
We will discuss the big data components responsible for functions such as storage, resource management, governance, processing, and analysis. Most of these big data components are packaged into an enterprise-grade-supported Hadoop distribution, which will be discussed later in more detail.
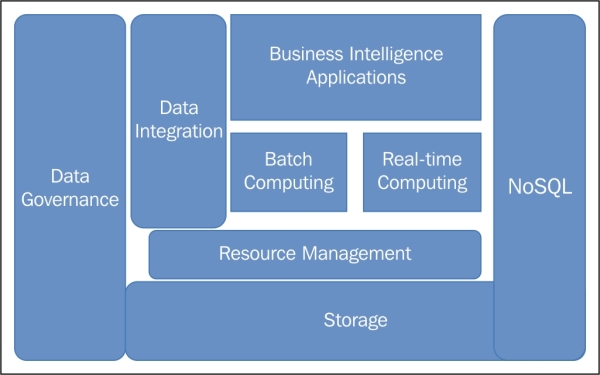
Data storage is where your raw data lives. It is a reliable, fault-tolerant distributed filesystem that contains structured and unstructured data.
The data is stored either on a distributed on-premise filesystem, such as Hadoop Distributed Filesystem (HDFS), or a cloud-based system, such as Amazon S3. The data is also stored in NoSQL databases, such as HBase or Cassandra on Hadoop storage.
To move data into a big data ecosystem, there are data integration tools, such as Flume and Sqoop, or web-service interfaces, such as REST and SOAP for Amazon S3.
NoSQL databases are non-relational, distributed, generally open source, and horizontally scalable.
The term NoSQL is slightly misleading as NoSQL databases do support SQL operations. The term is now popularly defined as Not Only SQL.
Some other characteristics are schema-free, easy replication support, integrated caching, simple API, and eventually consistent/BASE (not ACID).
In comparison to relational databases, NoSQL databases have superior performance and are more scalable if you need to handle the following:
- Large volumes of structured, semistructured, and unstructured data
- Quick iterative requirements involving frequent code changes
- High growth business requiring efficient and scale-out architecture
There are mainly four types of NoSQL databases:
- Document databases: They pair each key with a document. Documents can be simple or complex data structures and contain key-value pairs, key-array pairs, or even nested documents; examples of these databases are MongoDB and CouchDB.
- Graph databases: They are used to store graphical relationships such as social connections; examples of these databases are Neo4j and HyperGraphDB.
- Key-value databases: They are the simplest of all NoSQL-type databases. Every single item is stored as an attribute name (or key) and corresponding value. Some key-value stores, such as Redis, allow each value to have a data type such as integer, which may be useful. Document databases can also function as a key-value database, but they are more targeted at complex structures; examples of these databases are Riak and Voldemort.
- Wide-column databases: They are highly optimized for queries over large datasets. They store columns of data together instead of rows, such as Cassandra and HBase.
It is a flooded market with at least dozens of NoSQL vendors, each claiming superiority over the others. Most of the databases within their type follow similar architecture and development methodologies and so it is not uncommon that organizations stick to a few of the vendors only.
Effective resource management is a must, especially when there will be multiple applications running, fighting for the computing and data resources. Resource Managers such as YARN and Mesos manage allocation, de-allocation, and efficient utilization of your compute/data resources.
There is also a collection of tools to manage the workflow, provisioning, and distributed coordination; for example, Oozie and Zookeeper.
Data governance is all about taking care of the data, ensuring that the metadata (information about data) is recorded properly and the data is only accessed by authorized people and systems. There is a collection of tools to manage metadata, authentication, authorization, security, privacy settings, and lineage. The tools used are Apache Falcon, HCatalog, Sentry, and Kerberos.
Batch computing is an efficient way to process large data volumes, as the data is collected over a period of time and then processed. The MapReduce, Pig, and Hive scripts are used for batch processing.
Typically, a batch process will have persistent-disk-based data storage for input, output, and intermediate results.
Examples include end-of-day risk metrics calculation and historical trade analytics.
Real-time computing is low-latency data processing and usually a subsecond response. Spark and Storm are the popular ones for real-time processing.
Typically, a batch process will have in-memory processing with continuous data input, but it doesn't necessarily need persistent storage for output and intermediate results.
Examples include live processing of tweets and stock prices, fraud detection, and system monitoring.
Data integration tools bring data in and out of Hadoop ecosystems. In addition to tools provided by Apache or Hadoop distributions, such as Flume and Sqoop, there are many premium vendors such as Informatica, Talend, Syncsort, and Datameer, which are a one-stop shop for the majority of data integration needs. As many data integration tools are user-interface-based and use fourth-generation languages, they are easy to use and will keep your Hadoop ecosystem free from complicated MapReduce low-level programs.
Machine learning is the development of models and algorithms that learn from the input data and improve it based on feedback. The program is driven by the input data and doesn't follow explicit instructions. The most popular suite of machine learning libraries is from Mahout, but it's not uncommon to program using the Spark MLlib library or the Java-based custom MapReduce.
A few examples are speech recognition, anomaly or fraud detection, forecasting, and recommending products.
Hadoop distributions can be combined with different business intelligence and data visualization vendors that can connect to the underlying Hadoop platform to produce management and analytical reports.
There are many vendors in this space and nowadays almost all leading BI tools provide connectors to Hadoop platforms. The most trendy ones are Tableau, SAS, Splunk, Qlikview, and Datameer.
Gartner predicted that the roles directly related to big data are predicted to be around 4.4 million across the world by 2015, which could be anything from basic server maintenance to high-end data science innovation.
As more companies want to make use of analytics on their big data, it looks more likely that the number of roles will only increase going forward. 2015 is likely to see a marked increase in the number of people involved within big data directly as the market has started maturing and now more businesses have proven business benefits.
The technical skills required are very diverse—server maintenance, low-level MapReduce programming, NoSQL database administration, data analytics, graphic designers for visualizations, data integration, data science, machine learning, and business analysis. Even the non-technical roles—project management, front office staff such as finance, trading, marketing, and sales teams to analyze the results—will need retraining with the usage of the new set of analytics and visualization tools.
There are very few people with skills on big data or Hadoop and the demand is very high. So, obviously, they are generally paid higher than the market average. The pay packages of Hadoop roles will be better if:
- The skills are new and scarce
- The skills are comparably difficult to learn
- Technical skills such as MapReduce are combined with business domain knowledge
The skills required are so diverse that you can choose a career in a subject that you are passionate about.
Some of the most popular job roles are:
- Developers: They develop MapReduce jobs, design NoSQL databases, and manage Hadoop clusters. Job role examples include Hadoop, MapReduce, or Java developer and Hadoop administrator.
- Architects: They have the breadth and depth of knowledge across a wide range of Hadoop components, understand the big picture, recommend the hardware and software to be used, and lead a team of developers and analysts if required. Job role examples include big data architect, Hadoop architect, senior Hadoop developer, and lead Hadoop developer.
- Analysts: They apply business knowledge with mathematical and statistical skills to analyze data using high-level languages such as Pig, Hive, SQL, and BI tools. Job role examples include business analysts and business intelligence developers.
- Data scientists: They have the breadth and depth of knowledge across a wide range of analytical and visualization tools, possess business knowledge, understand the Hadoop ecosystem, know a bit of programming, but have expertise in mathematics and statistics and have excellent communication skills.
People with development skills in Java, C#, relational databases, and server administration will find it easier to learn Hadoop development, get hands-on with a few projects, and choose to either specialize in a tool or programming language. They can also learn more skills across a variety of different components and take on architect/technical lead roles.
People with analysis skills who already understand the business processes and integration with technology can learn a few high-level programming languages such as Pig, R, Python, or BI tools. Experience in BI tools and high-level programming works best with good business domain knowledge.
Although I am trying here to divide this into two simple career paths—development and analysis—in the real world there is a significant overlap in all the mentioned job roles.
As long as you have excellent development and analysis skills and are also ready to learn mathematics and business (either formal education or experience), there is nothing stopping you from becoming the "data scientist"—claimed to be the sexiest job for the 21st century by Harvard Business Review.