
Chapter 11. Migration and integration
This chapter covers
- How to access non-OSGi code from within an OSGi framework
- How to migrate Java EE web applications into OSGi
- How Apache Aries can be used to run EJB modules
In this book, we’ve been looking at how to write OSGi applications from scratch. This is fun, and also useful to know how to do, but it isn’t usually the case that you can begin a brand new project with no existing code. Normally, you’ll have application code to bring with you, either code that needs to be migrated into OSGi as part of your project, or external services that you need to be able to use from within the OSGi framework. Having to bring these sorts of things with you often results in a sinking feeling, particularly if the code has to keep working in more than one environment.
We’re happy to tell you that migrating to OSGi is almost certainly not as hard as you think, and that there are a number of helpful OSGi tools and specifications that make these sorts of requirements possible.
When writing any enterprise application that’s going to be put into production, one of the main tasks is usually to integrate with an existing system or service. It’s unlikely that this service is OSGi-based, and there’s a decent chance that it isn’t even using Java. Regardless of how the backend service is implemented, there are techniques you can use.
11.1. Managing heterogeneous applications
We introduced you to SCA as a remoting technology for OSGi in section 10.6, but SCA is capable of much more than connecting two OSGi frameworks. Connecting one OSGi service to another is only a fraction of what SCA can do.
In an ideal world, your entire enterprise architecture would be based on a single technology, and that technology would—naturally—be OSGi-based. You would use remote services to hook together the disconnected parts of your system. In practice, we’ve never seen such an architecture, or at least not in an organization that had more than a few developers, or one or two years of history. Although technologies continue to evolve, old applications and systems based on old technologies can be stubborn in refusing to go away. One truly impressive example we’ve seen of this had a COBOL program providing information to a Python script, spanning nearly 50 years of application development! Even applications developed at the same time by different teams may be based on wildly varying technologies because of different development styles or skill sets within the teams.
It’s worse than that, though—even applications developed at the same time within the same team may need to pick and choose capabilities from various technologies. Although it pains us to admit it in a book on enterprise OSGi, no single programming model can handle all requirements. Being able to stitch together applications that exploit the best capabilities of multiple technologies is clearly desirable.
How can these heterogeneous applications be managed and integrated? Are they doomed to remain in technology-specific silos, or is there a way of breaching the technology boundaries and moving operations and data between systems and across programming models? Over the years, there have been a number of attempts at integration technologies, but in recent years efforts have focused on service-oriented architecture (SOA) and the Service Component Architecture (SCA) technology. A different but related approach uses an Enterprise Service Bus (ESB) as an integration container to manage communication between disparate system components.
11.1.1. Using SCA to integrate heterogeneous systems
In section 10.6, we showed how to use web services bindings to connect two OSGi components together. SCA offers a range of bindings, so why web services? Part of the reason is that web services is a popular way to integrate distributed or heterogeneous applications. More pragmatically, web services is one of the few SCA bindings that are easy to get up and running on your little stack; Apache Aries isn’t intended to be an application server, and the little sample assemblies don’t include Java EE functionality like EJBs, CORBA, or JMS runtimes.
Assuming you’re running with more application server support, what other bindings are available, and what else can SCA do for you in a heterogeneous environment?
At a high level, an SCA system consists of components and bindings. Components are functional elements; bindings allow components to communicate with one another. In general, components and bindings are mix-and-match, allowing business logic to be neatly separated from communication protocols (see figure 11.1).
Figure 11.1. SCA systems consist of components connected by bindings.
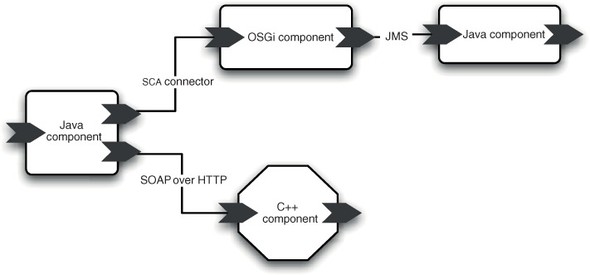
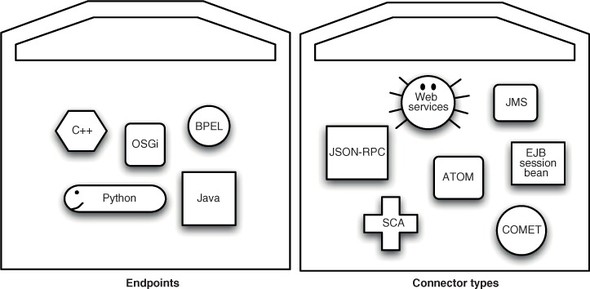
SCA allows a range of component types and bindings. We’ve already seen the OSGi component type in section 10.6 (where it was cunningly disguised as an implementation of the Remote Services Specification). Other component types include the SCA Java component type, whose components resemble normal Java classes with some SCA-specific annotations, the BPEL component type, a Spring component type, and even C++ and Python component types. These components can be bound together using web services, JMS, EJB protocols, Comet, ATOM, JSON-RPC, or a default SCA communication binding (see figure 11.2).
Figure 11.2. SCA provides a toolkit of component types and a toolkit of connectors that can be mixed and matched to bind endpoints together. The component types and bindings we show here aren’t an exhaustive list, not least because SCA is extensible.
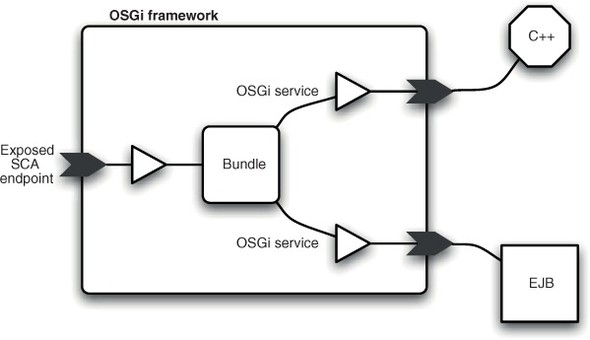
Most of the SCA bindings, like web services, aren’t SCA-specific, and this allows SCA-based applications to communicate with external applications that haven’t even heard of SCA. For example, anything that can drive a web service can communicate with an SCA component that exposes a web services binding. They also allow an SCA component—such as an OSGi service—to communicate transparently with external services with no awareness either of OSGi or of SCA (see figure 11.3).
Figure 11.3. SCA bindings are exposed to OSGi applications as services, which means non-SCA-aware OSGi applications can communicate with non-SCA-aware applications of other types by consuming normal OSGi services.
Integrating with an EJB
SCA allows OSGi services to interact with EJBs. Although EJBs might seem like a component type, they’re a binding. One way of thinking of this is that EJBs have a language (or communication protocol) and the SCA EJB binding provides a translation layer that allows things that aren’t EJBs to communicate with EJBs.
Hooking an OSGi service up to an EJB is therefore as simple as replacing the web services binding in the food-config.xml configuration file (listing 10.8) with an equivalent EJB binding, as shown in the following code:
<sca:binding.ejb
name="ForeignFood"
uri="corbaname:iiop@localhost:4201#ForeignFoodFacadeBeanRemote" />
Assuming you have an EJB with the right name listening on the configured port, it will be accessible as an OSGi service inside the OSGi framework.
Integrating with JMS
Accessing an external JMS queue is similarly transparent. The binding for a JMS queue called (for example) FoodQueue is as follows:
<sca:binding.jms
uri="jms:FoodQueue" />
By default, a method called onMessage is called on the bound component, but if the component only has one method, then that will be called instead. Properties specifying the method to call can also be added to incoming messages.
Although it’s another binding, in practice the JMS binding has some different characteristics from the web services and EJB bindings, and you may end up thinking about the asynchronous nature of the JMS binding when you’re designing your component. For example, you may want to specify callbacks in your component definition to allow two-way communication. If you’re connecting to an external queue, you may need to adjust the message format used by SCA to align with what’s already in place. You can specify the wire format, extra headers, and operation properties. You can also use message selectors to filter incoming messages.
SCA is an extremely powerful and versatile technology for enterprise OSGi integration. After reading this section and section 10.6, you may be reeling slightly at how versatile SCA is and how many possibilities there are. It’s a big topic, so we can only skim the surface of it here. If you’re interested in learning more, we recommend Tuscany SCA in Action by Simon Laws, Mark Combellack, Raymond Feng, Haleh Mahbod, and Simon Nash (Manning, 2011).
But wait—there are even more possibilities to consider. Not only is there more than one way of integrating your application using SCA, there’s a range of technologies beyond SCA that can be used for integration. Apache CXF, which worked so well as a remote services implementation in section 10.4, is intended to be a more general integration platform. Like SCA, it supports a range of component implementations and standardized communications protocols, such as web services, and JMS. CXF itself is a product supporting a range of standards, rather than a standard supported by a number of products, as SCA is. The primary orientation of CXF is web services, so it supports fewer languages and communication protocols than SCA.
11.1.2. Integrating using an ESB
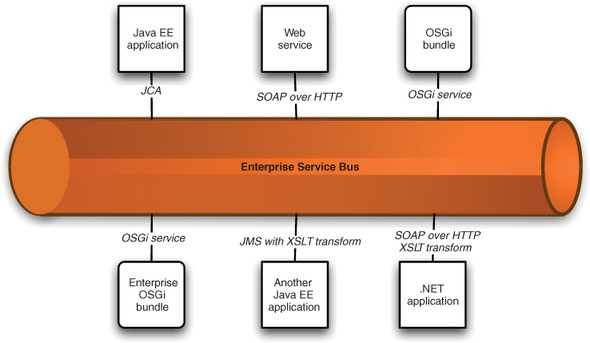
A range of other integration technologies is available that falls into the general category of Enterprise Service Buses, or ESBs. As the name suggests, ESBs are intended to provide an adaptable asynchronous communications channel between loosely coupled enterprise components. Mediations allow conversions between a range of message formats and wire protocols (see figure 11.4).
Figure 11.4. An ESB acts as a common transport channel loosely connecting diverse endpoints. Communications may be mediated with XSLT transforms or other adjustments to the content.
ESBs and SCA are designed to address similar problems—how can a technologically diverse set of applications be knit together into a functioning system without lots of hand-cranking and manual gluing? Importantly, though, an ESB is an architectural pattern, rather than a specific standard like SCA. As a technology, ESBs predate SCA, and many established ESBs started making use of SCA in some form or another after its introduction. Some ESBs are based on SCA, whereas others support SCA components as another type of deployable artifact.
Whether you choose to use an ESB or SCA will probably be determined by what technologies you’re already using. SCA usually has a lower initial cost for connecting together two specific things, but an ESB may have lower long-term costs because it’s a more general-purpose solution to an infrastructure problem.
A number of ESB providers use OSGi for their internal architecture. But fewer of these ESBs include support for user’s OSGi bundles, and fewer still include enterprise OSGi support in their runtime. But you do have some choices if you want to use your enterprise OSGi application with an ESB.
Apache Servicemix
The most comprehensive enterprise OSGi support is arguably provided by Apache ServiceMix. ServiceMix provides native hosting for your OSGi bundles and built-in Blueprint support, based on Apache Aries. Some nice extensions mean Blueprint can even be used to configure the message routing.
Fuse ESB
Closely related to ServiceMix is Fuse ESB, a productized offering of ServiceMix. Fuse ESB is still open source, but commercial support subscriptions are available.
Apache Karaf Plus Apache Camel
ServiceMix is based on a combination of Apache Karaf and Apache Camel, with features to handle security, registries, and extra configuration. Some users find they don’t need this extra function, and the lighter combination of Karaf and Camel works well for them. You’ve already seen Karaf as a testing environment in section 8.3.4, and we’ll be coming back to it as a production environment in section 13.2. Camel is a router. Karaf on its own certainly isn’t an ESB, and Camel on its own doesn’t offer OSGi support, but in combination they make a nice little integration platform. Camel provides Karaf with features that allow it to be easily installed into a Karaf instance, although you may need to adjust the JRE properties and OSGi boot delegation in some cases.
This completes our tour of SCA and ESBs. Talking to external services isn’t the only problem you face when trying to start using enterprise OSGi. What do you do with existing Java EE artifacts if you want to use them in your application?
11.2. Migrating from Java EE
Java EE is an enormously popular and successful programming model for enterprise applications. If you picked up this book as someone with Java EE experience, you might have skipped ahead to this section. If so, we recommend cooling your jets and taking a step back to some of the earlier content in this book. Migrating Java EE applications to OSGi can be surprisingly easy, but it helps to have a good understanding of OSGi fundamentals before you start. If you try to migrate an application without that understanding, then things may seem confusing, but for those of you who have read chapters 2 and 3, you may find that this section reinforces what you thought already.
Java EE offers a huge range of support and integration points for many different enterprise technologies, so huge that there are few applications that use it all. Most applications stick to a small subset of the Java EE programming model. Recognizing this, in Java EE 6 the Java Community decided to allow the Java EE specifications to be grouped into profiles offering a reduced set of functions. The first profile introduced is known as the Web profile and unsurprisingly focuses on Java EE web applications (WARs) and the technologies most commonly used with them.
Having identified WARs as the most commonly used Java EE module type, it makes sense to start by looking at how you can migrate a Java EE WAR file into the OSGi container.
11.2.1. Moving from WARs to WABs
Unless you’ve skipped the majority of this book, you’ll certainly have been introduced to the concept of the OSGi WAB. A WAB, or Web Application Bundle, is defined by the Web Applications Specification from the OSGi Enterprise Expert Group and is, by design, a close partner of the Java EE WAR. One of the key requirements for OSGi’s Web Applications Specification was that it must be possible to write any WAB such that it’s also a valid WAR file.
The wonderful thing about this requirement is that it not only dramatically simplifies the description of a WAB file, but that it also makes it trivial to migrate most Java EE WARs. Structurally, there’s no real difference between a WAB and a WAR file. Both expect the web deployment descriptor (web.xml to you and me) to be located in WEB-INF and to be called web.xml, and expect to find servlet classes on the internal classpath of the web application. As a result, you don’t need to change your WAR’s internal structure at all!
The only important detail that separates a WAB from a WAR is that it has OSGi metadata in its manifest that makes it an OSGi bundle. By including this metadata, most standalone WARs can be converted into working WABs with no other changes at all!
Creating OSGI Metadata for a War
All Java manifest files must declare the version of the manifest syntax that they use. To make a valid OSGi bundle, there are two more required headers, a Bundle-Manifest-Version with a value of 2, and a Bundle-SymbolicName that defines the bundle’s name. Because a WAB is a bundle, it also needs these two headers, but it must also add a third that identifies it as a WAB. This is the Web-ContextPath header, which not only identifies the bundle as a WAB, but also defines a default context root (base URL) from which the web application should be served. Although versioning your bundle isn’t strictly required, we would never build a bundle without versioning it properly, and would urge you not to either (for more information about why, see section 5.1.1).
The result of this is that the smallest possible WAB manifest looks something like the following listing.
Listing 11.1. A minimal WAB manifest
Manifest-Version: 1 Bundle-ManifestVersion: 2 Bundle-SymbolicName: my.simple.wab Bundle-Version: 1.0.0 Web-ContextPath: /contextRoot
Coping with the War Classpath
It’s clearly easy to provide enough metadata to get OSGi to recognize a WAR file as an OSGi WAB, but this isn’t enough to make the WAR file work as a WAB. One of the most critical differences is surprisingly easy to overlook: the internal structure of the WAR file itself!
Changing the extension of a Java EE module from .jar to .war has a much more extensive effect on the module than changing its name. WAR files have an internal classpath that’s different from normal JAR files. In a WAR, the servlet classes are supposed to live in WEB-INF/classes, not the root of the WAR (which is used for noncode resources). Furthermore, library JARs can be included inside a WAR file; any file with a .jar extension in the WEB-INF/lib folder of your WAR is implicitly added to the internal classpath (see figure 11.5).
Figure 11.5. A typical WAR layout
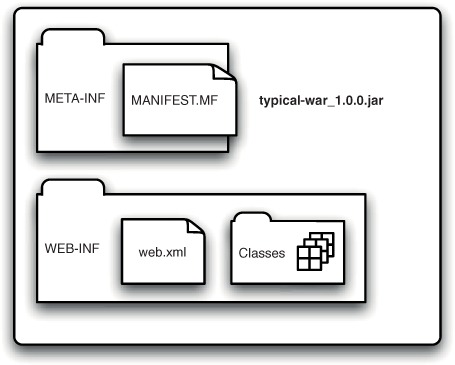
One of the best things you can do to help turn your WAR into a WAB is to remember that the internal classpath of an OSGi bundle is (by default) like a normal JAR. This means that you have some work to do to allow OSGi to find your classes! You have two options: you can either adjust the structure of your WAR to match a standard JAR layout, or you can adjust the classpath of your OSGi bundle to match the layout of your WAR. The latter approach has several advantages: it’s less invasive, less error-prone, more easily understandable for WAR developers, and, most critically, it allows the WAR to continue being used as a WAR and as a WAB!
Changing the default internal classpath of an OSGi bundle can be easily achieved using the Bundle-ClassPath header. This takes a comma-separated list of classpath locations, which can either be folders or JAR files, that are specified relative to the root of the bundle. If you were trying to make the WAR from figure 11.5 work in OSGi, then you would need to set the classpath as follows:
Bundle-ClassPath: WEB-INF/classes, WEB-INF/lib/myLib.jar, WEB-INF/lib/secondLib.jar
When your WAR has correctly specified its internal OSGi classpath, then you’re much closer to being able to get it running. In the majority of cases, you still won’t be able to load any of your classes. The internal classpath of a bundle is only a small part of the story.
Finishing Off Your OSGI Metadata
The key piece of information missing from your WAR is the most fundamental part of making your WAR into an OSGi bundle; it’s the modularity statement, the set of packages that you want to import. Some of the packages that need to be imported are obvious; for example, we would wager that your WAR needs to import javax.servlet and javax.servlet.http.
Over the life of the Java EE specifications, there have been a number of versions of the Servlet Specification. The OSGi Web Applications Specification defines support for version 2.5 of the Servlet Specification. As a result, you shouldn’t rely on being able to migrate Servlet 3.0 applications to an arbitrary OSGi web container. On the other hand, the OSGi Web Applications Specification does allow for implementations to support Servlet 3.0 applications. If you do need to use Servlet 3.0 in your application, then make sure that your container supports it, and also remember that the correct semantic version for the Servlet 3.0 package is 2.6.
Working out what other imports your WAR needs can be simple, or it can be difficult; it depends completely on how complex your WAR file is. You may need to add imports for packages used in your servlets, but it’s also possible that you may not, if the code is supplied by a JAR in WEB-INF/lib. There may even be some dependencies needed by the library JARs in WEB-INF/lib! If your dependencies are nontrivial, then you can use trial and error to find out what packages you need, but there are also tools that offer smarter ways to approach this. Because most portable WARs have few dependencies (other than on the servlet API), we’ll leave discussing these tools in detail until section 12.1.3.
Another approach you can use to get WAR files running in an OSGi framework is the webbundle URL scheme. The OSGi Web Applications Specification defines a URL handler for URLs that start with webbundle:. If you install a bundle using this URL, then the WAR file it points at will be automatically converted into a WAB. The webbundle URL scheme is a compound URL, so the first thing after the webbundle: is the real URL to the WAR. After this part of the URL, you can add one or more parameters using URL query syntax. These parameters can be used to configure manifest headers for things like the WAB context root, as in the following example:
webbundle:file://myFolder/myWarFile.war?Web-ContextPath=myContextRoot
Although the webbundle URL scheme might seem like an easy option for using a WAB in OSGi, we wouldn’t recommend it as a primary option. The reason for this is simple. You never get an OSGi bundle! Having installed your WAR using the webbundle URL scheme, you never get access to the generated WAB. This makes the WAB hard to debug and hard to reuse.
Evolving Better Modularity
You may remember that back in section 5.3.1 we recommended avoiding library JARs in OSGi WABs. The main reason for this is that it reduces the degree to which you can share classes and bundles in the runtime. If you’re bringing a WAR into OSGi, then you’re likely to have libraries inside it. We don’t think it’s reasonable to ask you to completely remove all of these library JARs immediately, which is why we added them to the bundle classpath. If the WAR file is going to be really modular, then you shouldn’t be packaging JARs inside it.
What you can do is to break out the library JARs one at a time. Removing a library from the WAB will require you to add some more package imports to the WAB (unless the JAR wasn’t being used), but it will allow other bundles to share the same library instance, reducing the memory footprint. In some cases, you may find that the library you’re using isn’t available as an OSGi bundle. In this case, you can either leave the library in your WAB or use the information in section 12.1 to help you obtain an OSGi-bundled version.
Following these guidelines should allow you to migrate any WAR file to OSGi, but WAR files are only one part of the Java EE specification. What do you do with some of the other types of modules?
11.2.2. Using persistence bundles
JPA is a popular persistence model, and is the Java EE standard for Object-Relational Mapping. As a result, JPA is tightly integrated with other Java EE specifications. Although JPA does fit nicely with other Java EE technologies, it’s also possible to use it in Java SE, as this is a common pattern, even inside enterprise web applications. Let’s start by looking at how to get a standard JPA bundle working in OSGi.
Packaging Persistence Units
As you saw in chapter 3, it’s easy to make use of JPA in OSGi, but there are some important differences. In Java SE you can package a persistence descriptor called persistence.xml in the META-INF folder of a JAR to define persistence units. This descriptor can then be located on the classpath by a JPA provider and used to build the required object models, table descriptions, and database connections. In OSGi, things have to be a little different. The persistence descriptor and the JPA provider shouldn’t be part of the same bundle, but if they aren’t then the JPA provider won’t be able to see persistence descriptors that are hidden away in other bundles. This is a specific example of a more general problem that affects Java SE programs in OSGi, one that we’ll cover more in section 12.2.1.
To get around this issue, OSGi persistence bundles add one important piece of information to their manifests. This is the Meta-Persistence header. This header is used to identify and advertise the locations of the JPA persistence descriptors in the bundle, and has a default value of META-INF/persistence.xml, like Java SE. Unlike Java SE, the header can also point to persistence descriptors in other parts of the bundle, even ones that aren’t named persistence.xml. A big advantage of this header is that it can be used to provide different persistence descriptors in Java SE and OSGi. Java SE will always use META-INF/persistence.xml, but OSGi can be told to use a different descriptor, potentially with different properties, that’s better suited to the OSGi environment.
In JPA the persistence descriptor isn’t the only important resource; there are also the managed classes, which are the classes that can be mapped into the database by the JPA provider. These are sometimes called the entity classes, but strictly speaking that term only refers to a subset of persistent classes. Because these classes are so closely related to the persistence descriptor, it’s important that they get packaged into the same bundle (which is almost always the case in Java SE JARs).
Other Types of Persistence Bundle
We’re focusing on Java SE JPA usage, but it’s worth briefly mentioning that Java EE defines persistence behavior for both EJB JARs and WAR files. If a bundle is an EJB JAR or WAR, then it’s automatically searched for persistence descriptors and managed classes. To help developers working with these module types in OSGi, the Aries JPA container has semantic understanding of the headers that define both WABs and EJB bundles. As a result, you don’t need to specify a Meta-Persistence header as well as a Web-ContextPath header, unless you wish to override the default WAB search locations of WEB-INF/classes/META-INF/persistence.xml and WEB-INF/lib/<library.jar>!/META-INF/persistence.xml. Like WABs, EJB bundles will also be searched automatically, although their default is the same as for normal bundles, META-INF/persistence.xml.
Creating a Persistence Bundle Manifest
In addition to specifying the Meta-Persistence header, persistence bundles have to define all of the other OSGi metadata you would expect for an OSGi bundle. Unlike the web bundles you migrated in section 11.2.1, persistence bundles are unlikely to need to specify an internal classpath, because the default is nearly always correct. This means that persistence bundle manifests are usually simpler to author than web bundle manifests. Importantly, you still need to make sure that the persistence bundle imports the right packages; for example, javax.persistence is almost always needed. An example persistence bundle manifest is shown in the following listing.
Listing 11.2. Specifying a custom location for the persistence descriptor
Manifest-Version: 1 Bundle-ManifestVersion: 2 Bundle-SymbolicName: basic.persistence.bundle Bundle-Version: 1.0.0 Meta-Persistence: persistence/descriptor.xml Import-Package: javax.persistence
If your entity classes are complex, or your persistence bundle contains data access code as well as the managed classes, you may find that your imports are too complex to manage by hand. If this is the case, then, as for web applications, we suggest looking at some of the tooling options described in section 12.1.3.
Missing Imports for Javax.Persistence and Other Packages
If your persistence bundle contains a persistence descriptor and managed classes, but no code that persists them or retrieves them, then it’s likely that you’ll only use the javax.persistence package to access annotations. Because of the way annotations work, it’s possible to load a class even if the annotations it uses aren’t on the classpath. In this case, the annotations won’t be visible to the runtime. This means that it’s possible for your persistence bundle not to import javax.persistence, and for your managed classes to still be loadable!
This may seem innocuous, or even helpful, but it can lead to some extremely nasty problems—many of which are horrendous to debug. What’s worse is that some of the problems can be subtle, or even implementation dependent, and easily missed until they cause a huge production failure costing thousands, or even millions, of dollars. What exactly is this problem, and how does it cause such awkward problems?
Annotations are used by a large number of enterprise technologies, such as JPA, EJBs, servlets, and Spring, to provide configuration and mapping information. This information is critical if the technology is to work correctly, and so its presence or absence results in huge behavior changes. The problem with a missing package import for annotations is that the annotations are still visible if you know where to look! Any annotation with a retention policy of class or runtime is compiled into the bytecode of the class (unlike source retained annotations). If the JPA container, JPA provider, EJB container, Spring, or anyone else, looks at the raw class bytes to determine which classes need to be managed, then the annotations can be found easily. This is a common way to locate annotated classes, and so most containers will locate your annotated classes, even if you don’t import the annotation package. Up to this point there isn’t a problem; annotated classes will be found correctly, the problem is with what happens next...
Having identified an annotated class for processing, it’s common practice to load it, and then use the Java reflection API to find the rest of the annotations present on the class. There are two main reasons for this. First, it’s much easier to use the reflection API than bytecode scanning to find all the annotations on a given class, and the annotations are returned in a more easily used form. Second, by loading the class it’s much easier to find any annotations it has inherited from its type hierarchy. Those of you who are particularly on the ball may now have noticed the problem. If the type is loaded but the annotation package isn’t available, then none of the annotations will be visible! If you’re lucky, this will cause an immediate failure, but usually containers have sensible defaults for cases where there are no annotations. This can lead to partconfigured objects being used by the container, almost always with spectacularly unpleasant results.
javax.persistence isn’t the only package that can potentially cause this problem, and because some packages contain only annotations, it’s entirely possible that you might run into this problem elsewhere. If you do use annotations, then consider using a manifest generation/validation tool like bnd to make sure that you don’t accidentally end up in this situation.
JPA Clients in OSGI
Building a working manifest for a persistence bundle isn’t a particularly difficult task, but this is only part of the story. The other difference between OSGi and Java SE is the way in which clients obtain an EntityManagerFactory. Unfortunately, this often requires changes to the client code. In Java SE, the API for obtaining an EntityManagerFactory is the Persistence bootstrap class, as follows:
Persistence.createEntityManagerFactory("myPUnit");
This model has a number of problems in OSGi. We’ve already mentioned the visibility of the persistence descriptor, but there are also general problems with static factories in OSGi that we’ll discuss further in section 12.3.1. To avoid these problems in OSGi, the JPA runtime registers the EntityManagerFactory as a service in the Service Registry. After a client has looked up this service, it can use it in the same way that it did before. In the case where there are multiple persistence units defined in the system, then clients can filter on the persistence unit’s name using the osgi.unit.name service property.
This code change may seem like a big problem, but it’s almost never pervasive. Because EntityManagerFactory objects are designed to be created once and reused, there’s almost always only one place in the code where they get created. This means that it’s often easy to replace a call to the Persistence bootstrap class with a service lookup. Ideally, the code will already use a dependency injection model, or it can easily be changed to do so. You saw back in listing 3.5 how you could use a Blueprint namespace to easily inject JPA resources (in that case, it was a managed EntityManager). When using dependency injection, JPA resource access is a simple matter of configuring the dependency injection container to use the appropriate mechanism for the current platform. When accessing JPA in this way, client code can continue to work in OSGi and Java SE unchanged.
JAVA EE JPA Clients
Java EE has a different model for JPA usage than Java SE, and luckily it’s one that fits a little better with OSGi. Java EE modules are either injected with JPA resources or they look them up in JNDI. As a result, some OSGi-aware containers are able to transparently request these objects from the Service Registry. This support isn’t available from all containers, and if it isn’t, it’s a trivial exercise to use the osgi:service JNDI scheme to locate the resource instead. (We discussed osgi:service lookups in sections 2.4 and 3.2.1).
Now that you’ve seen how WAR and JPA modules can be migrated, it’s time to look at another common Java EE module type, the EJB JAR.
11.2.3. EJBs in OSGi
WARs and JPA persistence archives both have related OSGi standards. As a result, our advice so far has been portable across multiple environments. Unfortunately, there’s no such specification support for EJBs in OSGi. The EJB project in Apache Aries is one of the newest, and at the time of writing Apache Aries EJB is still preparing for its first release.
Despite the comparative lack of support for EJBs in OSGi, there are still multiple supporting platforms. Oracle’s GlassFish Server supports EJB JARs that use OSGi metadata and classloading. Apache Aries approaches this from the other direction (OSGi bundles that contain EJBs), but there has been a significant effort to meet in the middle. As a result both Apache Aries and GlassFish use the same metadata to describe EJBs within an OSGi bundle, meaning that although EJB bundles aren’t strictly standard, they’re reasonably easy to use across multiple platforms.
EJB Bundle Packaging and Metadata
An EJB JAR has a simple structure. It has a normal JAR classpath, and it contains EJB classes. These classes can be identified using annotations, XML, or a mixture of both. If XML is used, then the XML file is called ejb-jar.xml and it lives in the META-INF directory of the JAR. Just like WABs do with WARs, EJB bundles follow exactly the same structure as EJB JARs (although as bundles they can choose to have a nonstandard internal classpath). The advantages of this approach are clear: it makes it easier to author an EJB bundle with existing tooling and skills, and it allows a module to be a valid EJB JAR and EJB bundle at the same time. The key difference between an EJB JAR and an EJB bundle is rather unsurprising: an EJB bundle must declare OSGi metadata in its manifest.
EJB bundles have to define standard OSGi metadata in exactly the same way that WABs, persistence bundles, and normal OSGi bundles do. We imagine that you’re comfortable with symbolic names, versions, and package imports by now, so we’ll skip the boring example and suggest that your import package statement is likely to need to contain an import for javax.ejb at version [3,4) or [3.1,4) depending on which version of the EJB specification you’re using.
The important piece of information that distinguishes a bundle as an EJB bundle is the Export-EJB header. The presence of this header allows the bundle to be recognized and loaded by an OSGi-aware EJB runtime. In many ways, this header behaves like Web-ContextPath does for WABs, but its value does something rather different. We’ll discuss exactly how the Export-EJB header can be used shortly, but it’s useful to know that your EJBs will be loaded and run, even if the header has no corresponding value.
Starting with EJB 3.1, it’s possible to define EJBs in a web module. This can be extremely useful if the EJB contains relatively little code, or if it’s only used by the WAR file. With WARs and WABs so similar, the EJB support in Apache Aries also allows EJBs to be defined in WABs. You don’t have to do anything special to make use of this function—the EJB runtime automatically scans any WABs for EJBs. The WABs don’t even need to specify the Export-EJB header, although if they do, then it will be processed.
One important thing to note about defining EJBs in WABs is that the ejb-jar.xml descriptor must be placed in WEB-INF, not META-INF. This is the same location used by the EJB specification when EJBs are defined in WAR files.
Integrating EJBS and OSGI
At the time of writing, the EJB integration in Apache Aries provides support for versions up to and including the latest release, EJB 3.1. Combined with the reasonably simple structure of an EJB JAR, this means that it’s usually easy to convert an existing EJB JAR into an EJB bundle. When running in an OSGi framework, however, accessing the EJBs might not feel particularly natural. Normally, EJBs are accessed through JNDI, and although this is still possible in Aries, it isn’t how OSGi bundles normally do things. Where possible, OSGi bundles use the OSGi Service Registry to integrate, and this is exactly what you can do with certain types of EJBs.
A number of different types of EJBs exist, but the most commonly used are Session Beans. Session Beans have a further set of distinct types; of these, the Stateless and Singleton Session Bean types behave a lot like OSGi services. They’re looked up, potentially by multiple clients, used for a period, and possibly cached in the meantime. It would be ideal if this usage pattern could integrate easily with other OSGi technologies such as Blueprint, and the Service Registry is an excellent place to do that. As a result, the Apache Aries runtime can be configured to register OSGi services for any Singleton or Stateless Session Beans inside an EJB Bundle.
Selecting EJBS to Expose in the Service Registry
Getting the Aries EJB runtime to expose your EJBs as OSGi services is remarkably easy, and it relates to the value of the Export-EJB header. The value of this header defines a comma-separated list of EJB names. This list is a simple whitelist that’s used to select the EJBs that should be exposed as OSGi services. As we mentioned earlier, this header can only cause Singleton and Stateless Session EJBs to be registered, but because these are the most commonly used types of Session EJBs (and you shouldn’t be trying to call a Message Driven Bean directly), this covers the majority of EJB applications.
You might wonder why the Export-EJB header works differently from some of the other Java EE integration headers that you’ve seen, and also why it’s a whitelist rather than a blacklist. This is an interesting discussion, and bears a little thought. In many ways, EJBs are similar to Blueprint beans or other managed objects. They can be wired together using dependency injection, and they can be exposed externally. We hope that we’ve convinced you by now that one of the most important aspects of a well-architected OSGi bundle is that it hides as much as possible. This is equally true of managed objects inside the bundles. You wouldn’t normally expose every bean in a Blueprint file as a service; some are used internally by the other beans. Exactly the same is true of EJBs. You should be making a decision to expose the beans, not hoping that nobody starts calling them. This is why, by default, no EJB services get exported. To help in those times that you do want to export everything, or when you want to be extra explicit that nothing should be registered, there are two special values that you can associate with the Export-EJB header. These are ALL and NONE, and their behavior is self-explanatory.
When an EJB has been exposed as a service, the Aries EJB container will register one OSGi service per client view of the EJB. This can be a local interface, a remote interface, or the no-interface view of the EJB. The services will be registered with some special properties: ejb.name gives the name of the EJB, and ejb.type gives the type of the EJB (either Singleton or Stateless). These services can then be used like any other OSGi service; they can be easily consumed using Blueprint, or the OSGi API, or in any other way that you fancy.
The EJB programming model includes comprehensive support for incoming requests from remote clients. This is supported through the use of remote EJB interfaces. Back in section 10.2, we showed that OSGi services can support remote call semantics as well. Given that remote EJB interfaces are designed to be remotely accessible, it’s only natural that they should be easy to expose as remote OSGi services. The Aries EJB container works to help you out here. All EJB services that correspond to remote interfaces have the service.exported.interfaces property set automatically by the Aries EJB container. This means that remote EJB services automatically integrate with a Remote Services Distribution Provider.
In addition to Java EE technologies, there’s one framework that’s widely used throughout enterprise programming: the Spring dependency injection framework.
11.2.4. Moving to Blueprint from the Spring Framework
The Spring Framework is a large ecosystem of projects, and there are books covering the wide variety of features available. Although there are powerful aspect-oriented programming tools and Web MVC helpers, the majority of Spring applications make significant use of Spring’s dependency injection, but are much less reliant on the other Spring projects. A typical Spring application might contain configuration similar to the following listing.
Listing 11.3. A simple Spring application definition

The Spring XML in listing 11.3 is simple, but it demonstrates an important point. Because of Blueprint’s heritage, it’s extremely easy to turn Spring XML into valid Blueprint XML. This can often be accomplished with few changes. If you were to write a roughly equivalent Blueprint version of the Spring example, it would look something like the following listing.
Listing 11.4. A simple Blueprint application definition

The Blueprint version of the application descriptor is slightly different, in that it uses the OSGi Service Registry to find the DataSource, but functionally it’s doing exactly the same job, and it looks remarkably similar. We haven’t picked a particularly special example here; most of Spring’s XML syntax can be directly used in Blueprint with few, or sometimes no, changes. These parallels are explicitly listed in the documentation for Eclipse Gemini (the reference implementation for the Blueprint container service), which was contributed to Eclipse by SpringSource. This documentation is available at http://www.eclipse.org/gemini/blueprint/documentation/reference/1.0.1.RELEASE/html/blueprint.html#blueprint:differences. Most usefully, this page includes a table indicating the different names used by Spring and Blueprint for the same logical structures. A subset of this table is visible in table 11.1.
Table 11.1. A comparison of Spring and Blueprint XML syntax
|
Element/Attribute meaning |
Spring syntax |
Blueprint syntax |
|---|---|---|
| Namespace declaration | http://www.springframework.org/schema/beans or http://www.springframework.org/schema/osgi | http://www.osgi.org/xmlns/blueprint/v1.0.0 |
| Root element | <beans> | <blueprint> |
| Default bean activation policy | default-lazy | default-activation |
| Bean ID | id | id |
| Bean class | class | class |
| Bean scope | scope | scope |
| Built-in scopes | singleton, prototype, request, session, bundle | singleton, prototype |
| Default bean activation policy | lazy-init=true/false | activation=lazy/eager |
| Explicit dependencies | depends-on | depends-on |
| Initialization method | init-method | init-method |
| Destruction method | destroy-method | destroy-method |
| Bean static/Instance factory method | factory-method | factory-method |
| Instance factory bean | factory-bean | factory-ref |
| Instantiation argument | <constructor-arg> | <argument> |
| Injection property | <property> | <property> |
| Injecting bean references | ref | ref |
| Injection value | <value> | <value> |
| Exposing a service | <service> | <service> |
| Consuming a single service | <reference> | <reference> |
| Consuming multiple services | <list> | <reference-list> |
Spring Transactions
In addition to its dependency injection model, Spring offers declarative transaction support to beans using aspect-oriented programming. This can be a little complicated to configure, but typically you would use one of Spring’s predefined transaction aspects with a Spring transaction manager. A simple example might look like the XML in the following listing.
Listing 11.5. Controlling transactions with Spring


The XML in listing 11.5 defines a number of things. In ![]() it defines the locations into which the transaction aspect should be injected. The aspect itself is defined at
it defines the locations into which the transaction aspect should be injected. The aspect itself is defined at ![]() , and declares that this injection point should create a transaction if none exists already. Finally, you can see the declaration
of the bean itself at
, and declares that this injection point should create a transaction if none exists already. Finally, you can see the declaration
of the bean itself at ![]() .
.
Aspect-oriented programming is a programming methodology that’s rather different from the object-oriented programming most of us know and love. In object-oriented programming, you try to identify groups of data that represent state and encapsulate them within an object. In aspect-oriented programming, you try to identify common problems or functions (usually known as cross-cutting concerns) and encapsulate them within aspects. These aspects (sometimes known as advice) are then woven into the code at points defined by pointcuts.
Aspect-oriented programming is a powerful mechanism for adding common code to objects, removing the need for them to declare it directly. This can significantly simplify the code within the object, and is particularly useful for things like logging and transactions, which are typically orthogonal to the main purpose of the running method.
You’ve already seen how to use the Aries transactions project to add declarative transactions to Blueprint beans in section 3.3.6, but it’s worth looking at the following listing to see how Blueprint compares to Spring.
Listing 11.6. Controlling transactions with Blueprint

As you can see, it’s easy to add transactionality to Blueprint beans using the Blueprint transactions namespace, as Spring beans can with the Spring transactions namespace. Because of their equivalent levels of function, it’s entirely possible to move between Aries Blueprint and Spring’s transaction syntax as necessary.
11.3. Summary
We’ve now covered a broad range of migration strategies for a variety of enterprise module types. We hope that you agree that moving enterprise applications to OSGi need not be an impossible, or even painful, process. The new standards introduced by the OSGi Enterprise Expert Group and the extensions provided in the Apache Aries project allow for many commonly used technologies to be migrated easily, often with no code changes.
In cases where migration is difficult, or where you don’t wish to migrate away from the existing system but do want to use OSGi for other parts of the application, then SCA can be used to link together the heterogeneous modules in a clean, implementation-independent way. All in all, life looks good for enterprise developers.
Given how easy migration can be, why does OSGi have such a reputation for being difficult to use? And why isn’t it already the de facto platform? One common theme throughout this chapter has been that you’ve had control of the source code and packaging, allowing you to change the modules as necessary. For the libraries that you use in your applications, this isn’t always the case! In chapter 12, you’ll learn some approaches for making use of code that isn’t OSGi-aware, and that, for whatever reason, you can’t change.