
Chapter 6. Building dynamic applications with OSGi services
This chapter covers
- What OSGi dynamism means for your application
- Your dependency injection options
- How to become a Blueprint power user
- How Blueprint interacts with OSGi dynamism
- Detecting system changes
Dynamism is probably the most powerful, and often the most underrated, feature of the OSGi framework. A lot of people think that their applications are already dynamic because they have plug points that can be easily extended, or that dynamism isn’t that useful. It’s true that dynamism isn’t important to everyone, but it can do a lot more than most people think!
What does dynamism mean for you? Is it your friend or your foe? If you decide it’s all too hard, can you ignore it entirely? How does it affect how you write your enterprise application?
One of the key enablers of OSGi dynamism is OSGi services. Services form the basis of an extremely powerful programming model, and OSGi’s dependency injection frameworks extend that programming model to make it simple to use, too.
In this chapter, we’ll discuss how OSGi dynamism works and how to get the most out of it. We’ll also cover in detail how dependency injection and services can be used to handle dynamism with as little work as possible.
We’ll start by looking more closely at what dynamism means for OSGi applications.
6.1. OSGi dynamism
One of the defining characteristics of OSGi is its dynamism. This dynamism was critically important in the environment for which OSGi was originally conceived: embedded devices. How does it play out in the enterprise space? Many of the concerns of enterprise applications are surprisingly similar to those of embedded ones; modules may be deployed to a variety of different environments, and those environments might change over the lifetime of the module, as other devices (in the embedded case) and components (in the enterprise case) come and go.
We first introduced the concept of dynamism way back in chapter 1, so far back that you might not remember it now. Since then we’ve covered a lot of ground, some of it making use of OSGi’s dynamism without calling it out. Going back to chapter 1, we discussed how in OSGi bundles can be started and stopped and even uninstalled from a running OSGi framework. This is the core of OSGi’s lifecycle model, and ties in closely with dynamism.
In OSGi, ACTIVE (that is, started) bundles are roughly equivalent to what Java EE developers would think of as running modules. In Java EE, running modules can load classes and have managed objects such as servlets or EJBs available for use by clients. In OSGi, things are similar: ACTIVE and STARTING bundles can load classes and expose services in the Service Registry. (A bundle may be in the STARTING state either because its bundle activator is still being run, or because the bundle has chosen lazy activation and none of its classes have been loaded.) Importantly, OSGi bundles have other states; you may remember that RESOLVED bundles can still load classes, but are not able to register services. If a bundle is stopped, then all of its services are unregistered. This has an important consequence for other bundles; because services can come and go, it’s possible that a service you’re using may cease to exist. Clearly your code might still have an object reference to call, but it’s important to stop using it because its behavior is no longer guaranteed. The stopped bundle will have lost access to any services it was using, and will probably also have done some tidy-up to free up resources.
The most surprising difference between Java EE and OSGi is that, in OSGi, modules can be completely removed from a running system or added to it. Can you imagine removing an EJB JAR from a running EAR without stopping the other EJB JARs and WARs? Doing this in OSGi is surprisingly easy; if you’ve been following our examples, then you’ve already done it! Do you remember fixing a bug in the superstore’s persistence layer? You had an in-memory database that continued running throughout. You didn’t even lose your HTTP session because the WAB was running throughout.
Warning: Dismantle with Care
Just because you can remove parts of a running OSGi application, doesn’t mean it always ends well! Your application must be written to cope safely with things appearing and disappearing. How to do that is the subject of this chapter.
Fixing the superstore was a powerful example of how OSGi’s dynamism can be used. You were able to apply a critical fix to your running application without stopping it. This is one of OSGi’s lesser-known features, but it’s the sort of thing that makes administrators squeak with joy. Your dynamic fix was only possible because you followed the good modularity practices described in section 5.1, keeping your bundles small and focused. If your persistence logic had been mixed in with your web layer, or implementation details had bled through, it wouldn’t have been possible. Good modularity on its own isn’t enough—you also had to follow good patterns for dynamism in the superstore’s design, handling the dynamic nature of the OSGi services you used to communicate between bundles.
6.2. Using OSGi services
Although services are an excellent way to decouple bundles from one another, they’re essential in a dynamic system. As you saw in the persistence layer of the superstore, service implementations can be replaced at runtime without even restarting the application. If implementation classes had been hardcoded, on the other hand, replacing one implementation with another would have required a complete recompile, as well as a restart.
One school of thought says that OSGi services are the most useful features of the entire OSGi specification, more valuable even than modularized classloading and versioning. In our opinion, it’s rather difficult to separate the two, although there have been a number of recent attempts to bring the OSGi Service Registry to Java SE, such as the pojosr project (http://code.google.com/p/pojosr/). This dynamic Service Registry has value, but without the underlying module lifecycle and classloading we can’t help but feel that there’s something missing. Equally, if you were to take the Service Registry out of OSGi, then you’d take many of the valuable usage patterns with it. Projects like pojosr are an excellent way to shrink the gap between Java SE and OSGi. We just hope that people don’t end up missing out on the real value of OSGi, thinking that OSGi is Java SE with a Service Registry.
6.2.1. Registering and looking up services the old-fashioned way
You’ve already been using OSGi services extensively in chapters 2 and 3. If you don’t recall a discussion of OSGi services, you’re probably not alone—you’ve always used Blueprint to manage your services. As you’ll see, there was a good reason for this!
Registering OSGI Services
Let’s see what OSGi services look like without a helper framework. Registering OSGi services is easy; it’s a single API call. The following listing shows how to register a service of class DesperateCheeseOffer that exposes the interface SpecialOffer.
Listing 6.1. Registering an OSGi service using the OSGi API

The service is registered under a string representing an interface name, and to prevent an error at runtime, the service object has to implement that interface. Optional properties describing the service can also be added. An object representing the service is instantiated, and then the name, properties, and instance are passed to the bundle context for registration with the OSGi framework. The returned ServiceRegistration can be used to unregister or update the service if you need to at some point in the future.
Looking up OSGI Services
Consuming OSGi services appears to be equally easy, requiring only two API calls. But this isn’t the whole story. You may have guessed that we’re keen to impress upon you that an OSGi framework is a dynamic place. Services can come and go at any moment, including the instant that you have looked them up! If you want to use services properly, it takes more code than the bare minimum two calls. You have to be particularly careful to always unget a service when you’re done with it. Listings 6.2 and 6.3 show code calling out to services in the Service Registry.
The get/release pattern can be the source of a lot of problems in computing, and many people are confused by why it’s needed in the OSGi Service Registry. Typically, in Java the only things that you release after use are I/O streams.
These need to be closed to free up resources, and that’s exactly the same reasoning used in OSGi. As we mentioned in section 1.2.3, OSGi began life in constrained systems. Every byte of memory was precious, so reducing the footprint was important. You’ll see in more detail in section 6.3.4 how services can be lazily created, but for now it’s enough to know that you can create a service object dynamically when it’s requested. The framework caches this result, speeding up future lookups and reducing memory usage. If the service is no longer being used, then this caching is a waste of memory. By ungetting the service you’re letting the framework know that it can invalidate its cache (assuming nobody else needs the service), and that any resources associated with the service can be cleaned up.
Listing 6.2. Consuming a single OSGi service using the OSGi API

You first use the bundle context to find services that are registered under an interface name you supply. A null return indicates that you couldn’t find any services with the right interface name. Then you can use the bundle context to get the service instance for the service you looked up. But between doing the initial lookup and getting the instance, the service might have been unregistered, in which case it’s no longer available. (Have we mentioned OSGi is dynamic?) After you have a service instance, you’re safe to use it. But you need to remember to unget the service when you’re done with it.
Even though listings 6.2 and 6.3 aren’t short, they don’t show all the possible complexity of getting services using the low-level OSGi APIs in a real application. If you showed this code to an OSGi expert, you’d get a lot of furrowed brows and concerned noises. This sample may not perform well, because it doesn’t keep hold of the service for long.
It also risks losing state if unget() is called with a stateful service. Even worse, nothing is done to handle the case when the service is dynamically unregistered. For more correct behavior, you’d need to introduce service listeners or service trackers. If your head is spinning at this point with all the APIs and complications, don’t worry—treat listings 6.2 and 6.3 as examples of what you won’t be doing, because you’ll be using dependency injection for your services instead!
Even if multiple services which implement the SpecialOffer interface are available, the code in listing 6.2 will only return the top-ranked service. To get all the available services, use the getServiceReferences method instead. You’ll also need to use getServiceReferences if you want to filter the returned services based on their service properties.
Listing 6.3. Consuming multiple OSGi services using the OSGi API

As before, you need to be diligent about checking for null service references and null service instances, and also in ungetting any services you get.
You may have noticed that listings 6.2 and 6.3 have to cast the service object to its interface type. Newer versions of the OSGi framework offer methods that take Class objects rather than String class names. These methods use Java generics to ensure type safety and remove the need to cast your service objects.
You could have used these methods to get slightly neater code in your examples, but existing code you see in the real world will almost certainly have been written using the older String versions of these methods.
The problem with consuming OSGi services is greatly magnified when a bundle relies on more than one; in fact this code is sufficiently complex that most people get it wrong. You can use a simpler OSGi API, called the ServiceTracker, to consume services (see appendix A for more detail). The ServiceTracker makes consuming a service easier, but things quickly become unmanageable if you need to consume more than one in a thread-safe way. It’s for this reason that we always recommend using a dependency injection framework to consume OSGi services. It’s not that you can’t do it yourself, but we don’t recommend it. (We suspect the complexity of the OSGi services API may be one of the reasons OSGi services haven’t yet taken the software world by storm, despite their usefulness.) Dependency injection frameworks eliminate almost all of the hassle of using OSGi services. But avoiding complexity isn’t the only reason to use dependency injection—there are lots of other advantages to using a dependency injection framework in OSGi.
Not only is it tricky to get right, consuming services programmatically isn’t terribly efficient unless you’re super-careful to optimize. Service instances (or service factories) need to be instantiated, even if nothing ever ends up looking up those services. If unget() isn’t called on looked-up services, classloaders may be held in memory unnecessarily. And OSGi dynamics mean that using services can be like walking through quicksand. At its best, dependency injection offers identical performance to using the programmatic service API and protects developers from the sometimes hairy dynamics of OSGi services without sacrificing anything in terms of dynamism or even the ability to respond to system changes. As you’ll see, there’s no shortage of dependency injection frameworks to choose from, either. We’ll discuss four of the more popular OSGi-enabled frameworks: Blueprint, Declarative Services, iPojo, and Peaberry.
6.2.2. Blueprint
In general, we believe the most suitable dependency injection framework for enterprise OSGi programming is Blueprint. Not only is it well integrated with other enterprise OSGi technologies, it acts as an integration point for many of them. For example, container-managed persistence and container-managed transactions use Blueprint for their metadata.
Because Blueprint is an open standard based on the Spring Framework, the XML syntax will be familiar to most Java EE developers. Blueprint also offers the best support of all the dependency injection frameworks for combining service injection with normal Java constructs like static factory methods and constructed objects. Finally, by using proxies, Blueprint insulates you and your application most effectively from some of the less welcome parts of OSGi dynamism.
6.2.3. Declarative Services
But Blueprint isn’t the only technology in town for managing OSGi services declaratively. An earlier specification, Declarative Services (DS), is also popular. In broad terms, Declarative Services is lighter-weight but less feature-rich than Blueprint-managed services. You may therefore find that Declarative Services offers slightly better performance than Blueprint, although well-optimized implementations are likely to show little measurable difference from one another. Like Blueprint, Declarative Services uses XML to expose a managed object as an OSGi service, inject dependencies, and chain services together. Also like Blueprint, managed objects are only exposed as services if all of the services that they’re injected with are also available or have been marked as optional. Declarative Services also helps manage OSGi dynamism, but unlike Blueprint it exposes you to more of the details.
Declarative Services doesn’t have the same level of support as Blueprint for building and describing networks of managed bean instances within a bundle. In Declarative Services, a managed component can easily be injected with a reference to a service and exposed as another service (see figure 6.1), but, for example, it isn’t possible to inject a component with another managed component that was created using an arbitrary static factory method.
Figure 6.1. A bundle using Declarative Services to consume a service into a managed component, which is then exported as a service itself

Instead of Blueprint beans, Declarative Services describes managed classes in terms of components and service components. For this reason, the Declarative Services technology is often referred to as Service Component Runtime (SCR). When we use the term SCR, we’re referring to one implementation of Declarative Services, the Apache Felix Service Component Runtime.
Like beans, service components may be wired to one another and optionally exposed as services. Listing 6.4 shows the Declarative Services equivalent of listing 3.7. The XML file should be referenced from the bundle manifest using the Service-Component header. Wildcards can be used to pick up several XML files.
Listing 6.4. Declaring special offer service that has an Inventory dependency

Because it’s an older technology than Blueprint, Declarative Services has a wider range of tooling support. Some of the more popular tools, such as bnd and bndtools, support both of them, which makes it convenient to use whichever dependency injection technology you prefer. (More on bnd can be found in chapter 8.)
Annotations
One limitation of both Declarative Services and Blueprint is that, in their original, strictly specified forms, neither supported annotations. Annotations are a frequent feature request for both Declarative Services and Blueprint, and unofficial support has been developed for both platforms. Annotation support for Blueprint has been prototyped in Apache Aries, but not developed further at the time of writing. Annotation support for Declarative Services is available in Apache Felix’s SCR subproject. The SCR support has now been standardized. As well as being more concise than XML metadata (which isn’t hard!), annotations are less brittle if you refactor your code frequently.
Felix’s annotation support works by using a Maven plug-in to convert the annotations to normal Declarative Services XML at compile time. To use the support, you’ll first need to add a Maven dependency on the maven-scr-plugin. The annotation syntax is rich, supporting almost everything that can be specified in DS XML, but in its simplest form, to identify a class as a component and expose it as a service, you’d write this:
@Component
@Service
public class DesperateCheeseOffer implements SpecialOffer {
To inject a reference to another service, it’s even simpler:
@Reference Inventory inventory;
Handy as it is, the Felix SCR annotation support does feel slightly tacked-on. Although Declarative Services is part of the existing OSGi specifications, annotations aren’t (although there are plans to add them soon). Other dependency injection frameworks support both XML and annotations as first-class programming models.
6.2.4. iPojo
We mentioned earlier that you’d be spoiled for choice in terms of dependency injection frameworks—or perhaps confused! Not only does the OSGi alliance specify two different dependency injection frameworks, Blueprint and Declarative Services, the Apache Felix project itself includes several subprojects for dependency injection: Service Component Runtime (a Declarative Services implementation), Dependency Manager, and iPojo. iPojo isn’t a standard, so you’re restricted to the one iPojo implementation. But it supports configuration by XML, annotations, and even API. It uses bytecode instrumentation internally, which makes it more invasive than Declarative Services, but also more powerful.
iPojo is extremely sophisticated, and we’ll only scratch the surface of it here. In its simplest form, iPojo looks a lot like SCR annotations, except that it uses a @Provides annotation instead of an @Service annotation to indicate that a component should be exposed as a service:
@Component
@Provides
public class DesperateCheeseOffer implements SpecialOffer {
Similarly, injected services are marked with a @Requires annotation:
@Requires Inventory inventory;
More fundamental differences become apparent when you try to do more involved things; iPojo has more support for lifecycle callbacks and complex dependency relationships than Declarative Services. It also supports stateful services by providing guarantees that a thread in a given context will always see the same service instance.
Because it uses bytecode instrumentation, in general iPojo requires an extra build step to insert the required bytecode. Build tasks and plug-ins are available for Ant, Maven, and Eclipse. iPojo does also provide a runtime enhancement feature, although this adds an unpleasant ordering dependency between iPojo and the bundles it extends.
6.2.5. Google Guice and Peaberry
Blueprint, Declarative Services, and iPojo were all designed with OSGi in mind, but dependency injection isn’t restricted to the OSGi world. Some of the non-OSGi dependency injection frameworks can also be adapted to work in an OSGi environment. In particular, a framework called Peaberry has been added to Google Guice that allows OSGi services to be exposed and consumed.
One feature of Peaberry that makes it different from the other frameworks here is that there’s nothing OSGi-specific about it. It can be extended to use any service registry (for example, integrations with the Eclipse extension registry are available). It can also use ordinary Guice injection. This means it’s easy to use the same client code in a variety of different contexts. The big problem with Peaberry comes from the fact that it isn’t specifically designed for OSGi, and there isn’t a specification describing it. Some of the more advanced features that are present in other OSGi dependency injection models are missing, or are more difficult to use than if they’d been designed in at the start.
A mix-and-match principle applies to any of the OSGi service-based injection frameworks we’ve described. If you want one of your modules to run outside of OSGi, but want to take advantage of Blueprint’s tight integration with the rest of the Apache Aries runtime, you can use Blueprint for most of your bundles and Peaberry in the module that needs to run elsewhere. Regardless of which implementation you choose to use, underneath they are all using normal OSGi services, so compatibility is guaranteed. Alternatively, if you like Blueprint’s tidy handling of OSGi dynamics, you could consume services using Blueprint but publish them using iPojo, or any other framework, or even register them programmatically.
Covering Declarative Services, iPojo, and Peaberry in detail is beyond the scope of this book; although these frameworks have many nice aspects and distinct advantages over Blueprint in some contexts, we think that Blueprint is the framework most suited to enterprise programming. Even though you’ve seen quite a bit of Blueprint already, it has lots of sophisticated features that we haven’t had a chance to explore yet. Let’s have a look at some of this extra power in more detail.
6.3. Getting the most out of Blueprint
As you’ve been writing the Fancy Foods application, we’ve been demonstrating the most important bits of the Blueprint syntax. But Blueprint is a rich specification language, and there’s lots more to it than what you’ve seen so far. We won’t cover all the dark corners of the Blueprint syntax in this chapter, but we’ll show you a few more capabilities.
6.3.1. Using Blueprint for things other than services
Although we’ve been talking about Blueprint as a tool for managing OSGi services, it can do a lot more than register and inject services. If you’re used to programming in core OSGi, you may have some jobs that you automatically do with a BundleActivator. (If you’re used to Java EE programming, you might be using static factories to do the same sorts of jobs.) All of this is still possible in enterprise OSGi, but we’re firmly convinced that it’s easier, cleaner, and better using Blueprint.
For example, an eager singleton bean can play the role of a bundle activator. The main difference is that a bean has much more flexibility in terms of its interface because a bundle activator has to implement BundleActivator, whereas a Blueprint bean can implement whatever it likes (or nothing at all).
Warning: Wiring Within a Bundle
One area where Blueprint is useful but OSGi services shouldn’t be used is for wiring within a bundle.
One good reason for this is that services are public; unless you want the entire framework to see your internal wiring, you should keep it out of the Service Registry.
Another good reason comes from Blueprint. Wiring beans from the same bundle together needs to be done using bean references instead of services. Otherwise, a circular dependency is created, where the Blueprint container for the bundle won’t initialize until it’s found all the unsatisfied service references. Because the unsatisfied service references are supposed to get registered by the waiting Blueprint container, this doesn’t usually end well.
6.3.2. Values
Blueprint allows you to declare a wide variety of Java objects using relatively simple XML. These values can be passed to beans using <property> and <argument> elements.
Special Types
Lists, sets, arrays, maps, and properties objects can also be specified in XML. To define a map of foods and prices, you could use the following XML:
<map>
<entry key="Bananas"
value="1.39" />
<entry key="Chocolate ice cream">3.99</entry>
</map>
The two forms of the <entry> element are equivalent. To define the same relationship as a Properties object, the XML would be
<props>
<prop key="Bananas"
value="1.39" />
<prop key="Chocolate ice cream">3.99</prop>
</props>
Null can be specified using <null>.
Type Conversion
Beans can be instantiated with simple Java types or references to more complex Blueprint-managed classes. The container will try to construct an appropriate object to pass to the class’s setter object from the XML parameters. It will automatically convert XML strings into Java primitives, and it can initialize arbitrary Java classes if they have a constructor that takes a simple String. Most impressively, Blueprint can use generic type information to perform implicit type conversion for collection types. For example, the following snippet calls a setShopClosedDates(List<Date> dates) method that expects a List of Date objects:
<property
name="shopClosedDates">
<list>
<value>November 6, 1980</value>
<value>February 14, 1973</value>
</list>
</property>
When implicit conversion isn’t good enough (or if you have nongeneric code), you can explicitly specify types:
<entry>
<key type="java.lang.String">Bananas</key>
<value type="java.lang.Double">1.39</value>
</entry>
Blueprint also allows you to define your own type converters, turning String values from the XML into arbitrary Objects, but because the default Blueprint type converter works in so many situations, it’s unlikely you’ll ever need to write your own.
Special Properties
In chapter 3, you saw how special <jpa:context> elements could be used to inject JPA persistence contexts. Blueprint also has a number of other predefined properties that can be used to get hold of special objects. For example, in the following example, the blueprintBundleContext reference is a precanned reference to the bundle’s BundleContext:
<bean class="SomeClass">
<property name="context" ref="blueprintBundleContext"/>
</bean>
(If you followed our advice about always using Blueprint instead of old-style OSGi, you shouldn’t ever need to get hold of a bundle context. But there are exceptions to every rule!)
6.3.3. Understanding bean scopes
Blueprint beans may have one of two scopes: singleton or prototype. If you’re keen, you can also write your own custom scopes. The scope determines the lifespan and visibility of the beans.
The Singleton Scope
When the singleton scope is used, a single instance of the bean is created. As figure 6.2 shows, the exact same instance is used every time the bean is required, even if it’s already in use. The singleton scope requires—but doesn’t enforce—that beans are stateless and thread safe. There’s only one instance created, regardless of the number of requests, so it’s an extremely scalable model.
Figure 6.2. When the singleton scope is used for a bean, every consumer of the bean is wired to the same instance.

The Prototype Scope
The prototype scope is the exact opposite of the singleton scope. Every time the bean is wired to a consuming bean, a new instance is created. This means beans can safely hold internal state, although they still need to be careful about thread safety. Although holding state can be a convenient programming model, its scalability is more limited. Figure 6.3 shows how the number of bean instances can rapidly multiply with the prototype scope.
Figure 6.3. When the prototype scope is used for a bean, every user of the bean is wired to a new instance. This allows beans to maintain internal state, but it’s less scalable.

The singleton scope is the default Blueprint scope for top-level beans (beans that are immediate children of the <blueprint> element). Inlined beans (bean declarations that are nested within other elements), on the other hand, have a default scope of prototype. Not only is the scope prototype by default, the scope is always prototype for beans declared inline. Because Blueprint is designed to be extensible, the schema does allow you to specify a scope for inlined beans; however, unless you’re using a custom namespace for your particular Blueprint implementation, any value other than prototype will be ignored, or cause an error creating the Blueprint container.
For example, the following Blueprint snippet declares a top-level bean with a prototype scope:
<bean
class="fancyfoods.department.cheese.offers.DesperateCheeseOffer"
scope="prototype"
id="cheeseOffer" />
<service
interface="fancyfoods.offers.SpecialOffer"
ref="cheeseOffer">
</service>
The previous example demonstrates a pattern that’s occasionally useful. Because the bean exposed as a service is prototype scoped, a new one will be created for each bundle that requests the service (though successive requests return the same object; see ServiceFactory in appendix A for details).
The following Blueprint snippet declares the same bean inline, which therefore has an implicit prototype scope. The runtime behavior is identical to the previous example:
<service interface="fancyfoods.offers.SpecialOffer">
<bean
class="fancyfoods.department.cheese.offers.DesperateCheeseOffer"/>
</service>
The scope of a bean affects more than how many Object instances you end up with. It also has implications for how the bean is constructed and how its lifecycle is managed.
6.3.4. Constructing beans
Beans can be instantiated lazily or eagerly. Eager instantiation is the default for singleton beans; however, this default can be changed for all the singleton beans in a Blueprint XML file. Beans with prototype scope are always constructed lazily because that’s the only way that makes sense. You may find for some singletons lazy activation is more efficient:
<bean
id="microwaveMeal"
class="fancyfoods.food.MicrowaveMeal"
activation="lazy"/>
Lazy activation is often a good thing in enterprise applications, because otherwise they can take rather a long time to start. As a result, the Blueprint container offers much more laziness than bean instantiation. For reasons we’ll discuss further in the section on damping, Blueprint <reference> objects are proxies to the real service. This means that the Blueprint container doesn’t have to look up the service until it’s first used. Another place in which Blueprint is particularly lazy is when it comes to registering services on your behalf. Rather than eagerly creating the service object, the Blueprint container registers a ServiceFactory object. A ServiceFactory allows you to create your service object when it’s first looked up, rather than when it’s first registered. If you want more control, then you can write your own ServiceFactory and then treat it like a normal Blueprint service. The Blueprint container is smart enough to delegate to your ServiceFactory when a service is needed. If you’re interested in writing a ServiceFactory, we suggest having a look at OSGi in Action (Hall et al., Manning Publications, 2011).
Constructor Arguments
So far, you’ve always used Blueprint beans with a no-argument constructor. But this is by no means required. Any number of <argument> elements may be used to pass arguments to a constructor. The order in the Blueprint file determines their order in the constructor. Arguments may even refer to other beans or services:
<bean
id="offer"
class="fancyfoods.fruit.BananaOffer">
<argument value="Bananas" />
<argument ref="anotherOffer" />
<argument value="5.42" />
<argument ref="time" />
</bean>
Factories
Although the easiest way of instantiating a Blueprint bean is by direct construction, this doesn’t always line up well with how the bean class works. In that case, factories can be defined instead. Factories can be used to drive any static method, even on code you don’t control.
The following snippet cunningly uses a bean factory to generate a timestamp. Notice the use of the prototype scope to ensure that the timestamp is regenerated each time, rather than once at application initialization:
<bean
id="time"
class="java.lang.System"
factory-method="currentTimeMillis"
scope="prototype"/>
Is construction all the initialization a bean will ever need? Sometimes yes, but sometimes beans need initialization in multiple phases.
6.3.5. Lifecycle callbacks
You’ve already seen in section 3.2.2 that it can sometimes be handy to do some bean initialization after all the properties have been set by specifying an init-method. (Constructors are also good at initializing objects. In some cases, init-methods can be avoided by passing everything to a constructor using <argument>s instead of relying on injected <property> elements.)
Blueprint also offers a destroy-method callback. The destroy-method is only supported for beans with singleton scope; beans with prototype scope must be destroyed by the application.
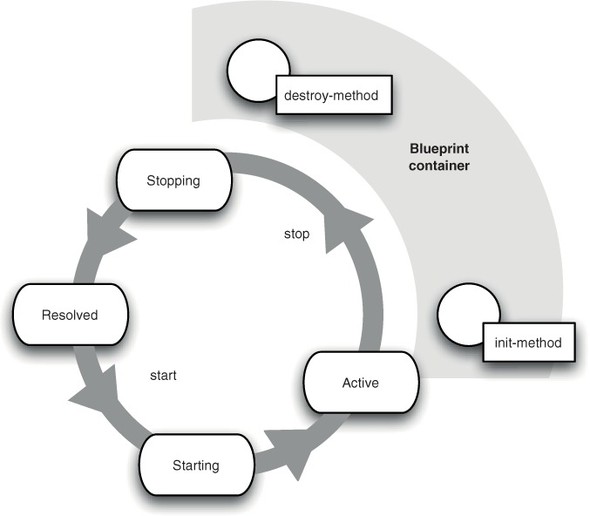
The destroy-method can be used to clean up resources used by the bean. Because singleton beans are only destroyed when a bundle is stopped, destroy-methods can also be used more generally for bundle-level cleanup (see figure 6.4).
Figure 6.4. The lifecycle of a bundle’s Blueprint container and Blueprint beans is closely tied to the bundle’s lifecycle. The init-method is called on eager singleton beans after the container is started; the destroy-method is called when the bundle is stopped.
Is Cleaning up in Destroy Methods Wise?
How much can you rely on destroy methods for resource cleanup? Some Java programmers have an instinctive twitchiness whenever the subject of callbacks for resource cleanup is mentioned. They remember the excitement they felt when they first learned about Java finalizers, and the creeping disillusionment that followed when they learned that JVMs don’t guarantee calling finalizers, because they don’t guarantee garbage collecting unused objects. Many JVMs optimize garbage collection times by doing everything they can to avoid collecting objects with potentially expensive finalize() methods.
Will you fall into the same trap if you rely on destroy methods? Yes and no. Your destroy methods will certainly be called by the Blueprint container, unlike a finalizer, but you should still exercise some caution in using them.
In particular, you should try to avoid calling other services (including injected services) in destroy methods. If your Blueprint bean is in the process of going away, there’s a chance that the system is shutting down or in some unstable state, and other services have already disappeared. If you try to use those services, you risk a long Blueprint timeout, and a ServiceUnavailableException at the end. In principle this should never happen, because the Blueprint specification requires that beans be destroyed in reverse dependency order. But this doesn’t help you when using services that aren’t managed by Blueprint. A bug in versions of Aries Blueprint below 0.4 also meant that calls to Blueprint-injected services in destroy methods were unreliable.
More fundamentally, a destroy method may not be the best place to do your cleanup. A destroy method will be called when a bundle is stopped, but after it’s been called you’re only guaranteed that your bean won’t be used by the Blueprint container, not by poorly written clients. Even ignoring this, if a resource is only used by a bean for a short period of time, a destroy method probably isn’t the best way of cleaning it up. For example, holding a file handle open for the whole life of a bean may not be ideal. On the other hand, if a resource is genuinely required for the lifespan of the bean (that is, until the bundle is stopped), a destroy method is an appropriate and safe way of cleaning up. However you tidy up, make sure that you correctly handle calls when tidy-up is complete, even if that’s by throwing an IllegalStateException.
There’s a further catch—destroy methods can only be declared for singleton scope beans. Even though destroy methods are a safe way of cleaning up resources, their utility is limited. If you were busily plotting to use destroy methods for all of your object cleanup, we’re afraid you’ll have to go back to the drawing board!
6.3.6. Service ranking
What happens when multiple services are registered, but a client requires only one? Services may have a service ranking specified when they’re registered:
<service
ref="specialOffer"
interface="fancyfoods.offers.SpecialOffer"
ranking="100"/>
When more than one service is available, the container will choose the highest-numbered service available.
6.3.7. Registering services under multiple interfaces
In the examples so far, you’ve always used only one interface for each service you’ve registered. But beans can be registered under multiple interfaces at the same time (as long as they implement those interfaces):
<service
ref="specialOffer">
<interfaces>
<value>fancyfoods.offers.SpecialOffer</value>
<value>fancyfoods.some.other.UsefulInterface</value>
</interfaces>
</service>
Blueprint can also reflectively determine the interfaces under which a service should be made available. In this case, it will be all the interfaces implemented by the bean:
<service
ref="specialOffer"
auto-export="interfaces"/>
6.4. Blueprint and service dynamism
As we’ve been working through enterprise OSGi programming, we’ve said several times that OSGi is a dynamic environment. You’ve even seen OSGi dynamism in action in chapters 2 and 3. Uninstalling a bundle fragment removed translations, and stopping and starting bundles made special offers appear and disappear. This dynamism is amazingly powerful and allows OSGi applications to do things that aren’t possible for conventional applications.
6.4.1. The remarkable appearing and disappearing services
What this dynamism means is that services can come and go at any time. It’s possible that a required service isn’t available when you need it. It’s possible that there’s more than one potential match for the service you need. It’s possible that a new service becomes available at runtime, or that a service you’re currently using goes away while you’re using it! Put like that, OSGi dynamism sounds scary. How can you write a solid program on quicksand?
Luckily, your application is only as dynamic as you want it to be. If you have good control over your application environment and have no need to add or remove services on the fly and no desire to upgrade your application without restarting everything, you can probably assume that a lot of the scenarios in figure 6.5 won’t apply to you.
Figure 6.5. It’s possible that (a) a required service isn’t available, (b) there’s more than one match for a required service or that a new service becomes available at runtime, or (c) a service that’s in use goes away.

Be careful, though—even relatively static applications aren’t completely free from OSGi dynamics. Even if your application never changes after it’s installed, there will be a period during server startup and shutdown when not every service is available to everyone who might want it. In general, the OSGi bundle start order is undefined, so your services may not appear in the order you expect.
The good news is that Blueprint insulates you from almost all of this uncertainty, both during bundle startup and later, during runtime.
Startup and Grace Period
When a bundle starts, there’s no guarantee that other bundles within the application that it requires have already been started. (The start order on your test system may end up being quite different from the start order on the customer’s production box.)
What happens when a bundle declares Blueprint beans that depend on services from other bundles, but those services aren’t there? Starting the bean anyway and hoping the services appear before the bean tries to use them would be rash. In this position, Blueprint allows a grace period for the required services to appear.
Each bundle that defines Blueprint components has its own Blueprint container. (This is probably at odds with your mental model, which may have a single Blueprint container for the whole system.) The Blueprint container for a bundle won’t start unless all the mandatory dependencies are available.
By default the Blueprint container will wait five minutes for all required services to appear. You may see messages relating to GRACE_PERIOD in the log during this time (see figure 6.6). If all the required services don’t appear, the container won’t start for the dependent bundle. You can change the duration of the grace period if you want things to fail more quickly, or even eliminate it entirely, but we can’t think of any good reasons why you’d want to do that!
Figure 6.6. The Blueprint container reporting that it’s waiting for a Blueprint dependency to become available

Warning: The Impact of One Missing Service
If any service dependency of a bundle can’t be satisfied, the Blueprint container won’t start. This can be hard to spot, because the bundle itself will reach the started state. No Blueprint container means no Blueprint services at all will be registered by that bundle, and there will be no managed Blueprint beans for the bundle. You may not have expected that a missing service dependency for one bean would prevent all your other beans from running. If you’re hitting problems in this area, consider declaring some of your service dependencies optional (see section 6.4.2) or dividing your bundle into smaller independent bundles. If you have several independent dependency networks in the same bundle, it may be a sign that you haven’t got the modularity right.
Blueprint also has an elegant way of handling services that appear, disappear, or change at runtime. Like the grace period, it’s a sophisticated variant of container-managed wait and hope. It’s a lot more robust than this description makes it sound, and it’s also more granular than the startup case. This is known as damping.
Damping
OSGi Blueprint aims to reduce the complexity of consuming OSGi services by performing service damping—rather than injecting a managed bean with a service, the Blueprint container injects a proxy. This means that if the service implementation needs to be replaced, then this can be performed transparently, without interrupting the normal operation of the bean. Figure 6.7 shows how a proxy allows the provider to be transparently swapped.
Figure 6.7. If the proxied implementation of a Blueprint-provided service becomes unavailable, the proxy will be transparently wired to another implementation.

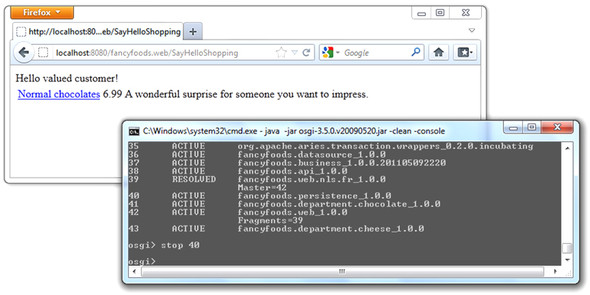
If no other implementation is available, any services registered by the consuming bean will automatically be unregistered. This management of dependency chains is one of the benefits of using Blueprint. You can see this behavior in action in the Fancy Foods application by stopping the persistence bundle. The Blueprint container will automatically unregister the desperate cheese special offer, because that special offer required the persistence service (see figure 6.8).
Figure 6.8. If the persistence bundle is stopped, the Blueprint container automatically makes the cheese special offer unavailable and removes it from the reference list in the offer aggregator. Subsequent requests won’t see the cheese offer.
The offer aggregator uses a reference list rather than a single reference. The cheese service is transparently removed from the aggregator list when it’s unregistered, and the aggregator service itself isn’t affected.
Timeouts
What happens if an attempt is made to use an injected service after it goes away? Nothing—literally! If a method is invoked on the service proxy, the proxy will block until a suitable service becomes available or until a timeout occurs. On timeout, a ServiceUnavailableException will be thrown.
In practice, timeouts don’t occur often, because the automatic unregistration of chained dependencies eliminates most opportunities to use nonexistent services. You can see this behavior in the Fancy Foods application if you try hard, but with a little tweaking you can make it happen much more often. What’s required is a bit of surgery so that you can stop a service before it’s been used, but after any services that depend on it have been invoked. What you’re trying to simulate here is a minor concurrency disaster, rather than normal operation.
The code you need to modify is in the cheese department of your application. You’ll modify the getOfferFood() method on the DesperateCheeseOffer to insert a pause so that you can reliably stop the persistence bundle in the middle of the method execution:
public Food getOfferFood() {
long start = System.currentTimeMillis();
System.out.println("INVOKED, PAUSING, STOP THAT BUNDLE!");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
}
System.out.println("RESUMING after "
+ (System.currentTimeMillis() - start) + " ms");
List<Food> cheeses =
inventory.getFoodsWhoseNameContains("cheese", 1);
System.out.println("Cheese returned after "
+ (System.currentTimeMillis() - start) + " ms.");
Food leastPopularCheese = cheeses.get(0);//
return leastPopularCheese;
Rebuild the cheese bundle, and drop it into the load directory. Also update the OfferAggregator to disable the sorting of the offer list for the moment (so that you get the persistence call at the right time) and rebuild the business bundle. Hit the web page, and then stop the persistence bundle when you see your first message appearing in the console. You’ll see that instead of returning after the five-second pause you introduced, the load request on the web page hasn’t returned. What’s going on? The call on the inventory object will block until a persistence provider becomes available again, or until the Blueprint timeout happens after five minutes (see figure 6.9).
Figure 6.9. If a Blueprint service is unregistered after services that depend on it have been invoked, the proxy to the service will block for five minutes before throwing a ServiceUnavailableException.

The nice thing about the Blueprint damping is that the disappearance of a service need not be fatal. If you restart the persistence bundle before the five-minute timeout expires, the cheese offer will miraculously kick back into life. But you may get more than you bargained for, as figure 6.10 shows.
Figure 6.10. If a proxied service reappears after disappearing, blocked service calls will resume and complete almost normally. But dependent services will be removed and reregistered, which could allow iterators to traverse them twice.
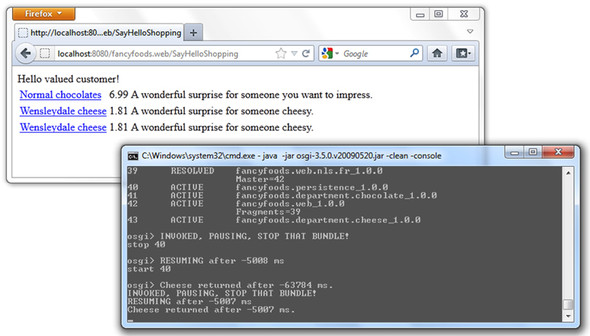
What’s going on? You certainly didn’t expect that the removal of the cheese offer service would give you two cheese offers.
The list of offers is injected into the OfferAggregator, which passes a reference to the same list to the servlet. When the servlet starts iterating over the list, there are two elements in the list. It requests the details for the chocolate offer, and then it requests the details for the cheese offer, which is where you disable the persistence bundle, causing the cheese offer to block when asked for its details. Re-enabling the persistence bundle unblocks the call and allows the servlet to see the details of the cheese offer. Meanwhile, however, the cheese offer has been removed from the aggregator’s reference list and then added back to it. When the iterator finishes printing out the details of the cheese offer, it checks to see if there are any more offers, and discovers that a new offer has been added to the list—a cheese offer, apparently. At the end of the procedure, the reference list still only has two offers, cheese and chocolate, but if the timing is right (or you insert lots of pauses, as we did!), an unlucky iterator could see both the old and new occurrences of the cheese offer.
In this case, the only consequence of a potentially disastrous outage of the persistence bundle is that the cheese offer is included twice in the printed list of offers. It looks a bit stupid, but there’s no harm done. If iterating over the same service twice is more serious, you may want to consider making unmodifiable copies of reference lists before passing them around or iterating over them.
In our opinion, this is incredibly cool. We must be honest, though, and disclose that it took a few tries to get the right pictures! If you expect to support these extreme dynamics in your application, it’s important that you test properly. As you’ve seen, hanging on to references to services that might have been compromised can cause problems (an offer appearing twice). In this case, you might see problems if there were multiple calls to getOfferFood() from the web frontend that returned different answers. If you make sure to synchronize access to your sorted list (and return a copy to the web layer), you should avoid any concurrent modification problems. One more issue is that if the web frontend holds on to the returned instance from getOfferFood(), then it could end up using a stale service.
Setting timeouts
The default Blueprint timeout is five minutes, but it can be adjusted per bundle or per reference. For example, the following update to the Inventory reference ensures that method invocations never block for more than two seconds, even when no Inventory service is available:
<reference
id="inventory"
interface="fancyfoods.food.Inventory"
timeout="2000" />
Timeouts can also be set for an entire bundle in the manifest by setting directives on the symbolic name:
Bundle-SymbolicName: fancyfoods.persistence; blueprint.timeout:=2000
If the timeout is set to 0, a service invocation will block indefinitely.
6.4.2. Multiplicity and optionality
Part of the power of Blueprint services is that you can easily tune how many instances are injected (multiplicity), and what happens if none at all are available (optionality).
Optional Service References
When declaring a Blueprint service reference, one of the things you can do is declare that it’s optional:
<reference
id="specialOffer"
interface="fancyfoods.offers.SpecialOffer"
availability="optional"/>
This means that if no satisfactory service can be found, the Blueprint container will still start up and initialize the rest of your beans. This is useful; you often don’t want a single missing service to be fatal. But what happens if you try to use an unsatisfied optional service?
Service Damping and Optional References
As it happens, after the Blueprint container has been initialized for a bundle, optional services are indistinguishable from mandatory services. Even if the backing service goes away—or was never there—any method invocation on the injected service (which is a proxy, remember) will block until the service reappears or until a timeout happens. Whether your service is optional or mandatory, you’ll need to remember that a timeout could occur and a ServiceUnavailableException could be thrown.
A service being unavailable is arguably much more likely if the service was optional in the first place, and so using your optional services as if they were mandatory services may lead to some long delays. How can you handle missing services gracefully? One option is to set a short timeout and catch the ServiceUnavailableException. A cleaner option is to use a reference listener to monitor the lifecycle of the service (more on those in a moment). Alternatively, the sneakily lazy option is to use a reference list instead of a reference for your service.
So far we’ve been talking about how damping works for service references. Reference lists are subtly different from references in how they handle dynamism, and sometimes this difference comes in handy.
References and Reference Lists
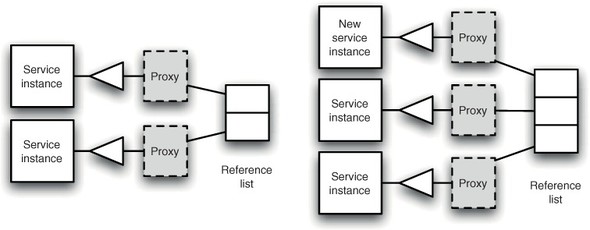
A reference refers to one, and only one, instance of a service. Reference lists, on the other hand, refer to several instances of a service. Although reference lists still use proxies, they make it much more apparent when services come and go. As services appear and disappear from the system, they’ll pop in and out of a reference list (see figure 6.11). A reference list will never contain entries for services that are unavailable. So dynamic is the reference list, services can even appear in an existing iterator. (No ConcurrentModificationExceptions here!)
Figure 6.11. As services appear and disappear in a system, they’re automatically added to or removed from reference lists.
How does this help with optional services? If you use an optional reference list rather than an optional reference to inject a service, then the service’s absence still won’t prevent the bundle’s Blueprint container from starting. The key difference is that if a service arrives and then goes away again, you’ll find a zero-length list rather than a long wait and a ServiceUnavailableException.
Coping with multiplicity
On the other hand, if you use a reference list, you may get more than you bargained for. What will you do if multiple instances of a service are present? You could decide you want to call all the services in the list, but on the other hand you may never want more than one service. If you do only want to call one service, then which service do you call? Will the first service be the most appropriate one?
It turns out that this is an issue that affects you even if you’re using references instead of reference lists. With references, the container will choose the service for you, but how does it decide which service to pick?
One strategy for ensuring you get supplied with the most suitable service is to specify a ranking for each service. (We showed you how to do this in section 6.3.6.) The downside here is that the ranking must be specified at the time the service is registered by the service provider. If that’s not you, you’ll have some work to do persuading all your dependencies to rank themselves. More seriously, what should the ranking even be? Can you be sure that every consumer of the services will agree on the same relative ranking? Should a faster service implementation be ranked highest, or a more reliable one? Sometimes a clear ranking of services is possible—for example if one service wraps another one and is intended to supersede it—but more often, different services are...different.
Although it’s usually easy to distinguish services, it’s also worth remembering that a well-designed application shouldn’t normally need to. If you’ve done things right, then any service in the list should be up to the job.
Sometimes the differences between services can be an issue; happily, these differences can be expressed using service properties. You can identify your service precisely by adding specific service properties to it. As it does for other parts of the service API, Blueprint offers some handy XML for adding properties to a service:

When you have some service properties to pick from, you can tie down your choice of service tightly by using a service filter in your Blueprint XML. Filters can be used to pick services with certain properties:
<reference interface="fancyfoods.offers.SpecialOffer"
filter="(magic.number=42)"/>
If you want to lock down your service usage completely you could even set the implementation name as a service property and filter on it. This drastically increases coupling between bundles and we definitely don’t recommend it! The risk of this strategy is that if no available service satisfies your filter, you’ll be left with none at all. The more specific your filter, the greater the risk. In general, you should choose service properties that express something about the contract the service satisfies (for example, is.transactional=true), rather than ones that are unique to one particular service (such as vendor=SomeCorp). Filters are extremely powerful and use the full range of syntax allowed by the LDAP filter specification. If you’re keen to use filters in your application, then there’s more information about them in appendix A, but we find that we don’t usually need them in our applications.
Being flexible about what service gets used can feel uncomfortable at first. How can you possibly test your code (it’s possible—wait until chapter 8)? What happens if the provided service turns out to be terrible? What if it doesn’t do what you need? Nonetheless, it’s best to trust the application deployer and leave the decision about what service gets used to deploy time, rather than trying to specify everything at development time. It can be hard to give up control, but being service-oriented and loosely coupled means—well, just that!
Services and State
Holding much state in services presents some problems. An injected service may be transparently swapped for another implementation if the original service goes away, or if a higher-ranked service comes along. More fundamentally, a bundle can be restarted or upgraded at any time, which destroys state. Persisting data is so easy that you should consider using a persistence bundle or data grid to ensure that information survives.
If it’s absolutely essential that your services store state, all isn’t lost. After all, in many realistic application environments the system is, by design, stable—services won’t be dynamically swapped out or bundles arbitrarily bounced, even though such things are possible in principle.
As a starting point, you’ll almost certainly want to use the prototype scope for beans that represent stateful services, rather than the singleton scope. The prototype scope ensures each bundle that uses the service gets its own instance (though a bundle will get the same instance if it does more than one lookup). Don’t forget that using prototype scope can have scalability implications.
The prototype scope ensures no service instance is being used by more than one bundle, but it doesn’t solve the problem of more than one service instance being used by the same bundle. Ultimately, even in a relatively stable system, nothing can stop a service instance from going away if an unexpected catastrophe occurs. (We’ve been imagining a mischievous cat sneaking into the ops center and walking all over the keyboard, disabling parts of the system, but feel free to invent your own entertaining mental pictures!)
If you’re programming defensively, you’ll protect yourself against the disappearance of stateful services, even if such things are extremely unlikely. (The system is stable, maintenance is done in scheduled downtime windows, and you keep a dog in the ops center.) Nothing can get the stateful service back after it’s gone, but as long as you can detect the disappearance, you can initiate data recovery procedures or throw an exception to indicate a catastrophic event.
Both the core OSGi programming model and Blueprint allow you to closely monitor the lifecycle of services. Not only does this allow you to be confident that your stateful services aren’t disappearing, it has a variety of other uses, particularly for services that are optional.
OSGi services don’t fit well with the stateful model. The default usage pattern has only a single service instance for the whole framework, and even if you use a ServiceFactory, you still only get one instance per client bundle. Added to this, services have to be thread safe, which becomes much more difficult if they have state. All in all, we recommend steering clear of stateful services if you can, but it’s perfectly possible to use them if you’re careful.
6.4.3. Monitoring the lifecycle
Closely monitoring what’s going on with the services you care about is a convenient way of handling optional services and service multiplicity.
If a service has been declared optional, how do you know if it’s there and safe to use or not? If you have a reference list, how can you know when things magically get added or removed? If you’re interested, you can register service listeners that are notified when services are registered or unregistered. (If you’re not using Blueprint, you have to care when these things happen. With Blueprint, caring is optional!)
Reference Listeners
Reference listeners have a number of potential uses, but you’ll start with a straightforward case—caching. For example, in the Fancy Foods application, the current implementation of the offer aggregator re-sorts the offer list every time a request is made (listing 2.11). Users are likely to hit the offer page far more often than the Fancy Foods business updates its special offers, so caching the sorted list is a performance optimization.
The code changes to use a cache instead of recalculating the sorted list are straightforward:
private synchronized void sortOfferList() {
if (offers != null) {
sortedOffers = new ArrayList<SpecialOffer>(offers);
Collections.sort(sortedOffers, new OfferComparator());
int offerCount = Math.min(MAX_OFFERS, sortedOffers.size());
sortedOffers = sortedOffers.subList(0, offerCount);
}
}
@Override
public synchronized List<SpecialOffer> getCurrentOffers() {
return new ArrayList(sortedOffers);
}
The challenge is to know when the cache should be updated, and this is where the reference listeners come in. Registering a reference listener ensures the OfferAggregator bean is notified every time an offer is added to or removed from the list. To register the reference listener, a <reference-listener> declaration is added as a child of the <reference> or <reference-list> element from listing 2.10:
<reference-list
id="specialOffers"
interface="fancyfoods.offers.SpecialOffer">
<reference-listener
ref="offerAggregator"
bind-method="bind"
unbind-method="unbind" />
</reference-list>
The reference listener need not be the same as the bean that uses the services. It can even be a completely new bean declared with an inlined <bean> element, although in that case the bean will always have a singleton scope.
The bind method is only called if the new service is consumed by the bean. In the case of a reference list, this is every time a matching service is added to the Service Registry. When a reference is used, on the other hand, the consumed service will only be changed (and the bind method called) if the new service has a higher service ranking than the existing one.
The bind method for the offer aggregator is simple; when something gets added to the list, the cache should be updated. If you’re interested in the service properties, your bind and unbind methods can also be written to take an optional Map that lists all of the service properties:
public void bind(SpecialOffer offer) {
sortOfferList();
}
The bind method is called after the new service has been added to the list, so the sorted list will be accurate. The unbind method, on the other hand, is called before the reference is removed. Calling the method to re-sort the offer list and update the cache in the unbind method isn’t much use, because it’s the old list that will be sorted. Instead, you’ll need to get your hands dirty and remove the obsolete offer from the cache manually:
public synchronized void unbind(SpecialOffer offer) {
if (sortedOffers != null) {
sortedOffers.remove(offer);
}
}
Warning: Proxying Objects
One side effect of the proxying of services is that you’ll find that the service you get injected with isn’t == to the service in the Service Registry, even though you might expect it to be. The proxied object may not even be of the same type as the real service object! Rest assured, if you’ve implemented equals() and hashCode() on your service, then the proxy code does the correct unwrapping to make sure that they work properly.
Somewhat unfortunately, a bug in the early releases of the Aries proxy code (prior to 0.4) sometimes fails to do this unwrapping if your service uses the default version of equals().
If you’re using version 0.4 or higher, then there’s nothing that you need to do. If, on the other hand, you’re using, or might need to use, an older version of the proxy bundle and are relying on default equality, you’ll need to provide your own implementation of equals() and hashCode()—adding these also documents the fact that you rely on the default behavior for anyone else maintaining your code, which is a good thing too.
You’ve got one little change to make for your cache to work. Remember that OSGi is dynamic (we might have mentioned that once or twice already!). Bundle startup order isn’t deterministic, and so the collection of references may be populated before it’s injected into the OfferAggregator, or after. If the list is populated first, then the bind() method will be called when the offers field is still null. You’ve guarded against this in the sortOffersList() method, so there’s no risk of a NullPointerException from the bind() method. But there’s a risk the sortedOffers field will never be initialized at all, if all the bind() calls happen before the injection. Luckily, there’s an easy solution, which is to ensure you also sort when the offers are injected:
public void setOffers(List<SpecialOffer> offers) {
this.offers = offers;
sortOfferList();
}
If you build the updated bundle and drop it into your load directory, you should find that everything works as it did before. You can test your caching by using the OSGi console to stop and start the chocolate and cheese bundles. If you’ve got things right, your stopped services will continue to appear and disappear appropriately from your web page when you refresh it.
Other uses for monitoring
Caching is a nice use for reference listeners, but it’s not the only one. In the case of our example, when new special offers appear, they could be highlighted or bumped to the top of an otherwise sorted list. Reference listeners can also act as a fail-safe when using stateful services, as we discussed earlier. Finally, reference listeners allow you to avoid calling a service that has gone away and blocking in the proxy, or to disable parts of your application if a service goes away.
Warning: Detecting Service Swaps
If you’re planning to use reference listeners to detect when an injected service has been swapped out (for example, to reconstitute a stateful service), be careful. If you’re using a reference, the bind-method and the unbind-method aren’t symmetric. The bind-method will be called every time a new service is bound—every time the service changes. But the unbind-method will only be called if a service goes away and can’t immediately be replaced—if your bean is left without a service. Only the bind-method, therefore, can be reliably used to detect when the service has changed, whereas the unbind-method is most useful to detect periods of service unavailability.
Registration Listeners
Usually, when services appear and disappear, it’s the users of the service that need to be notified. But the services themselves can be notified of their registration and unregistration using a registration listener. Remember that a service being registered is a necessary prerequisite for anyone to be able to consume it, but it’s not the same thing as it being consumed. Just because a service is registered doesn’t mean it’s used by someone, or ever will be.
Why would you want to know if a service has been registered and unregistered? Notification of unregistration has a clear use case for teardown and tidy-up. An unregistration listener can serve the same function as a Java finalizer, but without the issues of finalizers.
There are fewer uses for service registration listeners, but they can sometimes be useful for initialization. If nothing else, they’re handy for tracing the dynamics of your system!
6.5. Summary
OSGi services are sometimes described as a replacement for conventional Java factories. You’ve seen in this chapter that services can do an awful lot of things that factories can’t—they can come and go, they can be managed at runtime, they can be filtered using properties, and they form the basis of a handy pattern for handling event notifications.
The dynamism of OSGi services isn’t without its downside; in their raw form, registering them is a little verbose, and accessing them, if done in a safe way, is extremely verbose. Blueprint and other dependency injection frameworks neatly eliminate these issues. They make providing services easy and insulate applications from the dynamism of services. Perhaps most conveniently, Blueprint manages dependency chains so that services (and ordinary Blueprint beans) only become available when all their dependencies are present; if services go away, the services that depend on them are automatically unregistered.