
Chapter 1. Introduction to project automation
This chapter covers
- Understanding the benefits of project automation
- Getting to know different types of project automation
- Surveying the characteristics and architecture of build tools
- Exploring the pros and cons of build tool implementations
Tom and Joe work as software developers for Acme Enterprises, a startup company that offers a free online service for finding the best deals in your area. The company recently received investor funding and is now frantically working toward its first official launch. Tom and Joe are in a time crunch. By the end of next month, they’ll need to present a first version of the product to their investors. Both developers are driven individuals, and they pump out features daily. So far, development of the software has stayed within the time and budget constraints, which makes them happy campers. The chief technology officer (CTO) pats them on the back; life is good. However, the manual and error-prone build and delivery process slows them down significantly. As a result, the team has to live with sporadic compilation issues, inconsistently built software artifacts, and failed deployments. This is where build tools come in.
This chapter will give you a gentle introduction into why it’s a good idea to automate your project and how build tools can help get the job done. We’ll talk about the benefits that come with sufficient project automation, the types and characteristics of project automation, and the tooling that enables you to implement an automated process.
Two traditional build tools dominate Java-based projects: Ant and Maven. We’ll go over their main features, look at some build code, and talk about their shortcomings. Lastly, we’ll discuss the requirements for a build tool that will fulfill the needs of modern-day project automation.
1.1. Life without project automation
Going back to Tom and Joe’s predicament, let’s go over why project automation is such a no-brainer. Believe it or not, lots of developers face the following situations. The reasons are varied, but probably sound familiar.
- My IDE does the job. At Acme, developers do all their coding within the IDE, from navigating through the source code, implementing new features, and compiling and refactoring code, to running unit and integration tests. Whenever new code is developed, they press the Compile button. If the IDE tells them that there’s no compilation error and the tests are passing, they check the code into version control so it can be shared with the rest of the team. The IDE is a powerful tool, but every developer will need to install it first with a standardized version to be able to perform all of these tasks, a lesson Joe learns when he uses a new feature only supported by the latest version of the compiler.
- It works on my box. Staring down a ticking clock, Joe checks out the code from version control and realizes that it doesn’t compile anymore. It seems like one of the classes is missing from the source code. He calls Tom, who’s puzzled that the code doesn’t compile on Joe’s machine. After discussing the issue, Tom realizes that he probably forgot to check in one of his classes, which causes the compilation process to fail. The rest of the team is now blocked and can’t continue their work until Tom checks in the missing source file.
- The code integration is a complete disaster. Acme has two different development groups, one specializing in building the web-based user interface and the other working on the server-side backend code. Both teams sit together at Tom’s computer to run the compilation for the whole application, build a deliverable, and deploy it to a web server in a test environment. The first cheers quickly fade when the team sees that some of the functionality isn’t working as expected. Some of the URLs simply don’t resolve or result in an error. Even though the team wrote some functional tests, they didn’t get exercised regularly in the IDE.
- The testing process slows to a crawl. The quality assurance (QA) team is eager to get their hands on a first version of the application. As you can imagine, they aren’t too happy about testing low-quality software. With every fix the development team puts into place, they have to run through the same manual process. The team stops to check new changes into version control, a new version is built from an IDE, and the deliverable is copied to the test server. Each and every time, a developer is fully occupied and can’t add any other value to the company. After weeks of testing and a successful demo to the investor, the QA team says the application is ready for prime time.
- Deployment turns into a marathon. From experience, the team knows that the outcome of deploying an application is unpredictable due to unforeseen problems. The infrastructure and runtime environment has to be set up, the database has to be prepared with seed data, the actual deployment of the application has to happen, and initial health monitoring needs to be performed. Of course, the team has an action plan in place, but each of the steps has to be executed manually.
The product launch is a raving success. The following week, the CTO swings by the developers’ desks; he already has new ideas to improve the user experience. A friend has told him about agile development, a time-boxed iterative approach for implementing and releasing software. He proposes that the team introduces two-week release cycles. Tom and Joe look at each other, both horrified at the manual and repetitive work that lies ahead. Together, they plan to automate each step of the implementation and delivery process to reduce the risk of failed builds, late integration, and painful deployments.
1.2. Benefits of project automation
This story makes clear how vital project automation is for team success. These days, time to market has become more important than ever. Being able to build and deliver software in a repeatable and consistent way is key. Let’s look at the benefits of automating your project.
1.2.1. Prevents manual intervention
Having to manually perform steps to produce and deliver software is time-consuming and error-prone. Frankly, as a developer and system administrator, you have better things to do than to handhold a compilation process or to copy a file from directory A to directory B. We’re all human. Not only can you make mistakes along the way, manual intervention also takes away from the time you desperately need to get your actual work done. Any step in your software development process that can be automated should be automated.
1.2.2. Creates repeatable builds
The actual building of your software usually follows predefined and ordered steps. For example, you compile your source code first, then run your tests, and lastly assemble a deliverable. You’ll need to run the same steps over and over again—every day. This should be as easy as pressing a button. The outcome of this process needs to be repeatable for everyone who runs the build.
1.2.3. Makes builds portable
You’ve seen that being able to run a build from an IDE is very limiting. First of all, you’ll need to have the particular product installed on your machine. Second, the IDE may only be available for a specific operating system. An automated build shouldn’t require a specific runtime environment to work, whether this is an operating system or an IDE. Optimally, the automated tasks should be executable from the command line, which allows you to run the build from any machine you want, whenever you want.
1.3. Types of project automation
You saw at the beginning of this chapter that a user can request a build to be run. A user can be any stakeholder who wants to trigger the build, like a developer, a QA team member, or a product owner. Our friend Tom, for example, pressed the Compile button in his IDE whenever he wanted the code to be compiled. On-demand automation is only one type of project automation. You can also schedule your build to be executed at predefined times or when a specific event occurs.
1.3.1. On-demand builds
The typical use case for on-demand automation is when a user triggers a build on his or her machine, as shown in figure 1.1. It’s common practice that a version control system (VCS) manages the versioning of the build definition and source code files.
Figure 1.1. On-demand builds execute build definitions backed by a VCS.

In most cases, the user executes a script on the command line that performs tasks in a predefined order—for example, compiling source code, copying a file from directory A to directory B, or assembling a deliverable. Usually, this type of automation is executed multiple times per day.
1.3.2. Triggered builds
If you’re practicing agile software development, you’re interested in receiving fast feedback about the health of your project. You’ll want to know if your source code can be compiled without any errors or if there’s a potential software defect indicated by a failed unit or integration test. This type of automation is usually triggered if code was checked into version control, as shown in figure 1.2.
Figure 1.2. Build triggered by a check-in of files into VCS
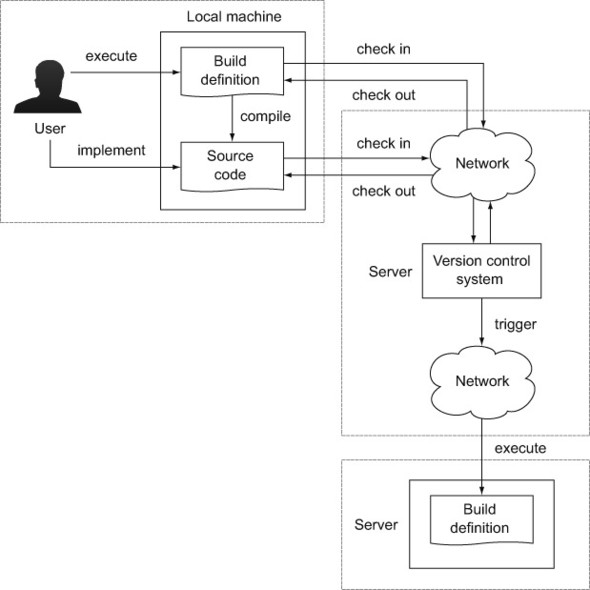
1.3.3. Scheduled builds
Think of scheduled automation as a time-based job scheduler (in the context of a Unix-based operation system, also known as a cron job). It runs in particular intervals or at concrete times—for example, every morning at 1:00 a.m. or every 15 minutes. As with all cron jobs, scheduled automation generally runs on a dedicated server. Figure 1.3 shows a scheduled build that runs every morning at 5:00 a.m. This kind of automation is particularly useful for generating reports or documentation for your project.
Figure 1.3. Scheduled build initiated at 5:00 a.m. daily

The practice that implements scheduled and triggered builds is commonly referred to as continuous integration (CI). You’ll learn more about CI in chapter 13. After identifying the benefits and types of project automation, it’s time to discuss the tools that allow you to implement this functionality.
1.4. Build tools
Naturally, you may ask yourself why you’d need another tool to implement automation for your project. You could just write the logic as an executable script, such as a shell script. Think back to the goals of project automation we discussed earlier. You want a tool that allows you to create a repeatable, reliable, and portable build without manual intervention. A shell script wouldn’t be easily portable from a UNIX-based system to a Windows-based system, so it doesn’t meet your criteria.
1.4.1. What’s a build tool?
What you need is a programming utility that lets you express your automation needs as executable, ordered tasks. Let’s say you want to compile your source code, copy the generated class files into a directory, and assemble a deliverable that contains the class files. A deliverable could be a ZIP file, for example, that can be distributed to a runtime environment. Figure 1.4 shows the tasks and their execution order for the described scenario.
Figure 1.4. A common scenario of tasks executed in a predefined order

Each of these tasks represents a unit of work—for example, compilation of source code. The order is important. You can’t create the ZIP archive if the required class files haven’t been compiled. Therefore, the compilation task needs to be executed first.
Directed Acyclic Graph
Internally, tasks and their interdependencies are modeled as a directed acyclic graph (DAG). A DAG is a data structure from computer science and contains the following two elements:
- Node: A unit of work; in the case of a build tool, this is a task (for example, compiling source code).
- Directed edge: A directed edge, also called an arrow, representing the relationship between nodes. In our situation, the arrow means depends on. If a task defines dependent tasks, they’ll need to execute before the task itself can be executed. Often this is the case because the task relies on the output produced by another task. Here’s an example: to execute the task “assemble deliverable,” you’ll need to run its dependent tasks “copy class files to directory” and “compile source code.”
Each node knows about its own execution state. A node—and therefore the task—can only be executed once. For example, if two different tasks depend on the task “source code compilation,” you only want to execute it once. Figure 1.5 shows this scenario as a DAG.
Figure 1.5. DAG representation of tasks

You may have noticed that the nodes are shown in an inverted order from the tasks in figure 1.4. This is because the order is determined by node dependencies. As a developer, you won’t have to deal directly with the DAG representation of your build. This job is done by the build tool. Later in this chapter, you’ll see how some Java-based build tools use these concepts in practice.
1.4.2. Anatomy of a build tool
It’s important to understand the interactions among the components of a build tool, the actual definition of the build logic, and the data that goes in and out. Let’s discuss each of the elements and their particular responsibilities.
Build file
The build file contains the configuration needed for the build, defines external dependencies such as third-party libraries, and contains the instructions to achieve a specific goal in the form of tasks and their interdependencies. Figure 1.6 illustrates a build file that describes four tasks and how they depend on each other.
Figure 1.6. The build file expresses the rules of your build expressed by tasks and their interdependencies.

The tasks we discussed in the scenario earlier—compiling source code, copying files to a directory, and assembling a ZIP file—would be defined in the build file. Oftentimes, a scripting language is used to express the build logic. That’s why a build file is also referred to as a build script.
Build inputs and outputs
A task takes an input, works on it by executing a series of steps, and produces an output. Some tasks may not need any input to function correctly, nor is creating an output considered mandatory. Complex task dependency graphs may use the output of a dependent task as input. Figure 1.7 demonstrates the consumption of inputs and the creation of outputs in a task graph.
Figure 1.7. Task inputs and outputs

I already mentioned an example that follows this workflow. We took a bunch of source code files as input, compiled them to classes, and assembled a deliverable as output. The compilation and assembly processes each represent one task. The assembly of the deliverable only makes sense if you compiled the source code first. Therefore, both tasks need to retain their order.
Build engine
The build file’s step-by-step instructions or rule set must be translated into an internal model the build tool can understand. The build engine processes the build file at runtime, resolves dependencies between tasks, and sets up the entire configuration needed to command the execution, as shown in figure 1.8.
Figure 1.8. The build engine translates the rule set into an internal model representation that is accessed during the runtime of the build.

Once the internal model is built, the engine will execute the series of tasks in the correct order. Some build tools allow you to access this model via an API to query for this information at runtime.
Dependency Manager
The dependency manager is used to process declarative dependency definitions for your build file, resolve them from an artifact repository (for example, the local file system, an FTP, or an HTTP server), and make them available to your project. A dependency is generally an external, reusable library in the form of a JAR file (for example, Log4J for logging support). The repository acts as storage for dependencies, and organizes and describes them by identifiers, such as name and version. A typical repository can be an HTTP server or the local file system. Figure 1.9 illustrates how the dependency manager fits into the architecture of a build tool.
Figure 1.9. The dependency manager retrieves external dependencies and makes them available to your build.
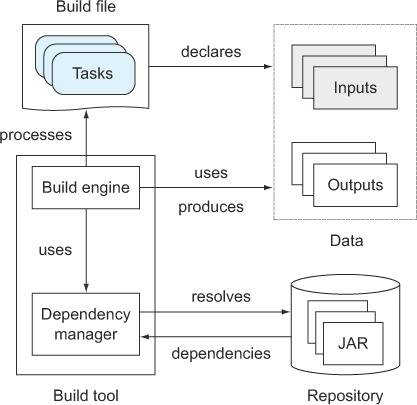
Many libraries depend on other libraries, called transitive dependencies. The dependency manager can use metadata stored in the repository to automatically resolve transitive dependencies as well. A build tool is not required to provide a dependency management component.
1.5. Java build tools
In this section, we look at two popular, Java-based build tools: Ant and Maven. We’ll discuss their characteristics, see a sample script in action, and outline the shortcomings of each tool. Let’s start with the tool that’s been around the longest—Ant.
1.5.1. Apache Ant
Apache Ant (Another Neat Tool) is an open source build tool written in Java. Its main purpose is to provide automation for typical tasks needed in Java projects, such as compiling source files to classes, running unit tests, packaging JAR files, and creating Javadoc documentation. Additionally, it provides a wide range of predefined tasks for file system and archiving operations. If any of these tasks don’t fulfill your requirements, you can extend the build with new tasks written in Java.
While Ant’s core is written in Java, your build file is expressed through XML, which makes it portable across different runtime environments. Ant does not provide a dependency manager, so you’ll need to manage external dependencies yourself. However, Ant integrates well with another Apache project called Ivy, a full-fledged, standalone dependency manager. Integrating Ant with Ivy requires additional effort and has to be done manually for each individual project. Let’s look at a sample build script.
Build Script Terminology
To understand any Ant build script, you need to start with some quick nomenclature. A build script consists of three basic elements: the project, multiple targets, and the used tasks. Figure 1.10 illustrates the relationship between each of the elements.
Figure 1.10. Ant’s hierarchical build script structure with the elements project, target, and task

In Ant, a task is a piece of executable code—for example, for creating a new directory or moving a file. Within your build script, use a task by its predefined XML tag name. The task’s behavior can be configured by its exposed attributes. The following code snippet shows the usage of the javac Ant task for compiling Java source code within your build script:

While Ant ships with a wide range of predefined tasks, you can extend your build script’s capabilities by writing your own task in Java.
A target is a set of tasks you want to be executed. Think of it as a logical grouping. When running Ant on the command line, provide the name of the target(s) you want to execute. By declaring dependencies between targets, a whole chain of commands can be created. The following code snippet shows two dependent targets:

Mandatory to all Ant projects is the overarching container, the project. It’s the top-level element in an Ant script and contains one or more targets. You can only define one project per build script. The following code snippet shows the project in relation to the targets:

With a basic understanding of Ant’s hierarchical structure, let’s look at a full-fledged scenario of a sample build script.
Sample build script
Say you want to write a script that compiles your Java source code in the directory src using the Java compiler and put it into the output directory build. Your Java source code has a dependency on a class from the external library Apache Commons Lang. You tell the compiler about it by referencing the library’s JAR file in the classpath. After compiling the code, you want to assemble a JAR file. Each unit of work, source code compilation, and JAR assembly will be grouped in an individual target. You’ll also add two more targets for initializing and cleaning up the required output directories. The structure of the Ant build script you’ll create is shown in figure 1.11.
Figure 1.11. Hierarchical project structure of sample Ant build script
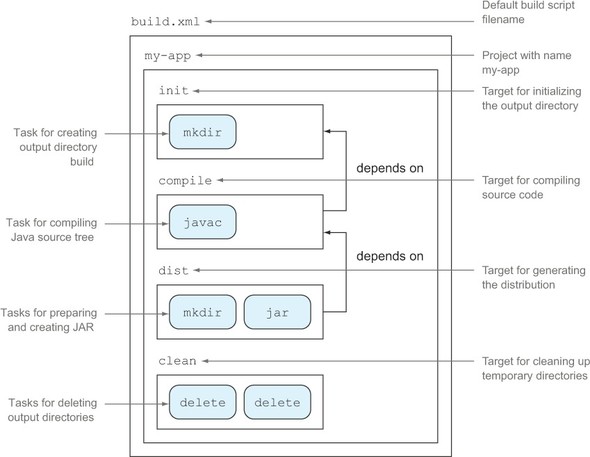
Let’s get down to business. It’s time to implement this example as an Ant build script. The following listing shows the whole project and the targets required to achieve your goal.
Listing 1.1. Ant script with targets for compiling source code and assembling JAR file

Ant doesn’t impose any restrictions on how to define your build’s structure. This makes it easy to adapt to existing project layouts. For example, the source and output directories in the sample script have been chosen arbitrarily. It would be very easy to change them by setting a different value to their corresponding properties. The same is true for target definition; you have full flexibility to choose which logic needs to be executed per target and the order of execution.
Shortcomings
Despite all this flexibility, you should be aware of some shortcomings:
- Using XML as the definition language for your build logic results in overly large and verbose build scripts compared to build tools with a more succinct definition language.
- Complex build logic leads to long and unmaintainable build scripts. Trying to define conditional logic like if-then/if-then-else statements becomes a burden when using a markup language.
- Ant doesn’t give you any guidelines on how to set up your project. In an enterprise setting, this often leads to a build file that looks different every time. Common functionality is oftentimes copied and pasted. Every new developer on the project needs to understand the individual structure of a build.
- You want to know how many classes have been compiled or how many tasks have been executed in a build. Ant doesn’t expose an API that lets you query information about the in-memory model at runtime.
- Using Ant without Ivy makes it hard to manage dependencies. Oftentimes, you’ll need to check your JAR files into version control and manage their organization manually.
1.5.2. Apache Maven
Using Ant across many projects within an enterprise has a big impact on maintainability. With flexibility comes a lot of duplicated code snippets that are copied from one project to another. The Maven team realized the need for a standardized project layout and unified build lifecycle. Maven picks up on the idea of convention over configuration, meaning that it provides sensible default values for your project configuration and its behavior. The project automatically knows what directories to search for source code and what tasks to perform when running the build. You can set up a full project with a few lines of XML as long as your project adheres to the default values. As an extra, Maven also has the ability to generate HTML project documentation that includes the Javadocs for your application.
Maven’s core functionality can be extended by custom logic developed as plugins. The community is very active, and you can find a plugin for almost every aspect of build support, from integration with other development tools to reporting. If a plugin doesn’t exist for your specific needs, you can write your own extension.
Standard directory layout
By introducing a default project layout, Maven ensures that every developer with the knowledge of one Maven project will immediately know where to expect specific file types. For example, Java application source code sits in the directory src/main/java. All default directories are configurable. Figure 1.12 illustrates the default layout for Maven projects.
Figure 1.12. Maven’s default project layout defines where to find Java source code, resource files, and test code.

Build lifecycle
Maven is based on the concept of a build lifecycle. Every project knows exactly which steps to perform to build, package, and distribute an application, including the following functionality:
- Compiling source code
- Running unit and integration tests
- Assembling the artifact (for example, a JAR file)
- Deploying the artifact to a local repository
- Releasing the artifact to a remote repository
Every step in this build lifecycle is called a phase. Phases are executed sequentially. The phase you want to execute is defined when running the build on the command line. If you call the phase for packaging the application, Maven will automatically determine that the dependent phases like source code compilation and running tests need to be executed beforehand. Figure 1.13 shows the predefined phases of a Maven build and their order of execution.
Figure 1.13. Maven’s most important build lifecycle phases

Dependency management
In Maven projects, dependencies to external libraries are declared within the build script. For example, if your project requires the popular Java library Hibernate, you simply define its unique artifact coordinates, such as organization, name, and version, in the dependencies configuration block. The following code snippet shows how to declare a dependency on version 4.1.7. Final of the Hibernate core library:

At runtime, the declared libraries and their transitive dependencies are downloaded by Maven’s dependency manager, stored in the local cache for later reuse, and made available to your build (for example, for compiling source code). Maven preconfigures the use of the repository, Maven Central, to download dependencies. Subsequent builds will reuse an existing artifact from the local cache and therefore won’t contact Maven Central. Maven Central is the most popular binary artifact repository in the Java community. Figure 1.14 demonstrates Maven’s artifact retrieval process.
Figure 1.14. Maven’s interaction with Maven Central to resolve and download dependencies for your build

Dependency management in Maven isn’t limited to external libraries. You can also declare a dependency on other Maven projects. This need arises if you decompose software into modules, which are smaller components based on associated functionality. Figure 1.15 shows an example of a traditional three-layer modularized architecture. In this example, the presentation layer contains code for rendering data in a webpage, the business layer models real-life business objects, and the integration layer retrieves data from a database.
Figure 1.15. Modularized architecture of a software project

Sample build script
The following listing shows a sample Maven build script named pom.xml that will implement the same functionality as the Ant build. Keep in mind that you stick to the default conventions here, so Maven will look for the source code in the directory src/main/java instead of src.
Listing 1.2. Maven POM for building standardized Java project

Shortcomings
As with Ant, be aware of some of Maven’s shortcomings:
- Maven proposes a default structure and lifecycle for a project that often is too restrictive and may not fit your project’s needs.
- Writing custom extensions for Maven is overly cumbersome. You’ll need to learn about Mojos (Maven’s internal extension API), how to provide a plugin descriptor (again in XML), and about specific annotations to provide the data needed in your extension implementation.
- Earlier versions of Maven (< 2.0.9) automatically try to update their own core plugins; for example, support for unit tests to the latest version. This may cause brittle and unstable builds.
1.5.3. Requirements for a next-generation build tool
In the last section, we examined the features, advantages, and shortcomings of the established build tools Ant and Maven. It became clear that you often have to compromise on the supported functionality by choosing one or the other. Either you choose full flexibility and extensibility but get weak project standardization, tons of boilerplate code, and no support for dependency management by picking Ant; or you go with Maven, which offers a convention over configuration approach and a seamlessly integrated dependency manager, but an overly restrictive mindset and cumbersome plugin system.
Wouldn’t it be great if a build tool could cover a middle ground? Here are some features that an evolved build tool should provide:
- Expressive, declarative, and maintainable build language.
- Standardized project layout and lifecycle, but full flexibility and the option to fully configure the defaults.
- Easy-to-use and flexible ways to implement custom logic.
- Support for project structures that consist of more than one project to build deliverable.
- Support for dependency management.
- Good integration and migration of existing build infrastructure, including the ability to import existing Ant build scripts and tools to translate existing Ant/Maven logic into its own rule set.
- Emphasis on scalable and high-performance builds. This will matter if you have long-running builds (for example, two hours or longer), which is the case for some big enterprise projects.
This book will introduce you to a tool that does provide all of these great features: Gradle. Together, we’ll cover a lot of ground on how to use it and exploit all the advantages it provides.
1.6. Summary
Life for developers and QA personnel without project automation is repetitive, tedious, and error-prone. Every step along the software delivery process—from source code compilation to packaging the software to releasing the deliverable to test and production environments—has to be done manually. Project automation helps remove the burden of manual intervention, makes your team more efficient, and leads the way to a push-button, fail-safe software release process.
In this chapter, we identified the different types of project automation—on-demand, scheduled, and triggered build initiation—and covered their specific use cases. You learned that the different types of project automation are not exclusive. In fact, they complement each other.
A build tool is one of the enablers for project automation. It allows you to declare the ordered set of rules that you want to execute when initiating a build. We discussed the moving parts of a build tool by analyzing its anatomy. The build engine (the build tool executable) processes the rule set defined in the build script and translates it into executable tasks. Each task may require input data to get its job done. As a result, a build output is produced. The dependency manager is an optional component of the build tool architecture that lets you declare references to external libraries that your build process needs to function correctly.
We saw the materialized characteristics of build tools in action by taking a deeper look at two popular Java build tool implementations: Ant and Maven. Ant provides a very flexible and versatile way of defining your build logic, but doesn’t provide guidance on a standard project layout or sensible defaults to tasks that repeat over and over in projects. It also doesn’t come with an out-of-the-box dependency manager, which requires you to manage external dependencies yourself. Maven, on the other hand, follows the convention over configuration paradigm by supporting sensible default configuration for your project as well as a standardized build lifecycle. Automated dependency management for external libraries and between Maven projects is a built-in feature. Maven falls short on easy extensibility for custom logic and support for nonconventional project layouts and tasks. You learned that an advanced build tool needs to find a middle ground between flexibility and configurable conventions to support the requirements of modern-day software projects.
In the next chapter, we’ll identify how Gradle fits into the equation.