
A pain point common in nearly every team-based project I've ever worked on is how to manage the database. More often than not, teams decide to have a central development database, and all the developers use that central development database as their backing DB while making changes. This invariably results in somebody breaking somebody else's application under development because the database schema gets changed in some way, or test data gets removed or modified, and so on. Having a single monolithic development database can be real nasty, and is something that I try to avoid.
I'm a firm believer that a developer should be able to check out the source code, and within a few keystrokes, be able to successfully build and run the application. This is difficult, if not impossible, to do without having some kind of automated tool to build a database on the developer's own local machine. Thankfully, some kind souls on the Internet share my ideals and have created various tools to try and help with this whole thing. One of the better Leiningen plugins that I've used to accomplish this is Migratus.
Migratus is an API and plugin for Leiningen that automatically migrates, and rolls back, our database. In a nutshell, it allows us to create a series of SQL scripts, which will be executed in order (based on filename) against our database. We can migrate a defined set of scripts, or all scripts. Conversely, we can roll back a defined set of scripts (however, there does not exist an option to rollback the whole lot).
The beauty of Migratus is we can commit our SQL files in version control and other developers will receive them when they perform an update (or if we get a new machine, or want to sync between a desktop and laptop, and the like). All they have to do to migrate their database after a git pull command, for example, is run lein migratus from their project root. Migratus will then run any migration files against a target database that have not yet been run. Done.
The remainder of this book will use Migratus to manage our database schema changes. As such, it might be useful to know how to actually get it.
Note
You can view the full documentation for Migratus at https://github.com/pjstadig/migratus.
Migratus comes in two forms: an API (which is useful for having migration scripts run as part of a start-up process if you're deploying) and a plugin for Leiningen.
To get the API, add it to the list of :dependencies in your project.clj file:
[migratus "0.7.0"]
To get the Leiningen plugin (which we will be using), add the following code to the list of :plugins in the hipstr project.clj file:
[migratus-lein "0.1.0"]
Running a simple lein deps command from the command line will download the new dependencies.
Now that we've added the Migratus plugin, we also need to configure it. After all, Migratus is not magical; it doesn't just work without a bit of guidance. Migratus' configuration, like most configurations, is thrown in hipstr's project.clj file under the keyword :migratus. The configuration contains three key pieces of information: what we're migrating (the :store—in our case, a database), where the migration scripts are kept (:migration-dir), and any configuration settings for the store in question. Add the following code to the hipstr project.clj file:
;…
:migratus {
:store :database
:migration-dir "migrations"
:migration-table-name "_migrations"
:db {:classname "org.postgresql.Driver"
:subprotocol "postgresql"
:subname "//localhost/postgres"
:user "hipstr"
:password "p455w0rd"}}
;…Let's take a look at the Migratus configuration keys from the preceding code:
:store: This defines the target object we are migrating. In our case, we're migrating a database, so we use the:databasekey. Supposedly, Migratus is a generic migrations library, but I've not seen it officially support anything other than databases.:migration-dir: This defines the directory on the classpath where our SQL migration scripts are stored. We'll create a directory called migrations under oursrcdirectory.:migration-table-name: This is an optional configuration key, but useful when using schemas instead of standalone databases. Migratus uses an underlying table to track which migrations have been run and which have not. We can specify the name of this table. This table name defaults toschema_migrations, however I've found that it can, for whatever reason, be somewhat buggy when using schemas.:db: The meat of the configuration, this tells the Migratus plugin how to connect to the database. The value map in our configuration should look familiar, as it leverages what we've done in the preceding sections of this chapter.
We can test this configuration by running the Migratus plugin. Type the following in your terminal from the root of your hipstr directory:
# lein migratus migrate
This will migrate any yet-to-be-run migration script inside our migrations directory, and emit information about the status of each migration. In our case, because we haven't written any migrations yet, we should see something similar to the following:
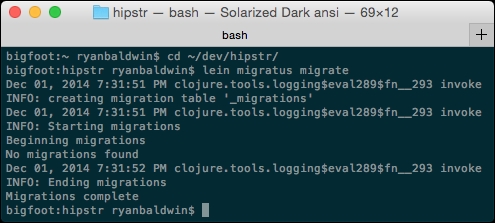
In the preceding output, we can see that Migratus created the _migrations table we configured to keep track of migrations. We're informed that no migrations were found. Let's fix this!
To create the database tables for our hipstr application, we'll write good old fashioned SQL scripts. For each table, we'll create an up script, which Migratus executes while migrating our database, and a down script, which Migratus executes when rolling back.
Note
Migratus is very particular about the naming of scripts. It expects a 14-digit number as the script's prefix, paired with any combination of characters, and finally suffixed with a .up.sql or .down.sql, respectively. The rational for this design decision was so that each migration script would have a date/time prefix, which supposedly helps in a distributed version control system such as Git, where multiple branches and such may exist. In our case, however, that's overkill, so we'll just use incremental version numbers.
Create a migrations directory at src/migrations. Next, create your first Migratus script, and call it 00000000000100-users.up.sql, and save it in the src/migrations directory (all subsequent Migratus scripts that we write will go in this directory).
The content of the Migratus script is just SQL. We'll create a simple user table that captures the data from our signup form, along with a couple of timestamps. Add the following SQL to the users.up.sql script:
CREATE TABLE users (user_id SERIAL NOT NULL PRIMARY KEY, username VARCHAR(30) NOT NULL, email VARCHAR(60), password VARCHAR(100), created_at TIMESTAMP NOT NULL DEFAULT (now() AT TIME ZONE 'utc'), updated_at TIMESTAMP NOT NULL DEFAULT (now() AT TIME ZONE 'utc')); --;; -- create a function which simply sets the update_date column to the -- current date/time. CREATE OR REPLACE FUNCTION update_updated_at() RETURNS TRIGGER AS $$ BEGIN NEW.updated_at = now() AT TIME ZONE 'utc'; RETURN NEW; END $$ language 'plpgsql'; --;; -- create an update trigger which updates our updated_at column by -- calling the above function CREATE TRIGGER update_user_updated_at BEFORE UPDATE ON users FOR EACH ROW EXECUTE PROCEDURE update_updated_at();
There are three statements in this script, each of which are separated using the special --;; delimiter, which Migratus uses to split statements. The first statement creates the users table; the second statement creates a function responsible for keeping the updated_at column current; the third statement creates a BEFORE UPDATE trigger to ensure that the current date is set on the update_at column.
We can test the script by heading back over to our terminal and executing another lein migratus migrate command. You should see output similar to the following screenshot:
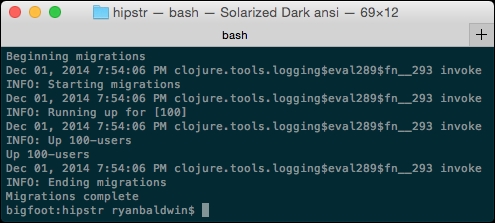
By all accounts, the migration appears to have completed successfully. Let's fire up the PostgreSQL management shell again and take a look at what was created.
From the terminal, launch the psql tool the same way we did earlier in this chapter in the Creating the Database Schema section:
# psql -U hipstr -d postgres -h localhost
Type the command dt, which lists all the tables in the current schema:
postgres=> dt
You should see something like the following:
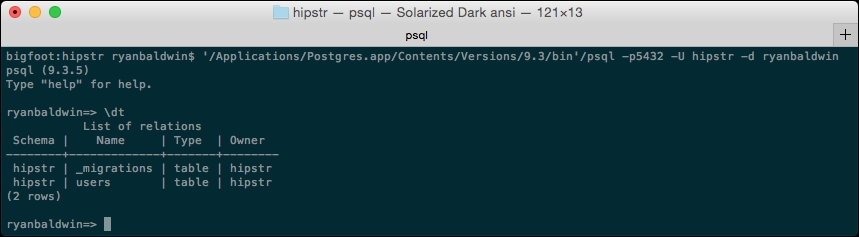
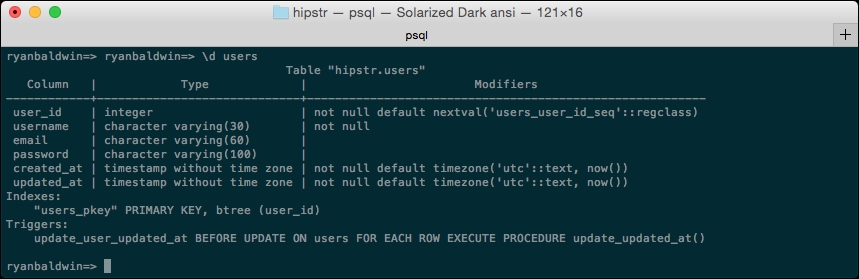
There you go! Our users table is in the hipstr schema! You can also issue a d users command, to describe the table.
In the previous section, we created an up migration script. The up scripts are executed whenever we perform a lein migratus migrate or lein migratus up command. However, we should also create a down script, which is used when we want to roll back the database.
Create another migration script with the same name as the users.up script, but this time call it 00000000000100-users.down.sql. Migratus looks for the down portion of the filename when deciding which scripts to execute when rolling back, so don't forget this!
In the users.up script, we created a table, a function, and a trigger. In the down script, we'll want to remove these objects, but in the reverse order (lest we produce ill-fated SQL errors as a result of attempting to drop objects that are depended upon). This is achieved using the following code:
DROP TRIGGER update_user_updated_at ON users; --;; DROP FUNCTION update_updated_at(); --;; DROP TABLE users;
The preceding code drops the three objects we created in the appropriate order.
We can run the down scripts by running lein migratus down [list of migration script ids]. For example:
# lein migratus down 100
Migratus will attempt to execute each down script matching the list of IDs. Much like lein migratus migrate, Migratus will emit output informing us of the status of each rollback, similar to the following screenshot:
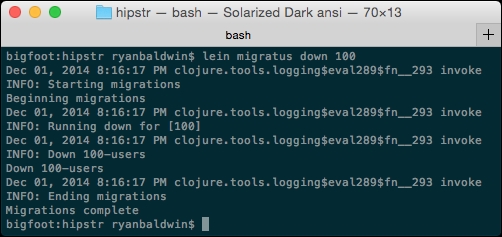
There currently does not exist an equivalent to Migratus' lein migratus migrate for running all down scripts, and thus we are forced to specify the ID of each down script we wish to execute. This is an unfortunate limitation, however Migratus is open source, so perhaps some generous Clojure whiz will be kind enough to write a lein migratus down all *cough*thanks*cough*.
Before we move forward and start actually interacting with the database from code, it would be worth considering how to migrate and roll back the database, both using Leiningen as well as programatically.
The commands to run migration scripts are as follows:
lein migratus migrate: This runs allupmigration scripts that are yet to be run. Migratus checks the migrations table, which consists of a single column of migration script IDs and runs any migrations that have not already been run (that is, any migration scripts whose ID is not already in the migrations table).lein migratus up [IDs]: This migrates one or moreupmigration scripts by specifying their ID. Each migration script is run in the order specified. If the migration script has already been run, it will be skipped.lein migratus up 100 200 300
lein migratus down [IDs]: This runs thedownscript for each ID specified, in the order of the IDs specified, for example:lein migratus down 300 200 100
This is quite possibly one of my favorite features of Migratus. I've spent far too many late nights deploying software, and botching SQL scripts. I'm a fan of single-click deployment or, at the very least, minimizing the amount of effort it takes to get a piece of software deployed. One of the things I like to do—either because I'm clever or stupid—is to tap into the Migratus API at startup (such as in the hipstr.handler/init) and run any migration that may be required. This frees up our effort when deploying our app for the first time, or on subsequent upgrades. As long as we have the proper database connection, the app will take care of the rest.
The Migratus API follows the same options as its Leiningen plugin counterpart, and has the following functions:
migratus.core/migrate: This runs allupmigration scripts that are yet to be run.migratus.core/up [IDs]: This migrates one or moreupscripts by specifying their ID, in the defined order. Again, this skips anyupscript that's already been run.migratus.core/down [IDs]: This runs one or moredownscripts by specifying their ID, in the defined order.
That's it—a tiny API that can make the deployment story a lot easier. For fun, let's add automatic migrations in our hipstr.handler namespace.
Adding migrations to the hisptr application is easy. We can have Migratus run any required migrations upon application startup by adding the appropriate call in our hipstr.handler/init location. Let's do it now:
- Add a Migratus config to our
hipstr.handlernamespace (we will refactor this later, I promise). For now, just copy and paste the:migratusvalue from theproject.cljfile:(def migratus-config {:store :database :migration-dir "migrations" :migration-table-name "_migrations" :db {:classname "org.postgresql.Driver" :subprotocol "postgresql" :subname "//localhost/postgres" :user "hipstr" :password "p455w0rd"}}) - Next, add the function that will perform the actual migration using
migratus.core/migrate, marked as#1. We'll wrap it in a try/catch function and emit any errors in case the migration fails:(defn migrate-db [] (timbre/info "checking migrations") (try (migratus.core/migrate migratus-config) ;#1 (catch Exception e (timbre/error "Failed to migrate" e))) (timbre/info "finished migrations")) - Lastly, add a call to
migrate-dbin thehipstr.handler/initfunction, right before we callsession-manager/cleanup-job:;...snipped for brevity (migrate-db) (cronj/start! session-manager/cleanup-job)
That's it! Now start the app with a lein ring server command (or restart it if you already have it running) and watch the output. You should see something similar to the following:
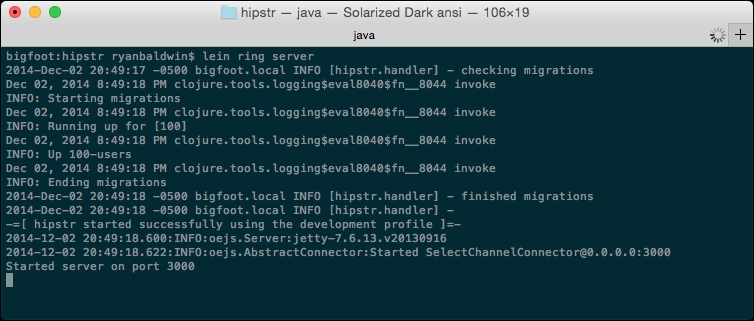
In the preceding image, you can see that Migratus ran any required migrations as part of the hipstr initialization.