
Chapter 1. OSGi and the enterprise—why now?
This chapter covers
- Why modularity is important, and how Java stacks up
- How OSGi enforces some simple rules to make Java better at modularity
- Why enterprise Java and OSGi traditionally don’t play well together
- How enterprise OSGi fixes this, and what the enterprise OSGi programming model looks like
Enterprise OSGi combines two of Java’s most enduringly popular programming models: enterprise Java and OSGi. Enterprise Java is a loosely defined set of libraries, APIs, and frameworks built on top of core Java that turn it into a powerful platform for distributed, transactional, interactive, and persistent applications. Enterprise Java has been hugely successful, but as the scale and complexity of enterprise Java applications have grown, they’ve started to look creaky, bloated, and monolithic. OSGi applications, on the other hand, tend to be compact, modular, and maintainable. But the OSGi programming model is pretty low-level. It doesn’t have much to say about transactions, persistence, or web pages, all of which are essential underpinnings for many modern Java programs. What about a combination, something with the best features of both enterprise Java and OSGi? Such a programming model would enable applications that are modular, maintainable, and take advantage of industry standard enterprise Java libraries. Until recently, this combination was almost impossible, because enterprise Java and OSGi didn’t work together. Now they do, and we hope you’ll agree with us that the merger is pretty exciting.
We’ll start by taking a look at what modularity is, and why it’s so important in software engineering.
1.1. Java’s missing modularity
When it was first introduced, in 1995, Java technology represented an enormous leap forward in software engineering. Compared to what had gone before, Java allowed more encapsulation, more abstraction, more modularity, and more dynamism.
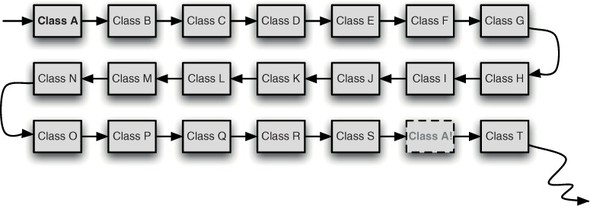
A decade later, some gaps were beginning to show. In particular, the development community was desperate for more encapsulation, more abstraction, more modularity, and more dynamism. Java’s flat classpath structure wasn’t scaling well for the massive applications it was now being used for. Developers found that, when deployed, their applications picked up a bunch of classes from the classpath that they didn’t want, but were missing some classes that they needed. In figure 1.1, you can see an example of a typical Java classpath.
Figure 1.1. Conventional Java has a flat classpath which is searched in a linear order. For large applications, this classpath can be long, and searches can be time consuming. If a class occurs more than once on the classpath, only the first instance is used—even if the second copy is better.
It was impossible to keep component internals private, which led to constant arguments between developers (angry that the function they relied on had been changed) and their counterparts, who were annoyed that developers had been coding against things that were intended to be private. After 10 years of continuous development, there was an urgent need to be able to label the many iterations of Java code that were out there with some sort of versioning scheme. Core Java was starting to feel pretty tightly coupled and undynamic.
Doesn’t Java’s object orientation enable modularity? Well, yes and no. Java does a great job of providing modularity at the class and package level. Methods and class variables can be declared public, or access can be restricted to the owning class, its descendants, or members of its package. Beyond this, there’s little facility for modularity. Classes may be packaged together in a Java Archive (JAR), but the JAR provides no encapsulation. Every class inside the JAR is externally accessible, no matter how internal its intended use.
One of the reasons modularity has become increasingly necessary is the scale of modern computer programs. They’re developed by globally dispersed teams and can occupy several gigabytes of disk space. In this kind of environment, it’s critical that code can be grouped into distinct modules, with clearly delineated areas of responsibility and well-defined interfaces between modules.
Another significant change to software engineering within the last decade is the emergence of open source. Almost every software need can now be satisfied by open source. There are large-scale products, such as application servers, IDEs, databases, and messaging engines. A bewildering range of open source projects that address particular development needs, from Java bytecode generation to web presentation layers, is also available. Because the projects are open source, they can easily be reused by other software. As a result, most programs now rely on some open source libraries. Even commercial software often uses open source componentry; numerous GUI applications, for example, are based on the Eclipse Rich Client Platform, and many application servers incorporate the Apache Web Server.
The increasing scale of software engineering projects and the increasing availability of tempting open source libraries have made modularization essential. Stepping back, what exactly do we mean by modularity, and what problems does it fix?
1.1.1. Thinking about modularity
Modularity is one of the most important design goals in modern software engineering. It reduces effort spent duplicating function and improves the stability of software over time.
Spaghetti Code
We’ve all heard code that’s too coupled and interdependent described as spaghetti code (figure 1.2).
Figure 1.2. A highly interconnected spaghetti application with little structure. The solid lines represent dependencies that are identifiable at both compile-time and runtime, whereas the dotted lines are runtime-only dependencies. This sort of dependency graph is typical of procedural languages.
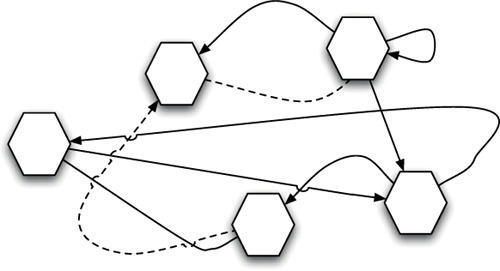
This sort of code is unfortunately common—both in open and closed source projects—and is universally despised. Not only is code like this hard to read and even harder to maintain, it’s also difficult to make even slight changes to its structure or move it to a new system. Even a slight breeze can be enough to cause problems! Given how strongly people dislike this sort of code, it should be a lot less common than it is, but, sadly, in a world where nothing stops you from calling any other function, it’s easy to write spaghetti by accident. The other problem with spaghetti is that, as soon as you have some, it tends to generate more quickly. . .
Object orientation marked a big shift in the development of programming languages, providing a strong level of encapsulation in them. Objects were responsible for maintaining their internal, private state, and could have internal, private methods. It was believed that this would mark the end of spaghetti code, and to an extent it did.
Extending the spaghetti metaphor, conventional Java programs (or any other object-oriented language, for that matter) can be thought of as object minestrone (figure 1.3)—although there’s a distinct object structure (the chunks of vegetable and pasta), there’s no structure beyond the individual objects. The objects are thrown together in a soup and every vegetable can see every other vegetable.
Figure 1.3. An application with no structure beyond individual well-encapsulated objects (connections between objects aren’t shown). This sort of structure is typical of object-oriented languages. Although the objects themselves are highly modular, there’s no more granular modularity.

Classpath Hell
Insufficient encapsulation isn’t the only problem with Java’s existing modularity. Few Java JARs are entirely freestanding; most will have dependencies on some other libraries or frameworks. Unfortunately, determining what these dependencies are is often a matter of trial and error. Inevitably, some dependencies may get left off the classpath when it’s run. In the best case, this omission will be discovered early when a ClassNotFoundException is thrown. In the worst case, the code path will be rarely traveled and the problem won’t be discovered until weeks later when a ClassNotFoundException interrupts some particularly business-critical operation. Good documentation of dependencies can help here, but the only reliable way of ensuring every dependency is present is to package them all up in a single archive with the original JAR. This is inefficient and it’s extra frustrating to have to do it for common dependencies.
What’s worse, even packaging JARs with all the other JARs they depend on isn’t guaranteed to make running an application a happy experience. What if a dependency is one of the common ones—so common that other applications running in the same JVM (Java Virtual Machine) depend on it? This is fine, as long as the required versions are the same. One copy will come first on the classpath and be loaded, and the other copy will be ignored. What happens when the required versions are different? One copy will still be loaded, and the other will still be ignored. One application will run with the version it expects, and the other won’t. In some cases, the “losing” application may terminate with a NoSuchMethodError because it invokes methods that no longer exist. In other, worse cases, there will be no obvious exceptions but the application won’t behave correctly. These issues are incredibly unpleasant and in Java have been given the rather self-explanatory name classpath hell.
Although classpath hell is a bad problem in core Java, it’s even more pernicious in the enterprise Java domain.
1.1.2. Enterprise Java and modularity—even worse!
Enterprise Java and the Java EE programming model are used by a large number of developers; however, there are many Java developers who have no experience with either. Before we can explain why enterprise Java suffers even more greatly than standard Java, we need to make sure that we have a common understanding of what the enterprise is.
What Distinguishes Enterprise Java from Normal Everyday Java?
Part of the distinction is the involvement of the enterprise—enterprise Java is used to produce applications used by businesses. But then businesses use many other applications, like word processors and spreadsheets. You certainly wouldn’t say that a word processor, no matter how business-oriented, had been produced to an enterprise programming model. Similarly, many “enterprise programmers” don’t work for particularly large corporations.
What’s different about enterprise applications? In general, they’re designed to support multiple simultaneous users. With multiple users, some sort of remote access is usually required—having 50 users crammed into a single room isn’t going to make anyone happy! Nowadays, remote access almost always means a web frontend.
To store the information associated with these users, enterprise applications usually persist data. Writing database access code isn’t much fun, so persistence providers supply a nicer set of interfaces to manage the interaction between the application code and the database.
This is a business application, and so transactions are usually involved—either buying and selling of goods and services, or some other business agreements. To ensure these “real” transactions proceed smoothly and consistently, even in the event of a communications problem, software transactions are used.
With all this going on, these enterprise applications are starting to get pretty complex. They’re not going to fit into a single Java class, or a single JAR file. It may not even be practical to run every part on a single server. Distribution allows the code, and therefore the work, to be spread across multiple servers on a network. Some people argue that distribution is the key feature of what’s known as enterprise computing, and the other elements, like transactions and the web, are merely there to facilitate distribution (like the web) or to handle some of the consequences of distribution on networks which aren’t necessarily reliable (such as transactions).
Java EE provides a fairly comprehensive set of standards designed to fit the scaling and distribution requirements of these enterprise applications, and is widely used throughout enterprise application development.
Modular Java EE—Bigger Isn’t Better
Our enterprise application is now running across multiple servers, with a web frontend, a persistence component, and a transaction component. How all the pieces fit together may not be known by individual developers when they’re writing their code. Which persistence provider will be used? What about the transaction provider? What if they change vendors next year? Java EE needs modularity for its applications even more than base Java does. Running on different servers means that the classpath, available dependencies, and technology implementations are likely to diverge. This becomes even more likely as the application is spread over more and more systems.
With these interconnected applications, it’s much better for developers to avoid specifying where all their dependencies come from and how they’re constructed. Otherwise the parts of the application become so closely coupled to one another that changing any of them becomes difficult. In the case of a little program, this close coupling would be called spaghetti code (see figure 1.2 again). In large applications, it’s sometimes known as the big ball of mud. In any case, the pattern is equally awkward and the consequences can be just as severe.
Unfortunately for Java EE, there’s no basic Java modularity to fall back on; the modules within a Java application often spaghettify between one another, and inevitably their open source library dependencies have to be packaged within the applications. To improve cost effectiveness, each server in a Java EE environment typically hosts multiple applications, each of which packages its own dependencies, and potentially requires a different implementation of a particular enterprise service. This is a clear recipe for classpath hell, but the situation is even worse than it first appears. The Java EE application servers themselves are large, complicated pieces of software, and even the best of them contain a little spaghetti. To reliably provide basic functions at low development cost, they also depend on open source libraries, many of the same libraries used by the applications that run on the application server! This is a serious problem, because now developers and systems administrators have no way to avoid the conflict. Even if all applications are written to use the same version of an open source library, they can still be broken by the different version (typically undocumented) in the underlying application server.
1.2. OSGi to the rescue
It turned out that a number of core Java’s modularity problems had already quietly been solved by a nonprofit industry consortium known as the OSGi Alliance. The OSGi Alliance’s original mission was to allow Java to be used in embedded and networked devices. It used core Java constructs such as classloaders and manifests to create a system with far more modularity than the core Java it’s built on.
OSGi is a big subject. Entire books are dedicated to it—including this one! This section reviews the basics of OSGi at a high level, showing how OSGi solves some of the fundamental modularity problems in Java. We also delve into greater detail into some aspects of OSGi which may not be familiar to most readers, but which will be important to understand when we start writing enterprise OSGi applications. We explain the syntax we use for the diagrams later in the book. This section covers all the important facts for writing enterprise OSGi applications, but if you’re new to OSGi, or if after reading it you’re bursting to know even more about the core OSGi platform, you should read appendixes A and B. We can’t cover all of OSGi in two appendixes, so we’d also definitely recommend you get hold of OSGi in Action by Richard Hall, Karl Pauls, Stuart McCulloch, and David Savage (Manning Publications, 2011).
In a sense, OSGi takes the Java programming model closer to an “ideal” programming model—one that’s robust, powerful, and elegant. The way it does this is by encouraging good software engineering practice through higher levels of modularity. These, along with versioning, are the driving principles behind OSGi. OSGi enables abstraction, encapsulation, decomposition, loose coupling, and reuse.
1.2.1. Modularity, versioning, and compatibility
OSGi solves the problems of sections and in one fell swoop using an incredibly simple, but equally powerful, approach centered around declarative dependency management and strict versioning.
OSGI Bundles—Modular Building Blocks
Bundles are Java modules. On one level, a bundle is an ordinary JAR file, with some extra headers and metadata in its JAR manifest. The OSGi runtime is usually referred to as the “OSGi framework,” or sometimes “the framework,” and is a container that manages the lifecycle and operation of OSGi bundles. Outside of an OSGi framework, a bundle behaves like any other JAR, with all the same disadvantages and no improvement to modularity. Inside an OSGi framework, a bundle behaves differently. The classes inside an OSGi bundle are able to use one another like any other JAR in standard Java, but the OSGi framework prevents classes inside a bundle from being able to access classes inside any other bundle unless they’re explicitly allowed to do so. One way of thinking about this is that it acts like a new visibility modifier for classes, with a scope between protected and public, allowing the classes to be accessed only by other code packaged in the same JAR file.
Obviously, if JAR files weren’t able to load any classes from one another they would be fairly useless, which is why in OSGi a bundle has the ability to deliberately expose packages outside itself for use by other bundles. The other half of the modularity statement is that, in order to make use of an “exported” package, a bundle must define an “import” for it. In combination, these imports and exports provide a strict definition of the classes that can be shared between OSGi bundles, but express it in an extremely simple way.
Listing 1.1. A simple bundle manifest that imports and exports packages
Manifest-Version: 1.0 Bundle-ManifestVersion: 2 Bundle-SymbolicName: fancyfoods.example Bundle-Version: 1.0.0 Bundle-Name: Fancy Foods example manifest Import-Package: fancyfoods.api.pkg;version="[1.0.0,2.0.0)" Export-Package: fancyfoods.example.pkg;version="1.0.0"
Many more possible headers can be used in OSGi, a number of which are described in later chapters.
By strictly describing the links between modules, OSGi allows Java programs to be less like minestrone and more like a tray of cupcakes (figure 1.4). Each cupcake has an internal structure (cake, paper case, icing, and perhaps decorations), but is completely separate from the other cupcakes. Importantly, a chocolate cupcake can be removed and replaced with a lemon cupcake without affecting the whole tray. As you build relationships between OSGi bundles, this becomes like stacking the cupcakes on top of one another. Exporting a package provides a platform onto which an import can be added. As you build up a stack of cupcakes, the cupcakes in the higher layers will be resting on other cupcakes in lower levels, but these dependencies can be easily identified. This prevents you from accidentally removing the cupcake on the bottom and causing an avalanche!
Figure 1.4. A well-structured application with objects grouped inside modules. Dependencies between modules are clearly identified. This is typical of the application structure that can be achieved with OSGi.
By enforcing a higher level granular structure on Java application code, OSGi bundles strongly encourage good software engineering practice. Rather than spaghetti code being easy to produce accidentally, it’s only possible to load and use other classes that are explicitly intended for you to use. The only way to write spaghetti in OSGi is to deliberately expose the guts of your OSGi bundle to the world, and even then the other bundles still have to choose to use your packages. In addition to making it harder to write spaghetti, OSGi also makes it easier to spot spaghetti. A bundle that exports a hundred packages and imports a thousand is obviously not cohesive or modular!
In addition to defining the API that they expose, OSGi bundles also completely define the packages that are needed for them to be used. By enforcing this constraint, OSGi makes it abundantly clear what dependencies are needed for a given bundle to run, and also transparent as to which bundles can supply those dependencies. Importing and exporting packages goes a long way to solving the issues described in this section, because you no longer have to guess which JAR file is missing from your classpath. In order to completely eradicate classpath hell, OSGi has another trick up its sleeve—versioning.
Versioning in OSGI
Versioning is a necessary complement to modularity. It doesn’t sound as enticing as modularity—if we’re being perfectly honest, it sounds dull—but it’s essential if modularity is to work at all in anything but the simplest scenarios. Why?
Let’s imagine you’ve achieved perfect modularity in your software project. All your components are broken out into modules, which are being developed by different teams, perhaps even different organizations. They’re being widely reused in different contexts. What happens when a module implements a new piece of functionality that breaks existing behavior, either by design or as an unhappy accident? Some consuming modules will want to pick up the new function, but others will need to stick with the old behaviors. Coordinating this requires the module changes to be accompanied by a version change.
Let’s go a step further. What if the updated module is consumed by several modules within the same system, some of which want the new version, and some the old version? This kind of coexistence of versions is important in a complex environment, and it can only be achieved by having versions as first-class properties of modules and compartmentalizing the class space.
Versioning is incredibly important in OSGi. It’s so important that if you don’t supply a version in your metadata, then you’ll still have version 0.0.0! Another important point is that versioning doesn’t only apply to packages; OSGi bundles are also versioned. This means that in a running framework you might have not only multiple versions of the same package, but multiple versions of the same bundle as well!
The semantic versioning scheme
Versioning is a way of communicating about what’s changing (or not changing) in software, and so it’s essential that the language used be shared. How should modules and packages be versioned? When should the version number change? What’s most important is being able to distinguish between changes that will break consumers of a class by changing an API, and changes that are internal only.
The OSGi alliance recommends a scheme called semantic versioning. The details are available at http://www.osgi.org/wiki/uploads/Links/SemanticVersioning.pdf. Semantic versioning is a simple scheme, but it conveys much more meaning about what’s changing than normal versions do. Every version consists of four parts: major, minor, micro, and qualifier. A change to the major part of a version number (for example, changing 2.0.0 to 3.0.0) indicates that the code change isn’t backwards compatible. Removing a method or changing its argument types is an example of this kind of breaking change. A change to the minor part indicates a change that is backwards compatible for consumers of an API, but not for implementation providers. For example, the minor version should be incremented if a method is added to an interface in the API, because this will require changes to implementations. If a change doesn’t affect the externals at all, it should be indicated by a change to the micro version. Such a change could be a bug fix, or a performance improvement, or even some internal changes that remove a private method from an API class. Having a strong division between bundle internals and bundle externals means the internals can be changed dramatically without anything other than the micro version of the bundle needing to change. Finally, the qualifier is used to add extra information, such as a build date.
Although our explanation focuses on the API, it isn’t only packages that should be semantically versioned. The versions of bundles also represent a promise of functional and API compatibility. It’s particularly important to remember that semantic versions are different from marketing versions. Even if a great deal of work has gone into a new release of a product, if it’s backwards compatible the version would only change from, for example, 2.3 to 2.4, rather than from version 5 to version 6. This can be depressing for the release team, but it’s helpful for users of the product who need to understand the nature of the changes. Also, think of it this way—a low major version number means you don’t make a habit of breaking your customers!
Guarantees of compatibility
One of the benefits provided by the semantic versioning scheme is a guarantee of compatibility. A module will be bytecode compatible with any versions of its dependencies where the major version is the same, and the minor version is the same or higher. One warning about importing packages is that modules should not try to import and run with dependencies with lower minor versions than the ones they were compiled against.
Version ranges are important when importing packages in OSGi because they define what the expected future compatibility of your bundle is. If you don’t specify a range, then your import runs to infinity, meaning that your bundle expects to be able to use any version of the package, regardless of how it changes! It’s good practice to always specify a range, using square brackets for inclusive or parentheses for exclusive versions. For example, [1.1,2) for an API client compiled against a package at version 1.1 would be compatible up to, but not including, version 2.
Coexistence of implementations
The most significant benefit provided by versioning is that it allows different versions of the same module or package to coexist in the same system. If the modules weren’t versioned, there would be no way of knowing that they’re different and should be isolated from one another. With versioned modules (and some classloading magic courtesy of OSGi), each module can use the version of its dependencies that’s most appropriate (figure 1.5).
Figure 1.5. The transitive dependencies of a module (the dependencies of its dependencies) may have incompatible versions. In a flat classpath, this can be disastrous, but OSGi allows the implementations to coexist by isolating them.

As you can see, being explicit about dependencies, API, and versioning allows OSGi to completely obliterate classpath hell, but OSGi on its own doesn’t guarantee well-structured applications. What it does do is give developers the tools they need to define a proper application structure. It also makes it easier to identify when application structures have slid in the direction of highly coupled soupishness. This is a pretty big improvement over standard Java, and OSGi is worth considering on the basis of these functions alone. OSGi has a few more tricks up its sleeve. Curiously enough, modularity was only one of the aims when creating OSGi: another focus was dynamic runtimes.
1.2.2. Dynamism and lifecycle management
Dynamism isn’t new to software engineering, but it’s fundamental to OSGi. Just as versioning is part of OSGi to support proper modularity, modularity is arguably an OSGi feature because it’s required to support full dynamism. Many people are unaware that OSGi was originally designed to operate in small, embedded systems where the systems could physically change. A static classpath wasn’t good enough in this kind of environment!
Why did OSGi need a new model for dynamism? After all, in some ways, Java is pretty dynamic. For example, reflection allows fields to be accessed and methods to be invoked on any class by name. A related feature, proxies, allows classes to be generated on the fly that implement a set of interfaces. These can be used to stub out classes, or to create wrappers dynamically. Arguably another even more powerful dynamic feature of Java is URL classloaders. Classes may be loaded from a given URL at any point in time, rather than all being loaded at JVM initialization from a static classpath. Furthermore, anyone can write a classloader.
Java’s ability to write custom classloaders and add classes dynamically to a running system isn’t to be sniffed at. It’s this feature that makes much of OSGi possible. But Java’s classloading APIs are too low-level to be widely useful on their own. What OSGi provides is a layer that harnesses this dynamism and makes it generally available to developers who aren’t interested in writing their own classloaders or hand-loading all the classes they need.
Bundle Lifecycles
Unlike most JAR files on the standard Java classpath, OSGi bundles aren’t static entities that live on the classpath indefinitely. Dividing classloading responsibility among multiple classloaders enables the entire system to be highly dynamic. Bundles can be stopped and started on demand, with their classloaders and classes appearing and disappearing from the system as required. Bundles that have been started are guaranteed to have their requirements met; if a bundle’s dependencies can’t be satisfied, it won’t be able to start. The complete state machine for bundle lifecycles is sufficiently simple to display in a single picture (see figure 1.6).
Figure 1.6. Bundles may move between the installed, resolved, starting, active, and stopping states. A starting bundle can be lazily activated, and if so it won’t move to the active state (crossing the dashed line) until it’s needed by another bundle. A bundle is resolved if it’s installed and all its dependencies are also resolved or started. When a bundle is uninstalled, it’s no longer able to start, nor can it provide packages to any new bundles.
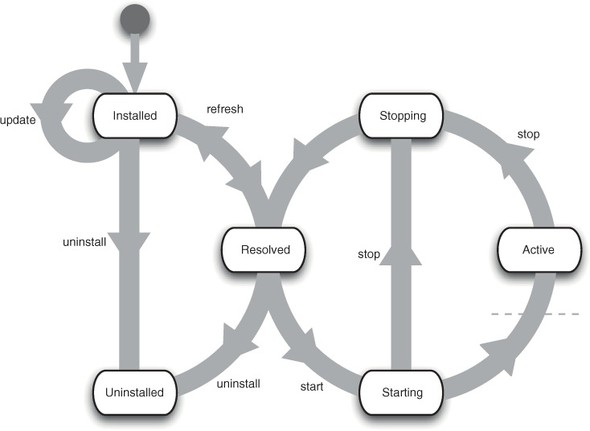
The most interesting states are installed, resolved, and active. An installed bundle doesn’t expose any classes until it’s resolved. After it’s resolved by having its dependencies satisfied, it can provide classes to other bundles. An active bundle can interact directly with the OSGi framework and change the behavior of the system by automatically executing nominated code.
Giving bundles a lifecycle has a few implications. The ability to execute code on bundle activation allows the system to dynamically update its behavior. Classes need not be loaded until required, reducing the memory footprint of the system. Because classes have the possibility of not being loaded, the system is able to ensure loaded classes have their dependencies satisfied. Overall, the system is both flexible and robust, which we think is pretty appealing!
Classloading
OSGi’s classloading is at the heart of what makes it different from standard Java. It’s an elegant and scalable system. Unfortunately, it’s also one of the greatest sources of problems when adapting applications that weren’t designed with modularity in mind to run in an OSGi environment.
Instead of every class in the virtual machine being loaded by a single monolithic classloader, classloading responsibilities are divided among a number of classloaders (see figure 1.7). Each bundle has an associated classloader, which loads classes contained within the bundle itself. If a bundle has a package import wired to a second bundle by the framework resolver, then its classloader will delegate to the other bundle’s classloader when attempting to load any class or resource in that package. In addition to the bundle classloaders, there are environment classloaders which handle core JVM classes.
Figure 1.7. The JVM contains many active classloaders in an OSGi environment. Each bundle has its own classloader. These classloaders delegate to the classloaders of other bundles for imported packages, and to the environment’s classloader for core classes.

Each classloader has well-defined responsibilities. If a classload request isn’t delegated to another bundle, then the request is passed up the normal classloader delegation chain. Somewhat surprisingly, this means that being included in a bundle doesn’t guarantee that a package will be loaded by that bundle. If that bundle also has an import for the package that’s wired by the framework resolver, then all class loads for that package will be delegated elsewhere! This is a principle known as substitutability. It allows bundles to maintain a consistent class space between them by standardizing on one variant of a package, even when multiple variants are exported. Figure 1.8 shows the class space for a bundle that exports a substitutable package.
Figure 1.8. The class space for a bundle includes all of its private classes, and the public classes of any bundle it’s wired to. It doesn’t necessarily include all the bundle’s public classes, because some might be imported from other bundles instead.

Services and the Service Registry
Bundles and bundle lifecycles are as far as many OSGi developers go with OSGi. Enterprise OSGi makes heavy use of another fundamental OSGi feature—services. OSGi services are much more dynamic than their Java Enterprise Edition (Java EE) alternatives. OSGi services are like META-INF services without all the messy files, or like Java Naming and Directory Interface (JNDI) with more power and less ... JNDI. Although OSGi services fill the same basic requirement as these two technologies, they have important extra features such as dynamism, versioning, and property-based filtering. They’re a simple and powerful way for bundles to transparently share object instances without having to expose any internal implementation—even the name of the class implementing the API. By hiding the service implementation and promoting truly decoupled modules, OSGi services effectively enable a single-JVM service-oriented architecture. Services also enable a number of other useful architectural patterns.
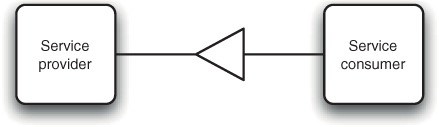
Figure 1.9 shows a simple OSGi service, represented by a triangle. The pointy end faces toward the provider of the service. One way of thinking of this is that the arrow points in the direction of invocation when a client calls the service. Another way to think of it is that the provider of a particular service is unique, whereas there may be many clients for it; as a result, the triangle must point at the only “special” bundle. Alternatively, if you squint really hard the service might look to you like the spout of an old-fashioned watering can, spreading water—or a service—out from a single source to many potential recipients.
Figure 1.9. A service that’s provided by one bundle and used by another bundle. The narrow end of the triangle points toward the service provider.
Providing services
Services are registered by a bundle using one or more class names that mark the API of the service, and the service object itself. Optional properties can provide extra information about the service and can be used by clients to filter which services get returned when they’re looking for one. Service properties aren’t intended for use by the service itself.

As you can see, providing a service is easy. Of course providing a service isn’t useful unless people have a way of finding and using it.
Accessing services
Services can be looked up using a simple API. Enterprise OSGi also allows services to be accessed declaratively and injected as a dependency. We’ll make use of service dependency injection throughout this book, starting in section 2.3.8. Before we get there, let’s have a peek at what a service lookup looks like without dependency injection:
String interfaceName = InventoryLister.class.getName(); ServiceReference ref = ctx.getServiceReference(interfaceName); InventoryLister lister = (InventoryLister) ctx.getService(ref);
What happens when multiple providers of the service have been registered? Service consumers have a choice between getting one, or a list containing all of them. If the service is something like a credit card processing service, it’s only necessary to take a payment once. In this situation one service provider is sufficient, and it probably doesn’t matter too much which provider is chosen. In the case of a logging service, on the other hand, logged messages should probably be sent to all the available loggers, rather than one of them. Fortunately, OSGi also allows you to find all of the services that match a particular request:
ServiceReference[] refs = ctx.getServiceReferences(Logger.class
.getName());
if (refs != null) {
for (ServiceReference ref : refs) {
Logger logger = (Logger) ctx.getService(ref);
logger.doSomeLogging();
}
}
As you can see, in addition to its modular, versioned runtime and flexible lifecycle management, OSGi provides an elegant services infrastructure and a lightweight dynamic framework. All of these encourage good engineering practice, but, as with most things, using OSGi doesn’t guarantee that your application will be well structured. What OSGi does is give developers the tools they need to be able to define a proper application structure. It also makes it easier to identify when application structures have slid in the direction of highly coupled soupishness. Given its obvious advantages, why isn’t everyone using OSGi already?
1.2.3. Why isn’t everyone using OSGi?
As we’ve mentioned previously, OSGi isn’t a new technology; the ideas have been around for more than a decade now. But OSGi adoption within the Java community isn’t as ubiquitous as you would expect, given its obvious advantages. There are several reasons for this.
The Origins of OSGI
The OSGi Alliance’s original mission was to allow Java to be used in embedded and networked devices. In addition to Sun, IBM, and Oracle, its original members were, for the most part, mobile phone manufacturers like Motorola and Ericsson, and networking companies like Lucent and Nortel. There were also energy companies involved, such as Électricité de France and the late Enron Communications. Within a few years, OSGi was being used inside set-top boxes, Siemens medical devices, Bombardier locomotives, and the entertainment system of the BMW 5 Series. The main reason for this is that the advantages of OSGi are particularly useful in constrained devices, or in applications where the system must remain running for long periods, including through maintenance updates.
The next wave of OSGi adoption happened in large-scale software projects, particularly IDEs, application servers, and other middleware. It’s initially surprising that a technology designed for the tiniest Java installations should be such a good fit for the largest ones. Do the software running a car stereo and the software in an enterprise application server have much in common? As it happens, yes. What embedded devices needed was modularity and dynamism; software with large codebases has the same requirements. Despite the huge increase in processing power and memory available to modern devices, OSGi is, if anything, even more useful in these big systems. The increasing complexity of software projects is a key driver for OSGi adoption in Java applications.
Because of its embedded origins, the acronym OSGi used to stand for Open Services Gateway initiative. Now, if you didn’t already know what OSGi was about, the phrase “Open Services Gateway initiative” doesn’t shout “dynamic module system for Java.” The name is so divorced from what OSGi is used for today that the original expansion of the acronym has been abandoned, and OSGi now stands for, well, OSGi.
Until recently, desktop applications suffered from neither the level of constraint of embedded systems nor the complexity of hefty middleware systems. In these environments the advantages of OSGi are sometimes viewed as insufficient when compared to its perceived drawbacks.
OSGI—Bad Press and Poor Understanding
During its lifetime, OSGi has suffered from some misconceptions and rather poor press. One of the big hurdles initially for OSGi was the perception that it was purely a technology for the embedded market, and that it was not needed, not useful, and, worst of all, a hindrance in the desktop and server space. This perception is clearly wrong, and was proved so when the Eclipse runtime chose to use an OSGi framework as its basis. It should be noted that Eclipse initially didn’t believe an OSGi platform would be suitable, but were later convinced by the huge increases in startup speed, reduced footprint, and complexity management offered by OSGi.
Despite OSGi’s success in Eclipse, OSGi is still perceived by many as being “too complex” for use in normal Java applications. Although OSGi metadata is simple, it isn’t part of base Java. This means that even experts in Java are usually novices in the use of OSGi. Further, the OSGi classloading model is significantly different from base Java and requires developers to understand the dependencies that their code has. This is, in general, good practice but it’s also something that developers aren’t used to. Particularly with established projects, retro-fitting modularity by unpicking entangled dependency graphs can be pretty daunting. The change of mindset in OSGi doesn’t always come easily, with the result that many people write OSGi off as too hard to be useful. While this may seem a little short-sighted, there are real reasons why OSGi feels excessively complex, particularly when applications try to make use of existing open source libraries.
Utility Libraries and OSGI
One of the big successes for Java has been that a large open source community has grown around it, providing a cornucopia of libraries, frameworks, and utilities. These libraries are so commonly used that there are almost no applications that don’t use any and most applications use several. Some libraries are so commonly used that many developers consider them to be part of the Java API.
Many of these Java libraries were not originally written with OSGi in mind. This means that they have to be manually converted into OSGi bundles by the developers using them. The developers have to guess which packages are API and which package dependencies exist, making the conversion process time consuming and error prone. We think this is a key reason why OSGi is often perceived as difficult.
Unfortunately for developers new to OSGi, the problems with open source libraries don’t end with packaging. Many libraries require users to provide some configuration, and sometimes implementations of classes. In standard Java, with its flat classpath, these resources and classes can be loaded easily using the same classloader that loaded the library class. In OSGi, these resources and classes are private to the application bundle, and can’t be loaded by the library at all! Problems like this are widespread in libraries that weren’t written with OSGi in mind and can’t usually be solved without reengineering the library significantly.
Fortunately for OSGi, open source libraries are increasingly available with OSGi-friendly packaging and API, meaning that OSGi is becoming easier to use than ever before. This effort is being made not only by the open source community, but also in new OSGi specifications, where the OSGi alliance is providing new, OSGi-aware mechanisms to make use of existing technologies.
1.2.4. Why OSGi and Java EE don’t work together
Unfortunately, utility libraries aren’t the only barrier to OSGi adoption. Many Java applications run on application servers, and use some form of enterprise Java, even if it’s only servlets or dependency injection. Sadly, the Java EE programming model has historically been incompatible with OSGi. Enterprise Java exists because the Java community recognized common needs and practices across a variety of business applications. Java EE provides a common way to make use of enterprise services. Unfortunately, Java EE aggravates the modularity problems present in standard Java, and is more resistant to OSGi solutions.
Frameworks and Class Loading
Enterprise Java application servers are large beasts, and typically host multiple applications, each of which may contain many modules. In order to provide some level of isolation between these applications, there’s a strict classloading hierarchy, one which separates the applications and modules from each other, and from the application server. This hierarchy is strongly based on the hierarchy of the classloaders in standard Java. Classes from the application server are shared between the applications through a common parent classloader; this means that application classes can’t easily be loaded from the application server classes. This may not seem like a big problem, but Java EE contains an awful lot of containers and frameworks that provide hook and plug points to application code. In order to load these classes, the frameworks, which are part of the base application server runtime, have to have access to the application.
This problem is bypassed in enterprise Java using the concept of the thread context classloader. This classloader has visibility to the classes inside the application module and is attached to the thread whenever a managed object (like a servlet or EJB) is executing. This classloader can then be retrieved and used by the framework code to access classes and resources in the application module that called into it. This solution works, but it means that many useful frameworks rely heavily on the thread context classloader being set appropriately. In OSGi, the thread context classloader is rarely set, and furthermore it completely violates the modularity of your system. There’s no guarantee that classes loaded by the thread context classloader will match your class space; in particular, there’s no assurance that you’ll share a common view of the interface that needs to be implemented. This causes a big problem for Java EE technologies in OSGi.
META-INF Services and the Factory Pattern
Although reflection, dynamic classloading, and the thread context classloader are useful, they’re of limited practical use in writing loosely coupled systems. For example, reflection doesn’t allow an implementation of an interface to be discovered, unless the implementation’s class name is already known. Having to specify implementation names in advance pretty much defeats the point of using interfaces. This problem crops up again and again in Java EE and, unsurprisingly, there’s a common pattern for solving it.
For many years, the best solution to the problem of obtaining interface implementations was to isolate the problem to one area of code, known as a factory. The system wasn’t loosely coupled, but at least only one area was tightly coupled. The factory would use reflection to instantiate a class whose name had been hardcoded into the factory. This didn’t do much to eliminate the logical dependency between the factory and the implementation, but at least the compile-time dependency went away.
A better pattern was to externalize the implementation’s class name out to a file on disk or in a JAR, which was then read in by the factory. The implementation still had to be specified, but at least it could be changed without recompiling the factory. This pattern was formalized into what’s known as META-INF services. Any JAR can register an implementation for any interface by providing the implementation name in a file named after the interface it implements, found in the META-INF/services folder of the JAR. Factories can look up interface implementations using a ServiceLoader and all registered implementations will be returned.
This mechanism sounds similar to OSGi services. Why isn’t this good enough for OSGi? One practical reason is that the service registry for META-INF services wasn’t available when OSGi was being put together. The other, more relevant issues are that, although META-INF services avoids tight coupling in code, it doesn’t give any dynamism beyond that, and it still relies on one JAR being able to load the internal implementation class of another. Furthermore, META-INF services can’t be registered programmatically, and they certainly can’t be unregistered.
1.3. Programming with enterprise OSGi
From what you’ve read so far, it probably sounds like OSGi is a lost cause for enterprise programming. Sure, it has some cool ideas and lets you do some things that you couldn’t easily do before, but who could give up the smorgasbord of enterprise services that don’t work in OSGi? Obviously this isn’t the case, or this would be a short book! Recently the gap between Java EE and OSGi has grown much smaller, with the introduction of enterprise OSGi.
One of the fascinating things about OSGi’s development from a platform for home gateways, to a platform for trains and cars, to a platform for IDEs and application servers is that OSGi itself hasn’t had to change that much. Even though the domains are totally different, the capabilities provided by OSGi solved problems in all of them. Enterprise OSGi is different because basic OSGi by itself isn’t enough. To address the needs of the enterprise, the OSGi Alliance has branched out and produced an Enterprise Specification with enterprise-specific extensions to core OSGi.
1.3.1. Enterprise OSGi and OSGi in the enterprise
Like the term enterprise Java, enterprise OSGi can mean different things to different people. Some people refer to the use of core OSGi concepts, or an OSGi framework, to provide business value for one or more applications. This definition is a little looser than is normally accepted; many people feel that merely using an OSGi framework to host business applications isn’t enough to justify the description “enterprise OSGi.” A parallel can be drawn to enterprise Java programming, a term which is linked to the use of the Java Enterprise Edition programming model, and usually an application server or servlet container. Using a Java Virtual Machine (JVM) and the Java Standard Edition (Java SE) APIs to write a business application would not normally be considered an “enterprise Java application.” Similarly, when business applications are merely using an OSGi framework and features from the core OSGi specifications, it’s not enterprise OSGi, although it might be OSGi in the enterprise.
Enterprise OSGi sometimes refers strictly to the set of specifications defined by the OSGi Enterprise Expert Group in the OSGi Enterprise Specification 4.2 and 5 releases. This narrow definition would exclude some open source technologies which aren’t in the enterprise OSGi specification but which clearly have an enterprise OSGi “feel.” Probably the most common and accurate definition of enterprise OSGi is a blend of what’s in the specification with the more general usage of OSGi in the enterprise we discussed. What we mean by enterprise OSGi in this book is an OSGi-based application that makes use of one or more enterprise services, as described in the OSGi Enterprise Specification, to provide business value. This links both the use of OSGi concepts and an OSGi framework with the OSGi Enterprise Specification, which defines how enterprise services can be used from inside an OSGi framework. What does this enterprise OSGi programming model look like?
1.3.2. Dependency injection
Dependency injection, sometimes called inversion of control, defines both an enterprise technology and an architectural model. Dependency injection has only recently become part of the official Java EE standard, but it has been a de facto part of enterprise programming for many years through the use of frameworks like Spring. Dependency injection is, if anything, even more valuable in an OSGi environment. Because the OSGi Service Registry is such a dynamic environment, it’s difficult to correctly write a bundle that makes use of a service in a safe way, monitoring its lifecycle, and finding an appropriate replacement.
Using and providing services becomes even more difficult when an implementation depends upon more than one service, with a user having to write some complex thread-safe code. Using dependency injection eliminates this complexity by managing the lifecycle of both the services exposed, and consumed, by a bundle.
Because of its ability to dramatically simplify programming in OSGi, dependency injection is at the heart of the enterprise OSGi programming model. Without it, business logic is difficult to separate from dependency management logic, and development is slow. The other key advantage of dependency injection is that it allows application code to avoid dependencies on core OSGi APIs, dramatically reducing the amount that developers need to learn before they can start making use of OSGi and making applications easier to unit test.
1.3.3. Java EE integration
As we mentioned previously, enterprise OSGi wouldn’t be useful if it didn’t provide at least some of the functions available in Java EE. Furthermore, Java EE already has a lot of experienced developers, and it wouldn’t be helpful if the OSGi way of doing things was completely different from the Java EE way. These two requirements are fundamental drivers of the OSGi Enterprise Specification, which aims to provide core enterprise services, reusing Java EE idioms and structure where possible.
The OSGi Enterprise Specification is large, and covers many of the Java EE services that developers know and love. For example, it includes an OSGi-friendly version of a Web Archive (WAR), declarative Java Persistence API (JPA) database access, and access to Java Transaction API (JTA) transactions. It also includes, not one, but two dependency injection systems, Java Management Extensions (JMX) management, and a way of distributing work across multiple JVMs. The OSGi Enterprise Specification Releases 5 even includes support for dynamically exposing META-INF services as OSGi services. If you’re not familiar with JPA, JTA, and the other Java EE technologies we’ve mentioned, don’t worry—we’ll introduce them in later chapters with worked examples.
1.4. Summary
As we’re sure you’ve noticed by now, this chapter doesn’t contain a Hello World sample. We hope that, rather than rushing to get your money back, you understand the reason for this. The enterprise is a huge place, containing lots of platforms, technologies, and some extremely difficult problems. In the enterprise, Hello World doesn’t cut the mustard. There will be plenty of sample code throughout the rest of the book, and we promise that in the next chapter our first sample will be rather more than five lines of code and a call to System.out!
What this chapter does contain is a discussion of the problems with the current enterprise technologies. For some of you with years of OSGi experience, this information probably confirms what you already know. For others, we hope you now have a sense of how easily applications can become complex, particularly when they’re enterprise-scale.
With its long history and the breadth of support now offered by OSGi for enterprise technologies, it should be clear that OSGi is ready for the enterprise. It should also be clear that, whether you’re an OSGi developer whose application needs are getting too big, or you’re a Java EE developer tired of object minestrone and debugging your application’s classpath for the thousandth time, you’re ready for enterprise OSGi.