
1 Welcome to Grokking Simplicity

In this chapter
- Learn the definition of functional thinking.
- Understand how this book is different from other books on functional programming.
- Discover the primary distinction that functional programmers make when they look at code.
- Decide whether this book is for you.
In this chapter, we will define functional thinking and how its major distinction helps working programmers build better software. We will also get an overview of the journey ahead through two major insights that functional programmers experience.
What is functional programming?
Programmers ask me all the time what functional programming (FP) is and what it’s good for. What FP is good for is difficult to explain because it is a general-purpose paradigm. It’s good for everything. We’ll see where it really shines in just a few pages.
Defining functional programming is difficult, too. Functional programming is a huge field. It’s used in both the software industry and in academia. However, most of what has been written about it is from academia.
Grokking Simplicity takes a different approach from the typical book about functional programming. It is decidedly about the industrial uses of functional programming. Everything in this book needs to be practical for working software engineers.

You may come across definitions from other sources, and it’s important to understand how they relate to what we’re doing in this book. Here is a typical definition paraphrased from Wikipedia:
functional programming (FP), noun.
- a programming paradigm characterized by the use of mathematical functions and the avoidance of side effects**
** we need to define the underlined terms
- a programming style that uses only pure functions without side effects
Let’s pick apart the underlined terms.
Side effects are anything a function does other than returning a value, like sending an email or modifying global state. These can be problematic because the side effects happen every time your function is called. If you need the return value and not the side effects, you’ll cause things to happen unintentionally. It is very common for functional programmers to avoid unnecessary side effects.
Pure functions are functions that depend only on their arguments and don’t have any side effects. Given the same arguments, they will always produce the same return value. We can consider these mathematical functions to distinguish them from the language feature called /functions/. Functional programmers emphasize the use of pure functions because they are easier to understand and control.
The definition implies that functional programmers completely avoid side effects and only use pure functions. But this is not true. Working functional programmers will use side effects and impure functions.
Common side effects include
- Sending an email
- Reading a file
- Blinking a light
- Making a web request
- Applying the brakes in a car
these are why we run software in the first place!
The problems with the definition for practical use
The definition might work well for academia, but it has a number of problems for the working software engineer. Let’s look at the definition again:
functional programming (FP), noun.
- a programming paradigm characterized by the use of mathematical functions and the avoidance of side effects
- a programming style that uses only pure functions without side effects
There are three main problems with this definition for our purposes.
Problem 1: FP needs side effects
The definition says FP avoids side effects, but side effects are the very reason we run our software. What good is email software that doesn’t send emails? The definition implies that we completely avoid them, when in reality, we use side effects when we have to.
![]() Vocab time
Vocab time
Side effects are any behavior of a function besides the return value.
Pure functions depend only on their arguments and don’t have any side effects.
Problem 2: FP is good at side effects
Functional programmers know side effects are necessary yet problematic, so we have a lot of tools for working with them. The definition implies that we only use pure functions. On the contrary, we use impure functions a lot. We have a ton of functional techniques that make them easier to use.
Problem 3: FP is practical
The definition makes FP seem like it’s mostly mathematical and impractical for real-world software. There are many important software systems written using functional programming.
The definition is especially confusing to people who are introduced to FP through the definition. Let’s see an example of a well-intentioned manager who reads the definition on Wikipedia.
The definition of FP confuses managers
Imagine a scenario where Jenna, the eager programmer, wants to use FP for an email-sending service. She knows FP will help architect the system to improve dependability. Her manager doesn’t know what FP is, so he has to look up the definition on Wikipedia.
The manager looks up “functional programming” on Wikipedia:
… the avoidance of side effects…

He Googles “side effect.” Common side effects include
- sending an email
- …

Later that day…

We treat functional programming as a set of skills and concepts
We’re not going to use the typical definition in this book. FP is many things to many people, and it is a huge field of study and practice.
I’ve talked with many working functional programmers about what they find most useful from FP. Grokking Simplicity is a distillation of the skills, thought processes, and perspectives of working functional programmers. Only the most practical and powerful ideas made it into this book.
In Grokking Simplicity, you won’t find the latest research or the most esoteric ideas. We’re only going to learn the skills and concepts you can apply today. While doing this research I’ve found that the most important concepts from FP apply even in object-oriented and procedural code, and across all programming languages. The real beauty of FP is that it deals with beneficial, universal coding practices.
Let’s take a crack at the skill any functional programmer would say is important: the distinction between actions, calculations, and data.

Distinguishing actions, calculations, and data
When functional programmers look at code, they immediately begin to classify code into three categories:
- Actions
- Calculations
- Data
Here are some snippets of code from an existing codebase. You need to be more careful with the snippets with stars.
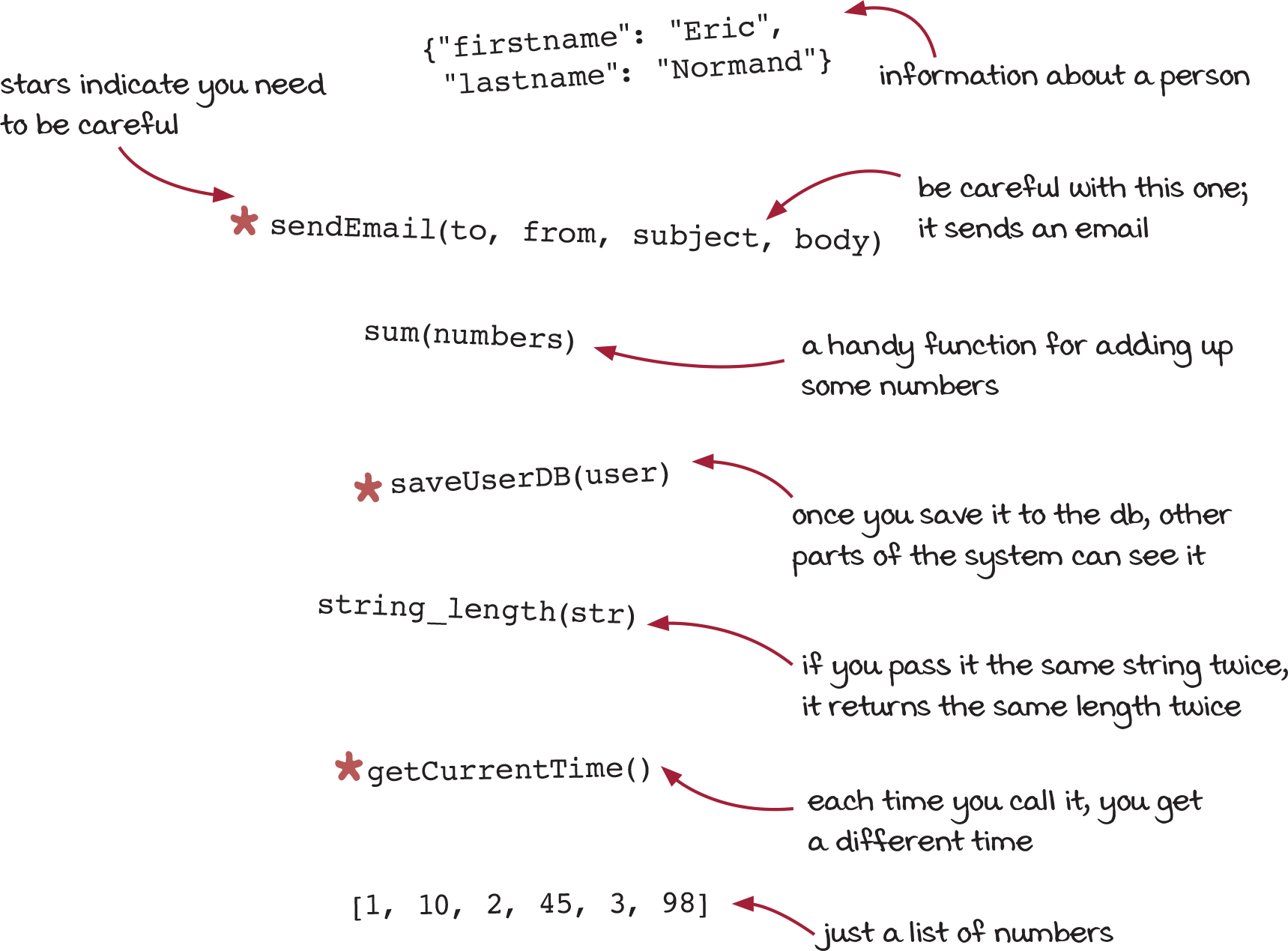
The starred functions need caution because they depend on when they are run or how many times they are run. For instance, you don’t want to send an important email twice, nor do you want to send it zero times.
The starred snippets are actions. Let’s separate those from the rest.
Functional programmers distinguish code that matters when you call it
Let’s draw a line and move all of the functions that depend on when you call them to one side of the line:
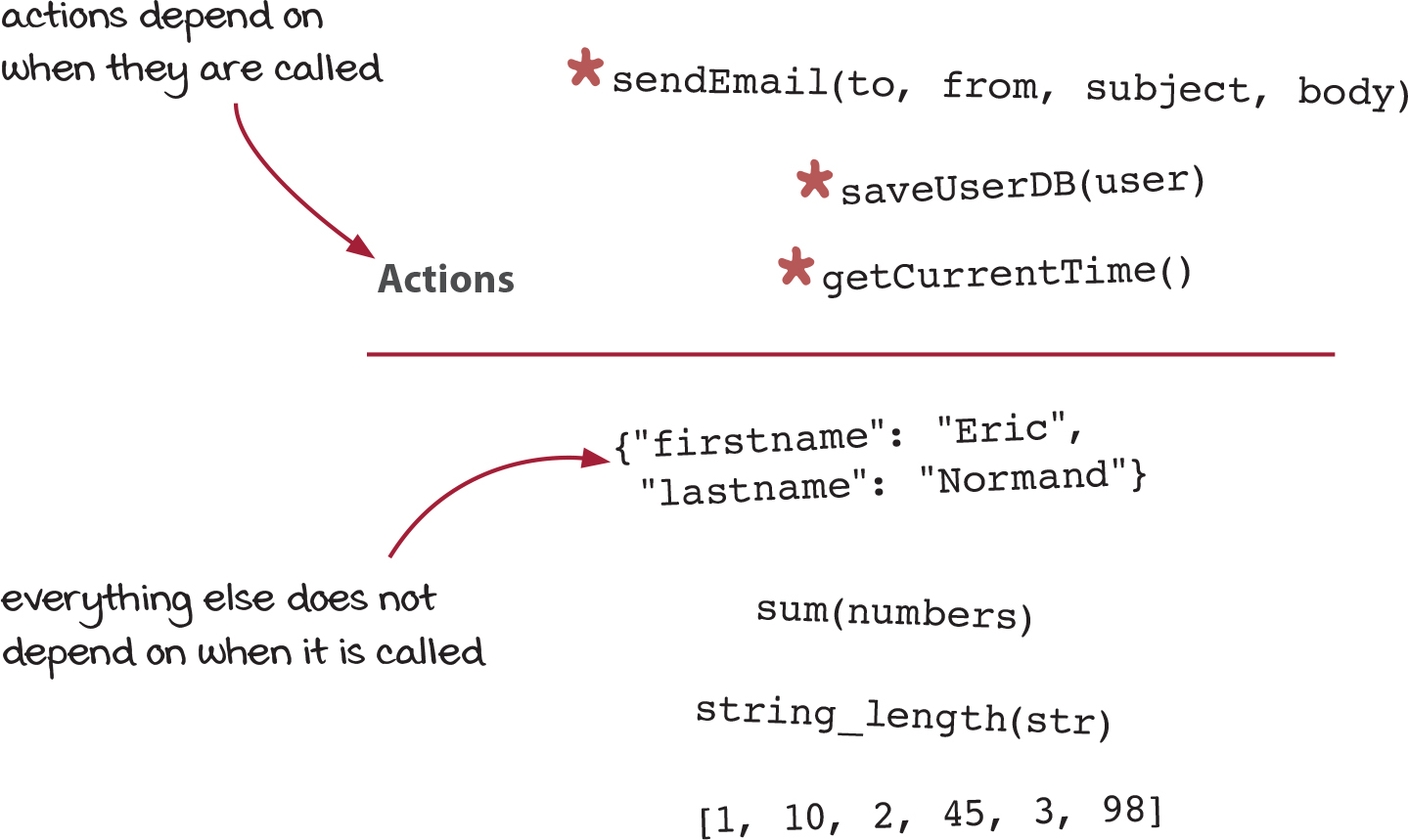
This is a very important distinction. Actions (everything above the line) depend on when they are called or how many times they are called. We have to be extra careful with them.
However, the stuff below the line is much easier to work with. It does not matter when you call a sum. It will give you the correct answer any time. And it doesn’t matter how many times you call it. It won’t have an effect on the rest of the program or the world outside the software.
But there is another distinction we can make: Some of the code is executable and some is inert. Let’s draw another line on the next page.
Functional programmers distinguish inert data from code that does work
We can draw another line between calculations and data. Neither calculations nor data depend on when or how many times they are used. The difference is that calculations can be executed, while data cannot. Data is inert and transparent. Calculations are opaque, meaning that you don’t really know what a calculation will do until you run it.

The distinction between actions, calculations, and data is fundamental to FP. Any functional programmer would agree that this is an important skill. Most other concepts and skills in FP are built on top of it.
It’s important to emphasize that functional programmers are not averse to using code in any of the three categories because they are all important. However, they do recognize the tradeoffs and try to use the best tool for the job. In general, they prefer data to calculations and calculations to actions. Data is the easiest to work with.
It’s worth emphasizing this again: Functional programmers see these categories when they look at any code. It’s the primary perspective difference of FP. There are a number of skills and concepts that revolve around this distinction. We will focus on these skills throughout the rest of Part 1.
Let’s see what this distinction can tell us about a simple task management service.
Functional programmers prefer data to calculations and prefer calculations to actions.
Functional programmers see actions, calculations, and data
Distinguishing actions, calculations, and data is fundamental to FP. You couldn’t really do FP without it. This may be obvious, but just so we are all on the same page, let’s go through a simple scenario that illustrates the three categories.
Let’s imagine a cloud service for project management. As the clients mark their tasks as completed, the central server sends email notifications.

Where are the actions, calculations, and data? In other words, how does a functional programmer see what’s going on?
Step 1: The user marks a task as completed.
This triggers a UI event, which is an action, since it depends on how many times it happens.
Step 2: The client sends a message to the server.
Sending the message is an action, but the message itself is data (inert bytes that must be interpreted).
Step 3: The server receives the message.
Receiving a message is an action, since it depends on how many times it happens.
Step 4: The server makes a change to its database.
Changing the internal state is an action.
Step 5: The server makes a decision of who to notify.**
Making a decision is a calculation. Given the same inputs, your server would make the same decision.
Step 6: The server sends an email notification.**
Sending an email is an action, since sending the same email twice is different from sending it once.
** we distinguish between deciding (calculation) and carrying out the decision (action)
If this doesn’t make sense to you now, don’t worry, because we’re going to spend the whole first part of this book understanding how to make this distinction, why we make it, and how to improve our code because of it. As we’ve talked about before, the distinction between actions, calculations, and data is the first big idea in this book.
The three categories of code in FP
Let’s go over the characteristics of the three categories:
1. Actions
Anything that depends on when it is run, or how many times it is run, or both, is an action. If I send an urgent email today, it’s much different from sending it next week. And of course, sending the same email 10 times is different from sending it 0 times or 1 time.
Actions**
- Tools for safely changing state over time
- Ways to guarantee ordering
- Tools to ensure actions happen exactly once
** FP has tools for using each category
2. Calculations
Calculations are computations from input to output. They always give the same output when you give them the same input. You can call them anytime, anywhere, and it won’t affect anything outside of them. That makes them really easy to test and safe to use without worrying about how many times or when they are called.
Calculations
- Static analysis to aid correctness
- Mathematical tools that work well for software
- Testing strategies
3. Data
Data is recorded facts about events. We distinguish data because it is not as complex as executable code. It has well-understood properties. Data is interesting because it is meaningful without being run. It can be interpreted in multiple ways. Take a restaurant receipt as an example: It can be used by the restaurant manager to determine which food items are popular. And it can be used by the customer to track their dining-out budget.
Data
- Ways to organize data for efficient access
- Disciplines to keep records long term
- Principles for capturing what is important using data

How does distinguishing actions, calculations, and data help us?
FP works great for distributed systems, and most software written today is distributed
FP is a buzzword these days. It’s important to know if it’s just a trend that will one day die down, or if there is something essential about it.
FP is not a trend. It is one of the oldest programming paradigms, which has roots in even older mathematics. The reason it is gaining popularity only now is that, due to the internet and a proliferation of devices such as phones, laptops, and cloud servers, we need a new way of looking at software that takes into account multiple pieces of software communicating over networks.
Once computers talk over networks, things get chaotic. Messages arrive out of order, are duplicated, or never arrive at all. Making sense of what happened when, basically modeling change over time, is very important but also difficult. The more we can do to eliminate a dependency on when or how many times a thing runs, the easier it will be to avoid serious bugs.
Data and calculations do not depend on how many times they are run or accessed. By moving more of our code into data and calculations, we sweep that code clean of the problems inherent in distributed systems.
The problems still remain in actions, but we’ve identified and isolated them. Further, FP has a set of tools for working with actions to make them safer, even in the uncertainty of distributed systems. And because we’ve moved code out of actions and into calculations, we can give more attention to the actions that need it most.
Three rules of distributed systems
- Messages arrive out of order.
- Each message may arrive 0, 1, or more times.
- If you don’t hear back, you have no idea what happened.
once you go distributed, things get really complicated
Why is this book different from other FP books?
This book is practical for software engineering
A lot of the discussion around FP is academic. It’s researchers exploring the theory. Theory is great until you have to put it into practice.
Many FP books focus on the academic side. They teach recursion and continuation-passing style. This book is different. Grokking Simplicity distills the pragmatic experience of many professional functional programmers. They appreciate the theoretical ideas but have learned to stick to what works.
This book uses real-world scenarios
You won’t find any definitions of Fibonacci or merge sort in this book. Instead, the scenarios in this book mimic situations you might actually encounter at your job. We apply functional thinking to existing code, to new code, and to architecture.
This book focuses on software design
It’s easy to take a small problem and find an elegant solution. There’s no need for architecture when you’re writing FizzBuzz. It’s only when things get big that design principles are needed.
Many FP books never need to design because the programs are so small. In the real world, we do need to architect our systems to be maintainable in the long term. This book teaches functional design principles for every level of scale, from the line of code to the entire application.
This book conveys the richness of FP
Functional programmers have been accumulating principles and techniques since the 1950s. A lot has changed in computing, but much has stood the test of time. This book goes deep to show how functional thinking is more relevant now than ever.
This book is language agnostic
Many books teach the features of a particular functional language. This often means that people using a different language cannot benefit.
This book uses JavaScript for code examples, which is not great for doing FP. However, JavaScript has turned out to be great for teaching FP precisely because it isn’t perfect. The limitations of the language will cause us to stop and think.
And even though it uses JavaScript for the examples, this is not a book about FP in JavaScript. Focus on the thinking, not on the language.
The code examples have been written for clarity, not to suggest any particular JavaScript style. If you can read C, Java, C#, or C++, you will be able to follow.
What is functional thinking?
Functional thinking is the set of skills and ideas that functional programmers use to solve problems with software. That’s a big set of skills. This book aims to guide you through two powerful ideas that are very important in functional programming: (1) distinguishing actions, calculations, and data and (2) using first-class abstractions. These are not the only ideas in FP, but they will give you a solid and practical foundation on which to build. And they will take you from beginner to professional functional programmer.
Each idea brings with it associated skills. They also correspond with the two parts of this book. Each part teaches practical, line-by-line and function-by-function skills and caps off with a chapter or two on design for a higher-level picture of what’s going on.
Let’s go over the two big ideas and what skills you’ll learn in each part.
Part 1: Distinguishing actions, calculations, and data
As we’ve seen, functional programmers separate all code into one of three categories: actions, calculations, or data. They may not use these same terms, but that’s what we’ll call them in this book. These categories correspond to how difficult the code is to understand, test, and reuse. We’ve already begun to discover this important distinction in this chapter. Throughout this first part of the book, we’ll learn to identify the category of any piece of code, refactor actions into calculations, and make actions easier to work with. The design chapters look at how identifying layers in our code can help make it maintainable, testable, and reusable.
Part 2: Using first-class abstractions
Programmers of all kinds will find common procedures and name them to be reused later. Functional programmers do the same but can often reuse more procedures by passing in procedures to the procedures. The idea may sound crazy, but it’s extremely practical. We’ll learn how to do it and how to avoid overdoing it. We’ll cap it off with two common designs called reactive architecture and onion architecture.
It will be quite a journey. But let’s not get ahead of ourselves. We’re still in part 1! Before we begin our journey, let’s lay out some ground rules for what we’ll learn.
Ground rules for ideas and skills in this book
FP is a big topic. We won’t be able to learn “the whole thing.” We will have to pick and choose what to learn. These ground rules will help us choose practical knowledge for the working programmer.
1. The skills can’t be based on language features
There are a lot of functional programming languages out there that have features made to support FP. For instance, many functional languages have very powerful type systems. If you are using one of those languages, that’s great! But even if you’re not, functional thinking can help you. We’ll only focus on skills that are language-feature agnostic. That means that even though type systems are cool, we will only mention them here or there.
2. The skills must have immediate practical benefit
FP is used in both industry and academia. In academia, they sometimes focus on theoretically important ideas. That’s great, but we want to keep it practical. This book will only teach skills that can benefit you here and now. In fact, the ideas we will learn are beneficial even if they don’t show up in your code. For example, just being able to identify actions can help you better understand certain bugs.
3. The skills must apply regardless of your current code situation
Some of us are starting brand new projects, with no code yet written. Some of us are working on existing codebases with hundreds of thousands of lines of code. And some of us are somewhere in between. The ideas and skills in this book should help us, regardless of our situation. We’re not talking about a functional rewrite here. We need to make pragmatic choices and work with the code we’ve got.

 Brain break
Brain break
There’s more to go, but let’s take a break for questions
Q: I use an object-oriented (OO) language. Will this book be useful?
A: Yes, the book should be useful. The principles in the book are universally applicable. Some of them are similar to OO design principles you might be familiar with. And some of them are different, stemming from a different fundamental perspective.
Functional thinking is valuable, regardless of what language you use.
Q: Every time I’ve looked into FP, it has been so academic and math-based. Is this book more of the same?
A: No! Academicians like FP because calculations are abstract and easy to analyze in papers. Unfortunately, researchers dominate the FP conversation.
However, there are many people working productively using FP. Though we keep an eye on the academic literature, functional programmers are mostly coding away at their day jobs like most professional programmers. We share knowledge with each other about how to solve everyday problems. You will find some of that knowledge in this book.
Q: Why JavaScript?
A: That’s a really good question. JavaScript is widely known and available. If you’re programming on the web, you know at least a little bit. The syntax is pretty familiar to most programmers. And, believe it or not, JavaScript does have everything you need for FP, including functions and some basic data structures.
That said, it’s far from perfect for FP. However, those imperfections let us bring up the principles of FP. Learning to implement a principle in a language that doesn’t do this by default is a useful skill, especially since most languages don’t have this by default.
Q: Why is the existing FP definition not enough? Why use the term “functional thinking”?
A: That’s also a great question. The standard definition is a useful extreme position to take to find new avenues of academic research. It is essentially asking “What can we accomplish if we don’t allow side effects?” It turns out that you can do quite a lot, and a lot of it is interesting for industrial software engineering.
However, the standard definition makes some implicit assumptions that are hard to uncover. This book teaches those assumptions first. “Functional thinking” and “functional programming” are mostly synonymous. The new term simply implies a fresh approach.
Conclusion
Functional programming is a large, rich field of techniques and principles. However, it all starts with the distinction between actions, calculations, and data. This book teaches the practical side of FP. It can apply in any language and to any problem. There are thousands of functional programmers out there, and I hope this book will convince you to count yourself among us.
Summary
- The book is organized into two parts that correspond to two big ideas and related skills: distinguishing actions, calculations, and data and using higher-order abstractions.
- The typical functional programming definition has served academic researchers, but until now, there hasn’t been a satisfactory one for software engineering. This explains why FP can feel abstract and impractical.
- Functional thinking is the skills and concepts of FP. It’s the main topic of this book.
- Functional programmers distinguish three categories of code: actions, calculations, and data.
- Actions depend on time, so they are the hardest to get right. We separate them so we can devote more focus to them.
- Calculations do not depend on time. We want to write more code in this category because they are so easy to get right.
- Data is inert and require interpretation. Data is easy to understand, store, and transmit.
- This book uses JavaScript for examples, since it has familiar syntax. We will learn a few JavaScript concepts when we need them.
Up next…
Now that we have taken a good first step into functional thinking, you might wonder what programming with functional thinking actually looks like. In the next chapter, we’ll see examples of solving problems using the big ideas that form the structure of this book.