
There are many distributions in the market, generally classified into two segments—either on premise or in the cloud. It is quite important to know which route we should go for, preferably during the early phase of the project. It is not uncommon to choose both for different use cases or to go for a hybrid approach.
Here, we will look at the pros and cons of each approach:
- Elasticity: In the cloud, you can add or delete computing and temporary data resources depending on your usage. So, you pay for only what you use, which is a major pro of the cloud. On premise, you need to procure resources for your peak usage and plan in advance for data growth.
- Horizontal scalability: Whether on premise or in cloud, you should be able to add more servers whenever you like. However, it is much quicker to do so on the cloud.
- Cost: This is debatable, but going by plain calculation, you may save cost by opting for the cloud because you will make savings on staff, technical support, and data centers.
- Performance: This is again debatable, but if most of your data resides on premise, you will get better performance by going on premise due to data locality.
- Ease of use: Hadoop server administration on premise is hard, especially due to the lack of skilled people. It's possibly easier to let our data servers be administered in cloud by administrators who are experts at it.
- Security: Although there is no good reason to believe that on premise is more secure than the cloud, because the data is moved out of local premises to the cloud, it is difficult to ascertain the security of sensitive data such as customers' personal details.
- Customizability: There are certain limitations on configurations and the ability to code on the cloud as the software is generic across all of their clients, so it is much better to keep the installation on premise if there are complex requirements that need a high degree of customizations.
Forrestor Research published its report in Q1 2014 on leading Hadoop distribution providers, as shown in the following figure. As of this writing, we are still waiting for the new report for 2015 to be released, but we don't expect to see any major changes.
The following figure shows all the leading Hadoop distributions in both segments—on premise and in cloud:
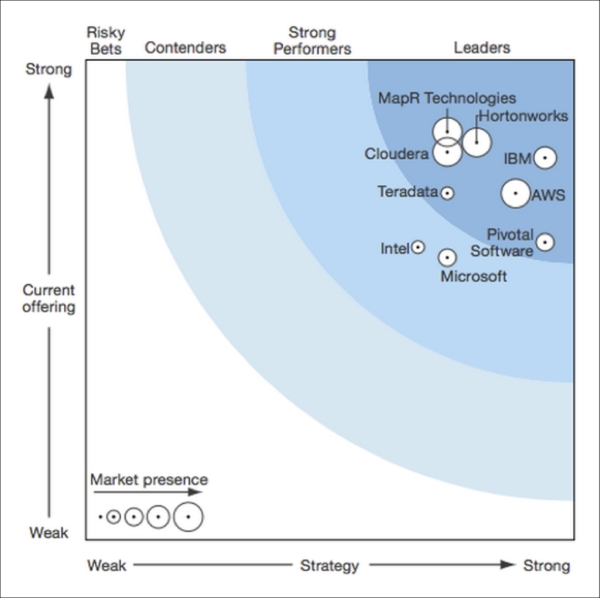
Source: Forrestor Report on Big Data solutions Q1 2014
A standard Hadoop distribution (open source Apache) includes:
- The Hadoop Distributed Filesystem (HDFS)
- The Hadoop MapReduce framework
- Hadoop common—shared libraries and utilities, including YARN
There are numerous Hadoop open source Apache components such as Hive, Pig, HBase, and Zookeeper each performing different functions.
If it's a free, open source collection of software, then why isn't everyone simply downloading, installing, and using it instead of different packaged distributions?
As Hadoop is an open source project, most of the vendors simply improve the existing code by adding new functionalities and combine it into their own distribution.
The majority of organizations choose to go with one of the vendor distributions, rather than the Apache open source distribution, because:
- They provide technical support and consulting, which makes it easier to use the platforms for mission-critical and enterprise-grade tasks and scale out for more business cases
- They supplement Apache tools with their own tools to address specific tasks
- They package all version-compatible Hadoop components into an easy installable
- They deliver fixes and patches as soon as they discover them, which makes their solutions more stable
In addition, vendors also contribute the updated code to the open source repository, fostering the growth of the overall Hadoop community.
As shown in the following figure, most of the distributions will have core Apache Hadoop components, complemented by their own tools, to provide additional functionalities:
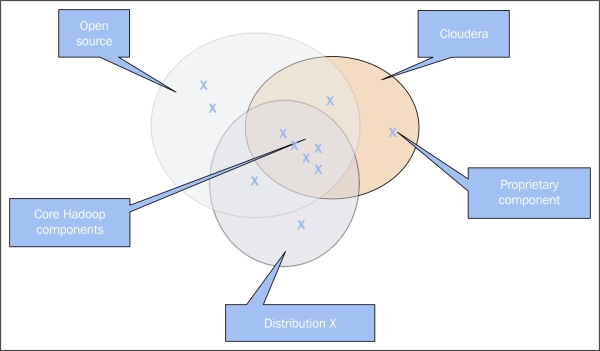
There are at least a dozen vendors, but I will mainly focus on the top three vendors by market share
- Cloudera: It is the oldest distribution with the highest market share. Its components are mostly free and open source, but gets complemented with a few of its own tools if you upgrade to the paid service.
- MapR: It has its own proprietary distributed file system (alternate to HDFS). Some of its components are open source, but you get a lot more if upgraded to the paid service. Its performance is slightly better than Cloudera and they have additional features such as mirroring and no single point of failure.
- HortonWorks: It is the only distribution that is completely open source. Despite being a relatively new distribution, it enjoys a significant market share.
There are other premium distributions from IBM, Pivotal Software, Oracle, and Microsoft that generally combine Apache projects with their own software/hardware or partner with other vendors to provide all-inclusive data platforms.
It is also called Hadoop as a service. Today, many cloud providers offer Hadoop with a distribution of your choice. The main motivation to run Hadoop in the cloud is that you only pay for what you use.
Although the majority of Hadoop implementations are on premise, Hadoop in the cloud is also a good alternative for organizations who like to:
- Lower the cost of innovation
- Procure large-scale resources quickly
- Have variable resource requirements
- Run closer to the data already in the cloud
- Simplify Hadoop operations
The public cloud market reached $67 billion in 2014 and will grow to $113 billion by 2018, according to Technology Business Research. This only proves that in future more and more data will be generated and stored in the cloud, which will make it easier to process in the cloud.
The top vendors who provide Hadoop as a service, with sometimes a choice of distribution like Cloudera, MapR, or HortonWorks, are:
- Amazon Web Services
- Microsoft's Azure
- Google Cloud
- Rackspace
You can literally run your own cluster, provided you have a credit or debit card with some balance left. The steps to get started in the cloud are quite simple:
- Create an account with the cloud service provider.
- Upload your data into the cloud.
- Develop your data-processing application in a programming language of your choice.
- Configure and launch your cluster.
- Retrieve the output.
We will discuss this in more detail in a subsequent chapter.