
Chapter 5. Best practices for enterprise applications
This chapter covers
- How to scope your OSGi bundles
- The importance of keeping your bundle’s private bits private
- Why static factory classes are no longer your friend
- The whiteboard pattern, a better alternative to the listener pattern
- Avoiding bad WAR habits, and why it makes sense to keep persistence code in its own bundle
In the first part of this book, we took a focused look at the Apache Aries project and how it can be used to write useful enterprise OSGi applications that leverage a combination of base OSGi modularity, enterprise services, and a lightweight programming model. Although this was an incredibly fast way to get to grips with enterprise OSGi, we feel it’s time now to take a step back and look at some of the principles underlying what we’ve been doing. Why did we structure the Fancy Foods application the way we did? What patterns should you be applying to your own applications?
5.1. The benefits of sharing—and how to achieve them in your bundles
You’re probably wondering why we make such a big deal about sharing code; sure it sounds great in theory, but is it ever practical? Even if it’s practical, is it worth the extra effort and loss of control?
Interestingly, both of these questions were initially raised about object-oriented programming (OOP), which was also introduced in an effort to increase reuse. Like OOP, the benefits of the new model in OSGi seem too good to be true, offering a theoretical reward that’s almost impossible to achieve in practice. Thankfully, OOP has proved to be a much better model for writing code that needed to work in a large system, but only if you made use of the tools available. The same is true of OSGi, and there are some simple rules you can use to determine whether what you’re writing will be a nice, reusable bundle, or if it will be a slightly mangled JAR.
Clearly there’s a significant cost associated with writing a piece of code. Even volunteered development time isn’t free; by spending time writing one piece of code, you’re always taking time away from other pieces of code that need to be written. What isn’t typically factored in is the cost of using code that has already been written. Sure, you don’t have to pay to write it again, but repackaging code when you need to update a dependency for a bug fix is time consuming, uses computing resource, and may in the long term lead to the sort of JAR hell we saw in chapter 1. More problems arrive if you have to switch to a different implementation of a library that’s ostensibly doing the same thing. It usually takes a lot of time and testing to find and fix all the places that were hooked into the old implementation.
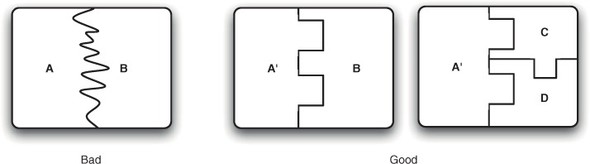
The cost of using and maintaining code depends to a great extent on how well modularized the code is. It sometimes helps if you think of a bundle as a puzzle piece. If your bundle has a lumpy, bumpy shape, then it’s almost certainly coupled to its dependencies (the other puzzle pieces around it) in a complex and brittle way. Although this shape may help in identifying the pieces of a puzzle, it doesn’t help when reusing bundles. The chances are that if the bundle or its dependencies change in any way, the result will change the shape of the pieces so that they don’t fit together anymore, causing a failure. If your bundle is well modularized, it will have a simple shape, meaning that it’s much easier to find pieces that fit with it (see figure 5.1). Clearly this doesn’t help you finish a puzzle, but it does make it much easier to reuse code!
Figure 5.1. Bundles that have complex dependencies (like A) can typically only be used in one way, relying on the dependencies they were compiled with. Bundles with a well-managed dependency graph can (like the refactored A') be reused in a variety of ways, because it’s simple to satisfy their dependency requirements.
Another cost that’s almost always overlooked by developers, but significantly affects infrastructure, is how things are shared at runtime. Although you may have saved lots of money at development time by using a library in the twenty applications running on your system, if that library is loaded twenty times you still need to pay the footprint cost at runtime. In many systems this is a real problem, running to hundreds of megabytes, that adds a significant cost over the lifetime of the application. The problem is particularly obvious in cloud environments, where there’s a direct price tag attached to application memory usage.
If you get your sharing right, then you can bypass both the cost of rewriting and the cost of repackaging your code. If you get your sharing really right, then you can reduce or even eliminate the cost of switching implementations, and the cost of loading the same library multiple times. One of the first, and most helpful, things you can do to start getting your sharing right is to get the basics of your bundles right. Unless you do this, everything else becomes difficult.
5.1.1. Versioning bundles and packages
As we discussed in section 1.2.1, versioning is a fundamental part of OSGi. Bundles and packages have versions, and getting them wrong can cause a lot of trouble. You can spend a lot of effort producing nice, well-proportioned bundles, but then waste it all by failing to version your imports and exports properly. A good explanation of the OSGi-recommended semantic versioning scheme is in section 12.1.2.
When we say versioning is vital, we mean it. In fact, a badly sized bundle with good versioning is better than any other bundle without versioning. If you don’t provide version ranges for the packages you import and versions for your exports, it’s impossible for anyone to reuse your bundle without having to find and install all the dependencies you originally compiled against. Even worse, if any of your bundle’s package dependencies are the same as any of those from any other bundle, and the two bundles need different versions of that package—but don’t express that in their package imports—then the application can’t be made to work!
Bundle Versions
Versioning bundles is probably the least well-defined versioning practice, and it’s correspondingly less important than versioning package imports and exports. You mustn’t let this mislead you into thinking that the bundle version isn’t at all important. The version of your bundle should indicate to the world how the bundle’s features and packages have changed over time. This will allow people to easily locate a bundle version that fits their needs.
How should you decide on a version for your bundle? Some people use the same semantic versioning principles for bundles as they do for packages, so that a bundle with backward-compatible changes might change from 2.1 to 2.2, for example, whereas a breaking change would be indicated by changing 2.1 to 3.0. Others align bundle versions with marketing versions, so that major functional improvements might warrant a change from 2.1 to 3.0, even if those changes are backward compatible. Whichever you choose, we feel that your bundle version should never change by a smaller increment than any of the packages it exports. If you’ve made a breaking change in a package that you provide, then this should be reflected in the bundle’s version, as well as the version of the exported package.
Versions for Exported Packages
Versioning API packages is extremely important; the version of an exported package is what allows providers and consumers of that API to determine if they’re compatible with it. Semantic versioning is important because it provides detailed information about the types of changes that have occurred within the API. Versioning API packages is also crucial because if two packages have the same name and version, then they need to be identical. If you don’t change your API version when the API changes, you’ll hit the kinds of problems that feature in the section, “The problem with split packages.”
Import Version Ranges
Export versions are usually easy to define. Even if you don’t follow the semantic versioning scheme (although you definitely should), it isn’t too hard to decide on a version number. Things are less easy when it comes to package imports. This is because package imports use version ranges to define their future compatibility. In the absence of semantic versioning this is painfully difficult, but you should still try to pick a range of versions. What you absolutely must not do is add a single version matching the export you intend to use. For example, the following innocent-looking import is dangerous:
Import-Package: fancyfoods.offers;version="1.0.0"
Doing this says that your application is compatible with all future versions of this package (to infinity). This is extremely unlikely to be true, and causes major problems when an API does eventually make a breaking change.
5.1.2. Scoping your bundles
How many bundles is the right number of bundles? How big should bundles be? The answer to both questions, unfortunately, is “it depends.” A bundle with one class in it is probably too small. A bundle with a hundred packages in it is almost certainly too big. In between those two extremes, however, it’s up to you.
The aim of modularization is the same for bundles as it is for objects, high cohesion, and loose coupling. A good bundle is highly cohesive and loosely coupled. Bundles should be tightly focused in what they do, and they should be flexible in how their dependencies are satisfied. If a single bundle seems to be doing lots of different things, it’s probably too big (incohesive). If it’s tightly coupled to another bundle, then perhaps the two of them should be merged into one bigger bundle, or have some of their classes redistributed to reduce the coupling.
A bundle’s package imports and exports can give a pretty good indication of both how cohesive it is and how coupled it is to its neighbors. If a bundle has a lot of package imports, perhaps it’s trying to do too much in too many different areas (incohesive). For example, does the code for generating servlets and the code for sending JMS messages need to live in the same bundle? The number of imports doesn’t show anything about coupling, but the nature of what’s imported does. If a bundle imports low-level APIs or, worse yet, implementation packages, perhaps it’s too closely coupled to its dependencies. Similarly, if a bundle has too many exports, it might be a bloated module trying to do too much in too many areas. If it’s exporting lots of packages, it may be exposing too many of its innards to the outside world and encouraging an unhealthy level of coupling; if it’s exposing packages containing implementation classes, the coupling is almost certainly too high. Keeping a handle on your imports and exports is a nicely complementary goal to achieving a well-structured modularization.
The Require-Bundle header is also a big clue that two bundles are tightly coupled. Ask yourself if you need those classes to come from that particular bundle rather than somewhere else. If you do need your dependencies to come from a fixed place, then the chances are that your classes should be packaged there too!
How to Minimize Package Imports and Exports
The dependency graph of a well-architected application should look less like spaghetti and more like a fork. Try to keep both the package exports and package imports as small as possible. This can be a useful guide to sizing your bundles correctly. If the bundles are too small, function will be split between bundles and dependencies that should be internal are forced to be external (see figure 5.2).
Figure 5.2. Bundles that are too granular will be forced to import and export lots of packages from other parts of the application (solid lines). If the bundles are made slightly larger, many of those dependencies become internal-only (dotted lines).

On the other hand, if bundles are too big, they may have sprawling external dependencies. For example, if the code for talking to both Oracle and DB2 databases is in the same bundle, that bundle will have dependencies on both the Oracle and DB2 database packages when both are unlikely to be present at the same time. In a less extreme case, a bundle that provides both a web frontend and a JMS backend will find itself depending on many unrelated bundles. Bundles that are too big are difficult to reuse in different contexts because they pull in piles of irrelevant dependencies, all of which have to be provided before you can call even a single method (see figure 5.3).
Figure 5.3. Bundles that are too big can have far too many unrelated dependencies. Splitting these bundles up doesn’t reduce the number of dependencies, but it can make the dependencies easier to manage, and the bundles easier to reuse, by not requiring all the dependencies to be present all the time!
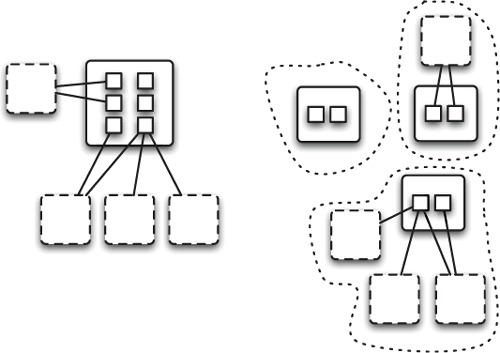
In the sweet spot, a bundle will—hopefully—have few dependencies on other bundles in the application, and few external dependencies. In day-to-day software development, bundles with tiny dependency sets and few exported packages are much easier to aspire to than to achieve! Both your authors have sometimes found themselves writing bundles with enormously long Import-Package statements, despite their best intentions.
If you end up in a similar situation, you shouldn’t beat yourself up over it—we’ve all been there, and a lot of us are still there! But, it might be a good opportunity to look at how your code is divided between your bundles, and see if rearranging your bundle boundaries, or moving to a more service-oriented approach (see the section, “Expose services, not implementations”), could neaten things up a bit. It may be that after looking at your bundles, you decide they’re highly cohesive and loosely coupled. In these cases you’ve done well, and no restructuring is required. Minimizing imports and exports is only a rough heuristic, and some highly cohesive and loosely coupled bundles do naturally have large dependency sets. What’s most important is the cohesion and coupling, not how many lines there are in the manifest!
Having read the information in this section, you’ll likely agree that structuring a bundle isn’t too difficult. The skills you’ve developed writing Java objects are completely transferable, and once you get a feel for it you’ll recognize a bad bundle in seconds. One important gotcha, which might seem perfectly innocuous and could easily be missed, is the cause of some of the most awkward headaches in OSGi development. This problem is called the split package.
The Problem with Split Packages
A split package is what you have when two bundles contain and export different bits of the same package at the same version. Although OSGi is well equipped to handle cases where the same package is exported by several bundles, the assumption is that the package implementations are interchangeable. Particularly, if two bundles export the same package at the same version, the OSGi framework could wire you to either. Importantly, the framework will only ever wire an importing bundle to one of the exported packages.
If a bundle imports a package and contains extra bits of that package without exporting it, it isn’t a split package. This is known as shadowing. Shadowing can cause as much of a mess as split packages, if you’re not careful. We’ll discuss shadowing more in a moment.
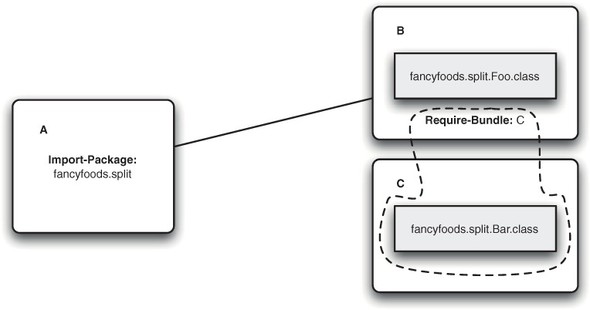
This works well when the packages are indeed interchangeable, but it can produce unexpected effects when different bundles claim to export the same package but contain different classes. Only the classes from the bundle you wire to will be visible at runtime! See figure 5.4.
Figure 5.4. An importing bundle can only wire to a single instance of an exported package. If this client needs fancyfoods.split.Foo, then you have a 50:50 chance of success. If it needs both fancyfoods.split.Foo and fancyfoods.split.Bar, then it can never work.

It’s possible to use attributes on your package exports to differentiate them, but this requires a corresponding attribute on the import. In the example manifests shown next, the importing bundle A will wire to the package from B and get fancyfoods.split.Foo every time:
Bundle-SymbolicName: A Import-Package: fancyfoods.split;type="top" Bundle-SymbolicName: B Export-Package: fancyfoods.split;type="top" Bundle-SymbolicName: C Export-Package: fancyfoods.split;type="bottom"
Another way of differentiating the two packages is to explicitly select a providing bundle, either with the bundle-symbolicname or bundle-version attributes. These are the only way to choose a particular provider that doesn’t specify any attributes:
Bundle-SymbolicName: A Import-Package: fancyfoods.split;bundle-symbolicname="B" Bundle-SymbolicName: B Export-Package: fancyfoods.split Bundle-SymbolicName: C Export-Package: fancyfoods.split
Although using attributes does allow you to pick one export or the other, it’s far from elegant. Using the bundle-symbolicname attribute introduces tight coupling between the importer and the exporter, as you force the framework to wire you to a particular bundle. This may indicate the two bundles should be merged. The type attribute you made up is a little more flexible, but still adds a degree of coupling. If you imagine a grand scale of coupling, this is much closer to an import without attributes than it is to the import with the bundle-symbolicname import. In either case, you’re constraining the framework resolver, which can introduce other problems. Depending on how the rest of the bundles in the runtime are wired together, it may not be possible for the importer to resolve, even if the right version of the fancyfoods.split package is present in the runtime. This can happen when the bundle importing the split package needs to import a different package from another bundle that has wired to the wrong version of the fancyfoods.split package.
Attributes have another critical limitation when it comes to split packages: they allow you to choose one export or the other, but never both. If the importer needs classes from more than one part of the split package (packages can be split across as many bundles as there are classes in the package), then they’re out of luck.
OSGi does offer a workaround for the split package problem that prevents the importing bundle from having to do anything messy, and that allows the importer to see the union of two or more parts of the split package. This requires one of the exporting bundles to use the Require-Bundle header to require the bundle that exports the other part of the split package. Require-Bundle is a bit like Import-Package:, except that you supply a bundle name and version, and it wires you to every exported package from that bundle. Unlike Import-Package:, Require-Bundle doesn’t cause any code inside your bundle to be shadowed. This means that your bundle can see its original content and the required bundle’s content for the split package, effectively combining them into one.
If a bundle contains a package without exporting it, and also imports it, the contained code will never be loaded. The semantics of OSGi classloading state that the load of any resource from an imported package is delegated to the exporting bundle to which you were wired. The content from the exporter shadows the entire content of the package inside the importing bundle, meaning that the contained content can’t be loaded even if there’s no corresponding resource in the exporting bundle. If you ever see a ClassNotFoundException for a class you know is in your bundle, then this is probably what has happened.
Require-Bundle doesn’t cause shadowing of entire packages, but it can cause shadowing of individual resources. As with imported packages, required bundles are searched before the classpath of the bundle. This means that if a resource is present in a required bundle, then it overrides that resource inside the bundle that requires it. This can cause major problems if the resources in the two bundles aren’t the same, or even if they are. When classes are loaded, their identity is defined by the java.lang.ClassLoader that loads them; this means that classes from required bundles are in a different package! This can cause havoc with default or protected visibility methods.
Using Require-Bundle, you can make one of the bundles export the entirety of the package. By adding an attribute with a mandatory constraint to the required bundle’s export of the split package, importers of that package no longer need to worry about accidentally getting wired to the wrong export (see figure 5.5). (We’ll look at the mandatory directive in more detail in section 7.1.3.)
Figure 5.5. In this case, the importing bundle, A, must wire to bundle B’s package because the mandatory directive on bundle C’s package requires that the importer specify partial="true" to wire to it. B uses Require-Bundle: C to unify the package, meaning that both fancyfoods.split.Foo and fancyfoods.split.Bar are visible to bundle A.
Bundle-SymbolicName: A Import-Package: fancyfoods.split Bundle-SymbolicName: B Require-Bundle: C Export-Package: fancyfoods.split Bundle-SymbolicName: C Export-Package: fancyfoods.split; partial="true"; mandatory:="partial"
The use of Require-Bundle and mandatory attributes can eliminate the ambiguity created by the split packages, but it significantly reduces the modularity and flexibility of your application. The two halves of your split package are forever tightly tied together, and the whole thing is rather unpleasant. We hope that you agree with us that split packages are better off avoided!
Warning: Require-Bundle and Eclipse Plug-in Development
If you’re using Eclipse’s Plugin Development Environment (PDE) to write your bundles, you may find you’re using Require-Bundle instead of Import-Packages even if you don’t have split packages. Historically, Eclipse used Require-Bundle internally, and its manifest editor occasionally defaults to requiring bundles rather than importing packages.
For those of you who develop in the Eclipse foundation, you’re likely to see split packages. The reason for the split packages in Eclipse is architectural. The core Eclipse runtime is packaged as an OSGi bundle and is extended by other bundles that add extra classes to core packages. Clearly, if the core runtime is going to be extensible, it can’t be tied to all the possible extensions by Require-Bundle. This left Eclipse with a solution similar to the one that we outlined earlier. Extensions to the Eclipse runtime bundle use Require-Bundle to unify the split package, and also export the package with an attribute that marks the extended view of the package. Clients that need a particular extension then supply a matching attribute on their import and find all the classes they need. Although this may sound elegant, it does mean that no client can make use of two extensions at once in a reliable way, and that clients need to be extra careful about what they import. As before, we strongly discourage you from splitting packages across bundles that you write.
So far we’ve been focusing on package imports and exports, but equally important is what you don’t share with the outside world.
5.1.3. Why isolation is important to sharing
An old adage in computing says “All you need to solve any problem is another layer of abstraction.” The grain of truth behind this saying is that problems often become much more tractable if the gory details are hidden away so that you can deal with a set of simple base cases instead. This fact applies generally across software, and most applications make use of frameworks or other services that deal in these abstractions.
Invasion of Privacy
One of the most important things about levels of abstraction is that the underlying details don’t bleed through, breaking the abstraction. In Java code this is typically accomplished through interfaces, factories, and changeable implementations. Unfortunately for Java, there’s little to prevent someone bypassing your API and starting to work directly with the underlying implementation classes. Clearly this is a gross violation of the abstraction, but what if there’s a method on the implementation object, but not on the interface, that does exactly what you want, what you need? Aren’t you tempted? Most people are; after all, expediency is what gets projects delivered on time, right?
The previous paragraph is clearly a bad idea, and yet so many of us are guilty of doing it. When people start casting objects to specific implementation types, the API becomes brittle. Any change to private content risks breaking clients, even though it’s not supposed to. Even without change, casting to implementation types is a risky business. What if the internal documentation says you’re supposed to synchronize on a particular object in a lock hierarchy before calling it to avoid a potential deadlock?
Keeping Your Bundles Modest
Given that we’ll never stop being tempted to make use of implementation specifics for expediency, sacrificing long-term benefit for a quick win despite the cost, developers won’t stop doing it. The only way to stop this sort of hack from happening is to make the hack less convenient than doing things properly. Fortunately, this is easy to accomplish in OSGi; if an implementation isn’t part of your API, then don’t export it. There’s no reason to expose the implementation type to other bundles. If other bundles can’t see your implementation type, it’s impossible for them to cast to it, and it takes a dirty hack for reflection to look like a good idea! When in doubt, cover up.
If your bundles do meet Victorian standards of decency, then how do they communicate? Bundle A may contain an implementation of an interface, but it’s not much use unless you can get it in to Bundle B somehow, and if you can’t cast to a type you certainly can’t instantiate it...
The answer is to use the OSGi Service Registry.
Expose Services, Not Implementations
As we’ve already mentioned, a great way of ensuring that bundles neither import nor export too many packages is to never export implementation classes. This also prevents people from violating any abstractions you’ve made, or doing things that are plain wrong. Using services isn’t just good for keeping manifest sizes down. It entirely avoids compile-time dependencies on implementation bundles and keeps the coupling between bundles much looser than it would be otherwise.
If you catch yourself exporting an implementation package from a bundle, stop and think carefully. Why are you doing this, and is it the best way? Is your bundle granularity too fine? Could a service be used instead?
5.2. Structuring for flexibility
You already know that how you structure and scope your bundles has a big impact on the modularity of your application. It’s also important to realize that the structure of your bundles affects how dynamic they can be as well. There are a few important things to remember.
5.2.1. Separate interfaces from implementation
Not exporting implementation packages is important for modularity, but for dynamism it’s best if they aren’t even in the same bundle as the interfaces. This is in fact one of the most important things you can do to allow dynamism. But why?
Hot Swappability
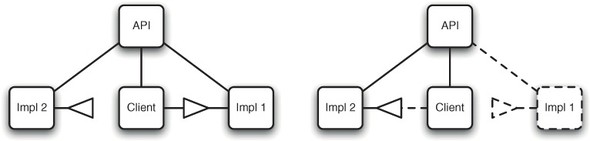
Keeping APIs separate from implementation matters more in an OSGi application because OSGi makes it possible to add and remove things from a bundle’s class space. If your implementation is packaged in the same bundle as its API, then their lifecycles are permanently tied together. If you had done this with your buggy persistence layer, then, to replace the implementation, you’d also have to replace the API. After the old API bundle has been replaced, any consumers of the API would need to be restarted and refreshed to wire to the new copy of the API classes. Keeping APIs separate gives you much more flexibility to swap implementations in and out without affecting other bundles in the runtime (see figure 5.6).
Figure 5.6. When the API for a service is separated from the client and implementations, then implementations can easily be switched. On the left you see the client using implementation 1. If you remove implementation 1 from the system, then the client can switch to implementation 2 with no loss in function or availability.
5.2.2. If you can’t separate out your API
Sometimes, for perfectly good reasons, it’s not possible to keep your API and implementation in separate bundles. Perhaps your architecture, or corporate policy, forces your API to be colocated with your implementation classes. The best solution is to come up with a more OSGi-friendly API, but often you have to play the cards you’re dealt.
In cases like this it’s important to ensure that you keep your class space as wide as possible. If three implementations of this API were present in the runtime, then clients would only be able to use one implementation at a time, determined by the API package they’re wired to, making the other two implementations redundant. Clearly this isn’t ideal.
Substitutability
Do you remember learning about shadowing (section 5.1.2)? In your current predicament, shadowing becomes useful. If your bundles both import and export the API packages, then the runtime will play a clever trick. If the API packages aren’t already available when your bundle is resolved, then the import statement is ignored and the API packages are exported from your bundle. If the API packages are available, then the export statement is ignored and the API packages are imported into your bundle. This arrangement means that there will only be one instance of the API package available in the framework, shared between all of the implementations. This means that clients can use any of the implementations.
If dependencies are only on interfaces, to the point where implementations can be swapped in and out at will, how does anything get hold of concrete instances of these interfaces? If you’re thinking in terms of conventional Java, you probably already have an answer ready—the factory pattern.
5.2.3. Avoid static factory classes
The factory pattern is extremely prevalent in Java; static factories are used to provide indirection between interfaces and implementations. Although this pattern is technically possible in OSGi, it’s unable to cope with OSGi’s dynamism. If you do create an object using a static factory, then you won’t get any notification when the bundle that provided it is stopped or even uninstalled. What’s worse is that because the static factory is unlikely to be OSGi aware, it won’t be tracking its dependencies either. This means that watching the lifecycle of the bundle that hosts the static factory isn’t always good enough to tell you that your object has become invalid.
The ability to register for Service Registry event notifications as well as the Service Registry’s get/release semantics provide exactly the lifecycle structure that’s missing from the static factory model. If you had used static factories to build your superstore, then you wouldn’t be able to dynamically add and remove special offers. What’s worse, you wouldn’t have been able to prevent people from seeing the special offer even if you removed the department, causing failures elsewhere. And you could never have separated out your interface and implementation bundles if you had to provide a static factory that was closely coupled to implementation internals.
As you try to break the static factory habit and replace it with services, you may find you have to change how you’re thinking in other areas. For example, the apparently inoffensive listener pattern often relies heavily on the factory pattern. Just as they allow you to avoid static factories, OSGi services also allow you to get more from your listener while writing less code.
5.2.4. Building a better listener with the whiteboard pattern
A common pattern in many applications is the listener pattern. An event source maintains a list of event listeners; when events happen, it notifies each listener in turn. Interested listeners register and unregister with the event source (see figure 5.7).
Figure 5.7. The listener pattern. A listener registers with an event source.
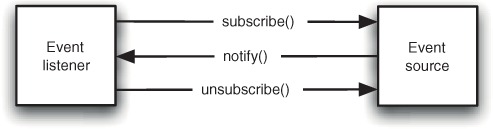
What happens when the listener’s useful life comes to an end? Depressingly little, in some cases. Unless the listener is careful, the event source still holds a reference to the listener. You risk ending up with unused objects hanging around, leaking memory, and being notified of events that they don’t care about and probably can’t handle without throwing an exception. The only way to avoid the issue is to be scrupulously careful about manually unregistering listeners when they no longer require events.
If you think about it a bit more, you can see that the event source is in fact maintaining a registry of listeners. It’s a pretty simple registry—often nothing more than a Set or List managed by register() and unregister() methods. Even though the registries aren’t particularly complex, they still need writing. It seems kind of crazy to re-implement a private registry for every class that could produce events. It seems extra crazy when even the best-written registries are still prone to memory leaks and runtime errors from obsolete entries. Less well-written registries can also be crippled by threading issues.
Outsourcing the Registry
Wouldn’t things be better if there were already a registry you could use? One that supported dependency injection? In OSGi, there is, and it does. Using the Service Registry as a convenient way of implementing a listener registry is known as the whiteboard pattern (see figure 5.8).
Figure 5.8. The whiteboard pattern. A listener registers with the Service Registry. When an event occurs, the event source obtains an up-to-date list of listeners to notify from the Service Registry.

The big advantage of the whiteboard pattern is that it avoids the explicit dependency between the event source and the listener. The listener merely needs to advertise that it’s interested in events, instead of tracking down a reference to a named event source. If needed, service properties and filters can be used to ensure listeners are registered only for events from the right sources; we’ll cover more about those in section 6.4.2.
If you struggle to get the whiteboard pattern first time ‘round, you’re not alone. One of the most puzzling things about the whiteboard pattern is its name! The idea behind the name, apparently, is that the Service Registry acts a bit like a whiteboard in an office. People can subscribe to an event—a picnic, say—by adding their name to the shared whiteboard. They don’t need to contact the picnic organizer directly, or even know who’s organizing the picnic.
At first, the whiteboard pattern can seem backward. After all, surely it’s the event source that’s providing the useful service, and the listeners that benefit from the service, right? The event source doesn’t need any of its listeners, but the listeners need the event source a great deal!
The thing to do is think less about the service part of the Service Registry and more about the registry part. The Service Registry, in combination with Blueprint, is a handy general-purpose registry. By using the Service Registry to collect your listeners you dramatically reduce the complexity of your event source. You also don’t have to worry about what happens when listeners are stopped; the Service Registry elegantly ensures that you only ever see services from running bundles. When you get used to the whiteboard pattern, you’ll find that it can be used to simplify many different situations. It even crops up when writing remote services, as you’ll see in chapter 10.
The whiteboard pattern is most effective when you want the same event, or the same processing, to occur multiple times. This could involve calling a number of listeners, counting up a number of objects, or even reacting to the presence and absence of particular services. You’ve been using the whiteboard pattern in the Fancy Foods online superstore since chapter 3; rather than registering each of the departments in your superstore with the business beans, you expose them as services, and let the business beans look them up as necessary. This is part of what makes the superstore so simple to extend.
Taking full advantage of OSGi doesn’t just means changing how you think about low-level patterns like factories and listeners. You may also need to have a bit of a rethink about some of your habits for structuring enterprise applications.
5.3. A better enterprise application architecture
If you’re used to writing Java EE applications, you probably have a toolkit of application architectures and development patterns you’re in the habit of using. Many of the patterns that work well for Java EE applications work equally well for enterprise OSGi ones.
How do these Java EE patterns translate in the dynamic world of OSGi? Some work pretty much unchanged. For example, you’ll probably want a business tier, a presentation tier, and a data access tier. But some of the familiar Java EE patterns need a bit of rework to make the most of OSGi’s modularity and dynamism, and there are some new patterns in enterprise OSGi.
A complete lesson on designing Java EE applications is well beyond the scope of this book, but we’ll walk you through some of the variations and exciting new possibilities that come with enterprise OSGi.
5.3.1. Use small WABs
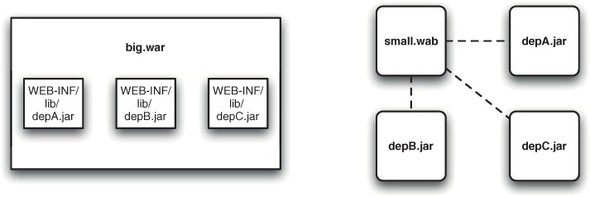
Many Java EE WARs are pretty big beasts. Not only does the WAR include its own code and image resources, it often packages all of its dependencies in the WEB-INF/lib folder. The WAR is acting almost like a mini-EAR, only with less explicit metadata.
Nobody likes massive WARs, but sometimes keeping all your JARs inside the lib directory is such an ingrained habit that you do it automatically. Remember—unlike WARs, WABs can be small, compact, and modular—and they’re better that way (see figure 5.9).
Figure 5.9. Whereas a WAR often needs to package all its code and dependencies inside the WAR itself, WABs can be much more modular.
5.3.2. Make a persistence bundle
If your application is using persistence, it’s a good idea to use a purpose-built persistence bundle for the persistence.xml and the entity classes. This may be a bit different from how you structured your persistence code for Java EE, but there’s a good reason for grouping everything together (see figure 5.10).
Figure 5.10. In an enterprise OSGi environment, it’s important to package persistence classes in the same bundle in which the persistence units are defined.
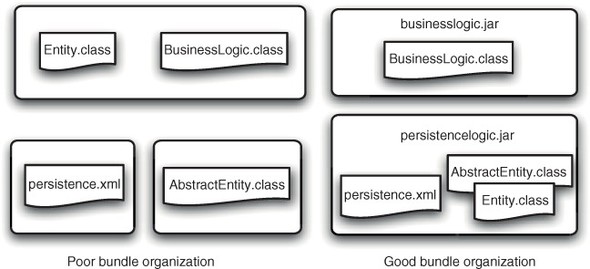
Why should the persistence unit and the entities be kept together? A persistence unit and its entities are intimately related; one without the other doesn’t give a complete picture. In combination, the persistence unit defines not only the database backing the entity classes, but also the way in which the entity classes are mapped into tables within the database. This is a tight coupling, and so the artifacts should live in the same bundle; making a change to an entity without reference to the persistence unit is usually disastrous, which is why storing them independently is a bad idea. Not only is keeping the persistence unit and its entity classes together wise, it’s required by the JPA Service Specification. If the entities are separated from the persistence unit, features like runtime entity enhancement will stop working.
Having a discrete persistence bundle has a second advantage. If the persistence code and domain model aren’t tangled in with application business logic, the same persistence services may be reused by several different applications. Having multiple persistence units talking to the same database is far less efficient in terms of implementation and maintenance effort. If either the implementation or the maintenance goes wrong, there’s the possibility of inaccurate entity mappings causing data corruption.
Packaging all of an application’s entities together may not feel like the most natural pattern to you. If your database is complex, your persistence bundle might be quite large, or even—say it isn’t so—monolithic. Ultimately, your persistence bundle will have the same modularity characteristics as your backing database. If the tables in your database split nicely into separate groups with the entities representing them having no mapped relationship (that is, they can be put into separate persistence units), then those persistence units can be happily packaged in different persistence bundles. On the other hand, if your entities are all interconnected, then they need to be in a single persistence unit, and therefore a single persistence bundle. When you think about it, this is exactly what you should be doing with classes in a bundle anyway.
Luckily, just because all of your entity classes are in a single bundle doesn’t mean they all have to be exposed to the rest of your application. Large domain models should at least be divided across multiple packages. Consuming bundles should only import the packages they need for their part of the business logic.
You may remember that in the section, “Expose services, not implementations,” we explained that hiding your implementation classes is a good idea. Sadly, JPA entity classes don’t fit particularly well with this model. By definition, entity classes aren’t interfaces, and they do contain a reasonable level of mapping metadata. When working out how best to deal with your JPA entities, you have two main options, which we’ll discuss next.
In more complex applications with multiple persistence units, it’s sometimes nice to pull out elements common to several JPA entities (such as numeric primary keys or creation dates) into a superclass or embedded class. This is enabled by JPA’s @MappedSuperclass and @Embedded annotations. Unfortunately, this pattern doesn’t always translate into an OSGi environment. The specification requires the persistence.xml to be in the same bundle as the entity implementations. This restriction applies to mapped superclasses, as well as the named entities. (Any interfaces are exempt!) This means mapped superclasses must be packaged in the same bundles as their subclasses, which can limit their reuse.
Exposing Entity Classes
The simplest option is to bite the bullet and export the JPA entity classes. This has the important, and sometimes unwanted, effect of making your entity classes part of your API. Exposing the entity classes directly makes it quick and easy for clients to use them, and also allows other bundles to make use of your persistence units by directly using your EntityManagerFactory services. This works well if the entity classes are simple, JavaBeans-style objects with getters and setters. It’s also important that the entity classes offer a reasonably stable API, and particularly one that isn’t specific to the underlying database implementation.
The main problems with exposing entity classes stem from the fact that the entities have become part of your API. First, you can no longer replace your persistence bundle without having to refresh all your persistence clients. Second, and probably more awkward, you can no longer make structural database changes, or add new features to your entity classes without potentially breaking the rest of your application. The more complex the logic in your entity classes is, the more likely this is to happen. Finally, if you do expose your entity classes, then you’re implicitly accepting the fact that other bundles can directly use your persistence units without going through a data access layer. If your database model is complex, or you wish to enforce some rules about valid data values, this is often a deal breaker.
Hiding Entity Classes with Interfaces
Normally, there’s no reason for any code to have a direct dependency on the persistence bundle, a fact that helps makes the persistence bundle easy to upgrade. If you add a data access service to your persistence bundle, you can use this to load and store objects but only refer to them by interface. This is exactly what you do in the Fancy Foods application, where Inventory and Accounting from section 3.2.4 take interfaces instead of implementations. Not only does this keep your business layer loosely coupled to your persistence bundle, but this has the big advantage that you can force every bundle to use your data access methods. This means that you can enforce rules about minimum stock and credit levels much more easily.
There are clear advantages to using interfaces to hide your entity classes; however, it isn’t a perfect solution. It’s easy for the data access service to return data objects that have been looked up—either the entity types will implement the interface directly, or there can be a wrapper class. Storing or updating the entity instances in JPA requires instances of the entity class. This means that the data access service must be able to create new instances of the entity classes from raw data (or other implementations of the interface) that get passed in. Sometimes you might get lucky, and find that you can cast the instance you were passed to an entity implementation (if, say, it came from a previous lookup), but other cases can involve significant amounts of copying.
5.3.3. The rewards of well-written bundles
Given the level of effort you spent making your bundles, you would hope for some sort of pay-off, and unsurprisingly there’s a big one. If you’ve written your bundles well, it becomes extremely easy to reuse them. Because you have a small list of imports, it’s trivial to supply your dependencies, and because the imports are versioned, you also know what version of the dependencies to supply. Furthermore, if you want to make use of a third-party bundle, then later change version or implementation, you know exactly which bundles are affected; there’s no need to scour the entire codebase of your application. Finally, because all of your exports and imports are versioned, it doesn’t matter if the dependency of a dependency clashes with another; if the versions are semantically compatible, you can provide one implementation that both can use, or if not, you can provide two implementations knowing that there’s no risk of failure at runtime!
For those who embrace OSGi, hiding implementation classes adds yet more benefits. Bug fixing and refactoring become trivial because there are no compile-time dependencies between implementation bundles, only between an implementation and its API. This significantly reduces the time it takes to debug, fix, build, and deploy.
Although the benefits mentioned are all incredibly worthwhile achievements, OSGi wouldn’t have achieved the popularity it has if that were all it had to offer. For many people who know OSGi, they’re fringe benefits—services are OSGi’s killer feature. We’ve seen one of the ways OSGi services can be put to use in our discussion of the whiteboard pattern. We’ll discuss OSGi services more in the next chapter.
5.4. Summary
Although this chapter hasn’t extended your superstore, it has taught you a lot more about what was already there. The main reason that you haven’t had to make changes to your application is that it was already following the guidelines for ensuring good modularity and dynamism. We hope that you have a new-found appreciation for your little superstore, and that by better understanding the principles that underpin it, you’ll find it easier to recreate its modularity in your own applications.