
In this section, we will briefly explain the components on Hadoop and point you to related study materials. Many of these components will be referred to throughout the book.
We know that big data is everywhere and that it needs to be processed and analyzed into something meaningful. But how do we process the data without breaking the bank?
Hadoop, the hero, can tame this big data monster because of the following features:
- It is enterprise grade but runs on commodity servers. Storing big data on traditional database storage is very expensive, generally in the order of $25,000 to $50,000 per terabyte per year. However, with Hadoop, the cost of storing data on commodity servers drops by 90 percent to the order of $2,500 to $5,000 per year.
- It scales horizontally; data can be stored for a longer duration if required, as there is no need to get rid of older data if you run out of disk space. We can simply add more machines and keep on processing older data for long-term trend analytics. As it scales linearly, there is no performance impact when data grows and there is never a need to migrate to bigger platforms.
- It can process semistructured/unstructured data such as images, log files, videos, and documents with much better performance and lower cost, which wasn't the case earlier.
- Processing has moved to data rather than large data moved to the computing engine. There is minimal data movement and processing logic can be written in a variety of programming languages such as Java, Scala, Python, Pig, and R.
The core of Hadoop is a combination of HDFS and MapReduce—HDFS for data storage and MapReduce for data computing.
But Hadoop is not just about HDFS and MapReduce. The little elephant has a lot of friends in the jungle who help in different functions of the end-to-end data life cycle. We will talk briefly on popular members of the jungle in subsequent sections.
HDFS is about unlimited reliable distributed storage. That means that, once you have established your storage and then your business grows, the additional storage can be handled by adding more inexpensive commodity servers or disks. Now, you may wonder whether it might fail occasionally if the servers are not high end. The answer is yes; in fact, on a large cluster of say 10,000 servers, at least one will fail every day. Still, HDFS is self-healing and extremely fault tolerant as every piece of data is replicated on different node servers (the default is three nodes). So, if one data node fails, either of the other two can be used. Also, if a DataNode fails or a block gets corrupted or missed, the failed DataNode's data or block is replicated to a live, light-weight data node.
MapReduce is about moving the computing onto data nodes in a distributed form. It can read data from HDFS as well as other data sources such as mounted filesystems and databases. It is extremely fault tolerant. If any of the computing jobs on the node fails, Hadoop reassigns the job to another copy of the data node. Hadoop knows how to clean up the failed job and combine the results from various MapReduce jobs.
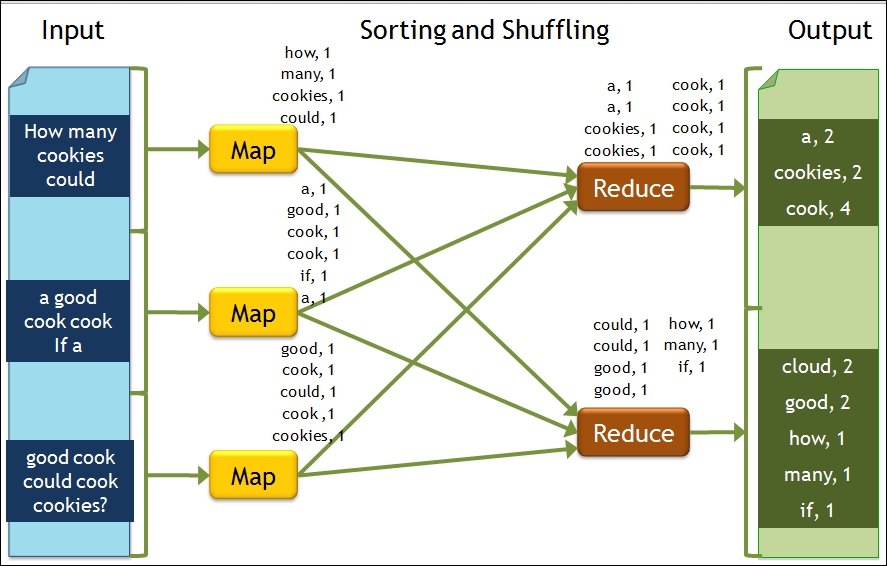
The MapReduce framework processed data in two phases—Map and Reduce. Map is used to filter and sort the data and Reduce is used to aggregate the data. We will show you the famous word count example, which is the best way to understand the MapReduce framework:
- The input data is split into multiple blocks in HDFS.
- Each block is fed to Map for processing and the output is a key-value pair of word as key and count as the value.
- The key-value pairs are sorted by key and partitioned to be fed to Reduce for processing. The key-value pair with the same keys will be processed with the same Reducer.
- Reduce will sum the count of each word and output it as a key-count pair with word as key and count as the sum.
Another example of MapReduce at work is finding the customers with the highest number of transactions for a certain period, as portrayed in the following figure:
HBase is a wide-column database, one of the NoSQL database types. The database rows are stored as key-value pairs and don't store null values. So, it is very suitable for sparse data in terms of storage efficiency. It is linearly scalable and provides real-time random read-write access to data stored on HDFS.
Please visit http://hbase.apache.org/ for more details.
Hive is a high-level declarative language for writing MapReduce programs for all the data-warehouse-loving people who like to write SQL queries on the existing HDFS. It is a very good fit for structured data, and if you like to do a bit more than standard SQL, write your own user-defined functions in Java or Python and use them.
Hive scripts are eventually translated to MapReduce jobs, and many times are almost as good as MapReduce jobs in terms of performance.
Please visit http://hive.apache.org/ for more details.
Pig is a high-level procedural language for writing MapReduce programs for data engineers coming from a procedural language background. It is also a good fit for structured data but can handle unstructured text data as well. If you need additional functions that are not available by default, you can write your own user-defined functions in Java or Python and use them.
As Hive, Pig scripts are also translated to MapReduce jobs, and many times are almost as good as MapReduce jobs in terms of performance.
Please visit http://pig.apache.org/ for more details.
Zookeeper is a centralized service to maintain configuration information and names, provide distributed synchronization, and provide group services.
It runs on a cluster of servers and makes cluster coordination fast and scalable. It is also fault tolerant because of its replication design.
Please visit http://zookeeper.apache.org/ for more details.
Oozie is a workflow scheduler system to manage a variety of Hadoop jobs such as Java MapReduce, MapReduce in other languages, Pig, Hive, and Sqoop. It can also manage system-specific jobs such as Java programs and shell scripts.
As for other components, it is also a scalable, reliable, and extensible system.
Please visit http://oozie.apache.org/ for more details.
Flume is a distributed, reliable, scalable, available service for efficiently collecting, aggregating, and moving large amounts of log data. As shown here, it has a simple and flexible architecture based on streaming data flows:
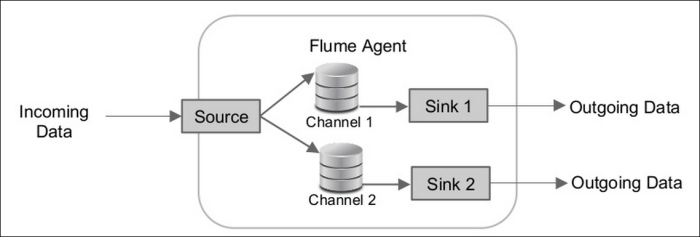
The incoming data can be log files, click streams, sensor devices, database logs, or social data streams, and outgoing data can be HDFS, S3, NoSQL, or Solr data.
The source will accept incoming data and write data to the channel(s). The channel provides flow order and persists the data, and the sink removes the data from the channel once the data is delivered to the outgoing data store.
Please visit http://flume.apache.org/ for more details.
Sqoop is a tool designed to efficiently transfer bulk data between Hadoop and relational databases. It will do the following:
Please visit http://sqoop.apache.org/ for more details.