
You may be thinking that deriving intelligence from underlying data is a new phenomenon, but in reality it has been there since the computer was developed for commercial use.
In the '70s, there were terminal-based reports extracted from OLTP systems, and in the '80s, IT teams were able to combine data on OLTP systems with desktop tools with additional analysis options using spreadsheets and user interface tools.
In the '90s, Ralph Kimball and Bill Inmon proposed data warehouse paradigms, which transformed the way data was used. Financial organizations were able to store historical transactions and product and customer data in their data warehouses in normalized or denormalized form to be exploited by reporting and analytics tools. Financial organizations did many such implementations on data warehouses using large relational databases, ETL, and analytics and reporting tools with the help of consulting and technology vendors.
In the 21st century, memory got cheaper and financial organizations were able to build large in-memory parallel data appliances such as Teradata and Netezza for advanced analytics.
The data on parallel platforms costs in the range of 20,000 to 100,000 US dollars and is generally tied to a single hardware vendor. Even though parallel platforms have the obvious advantage of extreme performance and easy maintenance, they just cannot cope with the explosive growth of the data.
By year 2014, the market has been flooded and in fact complicated by hundreds of expensive vendors with tools and platforms on ETL, analytics, virtualization, business intelligence, and data integration, each claiming to be better than others in one aspect or another.
But fortunately or unfortunately, memory kept getting cheaper and the desire to use larger data sets and complex analytics inched even higher, which led to more and more innovations.
Thankfully, we now have open source Hadoop and it looks set to dominate the data landscape for the foreseeable future.
As financial organizations usually accept a technology when it has been mature enough and proven in other industry sectors, Hadoop, being relatively new, is not going to completely replace the existing data warehouses in the near future, as existing data warehouses still prove to be beneficial.
A typical data warehouse for many financial organizations works as shown here:
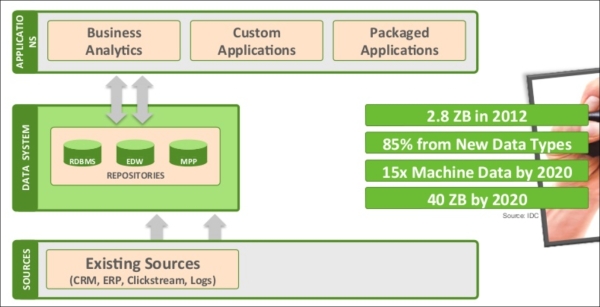
Source: the Horton Works website
But as data explodes and newer varieties of sources continue to appear, Hadoop has to be built alongside existing data warehouses with the intention to either share the data load or take on additional data sources (especially unstructured ones). That workflow is portrayed here:
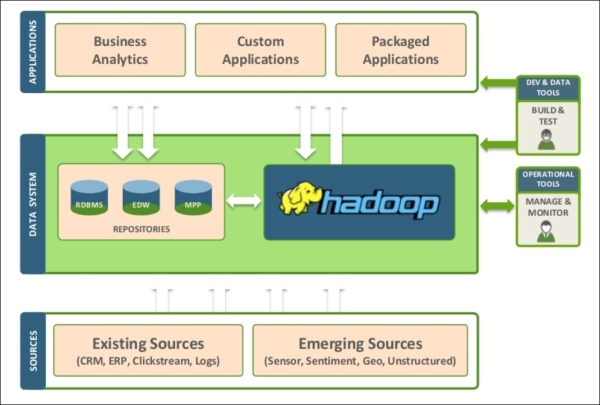
Source: the HortonWorks website
Financial organizations will continue to use Hadoop along with their existing databases and the BI and ETL tools that they are already used to. Most of the leading databases and BI and ETL tools provide connectors and APIs for Hadoop, which makes it a very cohabiting relationship, as shown here:
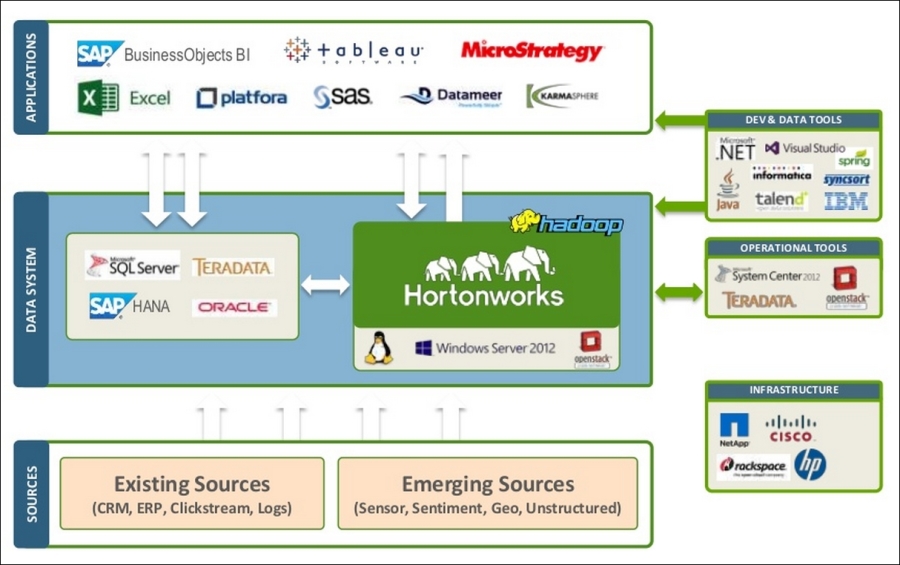
Source: the HortonWorks website
Most of the large financial organizations will have multiple data warehouses with many ETL jobs moving data from source systems to data warehouses and downstream systems. Hadoop comes as a savior and integrates them together by making it possible to have one large, extremely scalable data platform across the whole financial organization.
Big data projects work best when started as evolutionary rather than revolutionary. We recommend that the first few projects should be quick wins and should be small projects such as the migration of older transactional data from expensive databases to the Hadoop HDFS platform.