
Creating and Populating
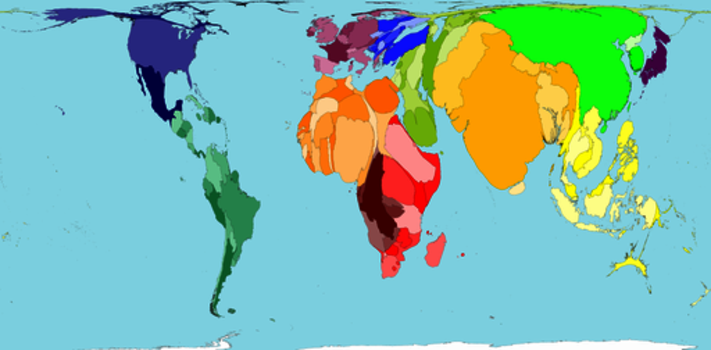
As a running example, we will use the predictions for regional populations in the year 2300, which is taken from http://www.worldmapper.org. The first table that we’ll work with, Table 30, Estimated World Population in 2300, has one column that contains the names of regions and another that contains the populations of regions, so each row of the table represents a region and its population.
|
Region |
Population (in thousands) |
|---|---|
|
Central Africa |
330,993 |
|
Southeastern Africa |
743,112 |
|
Northern Africa |
1,037,463 |
|
Southern Asia |
2,051,941 |
|
Asia Pacific |
785,468 |
|
Middle East |
687,630 |
|
Eastern Asia |
1,362,955 |
|
South America |
593,121 |
|
Eastern Europe |
223,427 |
|
North America |
661,157 |
|
Western Europe |
387,933 |
|
Japan |
100,562 |
If the countries were sized by their estimated populations, they would look like this:
As promised earlier, we start by telling Python that we want to use sqlite3:
| | >>> import sqlite3 |
Next we must make a connection to our database by calling the database module’s connect method. This method takes one string as a parameter, which identifies the database to connect to. Because SQLite stores each entire database in a single file on disk, this is just the path to the file. Since the database population.db doesn’t exist, it will be created:
| | >>> con = sqlite3.connect('population.db') |
Once we have a connection, we need to get a cursor. Like the cursor in an editor, this keeps track of where we are in the database so that if several programs are accessing the database at the same time, the database can keep track of who is trying to do what:
| | >>> cur = con.cursor() |
We can now actually start working with the database. The first step is to create a database table to store the population data. To do this, we have to describe the operation we want using SQL. The general form of a SQL statement for table creation is as follows:
| | CREATE TABLE TableName(ColumnName Type, ...) |
The types of the data in each of the table’s columns are chosen from the types the database supports:
|
Type |
Python Equivalent |
Use |
|---|---|---|
|
NULL |
NoneType |
Means “know nothing about it” |
|
INTEGER |
int |
Integers |
|
REAL |
float |
8-byte floating-point numbers |
|
TEXT |
str |
Strings of characters |
|
BLOB |
bytes |
Binary data |
To create a two-column table named PopByRegion to store region names as strings in the Region column and projected populations as integers in the Population column, we use this SQL statement:
| | CREATE TABLE PopByRegion(Region TEXT, Population INTEGER) |
Now, we put that SQL statement in a string and pass it as an argument to a Python method that will execute the SQL command:
| | >>> cur.execute('CREATE TABLE PopByRegion(Region TEXT, Population INTEGER)') |
| | <sqlite3.Cursor object at 0x102e3e490> |
When method execute is called, it returns the cursor object that it was called on. Since cur refers to that same cursor object, we don’t need to do anything with the value returned by execute.
The most commonly used data types in SQLite databases are listed in Table 31 along with the corresponding Python data types. The BLOB type needs more explanation. The term BLOB stands for Binary Large Object, which to a database means a image, an MP3, or any other lump of bytes that isn’t of a more specific type. The Python equivalent is a type we haven’t seen before called bytes, which also stores a sequence of bytes that have no particular predefined meaning. We won’t use BLOBs in our examples, but the exercises will give you a chance to experiment with them.
After we create a table, our next task is to insert data into it. We do this one record at a time using the INSERT command, whose general form is as follows:
| | INSERT INTO TableName VALUES(Value, ...) |
As with the arguments to a function call, the values are matched left to right against the columns. For example, we insert data into the PopByRegion table like this:
| | >>> cur.execute('INSERT INTO PopByRegion VALUES("Central Africa", 330993)') |
| | <sqlite3.Cursor object at 0x102e3e490> |
| | >>> cur.execute('INSERT INTO PopByRegion VALUES("Southeastern Africa", ' |
| | ... '743112)') |
| | <sqlite3.Cursor object at 0x102e3e490> |
| | ... |
| | >>> cur.execute('INSERT INTO PopByRegion VALUES("Japan", 100562)') |
| | <sqlite3.Cursor object at 0x102e3e490> |
Notice that the number and type of values in the INSERT statements matches the number and type of columns in the database table. If we try to insert a value of a different type than the one declared for the column, the library will try to convert it, just as it converts the integer 5 to a floating-point number when we do 1.2 + 5. For example, if we insert the integer 32 into a TEXT column, it will automatically be converted to "32"; similarly, if we insert a string into an INTEGER column, it is parsed to see whether it represents a number. If so, the number is inserted.
If the number of values being inserted doesn’t match the number of columns in the table, the database reports an error and the data is not inserted. Surprisingly, though, if we try to insert a value that cannot be converted to the correct type, such as the string “string” into an INTEGER field, SQLite will actually do it (though other databases will not).
Another format for the INSERT SQL command uses placeholders for the values to be inserted. When using this format, method execute has two arguments: the first is the SQL command with question marks as placeholders for the values to be inserted, and the second is a tuple. When the command is executed, the items from the tuple are substituted for the placeholders from left to right. For example, the execute method call to insert a row with "Japan" and 100562 can be rewritten like this:
| | >>> cur.execute('INSERT INTO PopByRegion VALUES (?, ?)', ("Japan", 100562)) |
In this example, "Japan" is used in place of the first question mark, and 100562 in place of the second. This placeholder notation can come in handy when using a loop to insert data from a list or a file into a database, as shown in Using Joins to Combine Tables.
Saving Changes
After we’ve inserted data into the database or made any other changes, we must commit those changes using the connection’s commit method:
| | >>> con.commit() |
Committing to a database is like saving the changes made to a file in a text editor. Until we do it, our changes are not actually stored and are not visible to anyone else who is using the database at the same time. Requiring programs to commit is a form of insurance. If a program crashes partway through a long sequence of database operations and commit is never called, then the database will appear as it did before any of those operations were executed.
Closing the Connection
Finally, when we’ve finished working with a database, we need to close our connection it to using the connection’s close method:
| | >>> con.close() |
Closing a database connection is similar to closing a file. But beware—when you close your database connection, any uncommitted changes will be lost! Make sure that you commit your changes before closing the connection.