
In this chapter, we shall review the underlying principle of cyber security – that of information risk management. This chapter is not a detailed review of the subject – you can find this in the second edition of my book Information Risk Management: A Practitioner’s Guide,1 also published by BCS.
A GENERAL VIEW OF RISK
In Part I of this book, we looked at some of the impacts of cyber-attacks, the threats that can cause them and some of the possible motives behind an attack. Impacts and consequences are just two of the elements of risk management. The others are assets – the things we care about; vulnerabilities – those things that weaken our defences against cyber-attacks; and likelihood or probability – the chance that the threat will be successfully carried out.
We have already covered impacts in Chapter 4 and threats in Chapter 5, both in some detail, so let’s consider the others.
Figure 6.1 shows the relationship between the various elements of risk and is described in the following paragraphs.
Figure 6.1 A general view of the risk environment
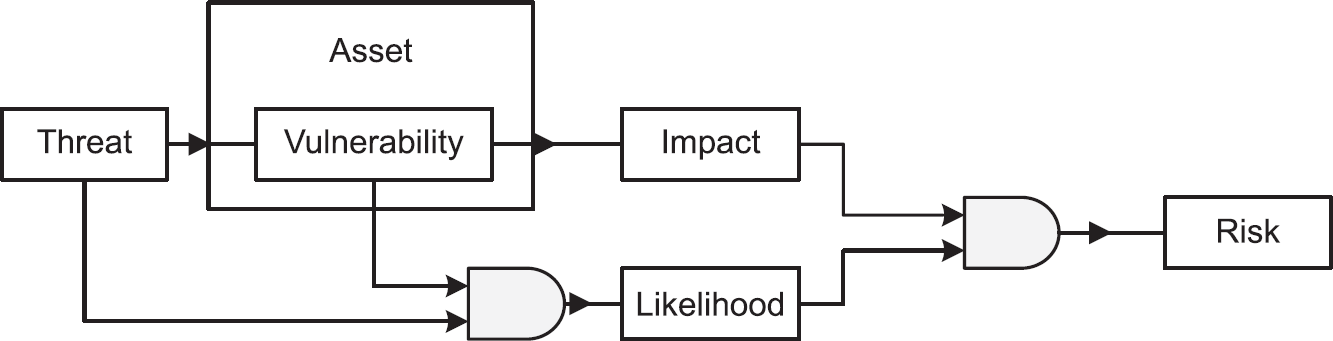
Looking at the relationship between these elements, we can see that threats act on a vulnerability in an asset, which in turn leads to an impact. Threats also, when there is motivation, combine with the existence of a vulnerability to provide us with the likelihood or probability of the threat being carried out. Following this, impacts and likelihood combine to produce risk.
However, there are two sides to the question of motivation – on one hand, there are attackers who have a strong motive and determination for carrying out the attack, while on the other, there are script kiddies who happen upon an exploit and try it out to see what happens (inquisitiveness). When combined with a vulnerability, either situation can result in the likelihood being high.
Occasionally, people confuse ‘threats’ with ‘risks’. They may say that there is the risk of rain when they actually mean there is the threat of rain. The risk is that if it does rain, we might get wet as a result. As we shall see later, the difference is subtle, but important when it comes to information risk management.
It is also not unusual for people to confuse probability and likelihood. As we shall see later in this chapter, there is a considerable difference between them, probability being an objective assessment with some form of statistical underpinning, and likelihood being subjective, based on emotions and gut feel.
There are inherent risks in many areas of cyber security, the main one being the possibility that despite all efforts to secure the organisation, an attacker may still find a way of accessing a system and causing damage.
Now let us look at some of the terms used in information risk management.
ASSETS
Assets in the wider sense can be almost anything, but in cyber security terms, assets can include not only the data – information we may be trying to protect – but also the complete technical infrastructure – hardware, software, data and information, HVAC and premises. Last, but by no means least, are the staff who have the technical knowledge and skills to design, implement and manage the appropriate security measures, to maintain them and to respond to incidents.
Although I have drawn the distinction between data and information, for the purposes of this book I have considered both to be assets that have value for their owners and must be equally protected, although the owner of the original data and the owner of the resulting information may be entirely different entities.
THREATS
Threats are things or events that take advantage of vulnerabilities in order to cause some form of harm to assets. They may be differentiated from hazards that, although they too can cause harm to assets, are generally found more in the physical environment. Examples of hazards are fire, storms, floods, earthquakes and so on. Examples of threats in the cyber security area can be found in Chapter 5.
Vulnerabilities are things that reduce the level of security within assets and come in two distinct varieties. Intrinsic vulnerabilities are inherent in the very nature of an asset, such as the ease of erasing information from magnetic media (whether accidental or deliberate), whereas extrinsic vulnerabilities are those that are poorly applied, such as software that is out of date due to a lack of patching, or vulnerable due to poor coding practices.
When threats exploit vulnerabilities, this results in an impact to an asset, as shown in Figure 6.1, whether data that is copied or stolen (confidentiality), data that is changed or damaged (integrity) or access to data is prevented (availability).
Vulnerabilities can exist without our knowledge. There may be security issues with an operating system or a bug in an application that a hacker has discovered but is unknown to the software vendor and the end user – this type of vulnerability is called a zero-day vulnerability.
One of the biggest problems with this kind of vulnerability is that once it becomes known to the hacking community it will usually be ruthlessly exploited until a fix is developed – and more importantly, applied. Once the software vendor announces the fix, knowledge of the vulnerability becomes even wider, and will often result in increased attacks, and an added danger is that individuals and organisations will fail to apply the fix, placing themselves at greater risk.
An interesting twist on the publication of known vulnerabilities is the situation in which attackers reverse engineer the vulnerabilities in order to design and build dedicated attack tools.
Other vulnerabilities are more obvious – such as the lack of antivirus software, which can allow malware to reach the target through email. Disaffected staff can either allow malware through the organisation’s defences by reconfiguring them, or by bypassing them completely, introducing malware on a USB stick for example. Computers without passwords, or with default passwords for operating system software and application software or passwords that are shared, present easy pickings for even the least experienced attacker.
As we shall see later in this chapter, and also in Chapters 7 to 11, removing or reducing vulnerabilities will go a considerable way towards improving cyber security.
LIKELIHOOD OR PROBABILITY
The chance that something will happen is called the likelihood. Sometimes the term ‘probability’ is used instead, but it is useful to understand, for our purposes, that there is a considerable difference between the two.
Likelihood is a rather subjective term. If there are dark clouds in the sky, it may rain – but then again it may not. All we can say is that there is the likelihood of rain, and we may think that the chance of rain may be greater or lesser, depending on the amount of cloud. It is not an especially scientific method of predicting the weather but provides us with a general guide as to whether or not we should carry an umbrella.
Probability on the other hand is much more objective in nature. Probability relies on data – usually statistical data – that will underpin our judgement, and is often expressed in percentage terms. Again, it may be incorrect or expressed as having a margin of error, but at the very least, probability has a rather more scientific basis than likelihood. Sometimes you may hear of likelihood being referred to as a qualitative assessment, whereas probability is sometimes referred to as a quantitative assessment.
QUALITATIVE AND QUANTITATIVE ASSESSMENTS
One of the problems we face in information risk management is deciding which of the two types of measure to use – a subjective assessment of likelihood or an objective assessment of probability. In fact, one commonly used technique is to combine the two, referred to as semi-quantitative and semi-qualitative – for example, to use ranges of numerical values to improve the subjective nature of both impact and likelihood, as shown in Tables 6.1 and 6.2.
Table 6.1 Typical impact scales
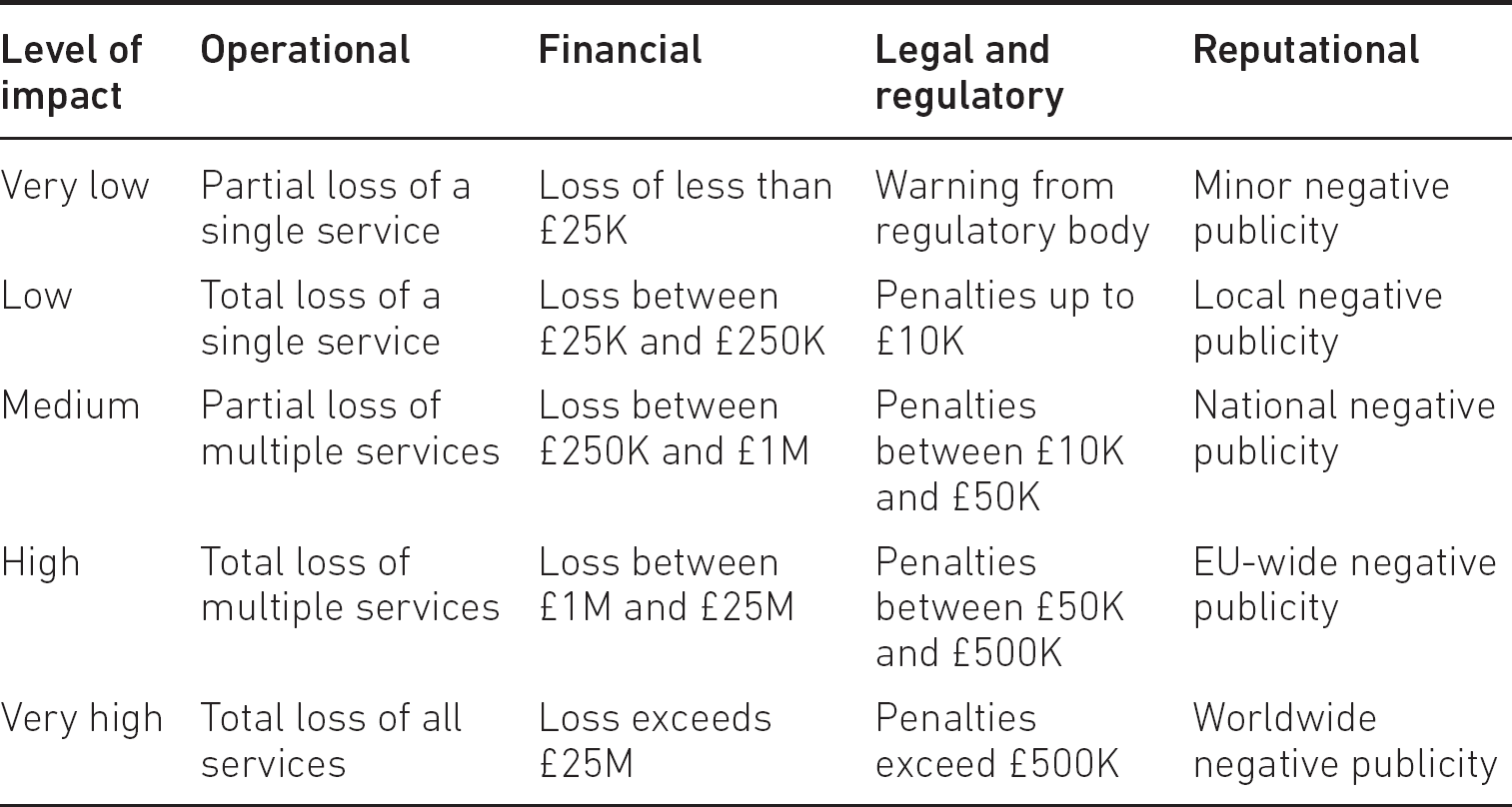
Although we have provided boundaries for the levels, there will be a degree of uncertainty about the upper and lower limits of each, but in general the ranges should be sufficient to provide a fairly meaningful assessment. Clearly these ranges will differ from one scenario to another but set a common frame of reference when there are a substantial number of assessments to be carried out.

THE RISK MANAGEMENT PROCESS
The generic process for managing risk is illustrated in Figure 6.2. Since we are only taking a brief look at risk management, we will focus on context establishment, risk assessment and risk treatment and omit the communication and consultation, and monitoring and review stages. A more detailed explanation of all of these stages is given in Information Risk Management: A Practitioner’s Guide.2
Figure 6.2 The overall risk management process
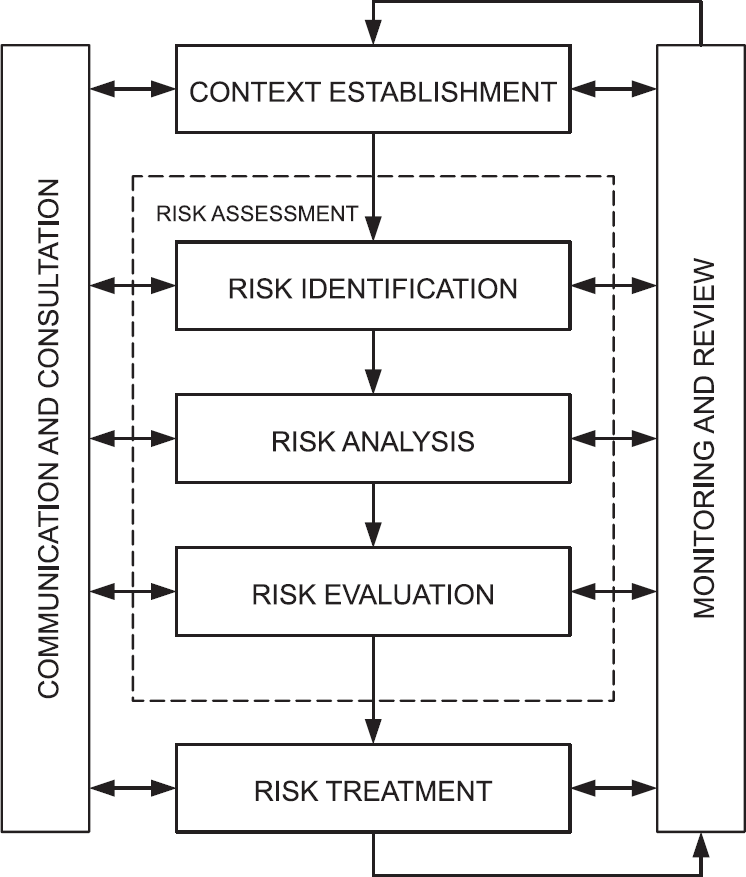
If we look at just the basic components of risk as described above, we can certainly make some form of assessment, but unless this is placed within the context in which the organisation operates, any judgement will have been taken in isolation.
The first stage of the risk management process then is to understand the context in which the organisation operates – financial, commercial and political – so that the later steps take these into account when making decisions about how to treat the risks.
Risk assessment
This second stage of the risk management process is broken down into three distinct areas: risk identification, risk analysis and risk evaluation.
Risk identification
Risk management begins by identifying the assets, deciding what value they have to the organisation, and therefore what the impact might be if they were damaged or lost. All assets require a single clearly identified owner who will have overall responsibility for the asset, even if the asset is shared between a number of departments in an organisation.
Some organisations mistakenly allocate ownership of information assets to the IT department, but this (unless it is an IT-specific asset) is a mistake, since the IT department can easily become the unwitting owner of many assets over which they have little or no influence, despite the assets being held on the IT department’s systems. Only the true owner of the asset will be able to estimate its value to the organisation.
Once we have established the assets, their ownership and their value to the organisation, we can move on to understand what might threaten these assets and what (if any) vulnerabilities the assets have, which provides us with a basis for deciding on both the impact or consequence and likelihood or probability.
There is an ongoing debate about which aspects of risk identification come in which order. Some people feel that it is easier to identify the impacts if they understand the threats first; others feel that threat assessment can come later. Whichever approach you favour, it is important that you assess:
- the threats the assets face;
- the potential impact or consequence of the loss or degradation of those assets;
- the vulnerabilities that might contribute to this;
- the likelihood or probability that the threats will exploit the vulnerabilities resulting in an impact.
When assessing the threats, we can make use of a number of models – one of these is referred to by the initial letters D.R.E.A.D. and asks five questions:
- Damage – how bad would an attack be?
- Reproducibility – how easy is it to reproduce the attack?
- Exploitability – how much work is required to launch the attack?
- Affected users – how many people will be impacted?
- Discoverability – how easy it is to discover the threat?
Although rather subjective, the answer to each question is allocated a value (say between 1 for ‘low’ and 3 for ‘high’), and the sum of the five elements delivers the relative threat level.
Impact and likelihood are the two key outputs of this part of the process, and as mentioned earlier there are two methods of deciding the level of them:
- qualitative impact and likelihood assessment;
- quantitative impact and likelihood assessment.
In the case of the qualitative assessment, the outputs are measured in general subjective terms, such as low, medium and high, whereas in quantitative assessment, objective numerical data is used – for example, financial values for impact and percentages for likelihood.
Each method has its own merits – qualitative assessment can be carried out quite quickly (often based on ‘gut feel’) and does not require detailed research or investigation, whereas quantitative assessment can be time-consuming but will usually deliver more meaningful results.
It is for the organisation to decide whether such a high degree of accuracy adds value to the assessment exercise – if the resulting risk is very high, the problem will require urgent attention, regardless of whether the risk comes out at 90 per cent or 95 per cent.
As already mentioned, there is, however, a halfway house in which qualitative and quantitative assessments are combined in a ‘semi-quantitative’ assessment. In these, boundaries are set for the values – for example for impact assessments, ‘low’ might indicate a financial value between zero and one million pounds; ‘medium’ might indicate a financial value between one million and ten million pounds; and ‘high’ might indicate a financial value above ten million pounds.
Similarly, for likelihood assessments, ‘low’ might indicate a likelihood between zero and 35 per cent; ‘medium’ might indicate a likelihood between 35 per cent and 70 per cent; and ‘high’ might indicate a likelihood above 70 per cent.
This provides a more meaningful assessment of risk, especially when presenting a business case to the board for approval.
Risk analysis
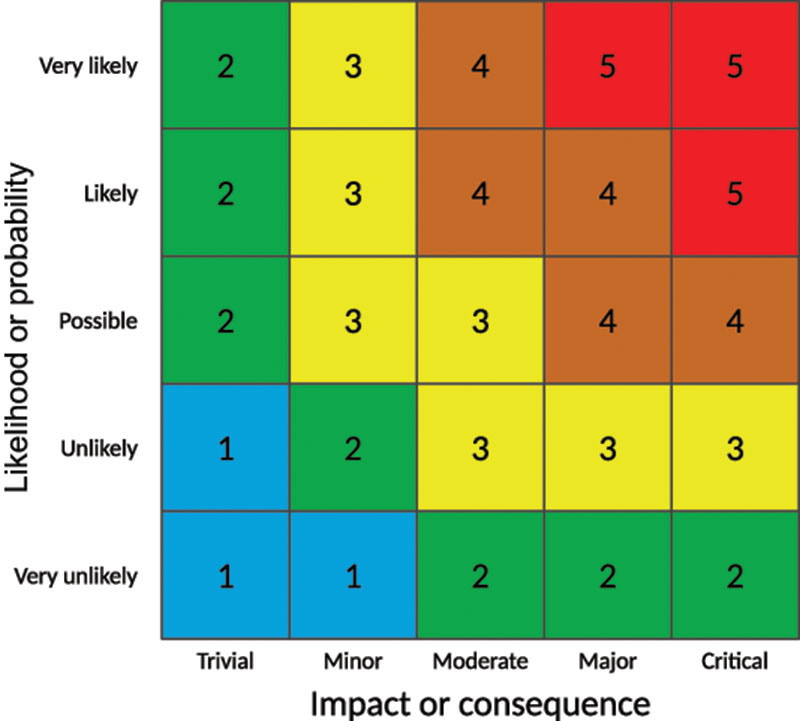
Once we have conducted the initial risk identification, we then take the impact and likelihood and combine them in the form of a risk matrix as shown in Figure 6.3, which will allow us to compare the risk levels.
The risk matrix is simply a pictorial representation of the relative levels of all the risks we have identified, and which will help us to understand the order in which we wish to treat them, based on some form of priority or urgency.
Risk matrices most commonly consist of three, four or five ranges of values. Three is often considered to be too few to be meaningful, while five allows the possibility of too many results being in the middle. Four is sometimes thought to be a better choice, since the assessor must choose some value either side of the middle ground, avoiding the problem of a large number of risks being rated ‘medium’.
In conjunction with others, the risk assessor will allocate a risk category to each part of the matrix, in order to assist prioritisation. Alternatively, values can be assigned to each cell in the matrix, which enables grouping of risks. A typical example of a risk matrix is shown in Figure 6.3, where the values of each axis are multiplied together to provide a measurement of the risk.
Risks measuring 1 to 5 might be graded as trivial; 6 to 10 might be minor; 11 to 15 might be moderate; 16 to 20 might be major; and 21 to 25 might be critical.
Figure 6.3 A typical risk matrix
Risk evaluation
Finally, we can decide how we are going to deal with the various risks, usually recording the results in a risk register. There are four ways in which we can deal with or treat them, as shown in Figure 6.4.
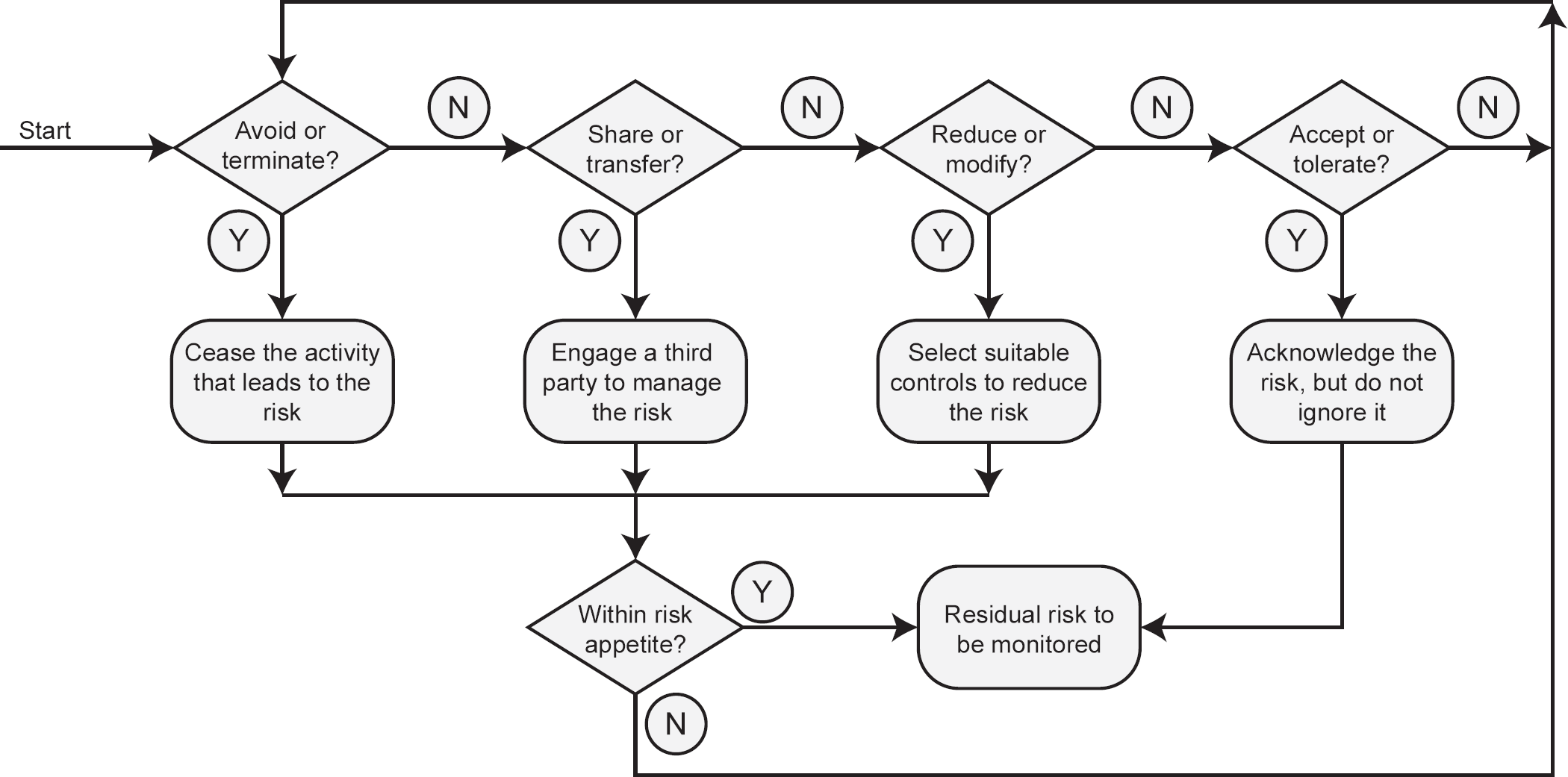
Risk avoidance or termination In this method of risk treatment, we either stop doing whatever it is that has caused or might cause the risk, or if it is a planned activity we simply avoid doing it. While this will usually result in the risk being completely eliminated, it may cause the organisation other problems, for example if an organisation was planning to build a data centre and the risk assessment indicated a high likelihood of flooding in the proposed location, the decision would almost certainly be to avoid the risk by abandoning that location and building elsewhere. However, this might prove problematic, since alternative sites might be difficult to identify, be excessively costly or have other limiting factors. This would result in the organisation reviewing all these risks against one another.
Risk sharing or transfer If we find that we cannot avoid the risk, an organisation may decide to share it with a third party. This is usually in the form of insurance, but it is important to remember that even though the organisation may let someone else share or take the risk, they still own the responsibility for it.
However, some insurance companies will refuse to insure certain types of risk, particularly when the full possible impact is unknown, and in such cases the organisation must find an alternative method of dealing with it.
Risk reduction or modification Some people refer to this as risk treatment, although it is actually just one form of risk treatment. In this option, we do something that will reduce either the impact of the risk or its likelihood, which in turn may require that we reduce either the threat or the vulnerability where this is possible.
It is often the case that threats cannot be reduced – one cannot, for example, remove the threat of a criminal attempting to hack into an organisation’s website, but it may in such cases be possible to reduce the likelihood by applying strict firewall rules or other countermeasures.
Risk acceptance or tolerance The final option is to accept or tolerate the risk, especially if it has a very low impact or likelihood. This is not to be confused with ignoring risk – never a sensible option – but is undertaken knowingly and objectively and is reviewed at intervals or when a component of the risk changes, such as the asset value, the threat level or the vulnerability.
Risk acceptance is based largely on the organisation’s attitude to risk, known as its risk appetite. Some organisations have a very low risk appetite – for example pharmaceutical companies, who understand that the impact of failure to keep details of their products secure can mean enormous financial loss if they are stolen, or that patients could die if the manufacturing process is tampered with.
On the other hand, organisations like petrochemical companies will have a much higher risk appetite, investing vast sums of money in test drilling for oil reserves, knowing that some attempts will produce no useful results.
Residual risk While some forms of risk treatment will completely remove the risk, others will inevitably leave behind an amount of residual risk. This residual risk is either not possible to treat, or, more frequently, too expensive when compared to the cost of the likely impact. Residual risk must be accepted by the organisation and will require monitoring and regular reviews to ensure that it does not grow and become a treatable risk.
Risk treatment
Once we have decided the most appropriate method of treating risks, we move to the final stage of the risk management process – risk treatment and the use of controls or countermeasures to carry out our decisions.
Risk treatment is also sometimes referred to as risk mitigation, which is generally taken to mean a reduction in the exposure to risk (the impact or consequence) and/or the likelihood or probability of its occurrence.
There are four distinct types of controls:
- detective controls, which allow us to know or be made aware when something has happened or is actually happening;
- directive controls, which invoke some form of procedure that must be followed;
- preventative controls, which stop something from happening;
- corrective controls, which fix a problem after it has happened.
Directive and preventative controls are proactive in nature, since they are carried out before an attack has occurred in order to reduce its impact or the likelihood of it occurring.
Detective and corrective controls are reactive in nature since they take effect once an attack is already happening or has actually happened.
The four types of control are implemented in one of three ways:
- Procedural controls, which dictate what actions must be taken in a particular situation. An example of a procedural control would be one in which users are required to change their system access passwords at regular intervals. Procedural controls might include the vetting of staff by the HR department.
- Physical controls, which prevent some form of physical activity from taking place, such as fitting locks on computer room doors to prevent unauthorised entry.
- Technical controls, which change the way in which some form of hardware or software operates, such as configuring firewall rules in a network.
Sometimes, the risk treatment options – avoid/terminate, share/transfer, reduce/modify and accept/tolerate – are referred to as strategic risk treatment controls; the four types of control – detective, directive, preventative and corrective – can be referred to as tactical risk treatment options; and finally, the three methods of implementing the controls – procedural, physical and technical – are sometimes referred to as operational controls.
Although it is not strictly speaking an information risk topic, for many years, and for a variety of purposes, organisations have linked the risk management process with a system known as the Plan–Do–Check–Act (PDCA) cycle, otherwise known as the Deming cycle,3 illustrated in Figure 6.5.
Figure 6.5 The Plan–Do–Check–Act cycle
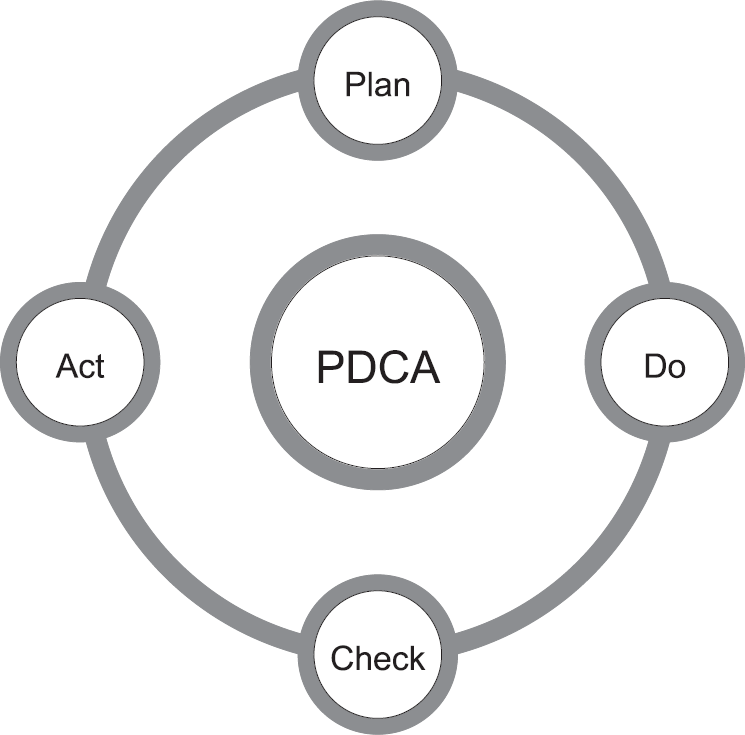
The PDCA cycle has been widely adopted as a basic reference framework in the cyber security, information security, information risk management and business continuity management disciplines as well as in many others.
The four stages are described as follows:
Plan
In this stage, we establish the objectives and the processes necessary to deliver the required results. In the cyber security context, this equates to understanding the organisation and its context.
Do
The next stage of the process implements the plan, initially as a means of testing that the plan has been successful. In the cyber security context, this equates to implementation of the information risk management framework.
Check
In this stage, we examine the results we have achieved by either measurement or observation. In the cyber security context, this equates to testing, monitoring and review of the framework.
In the final stage, we put the validated plans into action when an incident occurs and bring lessons learned from incidents into revisions of the plan. In the cyber security context, this equates to continual improvement of the framework.
Although the descriptions above relate to the wider area of information risk management, in cyber security terms any of these methods can be used to treat risk, since cyber threats can be made equally easily against poor procedures, a lack of good physical security and poor technical security.
We will examine the kinds of controls best suited to cyber security in Chapters 7 to 11.
1. David Sutton (2021) Information Risk Management: A Practitioner’s Guide. Second edition. Swindon: BCS.
2. David Sutton (2021) Information Risk Management: A Practitioner’s Guide. Second edition. Swindon: BCS.
3. See http://whatis.techtarget.com/definition/PDCA-plan-do-check-act