
PostgreSQL can be installed on almost all modern operating systems. It can be installed on all recent Linux distributions, Windows 2000 SP4 and later, FreeBSD, OpenBSD, Mac OS X, AIX, and Solaris. Also, PostgreSQL can work on various CPU architectures including x86, x86_64, IA64, and others. One can check if a platform (operating system and CPU architecture combination) is supported by exploring the PostgreSQL Build farm (http://buildfarm.postgresql.org/).
One can compile and install PostgreSQL from the source code or download its binary and install it.
Ubuntu is a Debian-based widely spread Linux operating system. Ubuntu uses the Advanced Packaging Tool (APT), which handles software installation and removal on the Debian operating system and its variants.
If you have a PostgreSQL server already installed and you need to interact with it, then you need to install the postgresql-client software package. In order to do so, open a terminal and execute the following command:
sudo apt-get install postgresql-client
With the installation of postgrsql-client, several tools are installed including the PostgreSQL interactive terminal (psql), which is a very powerful interactive frontend tool for PostgreSQL. To see the full list of installed programs, one can browse the installation directory. Note that the installation path might vary depending on the installed PostgreSQL version, and also depending on the operating system:
cd /usr/lib/postgresql/9.4/bin/ ls clusterdb createdb createlang createuser dropdb droplang dropuser pg_basebackup pg_dump pg_dumpall pg_isready pg_receivexlog pg_recvlogical pg_restore psql reindexdb vacuumdb
In order to connect to an existing PostgreSQL server using psql, one needs to specify the connection string, which might include the host, the database, the port, and the user name.
Another powerful frontend tool is pgAdmin which is used for PostgreSQL administration and development. Unlike psql: which is a terminal user interface, pgAdmin is a graphical user interface (GUI). pgAdmin is favored by beginners, while psql can be used for shell scripting.
In order to install pgAdmin, one should run the following command:
sudo apt-get install pgadmin3

Figure 2: pgAdmin tool
In order to install the server, one should run the following command:
sudo apt-get install postgresql ... Creating config file /etc/postgresql-common/createcluster.conf with new version Creating config file /etc/logrotate.d/postgresql-common with new version Building PostgreSQL dictionaries from installed myspell/hunspell packages... Removing obsolete dictionary files: * No PostgreSQL clusters exist; see "man pg_createcluster" Processing triggers for ureadahead (0.100.0-16) ... Setting up postgresql-9.4 (9.4.5-1.pgdg14.04+1) ... Creating new cluster 9.4/main ... config /etc/postgresql/9.4/main data /var/lib/postgresql/9.4/main locale en_US.UTF-8 Flags of /var/lib/postgresql/9.4/main set as -------------e-C port 5432 update-alternatives: using /usr/share/postgresql/9.4/man/man1/postmaster.1.gz to provide /usr/share/man/man1/postmaster.1.gz (postmaster.1.gz) in auto mode * Starting PostgreSQL 9.4 database server [ OK ] Setting up postgresql-contrib-9.4 (9.4.5-1.pgdg14.04+1) ... Processing triggers for libc-bin (2.19-0ubuntu6.6) ...
The installation will give you information about the location of the PostgreSQL configuration files, data location, locale, port, and PostgreSQL status, as shown in the preceding code. PostgreSQL initializes a storage area on the hard disk called a database cluster. A database cluster is a collection of databases managed by a single instance of a running database server. That means, one can have more than one instance of PostgreSQL running on the same server by initializing several database clusters. These instances can be of different PostgreSQL server versions, or the same version.
The database cluster locale is en_US.UTF-8. By default, when a database cluster is created, the database cluster will be initialized with the locale setting of its execution environment. This can be controlled by specifying the locale when creating a database cluster. A configuration location enables a developer/administrator to control the behavior of the PostgreSQL database.
Another important package that should be installed is the postgresql-contrib, which contains community-approved extensions. To install postgresql-contib, use the command line and type the following:
sudo apt-get install postgresql-contrib
To check the installation, one can grep the postgres processes, as follows:
pgrep -a postgres 1091 /usr/lib/postgresql/9.4/bin/postgres -D /var/lib/postgresql/9.4/main -c config_file=/etc/postgresql/9.4/main/postgresql.conf 1108 postgres: checkpointer process 1109 postgres: writer process 1110 postgres: wal writer process 1111 postgres: autovacuum launcher process 1112 postgres: stats collector process
The preceding query shows the server main process with two options: the -D option specifies the database cluster, and the -c option specifies the configuration file. Also, it shows many utility processes, such as autovacuum, and statistics collector processes.
One could also install the server and the client in one command, as follows:
sudo apt-get install postgresql postgresql-contrib postgresql-client pgadmin3
In order to access the server, we need to understand the PostgreSQL authentication mechanism. On Linux systems, one can connect to PostgreSQL by using a unix-socket or TCP/IP protocol. Also, PostgreSQL supports many types of authentication methods.
When a PostgreSQL server is installed, a new operating system user, as well as a database user, with the name postgres is created. This user can connect to the database server using peer authentication. The peer authentication gets the client's operating system user name, and uses it to access the databases that can be accessed. Peer authentication is supported only by local connections—connections that use unix-sockets. Peer authentication is supported by Linux distribution but not by Windows.
Client authentication is controlled by a configuration file named pg_hba.conf, where pg stands for postgres and hba stands for host-based authentication. To take a look at peer authentication, one should execute the following command:
$ grep -v '^#' /etc/postgresql/9.4/main/pg_hba.conf|grep 'peer' local all postgres peer local all all peer
The interpretation of the first line of the result is shown here: The postgres user can connect to all the databases by using unix-socket and the peer authentication method.
To connect to the database servers using the postgres user, first we need to switch the operating system's current user to postgres, and then invoke psql. This is done via the Linux command, su, as follows:
sudo su postgres psql # This also could be done as follows # sudo -u postgres psql
The preceding query shows the psql interactive terminal. The select statement SELECT version (); was executed, and the PostgreSQL version information was displayed.
$ psql psql (9.4.4) Type "help" for help. postgres=# SELECT version(); version ----------------------------------------------------------------------------------------------- PostgreSQL 9.4.4 on i686-pc-linux-gnu, compiled by gcc (Ubuntu 4.8.2-19ubuntu1) 4.8.2, 32-bit (1 row)
As shown in the preceding result, the installed version is PostgreSQL 9.4.4. The PostgreSQL version number has three digits. Major releases occur roughly on an annual basis, and usually change the internal format of the data. This means that the stored data's backward compatibility between major releases is not maintained. A major release is numbered by incrementing either the first or the second digit.
Minor releases are numbered by increasing the third digit of the release number, for example 9.3.3 to 9.3.4. Minor releases are only bug fixes.
The installation of PostgreSQL on Windows is easier than Linux for beginners. One can download the PostgreSQL binaries from EnterpriseDB. The installer wizard will guide the user through the installation process. The installer will also launch the stack builder wizard, which is used to install the PostgreSQL drivers and many other utilities and extensions.
Unlike Ubuntu, the installation wizard gives the user the ability to specify the binaries location, the database cluster location, port, the postgres user password, and the locale:

Figure 3: PostgreSQL installation wizard: PostgreSQL installation directory
Using the psql client is not very convenient in the latest version of Windows due to the lack of some capabilities such as copy, paste, and resizing in the Windows command prompt. pgAdmin is often used in the Windows operating system. Another option is to use a Linux emulator such as Cygwin and MobaXterm.

Figure 4: Stack builder
PostgreSQL in Windows is installed as a service; in order to validate the installation, one can view the service tab in the task manager utility.
In addition to PgAdmin III and the psql client tools, there are a lot of vendors producing tools for PostgreSQL that cover different areas, such as database administration, modeling, development, reporting, ETL, and reverse engineering. In addition to the psql tool, PostgreSQL is shipped with several client tools, including the following:
- Wrappers: The wrappers are built around SQL commands such as
CREATE USER. These wrappers facilitate the interaction between the database server and the developer, and automate the daily routine tasks. - Backup and replication: PostgreSQL supports physical and logical backups. The physical backup is performed by taking a snapshot of the database files. The physical backup can be combined with WAL in order to achieve streaming replication or a hot standby solution. Logical backup is used to dump the database in the form of SQL statements. Unlike physical backup, one can dump and restore a single database.
- Utilities: PostgreSQL comes with several utilities to ease extraction of information and to help in diagnosing the problems.
The PostgreSQL community unifies the look and feel of the client tools as much as possible; this makes it easy to use and learn. For example, the connection options are unified across all client tools. The following screenshot shows the connection options for psql, which are common for other PostgreSQL clients as well.
Also, most PostgreSQL clients can use the environment variables supported by libpq such as PGHOST, PGDATABASE, and PGUSER. The libpq environment variables can be used to determine the default connection parameter values.

Figure 5: psql connection options
The psql client is maintained by the PostgreSQL community, and it is a part of the PostgreSQL binary distribution. psql has many overwhelming features such as the following:
- psql is configurable: psql can be configured easily. The configuration might be applied to user session behavior such as commit and rollback, psql prompt, history files, and even shortcuts for predefined SQL statements.
- Integration with editor and pager tools: The psql query result can be directed to one's favorite pager such as less or more. Also, psql does not come with an editor, but it can utilize several editors. The following example shows the psql
efmeta tag—edit function—asking for editor selection on a Linux machine:postgres=# ef Select an editor. To change later, run 'select-editor'. 1. /bin/ed 2. /bin/nano <---- easiest 3. /usr/bin/vim.basic 4. /usr/bin/vim.tiny Choose 1-4 [2]:
- Auto completion and SQL syntax help: psql supports auto completion for database object names and SQL constructs.

Figure 6: psql syntax help
- Query result format control: psql supports different formats such as html and latex.
The psql client tool is very handy in shell scripting, information retrieval, and learning the PostgreSQL internals. The following are some of the psql Meta commands that are often used daily:
- d+ [pattern]: This describes all the relevant information for a relation. In PostgreSQL, the term relation is used for a table, view, sequence, or index. The following image shows the description of a
pg_viewsview:
Figure 7: d meta command
- df+ [pattern]: Describes a function
- z [pattern]: Shows the relation access privileges
For shell scripting, there are several options that makes psql convenient, these options are:
-A: The output is not aligned; by default, the output is aligned as shown in the following image:-q(quiet): This option forces psql not to write a welcome message or any other informational output.-t: This option tells psql to write the tuples only, without any header information.-X: This option informs psql to ignore the psql configuration that is stored in~/.psqlrcfile.-o: This option specifies psql to output the query result to a certain location.-F: This option determines the field separator between columns. This option can be used to generate comma-separated values (CSV), which are useful for importing data to excel files.PGOPTIONS: psql can usePGOPTIONSto add command-line options to send to the server at run-time. This can be used to control statement behavior such as to allow indexing only, or to specify the statement timeout.
Let us assume that we would like to write a bash script to check the number of opened connections for determining if the database server is over-loaded for the Nagios monitoring system:
#!/bin/bash connection_number=`PGOPTIONS='--statement_timeout=0' psql -AqXt -c "SELECT count(*) FROM pg_stat_activity"` case $connection_number in [1-50]*) echo "OK - $connection_number are used" exit 0 ;; [50-100]*) echo "WARNING - $connection_number are used" exit 1 ;; # rest of case conditions ... esac
The result of the command psql -AqXt –d postgres -c "SELECT count(*) FROM pg_stat_activity" is assigned to a bash variable, and then used in the bash script to determine the exit status. The options -AqXt, as discussed previously, cause psql to return only the result, without any decoration, as follows:
postgres@packet:/$ psql -AqXt -c "SELECT count(*) FROM pg_stat_activity" 1
The psql client can be personalized. The psqlrc file is used to store the user preference for later use. There are several aspects of psql personalization, including:
- Look and feel
- Behavior
- Shortcuts
The following recipes show how one can personalize the psql client, add shortcuts, and control the statement transaction behavior:
- Recipe 1: Change the psql prompt to show the connection string information including the server name, database name, user name, and port. The psql variables
PROMPT1,PROMPT2, andPROMPT3can be used to customize the user preference.PROMPT1andPROMPT2are issued when creating a new command and a command expecting more input, respectively. The following example shows some of the prompt options; by default, when one connects to the database, only the name of the database is shown. Thesetmeta command is used to assign a psql variable to a value. In this case, it assignsPROMPT1to(%n@%M:%>) [%/]%R%#%x >. The percent sign (%) is used as a placeholder for substitution. The substitutions in the example will be as follows:%M: The full host name. In the example, [local] is displayed, because we use the Linux socket.%>: The PostgreSQL port number.%n: The database session user name.%/: The current database name.%R: Normally substituted by=; if the session is disconnected for a certain reason, then it is substituted with (!).%#: Used to distinguish super users from normal users. The (#) hash sign indicates that the user is a super user. For a normal user, the sign is (>).%x: The transaction status. The*sign is used to indicate the transaction block, and (!) sign to indicate a failed transaction block.
Notice how
PROMPT2was issued when the SQL statementSELECT 1was written over two lines. Finally, notice the*sign, which indicates a transaction block:
Figure 8: psql PROMPT customization
- Recipe 2: Add a shortcut for a common query such as showing the current database activities. psql can be used to assign arbitrary variables using the
set" meta command. Again, the:symbol is used for substitution. The following example shows how one can add a shortcut for a query. Thexmeta command changes the display setting to expanded display: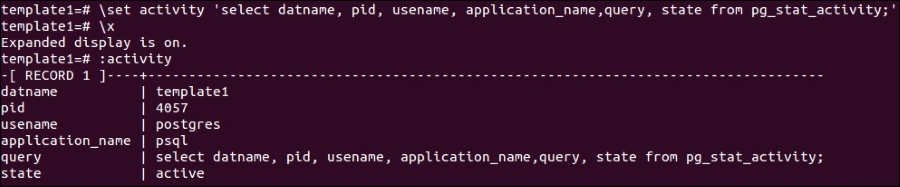
Figure 9: Add shortcut to a query in psql
- Recipe 3: Control statement and transaction execution behavior. psql provides three variables, which are
AUTOCOMMIT,ON_ERROR_STOP, andON_ERROR_ROLLBACK.ON_ERROR_STOP: By default, psql continues executing commands even after encountering an error. This is useful for some operations, including as dumping and restoring the whole database, where some errors can be ignored, such as missing extensions. However, in developing applications, such as deploying new application, errors cannot be ignored, and it is good to set this variable toON. This variable is useful with the-f,i,iroptions.ON_ERROR_ROLLBACK: When an error occurs in a transaction block, one of three actions is performed depending on the value of this variable. When the variable value is off, then the whole transaction is rolled back—this is the default behavior. When the variable value is on, then the error is ignored, and the transaction is continued. The interactive mode ignores the errors in the interactive sessions, but not when reading files.AUTOCOMMIT: An SQL statement outside a transaction, committed implicitly. To reduce human error, one can turn this option off:

Figure10: on_error_stop psql variable
The following figure shows the effect of the
autocommitsetting. This setting is quite useful because it allows the developer to rollback the unwanted changes. Note that when deploying or amending the database on life systems, it is recommended to make the changes within a transaction block, and also prepare a rollback script:
Figure 11: Autocommit variable setting behavior
- Other recipes:
iming: Shows the query execution time.pset null 'NULL': Displays null asNULL. This is important to distinguish an empty string from theNULLvalues. Thepsetmeta command is used to control the output formatting:

Figure12: Enable timing and change null display settings in psql
For more information about psql, one should have a look at the psql manual pages or at the PostgreSQL documentation (http://www.postgresql.org/docs/9.4/static/app-psql.html).
Several PostgreSQL utility tools are wrappers around SQL constructs. The following table lists these wrappers and the equivalent SQL commands:
|
Tool name |
SQL construct |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
or
|
|
|
|
PostgreSQL supports physical and logical backup. The following tools are shipped with the postgresql-client package:
|
Tool name |
Description |
|---|---|
|
|
Creates a logical dump of a single PostgreSQL database into an SQL script file or archive file |
|
|
Creates a logical dump for the whole PostgreSQL cluster |
|
|
Restores a PostgreSQL database or PostgreSQL cluster from an archive file created by |
|
|
Dumps the whole database cluster by taking a snapshot of the hard disk |
|
|
Streams transaction logs from a PostgreSQL cluster |
PostgreSQL is shipped with two utilities: pg_config and pg_isready. pg_config. They come with the postgresql package, and are used to provide information about the installed version of PostgreSQL such as binaries and cluster folder location. pg_config provides valuable information since the PostgreSQL installation location and build information varies from one operating system to another. pg_isready checks the connection status of a PostgreSQL server and provides several exit codes to determine connection problems. Exit code zero means successfully connected. If the exit code is one, then the server is rejecting connections. If there is no response from the server, two will be returned as the exit code. Finally, exit code three indicates that no attempt is made to connect to the server.
In addition to the above, vacuumdb is used for garbage collection and for statistical data collection. vacuumdb is built around the PostgreSQL-specific statement, vacuum.
PgAdmin III is a very rich GUI tool for PostgreSQL administration and development. It is an open source and cross platform tool. It is available in several languages, and supports most of the PostgreSQL data encoding. It supports psql as a plugin, Slony-I replication, and the pgAgent job scheduling tool. It can be used for editing the PostgreSQL configuration files.
As shown earlier, PgAdmin III is installed by default on the Windows platform. The following are some of the PgAdmin III features for development:
- Basic editor but with syntax highlighting and auto completion.
- Database objects are rendered according to the PostgreSQL sever organization.
- Very convenient for extracting database object definitions.
- Comprehensive wizards to create database objects such as domain, functions, tables, and so on.
- Graphical representation of query execution plans.
- Graphical query builder.
psql will be used throughout this book, because it has many amazing features, such as shortcuts and customizations. Also, it can be used for scripting purposes.