
In this section we will first learn about various important components of Impala and then discuss the intricate details on Impala inner workings. Here, we will discuss the following important components:
- Impala daemon
- Impala statestore
- Impala metadata and metastore
Putting together the above components with Hadoop and an application or command line interface, we can conceptualize them as seen in the following figure:
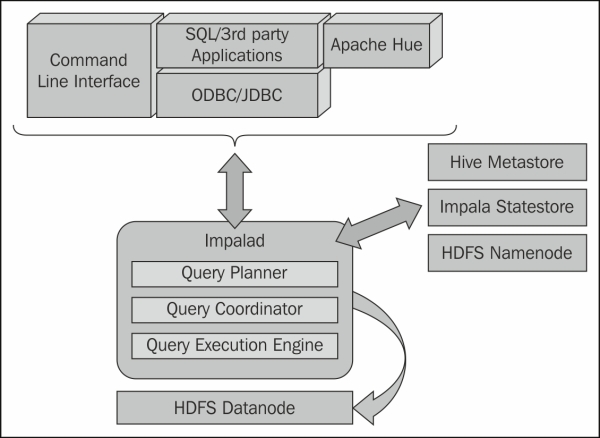
Let's starts discussing the core Impala components in detail now.
At the core of Impala, there exists the Impala daemon, which runs on each DataNode where Impala is installed. The Impala daemon is represented by an actual process named impalad. This Impala daemon process impalad is responsible for processing the queries, which are submitted through Impala shell, API, and other third-party applications connected through ODBC/JDBC connectors or Hue.
A query can be submitted to any impalad running on any node, and that particular node serves as a "coordinator node" for that query. Multiple queries are served by impalad running on other nodes as well. After accepting the query, impalad reads and writes to data files and parallelizes the queries by distributing the work to other Impala nodes in the Impala cluster. When queries are processing on various impalad instances, all impalad instances return the result to the central coordinator node. Depending on your requirement, queries can be submitted to a dedicated impalad or in a load balanced manner to another impalad in your cluster.
Impala has another important component called Impala statestore, which is responsible for checking the health of each impalad, and then relaying each impala daemon health to other daemons frequently. Impala statestore is a single running process and can run on the same node where the Impala server or any other node within the cluster is running. The name of the Impala statestore daemon process is statestored. Every Impala daemon process interacts with the Impala statestore process providing its latest health status and this information is relayed within the cluster to each and every Impala daemon so they can make correct decisions before distributing the queries to a specific impalad. In the event of a node failure due to any reason, statestored updates all other nodes about this failure, and once such a notification is available to other impalad no other Impala daemon assigns any further queries to the affected node.
One important thing to note here is that even when the Impala statestore component provides a critical update on the node in trouble, the process itself is not critical to the Impala execution. In an event where the Impala statestore becomes unavailable, the rest of the node continues working as usual. When statestore is offline, the cluster becomes less robust, and when statestore is back online it restarts communicating with each node and resumes its natural process.
Another important component of Impala is its metadata and metastore. Impala uses traditional MySQL or PostgreSQL databases to store table definitions. While other databases can also be used to configure the Hive metastore, either MySQL or PostgreSQL is recommended. The important details, such as table and column information and table definitions are stored in a centralized database known as a metastore. Apache Hive also shares the same databases for its metastore, because of which Impala can access the table created or loaded by Hive if all the table columns use the supported data types, data format, and data compression types.
Besides that, Impala also maintains information about the data files stored on HDFS. Impala tracks information about file metadata, that is, the physical location of the blocks about data files in HDFS. Each Impala node caches all of the metadata locally, which can expedite the process of gathering metadata for a large amount of data, distributed across multiple DataNodes. When dealing with an extremely large amount of data and/or many partitions, getting table specific metadata could take a significant amount of time. So a locally stored metadata cache helps in providing such information instantly.
When a table definition or table data is updated, other Impala daemons must update their metadata cache by retrieving the latest metadata before issuing a new query against the table in question. Impala uses REFRESH when new data files are added to an existing table. Another statement, INVALIDATE METADATA, is also used when a new table is included, or an existing table is dropped. The same INVALIDATE METADATA statement is also used when data files are removed from HDFS or a DFS rebalanced operation is initiated to balance data blocks in HDFS.
Impala provides the following ways to submit queries to the Impala daemon:
- Command-line interface through Impala shell
- Web interface through Apache Hue
- Third-party application interface through ODBC/JDBC
The Impala daemon process is configured to listen to incoming requests from the previously described interfaces via several ports. Both the command-line interface and web-based interface share the same port; however, JDBC and ODBC use different ports to listen for the incoming requests. The use of ODBC- and JDBC-based connectivity adds extensibility to Impala running on the Linux environment. Using ODBC and JDBC third-party applications running on Windows or other Linux platforms can submit queries directly to Impala. Most of the third-party Business Intelligence applications use JDBC and ODBC to submit queries to the Impala cluster and the impalad processes running on various nodes listen to these requests and process them as requested.