
Before we dive into more details on the separate components of the message broker and their implementation, you can refer to Appendix A, Contributing to RabbitMQ on how to get the RabbitMQ source code so that you can review it as we move through the components and also how to install useful tools that will aid in Erlang development and RabbitMQ plugin development, in particular.
The RabbitMQ boot component provides one of the key mechanisms in the message broker that allows the plugins to require certain steps from the RabbitMQ server in order to ensure that the components that they depend on are already loaded and it also allows the plugins to be installed and enabled in the RabbitMQ message broker. For this reason, it is advisable to write plugins with caution as they can crash the message broker if they are not implemented properly. Before the RabbitMQ boot mechanism is triggered, the common rabbit_sup process supervisor (the root of the RabbitMQ process tree) is started by calling the rabbit_sup:start_link() method from the start/2 method in the rabbit module. After the process supervisor starts, a series of boot steps are executed by calling the rabbit_boot_steps:run_boot_steps() method. The boot steps are divided into groups, as follows:
external_infrastructure: This prepares the infrastructure for the RabbitMQ server (such as, worker pool, file handle cache, and Mnesia database)kernel_ready: This initializes the core functionality of the message broker (such as plug-in registry, message logging, and statistics collection)core_intialized: This initializes the additional functions of the message broker (such as memory alarms, distribution of messages among queues, cluster node notifications, and memory monitoring)routing_ready: This initializes more startup activities (such as recovery of queues, exchanges and bindings, and initialization of queue mirrors)final steps: This performs the final startup activities (such as error log initialization, initialization of TCP listeners for configured interfaces, initialization of processes that are used to handle client connection, and sending of notifications to join the current RabbitMQ cluster)
The steps are organized in a directed acyclic graph and each step may specify predecessor steps that may be executed first and successor steps that might be execute after the current step. For example, the following boot step is used to add mirrors to the queues based on the mirroring policies that are defined in the message broker:
-rabbit_boot_step({mirrored_queues,
[{description, "adding mirrors to queues"},
{mfa, {rabbit_mirror_queue_misc, on_node_up, []}},
{requires, recovery},
{enables, routing_ready}]}).It requires the recovery step to be executed beforehand and enables the execution of the routing_ready step. The routing_ready step represents a group (and all other groups that are mentioned earlier are represented as steps):
-rabbit_boot_step({routing_ready,
[{description, "message delivery logic ready"},
{requires, core_initialized}]}).Each group step represents a barrier for the execution of steps from the next group. In the preceding example, the routing_ready group requires the core_initialized step to have been completed (and the core_initialized step will finish after all the steps that enable the core_initialized have finished executing).
The sequence of steps that are executed during the boot process is as follows:
- The
external_infrastructuregroup steps are as follow:codec_correctness_check: This checks whether the AMQP binary generator is working correctly and is able to generate the correct AMQP frames.rabbit_alarm: This enables the RabbitMQ alarm handlers (disk and memory); when the memory grows beyond a threshold or disk space drops below a limit, alarms are triggered in order to notify the broker that it must block subsequent connections to the broker.database: This prepares the Mnesia database.database_sync: This starts themnesia_syncprocess.file_handle_cache: This handles file read/write synchronization.worker_pool: This provides a mechanism to limit the maximum parallelism for a job (jobs can be executed synchronously or asynchronously). It is used for some operations in the message broker, such as executing transactions in the Mnesia database.
- The
kernel_readygroup steps are shown in the following: - The following are the
core_initializedgroup steps:rabbit_memory_monitor: This starts therabbit_memory_monitorprocess.guid_generator: This starts therabbit_guidprocess that provides a service for the generation of unique random numbers across the RabbitMQ service instance that is used for various purposes (such as use in autogenerated queue names).delegate_sup: This starts a process manager that is used to spread the tasks among child processes (for example, to send a message from an exchange to one or more queues).rabbit_node_monitor: This starts therabbit_node_monitorprocess.rabbit_epmd_monitor: This starts therabbit_epmd_monitorprocess.
- The
routing_readygroup steps are as follows:empty_db_check: This verifies that the Mnesia database runs fine and if necessary, inserts the default database data (such as guest/guest user and default vhost).recovery: This recovers the bindings between exchanges and queues and starts the queues.mirrored_queues: This adds mirrors to queues, as defined by the mirroring policies.
- The following are the final boot steps:
log_relay step: This starts therabbit_error_loggerprocess.direct_client: This starts the supervisor tree that takes care of accepting direct client connections.networking: This starts up thetcp_listener_suphandlers for each combination of TCP interface/port that will accept incoming connections for the message broker.notify_cluster: This notifies the current cluster that a node is started.background_gc: This starts thebackground_gcprocess that provides a service to force garbage collection on demand.
As additional reading on the boot process of RabbitMQ, the entries from the following GitHub repository at https://github.com/videlalvaro/rabbit-internals can be reviewed.
Plugin's loading is triggered by the broker_start() method in the rabbit module once the boot steps of the message broker has finished executing. To recall briefly, the following table lists the configuration properties that are related to RabbitMQ plugins:
|
RABBITMQ_PLUGINS_DIR |
The directory where RabbitMQ plugins are found |
|
RABBITMQ_PLUGINS_EXPAND_DIR |
The directory where the enabled RabbitMQ plugins are expanded before starting the messaging server |
|
RABBITMQ_ENABLED_PLUGINS_FILE |
The location of the file that specifies which plugins are enabled |
The start() method of the rabbit_plugins module is called and it clears the plugins expand directory, reads a list of the enabled plugins from the enabled plugins file, reads the location of the RabbitMQ plugin directory, builds a dependency graph from the list of all the plugins in that directory from where the enabled plugins and their dependencies are retrieved, and finally, they are unzipped to the plugins expand directory. The start_apps() method that uses the app_utils module is then called in order to load the plugins; the application module (module that implements the application behavior) of each plugin is loaded and the start() method of the plugins application is called.
For the recovery component, we will understand two particular steps from the boot process, as follows:
- queue, exchange and binding recovery: This is provided by the retrieves information about the items from Mnesia such as durable queues and exchanges along with the bindings between them and starts the queues. For this purpose, the
recover()method from therabbit_policy,rabbit_amqqueue,rabbit_binding, andrabbit_exchangemodules are used. Therabbit_amqqueuemodule recovers queues by first retrieving durable queues from the Mnesia database. Then, two processes for transient and persistent message storing (represented by therabbit_msg_storemodule) are started and bound to therabbit_supsupervisor process (this is done by calling thestart()method from therabbit_variable_queuedefault backing module). After this, a queue supervisor of all the queue-related supervisors from therabbit_amqqueue_sup_supmodule is started. Finally, the durable queues are recovered by starting arabbit_amqqueue_supqueue supervisor process for each queue (from therabbit_amqqueue_sup_supsupervisor, which specifies the child specification for the child processes in itsinit()method). Each queue supervisor process starts one queue process (represented by therabbit_amqqueue_processmodule) and one queue slave process for queue mirroring (represented by therabbit_mirror_queue_slavemodule). Once the recovery is completed, thestart()method from therabbit_amqqueuemodule is invoked, which triggers thego()method inrabbit_mirror_queue_slavethat further invokes (via thegen_server2module RPC) thehandle_go()method. This joins the queue slave process for the particular queue to a group of processes in order to distribute information in a broadcast manner among these processes. This broadcast mechanism is implemented by thegmmodule (which stands for guaranteed broadcast) that provides the necessary utilities to add/remove a process from a broadcast group and send a broadcast message among nodes in a group in a reliable manner. - Start up of queue mirroring based on the mirroring policies defined for the recovered queues. For this purpose, the
on_node_up()method from therabbit_mirror_queue_miscmodule is executed. It retrieves the cluster nodes on which to mirror queue messages for each queue based on the defined mirroring policies. Therabbit_mirror_*modules implement the logic for queue mirroring using master-slave semantics.
The following diagram depicts the process subtree for the queue-related processes and their supervisors:

We will divide the persistence component into metadata persistence and message persistence subcomponents.
In the boot process, we have a chain for the initialization of the Mnesia databases along with the relevant RabbitMQ tables. In earlier chapters, we discussed that the transient and persistent message stores are separated from the Mnesia tables, which store the information about object definitions (such as exchanges, queues, and bindings). The rabbit_mnesia module is initialized during the boot process and provides utilities to start and stop the Mnesia database, check whether the database is running, and transfer metadata among cluster nodes. It also handles the creation of the Mnesia schema along with the RabbitMQ tables by means of the rabbit_table module. The rabbit_table module provides definitions of the RabbitMQ tables. The following is a list of the RabbitMQ Mnesia tables:
rabbit_userrabbit_user_permissionrabbit_vhostrabbit_listenerrabbit_durable_routerabbit_semi_durable_routerabbit_route,rabbit_reverse_routerabbit_topic_trie_noderabbit_topic_trie_edgerabbit_topic_trie_bindingrabbit_durable_exchangerabbit_exchangerabbit_exchange_serialexchange_name_matchrabbit_runtime_parametersrabbit_durable_queuerabbit_queue
The preceding tables are manipulated by means of the mnesia built in the module throughout the RabbitMQ server sources. The rabbit_mnesia module uses the file utilities that are provided by the rabbit_file module.
First of all, the file handle cache is initialized by the start_fhc() method in the rabbit module. The file handle cache provides a buffer for read/write operations on the disk that manages the available file descriptors among processes that use the file handle cache (readers/writers). You can think of the file handle cache as a service that accepts jobs for read/write operations by means of the with_handle() methods, which accept a function closure providing the execution logic for a file operation and serves as a guard to acquire/release the file handles in order to accomplish that operation. The rabbit_file module uses file_handle_cache to perform disk operations. In the RabbitMQ configuration file, we can specify a backing_queue_module setting, which specifies an Erlang module that provides the queue operations, such as initialization and management of the message store, message processing in the queue (in-memory or on disk), queue purging, and so on. The default implementation is provided by the rabbit_variable_queue module that uses rabbit_msg_store to store transient and persistent messages on the disk. To do so, rabbit_msg_store uses the utilities that are provided by the rabbit_file and file_handle_cache modules.
The networking component is initialized during the boot process by calling the boot() method from the rabbit_direct and rabbit_networking modules. The first module starts the rabbit_direct_client_sup supervisor process to handle direct connections to the broker, while the second module starts rabbit_tcp_client_sup to handle the TCP client connections. The rabbit_tcp_client_sup also creates a rabbit_connection_sup supervisor that, on the other hand, creates a rabbit_reader process to process the connections and a helper_sup process (represented by the rabbit_connection_helper_sup module) to create channel supervisors. After that, a TCP listener supervisor is started for each TCP/SSL listener interface. For each TCP/SSL listener supervisor, two child processes are created (their specifications are provided in the init() method of the rabbit_listener_sup method), as follows:
- A
tcp_listenerprocess that accepts connections on a specified port - A
tcp_acceptor_supprocess that creates a number of child acceptor processing to handle incoming socket connections from thetcp_listenerprocess
The following diagram provides an overview of the interaction between the processes that are involved in accepting and processing a TCP connection in the message broker over a single interface:
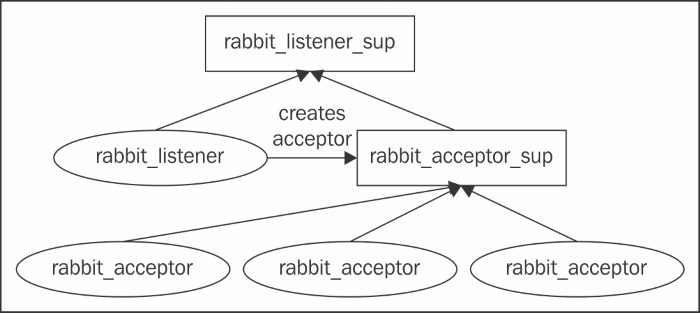
Once an acceptor receives a client connections, it calls the start_client() method for TCP connections or the start_ssl_client() method for SSL connections from the rabbit_networking module to process the incoming connection. The new connection is sent to the rabbit_reader process that starts reading the AMQP messages from the connection. It also provides the semantics to parse the messages and create channel-level processes by means of the helper_sup process. The following diagram provides an overview of the process subtree, originating from the rabbit_tcp_client_sup supervisor:

There are other components provided by the message broker; we briefly covered most of them when we were discussing the boot process of the message broker. In short, these components include the following:
- Alarm handler module that triggers memory alarms in case of excessive memory consumption; its implementation is provided by the
rabbit_alarmmodule. - RabbitMQ plugin registry that provides a service to register plugin modules to the message broker and retrieve information about the plugin modules from the various components of the broker; its implementation is provided by the
rabbit_registrymodule. - Statistics event manager that enables gathering of statistics from the message broker; its implementation is provided by the
rabbit_eventmodule. - Node monitoring provides a mechanism to monitor addition and removal of nodes from a cluster and also track the current cluster status; its implementation is provided by the
rabbit_node_monitormodule. - Memory monitoring provides a mechanism for central collection of statistics that are related to memory consumption in the broker; each queue sends information to the memory monitor upon changes in the queue contents. This allows the memory monitor to track the statistics about the overall memory consumption; its implementation is provided by the
rabbit_memory_monitormodule. - Custom garbage collection process allows components to force Erlang garbage collection for processes that are running in the message broker. garbage collection, in particular, is forced when a memory alarm is triggered; its implementation is provided by the
background_gcmodule.
Having seen how the message broker works, it is time to see how to write a plugin for RabbitMQ. It should be stressed again that a poorly written plugin can result in the crashing of the entire broker, therefore, you should be careful when implementing a plugin for the message broker that is intended to be used in production.
There is a public umbrella project that can be used as a starting point in writing a new RabbitMQ plugin. The umbrella project groups a number of sample child projects, which implement different types of plugins that you can use as an example. Refer to Appendix, Contributing to RabbitMQ on tools for Erlang development. In order to get the project from the RabbitMQ repository and check the child projects, execute the following set of commands:
git clone https://github.com/rabbitmq/rabbitmq-public-umbrella.git cd rabbitmq-public-umbrella make co
The rabbitmq_metronome can be used as a starting point as it provides a very basic functionality to send a message to the metronome topic exchange every second. It consists of an application class, a single process supervisor, and the actual process that performs the logic of the plugin. For development purpose, you can create a link from the plugins directory of your message broker to the root location of the plugin. Then, you can build the plugin with the following command:
make
In order to test the plugin, you can start the message broker as shown in the following:
make run-broker