
This section will not provide in-depth knowledge of the Hadoop architecture, but only a high-level overview so we can understand the following chapters without much difficulty.
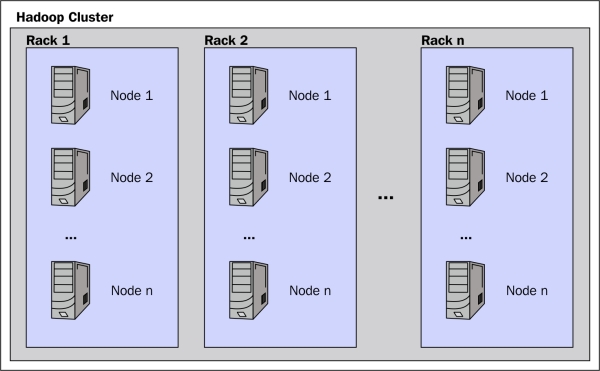
- A node is just a computer containing data that is based on nonenterprise, inexpensive commodity hardware. So, in the following figure, we have Node 1, Node 2, Node 3, and so on.
- A rack is normally a collection of 10 or more nodes physically stored together and connected to the same network switch. So, network latency between any two nodes in a rack is lower than the latency between two nodes on different racks.
- A cluster is a collection of racks as shown in the following figure:
- HDFS is designed to be fault tolerant through replication of data. If one component fails, another copy will be used.
- A file from a non-Hadoop system will be broken into multiple blocks and each block will be replicated on HDFS in a distributed form. Hadoop works best with very large files, as it is designed for streaming or sequential data access rather than random access.
- Blocks have a default size of 128 megabytes each since Hadoop 2.1.0. Newer versions of Hadoop are moving towards higher default block sizes. The block size can be configured depending on an application's needs.
- A 350 megabyte file with a 128 megabyte block size consumes three blocks, but the third block does not consume a full 128 megabytes. The blocks fit well with the replication design, which allows HDFS to be fault tolerant and available on commodity hardware.
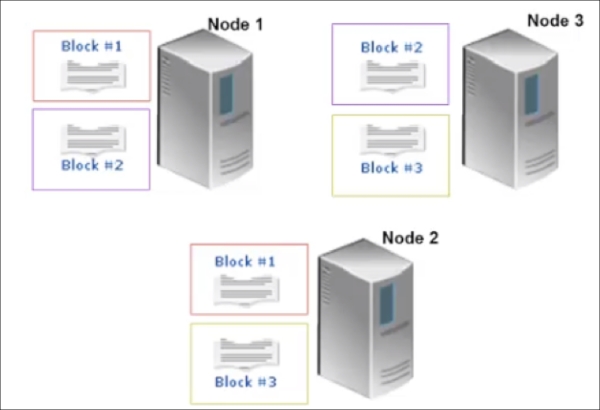
- As shown in the following figure, each block is replicated to multiple nodes. For example, Block 1 is stored on Node 1 and Node 2. Block 2 is stored on Node 1 and Node 3. And Block 3 is stored on Node 2 and Node 3. This allows for node failure without data loss. If Node 1 crashes, Node 2 still runs and has Block 1's data. In this example, we are only replicating data across two nodes, but you can set replication to be across many more nodes by changing Hadoop's configuration or even setting the replication factor for each individual file.
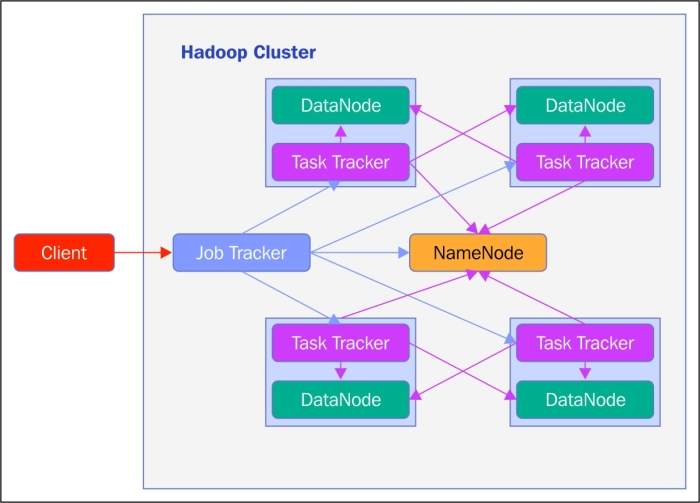
Before Hadoop Version 2.2, MapReduce was referred to as MapReduce V1 and had a different architecture:
- MapReduce programs are of two types—a map transformation or a reduce transformation
- A MapReduce job will be executing as parallel tasks on different nodes – the map job first, and then the results of the map job will be processed by the reduce job
There are two main types of nodes. They are classified as HDFS or MapReduce nodes:
- An HDFS node is either a NameNode or DataNode.
- A MapReduce node is either a JobTracker or a TaskTracker.
- The client generally communicates with a JobTracker. However, it can also communicate with the NameNode or any of the DataNodes.
- There is only one NameNode in the cluster. The DataNodes store all the distributed blocks, but the metadata for those files are stored on the NameNode. This means that NameNode is a single point of failure and therefore deserves the best enterprise hardware for maximum reliability. As NameNode keeps the entire filesystem metadata in memory, it is recommended to buy as much RAM as possible.
- An HDFS cluster has many DataNodes. The DataNodes store blocks of data. When a client requests to read a file from HDFS, the client finds out from the NameNode which blocks make up that file and on which DataNodes those blocks are stored. The client can now directly read the blocks from the corresponding DataNodes. These DataNodes are inexpensive enterprise hardware and the replication is provided in the software layer instead of the hardware layer.
- As NameNode, there is only one JobTracker on the cluster that manages all MapReduce jobs submitted by clients. It schedules the Map and Reduce tasks using TaskTrackers on the DataNodes itself. Basically, the task is executed very intelligently using the locations of data blocks via rack-awareness. Rack-awareness is a configuration that means the data blocks should be processed on the same rack if possible. The block is also replicated on a different rack to handle rack failures. The JobTracker monitors the progress of TaskTrackers and reschedules failed TaskTrackers on a different replicated DataNode.
MapReduce V1 dominated the big data landscape for many years, but there were a few limitations, such as:
MapReduce V2 came up with architectural changes to fix these limitations. This new architecture is also called Yet Another Resource Negotiator (YARN). However, it is not mandatory to run YARN on MapReduce V2.
The new architecture has DataNodes but has no TaskTrackers and a JobTracker.
MapReduce V1 is supported on V2, as V1 is still widely used by organizations across the world.
YARN works on two fundamentals:
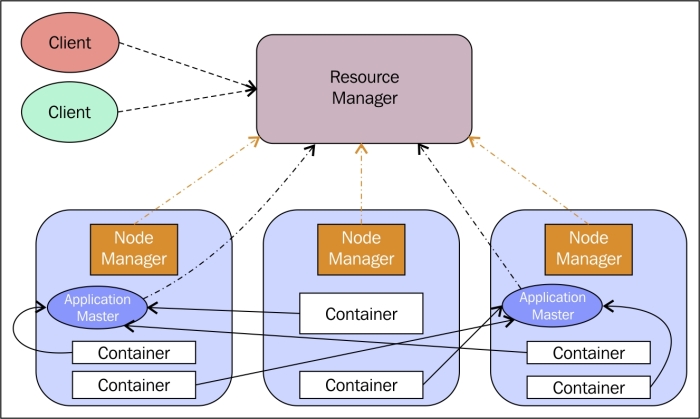
As shown in the following figure, when an application gets invoked by the client, an Application Master gets started on a NodeManager. The Application Master is then responsible for negotiating resources with the ResourceManager. These resources are assigned to containers on each slave node and the tasks are run in the containers.
The Hadoop architecture is now modified to support high availability of NameNode, which is a key requirement for any business-critical application. There are now two NameNodes, one active and one standby.
As shown in the following figure, there are JournalNodes. For a basic setup of one active and one standby NameNode, there are three JournalNodes. As expected, only one of the NameNodes is active at a time. The JournalNodes work together to decide which of the NameNodes is to be the active one. If, for some reason, the active NameNode has gone down, the backup NameNode will take over.
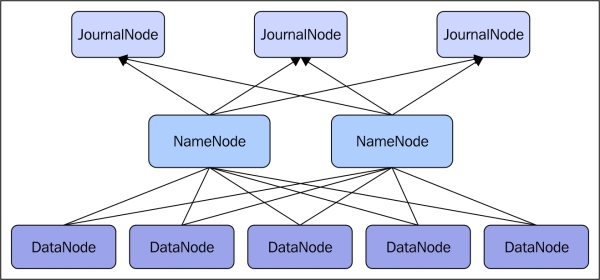
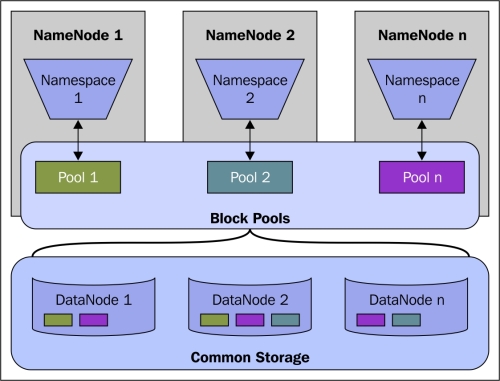
Hadoop has been improved further to provide extreme scalability. There are multiple NameNodes acting independently. Each NameNode has its own namespace and therefore has control over its own set of files. However, they share all of the DataNodes.
MapReduce V2, like V1, has awareness of the topology of the network. When rack-awareness is configured for your cluster, Hadoop will always try to run the task on the TaskTracker node with the highest bandwidth access to the data.