
Chapter 3. The Dark Side of Distributed Systems
Now that you have a better understanding of Reactive and had a brief overview of Quarkus, let’s focus on why you would want to use them and, more specifically, build reactive systems. The reason emanates from the Cloud and, more generally, the need to build better distributed systems.
The Cloud has been a game-changer. It’s making the construction of distributed systems easier. You can create virtual resources on the fly and use off-the-shelf services. However, easier does not mean straightforward. Building such systems is a considerable challenge. Why? Because the Cloud is a distributed system, and distributed systems are complicated. We need to understand what kind of animal we are trying to tame.
What’s a Distributed System?
There are many definitions of distributed systems. But, let’s start with a loose one and see what we can learn from it:
A distributed system is a collection of independent computers that appears to its users as a single coherent system.Andrew Tanenbaum
This definition highlights two important aspects of distributed systems:
-
a distributed system is composed of independent machines that are autonomous. They can be started and stopped at any time. These machines operate concurrently and can fail independently without affecting the whole system’s uptime (in theory, at least);
-
consumers (users) should not be aware of the system’s structure. It should provide a consistent experience. Typically, you may use an HTTP service, which is served by an API gateway (Figure 3-1) delegating requests to various machines. For you, the caller, it behaves as a single coherent system, you have a single entry point, and you ignore the underlying structure of the system.

Figure 3-1. Example of an HTTP service delegating calls to other machines/services
To achieve this level of coherence, the different autonomous machines must collaborate one way or another. This collaboration and the need for good communications that arise from it are the heart of distributed systems, but also its primary challenge.
But that definition does not explain why we are building distributed systems. Initially, distributed systems were workarounds. The resources of each machine were too limited. Connecting multiple machines was a smart way to extend the whole system’s capacity, making resources available to the other members of the network. Today, the motivations are slightly different. Using a set of distributed machines gives us more business agility, eases evolution, reduces the time to market, and from an operational standpoint, allows us to scale more quickly, improves resilience via replication, and so on. Distributed systems morphed from being a workaround to be the norm. Why? We can’t build a single machine powerful enough to handle all the needs of a major corporation, while also being affordable. If we could, we’d all use the giant machine and deploy independent applications on it. But, this necessity for distribution draw new operational and business boundaries based on physical system boundaries. Microservices, serverless, SOA, REST endpoints, mobile applications… all are distributed systems.
This distribution is stressing, even more, the need for collaboration between all the components forming the system.
When an application, for instance implemented in Java, needs to interact locally, it just uses a method call.
For example, to collaborate with a service exposing a hello method, you use service.hello().
We stay inside the same process.
Calls can be synchronous; there is no network I/O involved.
However, the dispersed nature of distributed systems implies inter-process communication, and most of the time, crossing the network (Figure 3-2).
Dealing with I/O and traversing the network makes these interactions considerably different.
Many middlewares tried to make the distribution transparent, but, don’t be mistaken, complete transparency is a lie as explained in A Note on Distributed Computing.
It always back-fires one way or another.
You need to understand the unique nature of remote communications and realize how distinctive they are in order to build robust distributed systems.
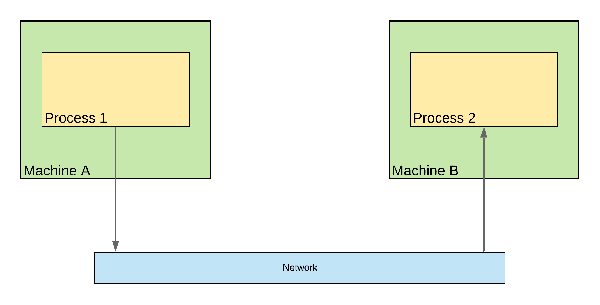
Figure 3-2. Remote interactions are leaving one process space and crossing into another process space via a network connection.
The first difference is the duration. A remote call is going to take much more time than a local call. It’s several degrees of magnitude higher. When everything is fine, sending a request from New-York City to Los Angeles takes around 72ms1. Calling a local method takes less than a nano-second.
A remote call is also leaving the process space, and so we need an exchange protocol. This protocol defines all the aspects of the exchange, such as who is initiating the communication, how the information is written to the wire (serialization and deserialization), how the messages are routed to the destination, and so on.
When you develop your application, most of these choices are hidden from you but present under the hood. Let’s take a REST endpoint you want to call. You will use HTTP and most probably some JSON representation to send data and interpret the response. Your code is relatively simple:
Example 3-1. Invoking a HTTP service using Java built-in client (chapter-3/http-client-example/src/main/java/http/Main.java)
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://httpbin.org/anything"))
.build();
HttpResponse<String> response = client.send(request,
HttpResponse.BodyHandlers.ofString());
System.out.println(response.body());Let’s describe what’s happening when you execute it:
-
Your application creates an HTTP request (
request). -
It establishes an HTTP connection with the remote server.
-
It writes the HTTP request following the HTTP protocol.
-
The request travels to the server.
-
The server interprets the request and looks for the resource.
-
The server creates an HTTP response with the representation of the resource state in JSON.
-
It writes the response following the HTTP protocol.
-
The application receives the response, and extracts the body (as
Stringin this example).
It’s the role of middleware (HTTP server and client, JSON mappers, …) to make these interactions easy for us developers.
In our previous example, the steps 2 to 8 are all hidden in the send method.
But, we need to be aware of them.
Especially today, with the Cloud, distributed systems and distributed communications are everywhere.
It becomes rare to build an application that is not a distributed system.
As soon as you call a remote web service, print a document or use an online collaboration tool, you are creating a distributed system.
The new kids on the block: Cloud-Native and Kubernetes-Native applications
The role of the Cloud can’t be overstated, and it’s a significant factor in the popularization of distributed systems. If you need a new machine, database, API gateway, or persistent storage, the Cloud can enable the delivery of these on-demand computing services. As a reminder, though, for as much as the Cloud improves efficiencies, you must never forget that running your application on the Cloud is equivalent to running on someone else’s machine. Somewhere there are CPUs, disks, and memory used to execute your application, and while Cloud providers are responsible for maintaining these systems and have built a reputation around reliability, the hardware is outside of your control.
Cloud providers provide fantastic infrastructure facilities making running applications much more straightforward. Thanks to dynamic resources, you can create many instances of your application and even auto-tune this number based on the current load. It also offers fail-over mechanisms such as routing requests to a healthy instance if another instance crashed. The Cloud helps to reach high-availability by making your service always available, restarting unhealthy parts of your systems and so on. This is a first step toward elastic and resilient systems.
That being said, it’s not because your application can run in the Cloud that it will benefit from it. You need to tailor your application to use the Cloud efficiently, and the distributed nature of the Cloud is a big part of it. Cloud-Native is an approach to building and running applications that exploit the Cloud Computing delivery model. Cloud-Native applications should be easy to deploy on virtual resources, support elasticity through application instances, rely on location transparency, enforce fault-tolerance, and so on. The Twelve-Factor App lists some characteristics to become a good Cloud citizen:
-
Codebase - one codebase tracked in version control, many deploys
-
Dependencies - explicitly declare and isolate dependencies
-
Config - store config in the environment
-
Backing services - treat backing services as attached resources
-
Build, release, run - strictly separate build and run stages
-
Processes - execute the application as one of more stateless processes
-
Port binding - export services via port binding
-
Concurrency - scale out via the process model
-
Disposability - maximize the robustness with fast startup and graceful shutdown
-
Dev/prod parity - keep development, staging and production as similar as possible
-
Logs - treat your logs as event streams
-
Admin process - run admin/management tasks as one-off processes
Implementing these factors help to embrace the Cloud-Native ideology. But, achieving Cloud-Native is not an easy task. Each of these factor comes with technical challenges and architectural constraints.
In addition, each Cloud provider provides its own set of facilities and APIs. This heterogeneity makes Cloud-Native applications non-portable from one Cloud provider to another. Very quickly, you end up in some kind of vendor lock-in, because of some specific API or services, or tooling, or even description format. It may not be an issue for you right now, but having the possibility to move and combine multiple Clouds improves your agility, availability, and user experience. Hybrid Cloud applications, for example, are running on multiple Clouds, mixing private and public Clouds, to reduce response time, and prevent global unavailability.
Fortunately, both public and private Clouds tend to converge around Kubernetes, a container orchestration platform. Kubernetes abstracts the differences between providers using standard deployment and runtime facilities. It executes and manages applications running in isolated boxes named containers.
To use Kubernetes, you package and run your application inside a container. A container is a box in which your application is going to run. So, your application is somewhat isolated from the other applications running in their own box.
To create containers, you need an image. A container image is a lightweight, executable software package. When you deploy a container, you actually deploy an image, and this image is instantiated to create the container.
The image includes everything needed to run an application: code, runtime, system libraries, and configuration. You can create container images using various tools and descriptors such as DockerFile. As we have seen in Chapter 2, Quarkus offers image creation facilities without having to write a single line of code.
To distribute your image, you push it to an image registry such as Docker Hub. Then, you can pull it and finally instantiate it to start your application (Figure 3-3).
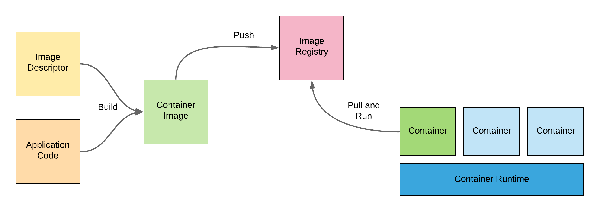
Figure 3-3. Creation, Distribution and Execution of Containers
While containerization is a well-known technique, when you start having dozens of containers, their management becomes complicated. Kubernetes provides facilities to reduce this burden. It instantiates containers and monitors them2, making sure your application is still running. As you can imagine, this can be very useful to implement the responsiveness and resilience characteristics from reactive systems.
Note
That does not mean you cannot implement a reactive system outside of Kubernetes. It’s definitely possible. In this book, we use Kubernetes to avoid having to implement the underlying infrastructure features such as deployment, replication and the ability to detect faults.
Under the hood, Kubernetes pulls container images, instantiates containers and monitors them. To achieve this, Kubernetes needs to have access to nodes to run the containers. This set of nodes forms a cluster. Thinking of a machine as a node allows us to insert a layer of abstraction. Whether these machines are Amazon EC2 instances, physical hardware from a data center or virtualized is irrelevant. Kubernetes controls these nodes and decides which part of the system will run where.
Once Kubernetes has access to your container image, you can instruct it to instantiate it: becoming a running container. Kubernetes decides on which node the container is executed. It may even move it later to optimize resource utilization, another characteristic that fit with reactive architectures.
As applications need to be Cloud-Native to benefit from the Cloud, they need to be Kubernetes-Native to benefit from Kubernetes. That includes supporting Kubernetes service discovery, exposing health checks used for monitoring, and, more importantly, running efficiently in a container. We will see in the next chapter how there three characteristics are essential from a Reactive point of view. You can wrap almost any application in a container. But it may not be a good idea.
When running in a container, your application lives in a shared environment. Multiple containers share the resources from the host, the machine executing them. They share the CPU, the memory and so on. If one container is too greedy, it penalizes the other containers that may starve. Of course, you can use quotas, but how would the greedy container behave under resource restrictions? So, yes, containers provide isolation, AND enable resource sharing.
One role of containers and Kubernetes is to increase the deployment density: running more using the finite set of available resources. Deployment density is becoming essential to many organizations because of the economic benefits. It allows reducing costs, either by reducing the monthly Cloud bill, or by running more applications on the current in-house infrastructure.
The table Table 3-1 summarizes some concepts we have seen so far around containers and Kubernetes.
| Name | Description | Associated Command |
|---|---|---|
Container Image |
lightweight, executable software package |
|
Container |
A box in which your application is going to run |
|
Pod |
The unit of replication in Kubernetes, composed by one of more containers |
|
Deployment |
Describe the content of a pod, how many instances of the pod we need |
|
Service |
A channel of communication delegating to a set of pods, selected by labels |
|
If you missed it, check out “Kubernetes with Quarkus in 10 minutes” where we deployed a Quarkus service to Kubernetes!
The dark side of distributed systems
Our system is simple, but even such a basic system can illustrate the hard reality of distributed systems. Cloud providers and Kubernetes provide excellent infrastructure facilities, but the laws of distributed systems still rule the system you are building. The technical complexity around provisioning and delivery has been replaced with fundamental issues from the nature of distributed systems. The size and complexity of modern applications make them undeniable.
At the beginning of this chapter, we saw a first definition of distributed systems. It was capturing the need for collaboration and communication to provide a consistent experience. Leslie Lamport gave a different definition which describes the dark nature of distributed systems:
A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable.Leslie Lamport
In other words, failures are inevitable. They are an inherent component of distributed systems. No matter how your system is built, it is going to fail. As a corollary, the bigger the distributed system, the higher the level of dynamism (i.e. the fluctuating availability of the surrounding services), and the chance of failure are.
What kind of failures can we encounter? There are three types of failures:
-
transient failure occurs once and then disappear, like a temporary network disruption;
-
intermittent failure occurs, then vanish and then reappear, like a failure happening once in a while without any apparent reason;
-
permanent failure is one that continues to exist until the faulty component (either software or hardware) is fixed.
Each of these types of failures can have two kinds of consequences. First, it can crash the application. We call these fail-stop failures. There are bad, of course, but we can easily detect them and repair the system. Then, a failure may introduce unpredictable responses at random times. We call them Byzantine failures. They are much harder to detect and to circumvent.
The Fallacies of Distributed Computing in a Kubernetes World
As developers, it can be challenging to imagine and plan all the different types of failure and consequences. How would you detect them? How would you handle them gracefully? How can you continue to provide a consistent experience and service if anything can fall apart? Building and maintaining distributed systems is a complex topic full of pitfalls and landmines. The Fallacies of distributed computing list, created by L Peter Deutsch along with others at Sun Microsystems, walks us through many false assumptions around distributed systems:
-
The network is reliable;
-
Latency is zero;
-
Bandwidth is infinite;
-
The network is secure;
-
Topology doesn’t change;
-
There is one administrator;
-
Transport cost is zero;
-
The network is homogeneous.
These fallacies have been published in 1997, long time before the era of the Cloud and Kubernetes. But, these fallacies are still relevant today, and even more relevant. We won’t discuss all of them, but focus on the ones related to the Cloud and Kubernetes.
The network is reliable:
The developer often assume that the network is reliable on the Cloud or Kubernetes. Indeed, it’s the role of the infrastructure to handle the network and making sure things work. Health checks, heartbeats, replications, automatic restart, a lot of mechanism are built-in at the infrastructure layer. It will do its best, but sometimes, bad things happen, and you need to be prepared for it. Data centers can fall apart3; parts of the system can become unreachable and so on.
Latency is zero:
The second fallacy seems obvious: a network call is slower than a local call, and the latency of any given call can vary significantly, even from one invocation to the next. We already discussed this. It is not limited to that aspect. The latency can change over time for various reasons.
Bandwidth is infinite, and The network is homogeneous:
You may reach the bandwidth limit, or, parts of the system use a faster network than some other regions, because they are running on the same node. Estimating latency is not trivial. Many capacity planning techniques and timeout computation are based on network latency.
Topology doesn’t change:
On the Cloud or on Kubernetes, services, applications, and containers move. Kubernetes can move containers from one node to another at anytime. Containers are frequently moving because of the deployment of new applications, updates, rescheduling, optimization, and so on. Mobility is a great benefit as it allows optimizing the whole system4, but interacting with services always on the move can be challenging. You may interact with multiple instances of your service, while, for you, it acts as one. Some instances can be close to you (and provide a better response time), while some may be further or just slower because of limited resources.
There is one administrator:
Managing systems have drastically changed over the past few years. The old-school system administration processes and maintenance downtimes are becoming less common. The DevOps philosophies and techniques such as continuous delivery and continuous deployment are reshaping how we managed applications in production. Developers can easily deploy small incremental changes throughout the day. DevOps tools and Site Reliability Engineers (SREs) work hard to provide an almost constant availability, while there is a continuous stream of updates to provide new features and bug fixes. The administration role is shared among SREs, software engineers, and software. For example, Kubernetes operators a program deployed on Kubernetes and responsible for installing, updating, monitoring and repairing parts of the system automatically.
Transport cost is zero:
Considering the network to be free is not only a fallacy, but it’s also an economic mistake. You must pay attention to the cost of the network calls and look for optimization. For example, crossing Cloud regions, transferring large amounts of data, or (especially) communicating between separate Cloud providers can be expensive.
So, not that simple, right? When you build a distributed system, consider all these issues and take them into account in your architecture and application code. That’s just some of the issues. There are more, such as the inability to reach a consensus5 or the C-A-P theorem6, which prevents a distributed data store from simultaneously providing more than two out of the following three guarantees:
-
Consistency: Every read receives the most recent write.
-
Availability: Every request receives a response.
-
Partition tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network.
Can things get even darker? Oh yes, distributed systems can be wonderfully imaginative to drive us crazy.
A question of timing - The synchronous communication drawback
Time is an often misunderstood issue. When two computers communicate and exchange messages, we make the natural assumption that the two machines are both available and reachable. We often trust the network between them. Why wouldn’t it be entirely operational? Why can’t we invoke remote services as we would do for a local service?
But, that may not be the case, and not considering this possibility leads to fragility. What happen if the machine you want to interact with is not reachable? Are you prepared for such a of failure? Should you propagate the failure? Retry?
In a hypothetical microservices-based example, it’s common to use synchronous HTTP as the main communication protocol between the services. You send a request and expect a response from the service you invoked. Your code is synchronous, waiting for the response before continuing its execution. Synchronous calls are simpler to reason about. You structure your code sequentially, you do one thing, then the next one, and so on. This leads to time-coupling, one of the less considered and often-misunderstood forms of coupling. Let’s illustrate this coupling and uncertainty that derive from it.
In the chapter-3/quarkus-simple-service directory of the Github Repository (https://github.com/cescoffier/reactive-systems-in-java/tree/master/chapter-3/quarkus-simple-service), you will find a simple hello world Quarkus application. This application is very similar to the one built in Chapter 2. It contains a single HTTP endpoint:
Example 3-2. JAX-RS Simple Service (chapter-3/quarkus-simple-service/src/main/java/org/acme/reactive/SimpleService.java)
package org.acme.reactive;
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.core.MediaType;
@Path("/")
@Produces(MediaType.TEXT_PLAIN)
public class SimpleService {
@GET
public String hello() {
return "hello";
}
}Hard to do simpler than this, right? Let’s deploy this application to Kubernetes. Make sure minikube is started, if not, start it with:
Example 3-3. Start minikube
> minikube start
...
> eval $(minikube docker-env) 
Don’t forget to connect the docker socket to minikube
Verify that everything is fine by running the kubectl get nodes command:
Example 3-4. Get the node names and roles
> kubectl get nodes NAME STATUS ROLES AGE VERSION minikube Ready control-plane,master 30s v1.20.2
Now, navigate in the chapter-3/simple-service directory and run:
Example 3-5. Deploy a Quarkus application to Kubernetes
> mvn verify -Dquarkus.kubernetes.deploy=true
Wait for the pod to be ready:
Example 3-6. Gets the list of running pods
> kubectl get pods NAME READY STATUS RESTARTS AGE quarkus-simple-service-7f9dd6ddbf-vtdsg 1/1 Running 0 42s
Then, expose the service using:
Example 3-7. Retrieving the URL of the service
> minikube service quarkus-simple-service --url ? Starting tunnel for service quarkus-simple-service. |-----------|------------------------|-------------|------------------------| | NAMESPACE | NAME | TARGET PORT | URL | |-----------|------------------------|-------------|------------------------| | default | quarkus-simple-service | | http://127.0.0.1:63905 | |-----------|------------------------|-------------|------------------------| http://127.0.0.1:63905 ❗ Because you are using a Docker driver on darwin, the terminal needs to be open to run it.
Don’t forget that the port is assigned randomly, and so, you will need to replace the port in the following commands.
Finally, let’s invoke our service by running in another terminal:
Example 3-8. Invoking the service
> curl http://127.0.0.1:63905 hello%
So far, so good. But this application contains a mechanism to simulate distributed system failures to illustrate the problem of synchronous communication. You can look at the implementation in chapter-3/quarkus-simple-service/src/main/java/org/acme/reactive/fault/FaultInjector.java. It’s basically a Quarkus route (a kind of interceptor) that monitors the HTTP traffic and allows simulating various failures. It intercepts the incoming HTTP request and outgoing HTTP response and introduce delays, loss, or application failures.
When we call our service in a synchronous way (expecting a response, such as with curl or a browser), three types of failure can happen:
-
The request between the caller and the service can be lost. This results in the service not being invoked. The caller waits until a timeout is reached. This simulates a transient network partition. This type of failure can be enabled using the
INBOUND_REQUEST_LOSSmode. -
The service receives the request but fails to handle it correctly. It may return an incorrect response or maybe no response at all. In the best case, the caller would receive the failure, or waits until a timeout is reached. This simulates an intermittent bug in the called service. This type of failure can be enabled using the
SERVICE_FAILUREmode. -
The service receives the request, processes it, writes the response, but the response is lost on its way back, or the connection is closed before the response reaches the caller. The service got the request, handled it and produced the response. The caller just doesn’t get it. It’s, like in (1), a transient network partition, but happening after the service invocation. This type of failure can be enabled using the
OUTBOUND_RESPONSE_LOSSmode.
Note
Don’t forget to update the port in the previous and following commands, as minikube randomly picks a port.
First, let’s introduce some request loss:
Example 3-9. Configuring the system to lose 50% of the incoming requests
> curl http://127.0.0.1:63905/fault?mode=INBOUND_REQUEST_LOSS Fault injection enabled: mode=INBOUND_REQUEST_LOSS, ratio=0.5
This command configures the FaultInjector to randomly loose 50% of the incoming requests.
The caller waits for a response that will never arrive half of the time, and will eventually timeout.
Try the following command until you experience a timeout:
Example 3-10. Invoking the service with a configured timeout
> curl --max-time 5 http://127.0.0.1:63905/
hello%
> curl --max-time 5 http://127.0.0.1:63905/
curl: (28) Operation timed out after 5004 milliseconds with 0 bytes received
--max-time 5configures a timeout of 5 seconds. Again, do not forget to update the port.
To simulate the second type of failure, execute the following command:
Example 3-11. Configuring the system to inject faulty responses
> curl http://127.0.0.1:63905/fault?mode=SERVICE_FAILURE
You have now a 50% chance of receiving a faulty response:
Example 3-12. Invoking the faulty application
> curl http://127.0.0.1:63905 hello% > curl http://127.0.0.1:63905 FAULTY RESPONSE!%
Finally, let’s simulate the last type of failure. Execute the following commands:
Example 3-13. Configuring the system to lose responses
> curl http://127.0.0.1:63905/fault?mode=OUTBOUND_RESPONSE_LOSS > curl http://127.0.0.1:63905 curl: (52) Empty reply from server
Now, the caller has a 50% chance of getting no response. The connection is closed abruptly before the response reaches the caller. You don’t get a valid HTTP response.
The purpose of these examples is to illustrate the strong coupling and uncertainty arising from synchronous communication. This type of communication, often used because of simplicity, hides the distributed nature of the interaction. However, it makes the assumption that everything (services, network…) is operational. But that’s not always the case. As a caller using synchronous communication, you must handle gracefully faulty responses and the absence of response.
So, what can we do? We immediately think about timeout and retries.
With cURL, you can specify a timeout (-m') and retries (--retry`):
Example 3-14. Invoking the application using a timeout and retry
> curl --max-time 5 --retry 100 --retry-all-errors http://127.0.0.1:63905/ curl: (28) Operation timed out after 5003 milliseconds with 0 bytes received Warning: Transient problem: timeout Will retry in 1 seconds. 100 retries left. hello%
There is a good chance that we can reach our service with 100 tries. However, bad luck and random numbers may decide otherwise, and even 100 may not be enough. Note that during that time, the caller (you) is waiting, that’s a rather bad user experience.
Yet, do we know for sure that if we get a timeout, the service was not invoked? Maybe the service or the network was just slow. What would be the ideal duration of the timeout? It depends on many factors: where the service is located, the latency of the network, the load of the service, maybe there not a single instance of this service but several, all with different characteristics.
Retries are even more sneaky. As you can’t know for sure if the service was invoked, you can’t assume it did not. Retrying may re-processed the same request multiple times. But, you can only retry safely if the service you are calling is idempotent.
So, what can we do? It’s essential to understand the impact of the time and decouple our communication. Complex exchanges involving multiple services cannot expect all the participants and the network to be operational for the complete duration of that exchange. The dynamic nature of the Cloud and Kubernetes stresses the limit of synchronous communications. Bad things happen, partitions, data loss, crashes…
In Chapter 4, we will see how Reactive addresses this issue. By using message-passing, spatial and time decoupling, a reactive system is not only more elastic and resilient, it improves the overall responsiveness. In other words: reactive systems are distributed systems done right. Also, in Chapter 5, we will see what approaches Reactive is proposing to embrace the asynchronous nature of distributed systems and how we can elegantly develop event-driven and asynchronous code. The result is not only concurrent and efficient applications, it also paves to road to new classes of applications such as data streaming, API gateways and so on.
Summary
Distributed systems are challenging. To build distributed systems, you need to understand their nature and always plan for the worst-case scenario. Hiding the nature of distributed systems to seek simplicity does not work. It results in fragile systems.
This chapter covered:
-
the erratic nature of distributed systems;
-
how distributed systems evolved from being a workaround to be the norm;
-
how the Cloud and Kubernetes are simplifying the construction of distributed systems;
-
how distributed communications can fail, because of network disruptions, or slowness.
But we won’t stop on a failure! Time to rebound! Let’s look a bit more into Reactive and see how it proposes to address these issues.
1 You can check the latency between the main American cities on https://ipnetwork.windstream.net/
2 Kubernetes provides health checks constantly verifying the state of the application. In addition, Prometheus (https://prometheus.io/) is becoming the metric collection standard framework.
3 In 2018, a power loss incident in AWS US-East-1 has caused many Amazon service disruption.
4 Kubernetes may move containers to achieve a higher deployment density, but also be instructed to move interacting applications on the same node to reduce the response time
5 Interested reader should look at Distributed System Revised from Heidi Howard re-discussing the problem of consensus in modern distributed system. (https://www.cl.cam.ac.uk/techreports/UCAM-CL-TR-935.pdf)
6 A short paper published in 2012 by Seth Gilbert and Nancy A. Lynch explain the technical implication of the C-A-P theorem in future distributed system (http://groups.csail.mit.edu/tds/papers/Gilbert/Brewer2.pdf)