In this chapter, we will talk about the basic administrative tasks and tools to manage data and its consistency.
There are three features in Cassandra that can make data consistent, and they are as follows:
- Hinted handoff
- Manual repair
- Read repair
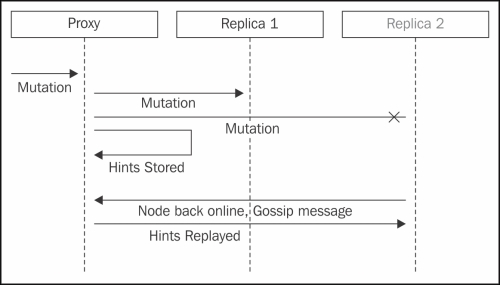
Hinted handoff is the process in which if the write is not successful on a node or the node is not able to complete the writes in time, a hint is stored in the coordinator to be replayed at a later point in time when the node is back online.
The downside of this approach is that a node that has been down for a long time comes back online; all the nodes will start to replay hints in order to make the node consistent. These processes can eventually overwhelm the node with hint replay mutations. To avoid this situation, Cassandra replays are throttled by replaying a configured amount of bytes at a time and waiting for the mutations to respond; refer to hinted_handoff_throttle_in_kb to tune this number.
To avoid storing hints for a node that is down for a long time, Cassandra allows a configurable time window after which the hints are not stored (refer to max_hint_window_in_ms
in
Cassandra.yaml). For larger deployments, it might work fine, but might not work that well for a multi-DC setup. Hints replay will be naturally throttled by the latency (more than 40 milliseconds) that will cause the hints to replay forever. We can rectify this by increasing the number of threads involved in the replay (refer max_hints_delivery_threads
in Cassandra.yaml).
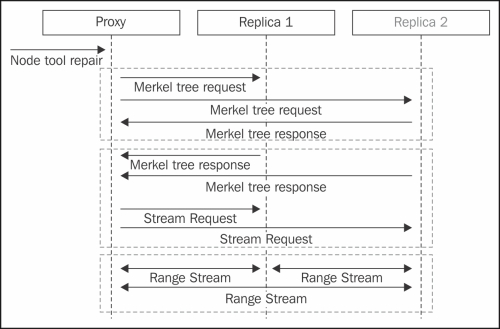
To make the data consistent, as administrators, we should repair the nodes at regular intervals. Manual repair or node tool repair is one such way to force Cassandra's nodes to sync the data. Manual repair or anti-entropy repair contains three stages:
- Validation compaction
- Exchange of Merkle trees and finding the inconsistencies
- Streaming
The repair process starts by the user executing the command on a node to repair the given range of data. The node in turn sends a request for validation compaction to all the replicas of the range then waits for the compaction to complete. Validation compaction is the stage in which the node constructs a Merkle tree of the data. Once the Merkle tree is constructed as a result of the validation compaction, the nodes send back the Merkle tress to the coordinating node.
The coordinating node now has all the trees of the entire node for comparison to identify data inconsistencies. Once the inconsistencies are identified, the node sends the ranges to the node to stream inconsistent data back and forth.
It is worth noting that the coordinator doesn't know which data is right, and hence Cassandra exchanges the data both ways and lets the compaction fix the inconsistency. The basic idea of manual repair is to be network-friendly. We don't want to move all the data to be streamed and compared (which will be lot more expensive). In other words, repair is very similar to Linux rsync. If a file is found to be inconsistent, the whole file is sent across. Streaming is the phase of repair where the inconsistent data file chunks are exchanged between the nodes.
There are many cases where the repairs can be too expensive. For example, the depth of comparison for inconsistency is not tunable and large, thereby saving runtime memory usage. This can cause a bigger range to be streamed every time there is a small inconsistency in the range of interest, and this is followed by a huge compaction in the receiving end. To avoid this, Cassandra supports incremental repair that can be used to make the whole repair process predictable and quicker to complete.
The following command is for the node tool repair:
nodetool repair –pr nodetool repair –st <Start token> -et <end token>