# default value assumes that list of index pairs is *NOT* zero-indexed,# which means that starting index values need to be reduced by 1index_offset=1# if column_info IS zero-indexed, don't offset starting index valuesifzero_index:index_offset=0forindex_pairincolumn_info:start_index=index_pair[0]-index_offsetend_index=index_pair[1]# strip whitespace from around the datanew_row.append((data_line[start_index:end_index]).strip())returnnew_rowif__name__=="__main__":main()
By starting and ending the file description and the
convert_to_columns()function description with a set of three double quotation marks ("""), both of them stand out more from the rest of the comments in the file5. Even more significantly, we can now access the file description from the command line by running the command:pydoc fixed_width_strip_parsing_refactored
Which will display all of the file and function descriptions within the command line interface (use the arrow keys to scroll up and down, or the spacebar to move an entire “page” down at once). To exit the documentation and return to the command-line, just hit the
qkey.Instead of writing a unique line of code to pull each column of data out of a given line of text, I’ve put all the start/end values for each column into a list of Python tuples, which are essentially unchangeable lists.
Now I can pass those values to the
convert_to_columns()function <2>, along with each line of data. Because the start/end index pairs are in a list, we can then use afor...inloop to convert the text to columns. Not only does this make our main script easier to read, in the process we’ve created a function that could actually be used to convert any line of text into columns, as long as we pass in the start/end index pairs in the correct format. I’ve even added a flag value calledzero_index, which let’s us use this function with start/end pairs that consider zero to be the first position (the default value assumes that the first position is “1”).
Note that in addition to viewing the documentation for the whole file, it is possible to use pydoc to view the documentation for a single function (for example, the convert_to_columns() function) by running:
pydoc fixed_width_strip_parsing_refactored.convert_to_columns
And moving through/exiting its documentation in the same way as you did for the entire file.
Navigating Documentation in The Command Line
Generically, you can view the documentation of any Python script (if its description has been properly formatted) using the command:
pydoc __filename_without_.py_extension__
Likewise, you can access the documentation of any function in a script using:
pydoc __filename_without_.py_extension__.__function_name__
And since you can’t use your mouse to get around these files, the following keyboard shortcuts are essential:
- arrow up/arrow down
-
Move one line up/down
- spacebar
-
Move one entire page down
- q
-
Quit/exit documentation
The Case for Command-Line Arguments
Refactoring one long script into a series of functions isn’t the only way we can make our data wrangling code more reusable. For scripts that involve downloading data and/or converting it from PDF images to text, breaking up a single data wrangling process into multiple scripts is another way to save time and effort both now and in the future. That’s partly because we want to minimize how often we do the resource-intensive parts of these processes (like the downloads or the conversion of PDFs to images) even in the short term, and partly because these tasks are usually pretty rote — meaning that with a few additional tricks, we can transform our bespoke data wrangling scripts into standalone code that we can easily reuse over and over again.
As an example, let’s look back at Example 5-9. In this script, the main thing we’re doing is downloading the contents of a webpage — though in this case it happens to be http://web.mta.info/developers/turnstile.html specifically. But is that really so different from what we would be doing if we downloaded the list of Citi Bike monthly operating reports at https://www.citibikenyc.com/system-data/operating-reports? Similarly, the code that downloaded the XML and JSON files in Example 5-1 was almost identical — the only substantive differences were the source URLs and the file names of the local copies. If there was a way that we could refactor these scripts so that the whole thing acted more like a function, that could potentially save us a lot of time and effort.
Fortunately, this is very achievable with standalone Python files, thanks to the built-in argparse Python library, which lets us write our scripts to both require — and use — arguments passed in from the command line. Thanks to argparse, we don’t need to write a new script for every individual webpage we want to download, because it lets us specify both the target URL and the name of our output file right from the command line, as shown in Example 8-11.
Example 8-11. webpage_saver.py
""" Webpage Saver!Downloads the contents of a webpage and it locallyUsage-----python webpage_saver.py target_url filenameParameters----------target_url : strThe full URL of the webpage to be downloadedfilename : strThe desired filename of the local copyRequirements------------* argparse module* requests module"""# include the requests library in order to get data from the webimportrequests# include argparse library to pull arguments from the command lineimportargparseparser=argparse.ArgumentParser()# arguments will be assigned based on the order in which they were providedparser.add_argument("target_url",help="The full URL of the webpage to be downloaded")parser.add_argument("filename",help="The desired filename of the local copy")args=parser.parse_args()# pull the url of the webpage we're downloading from the provided argumentstarget_url=args.target_url# pull the intended output filename from the provided argumentsoutput_filename=args.filename# since we're *not* using an API, the website owner will have no way to identify# us unless we provide some additional information. In this case, we're# describing the browser it should treat our traffic as being from. We're also# providing our name and contact information. This is data that the website# owner will be able to see in their server logs.headers={'User-Agent':'Mozilla/5.0 (X11; CrOS x86_64 13597.66.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.109 Safari/537.36','From':'YOUR NAME HERE - [email protected]'}# because we're just loading a regular webpage, we send a `get` request to the# URL, along with our informational headerswebpage=requests.get(target_url,headers=headers)# opening up a local file to save the contents of the webpage tooutput_file=open(output_filename,"w")# the webpage's code is in the `text` property of the website's response# so write that to our fileoutput_file.write(webpage.text)# close our output file!output_file.close()
Now we have an easy way to download any webpage to our device, without having to write separate scripts for every URL. For example, if we run:
python webpage_saver.py "http://web.mta.info/developers/turnstile.html" "MTA_turnstiles_index.html"
We will get exactly the same result as in Example 5-9, but we can also run:
python webpage_saver.py "https://www.citibikenyc.com/system-data/operating-reports" "citibike_operating_reports.html"
To get the Citi Bike operating reports, without having to even open, much less modify our script. Handy, no?
Tip
Using command line arguments with your task-specific scripts can save you time — but not it if you end up meticulously copying complex URLs, for example, into your command line interface by hand. To make things simpler, here’s a quick overview of how to copy/paste to the command line, depending on your operating system:
- Linux (including Chromebook)
-
Highlight the URL/text you want to copy, then context-click and select “Copy.” In your command-line window, just click and it will automatically paste.
- Windows/Mac
-
Highlight the URL/text you want to copy, then context-click and select “Copy.” In your command-line window, context-click again and select “Paste.”
Where Scripts and Notebooks Diverge
By now you may have noticed that in the preceding sections, I didn’t describe a way to get arguments from the command line into a Jupyter notebook, nor have I talked much about generating and interacting with script and function documentation for Jupyter notebooks, either. This is not because these things are impossible, but because Jupyter notebooks are designed to let you interact with Python differently than standalone scripts, and so some of these concepts are less applicable to those. As someone who started working with Python before Jupyter (formerly IPython) notebooks existed, my bias is still toward standalone scripts for the majority of my rubber-to-the-road Python data wrangling. While notebooks are (generally) great for testing and tweaking chunks of code, I almost always end up migrating back to standalone scripts once I’ve identified the approach that works for a particular data wrangling task. This is mostly because as I move further along in a project, I often get impatient even with the process of opening a modifying a script unless I have to — which is part of the reason that I favor using command-line arguments and standalone scripts for common, straightforward tasks.
As we’ll soon see, however, the interactivity of Jupyter notebooks makes them generally far superior to standalone Python scripts when it comes to experimenting with — and especially sharing — data analysis and visualization. As a result, we’ll look more closely at how to use Jupyter notebooks in particular as we turn to the basics of data analysis in [Link to Come]
Conclusion
In this chapter, we’ve taken a bit of a break from direct data wrangling to revisit some of our prior work whose code had gotten unweildly. Through the process of refactoring, we explored how we can reorganize code that works into code that works well — and in the process becomes more readable and reusable. As our data wrangling projects evolve, this lets us build up our own collection of custom functions that we can turn to for solving the kinds of problems — from formatting to data access — that we, personally, deal with frequently. Similarly, by applying a bit more structure to our documentation, we made it accessible — and useful — right from the command line, so that we can find what we’re looking for without opening a single script. And in a similar vein, we applied that refactoring logic to our scripts themselves, so that we can customize their functionality without having to open them up, either!
In the next chapter, we’ll return to our focus on data with a brief tour of basic data analysis techniques, followed by an overview of the visualization approaches that will help you better understand and present your data to the world!
1 Doing these things is definitely possible, but is well beyond the scope of most data wrangling activities, and therefore, this book.
2 Technically, parameters describe the variable names assigned in the function definition, while arguments are the actual values that are passed to the function when it is called. In practice, though, these terms are often used interchangeably.
3 This term is also why the forum is called StackExchange.
4 You can find an helpful description/demonstration of the reasoning behind this convention here: https://www.freecodecamp.org/news/if-name-main-python-example/
5 The actual structure/formatting I’ve used here a mashup of different styles derived from this guide: https://realpython.com/documenting-python-code/#documenting-your-python-code-base-using-docstrings. While using a standard approach may matter if you are working with a large team, if you are working alone or in a small group, find a style that works for you!