
Value at Risk (VaR) is a very effective method to calculate the financial risk of a portfolio. Monte Carlo is one of the methods used to generate the financial risk for a number of computer-generated scenarios. The effectiveness of this method depends on running as many scenarios as possible.
Currently, a bank runs the credit-risk Monte Carlo simulation to calculate the VaR with complex algorithms to simulate diverse risk scenarios in order to evaluate the risk metrics of its clients. The simulation requires high computational power with millions of computer-generated simulations; even with high-end computers, it takes 20–30 hours to run the application, which is both time consuming and expensive.
For our illustration, I will use Amazon Web Services (AWS) with Elastic MapReduce (EMR) and parallelize the Monte Carlo simulation using a MapReduce model. Note, however, that it can be implemented on any Hadoop cloud platform.
The bank will upload the client portfolio data into cloud storage (S3); develop MapReduce using the existing algorithms; and use EMR on-demand additional nodes to execute the MapReduce in parallel, write back the results to S3, and release EMR resources.
The bank loads the client portfolio data into the high-end risk data platform and applies programming iterations in parallel for the configured number of iterations. For each portfolio and iteration, they take the current Asset price and apply the following function for a variety of random variables:
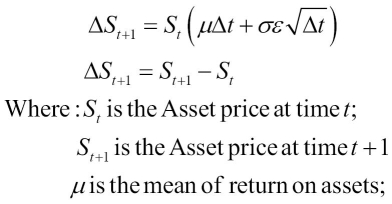
The asset price will fluctuate for each iteration. The following is an example with 15 iterations when the starting price is 10€:
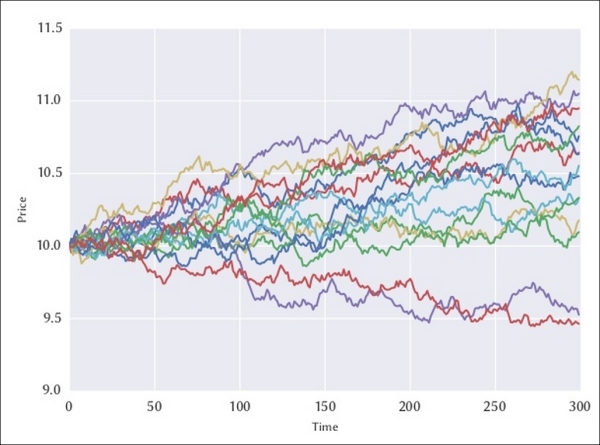
For a large number of iterations, the asset price will follow a normal pattern. As shown in the following figure, the value at risk at 99 percent is 0.409€, which is defined as a 1 percent probability that the asset price will fall more than 0.409€ after 300 days. So, if a client holds 100 units of the asset price in his portfolio, the VaR is 40.9€ for his portfolio.
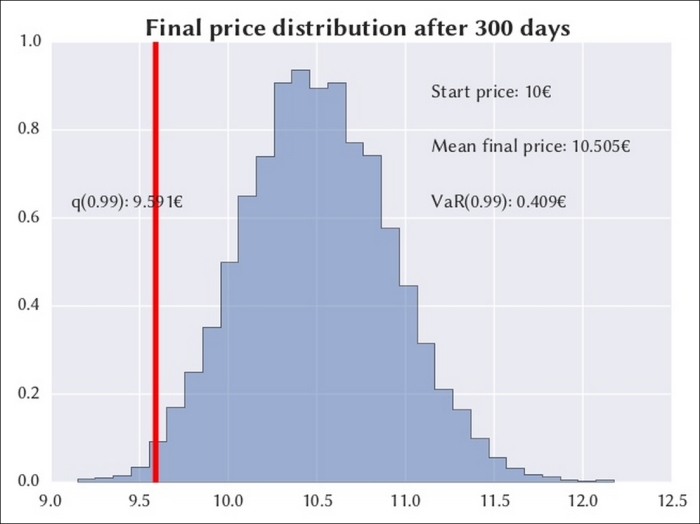
The results are only an estimate, and their accuracy is the square root of the number of iterations, which means 1,000 iterations will make it 10 times more accurate. The iterations could be anywhere from the hundreds of thousands to millions, and even with powerful and expensive computers, the iterations could take more than 20 hours to complete.
In summary, they will parallelize the processing using MapReduce and reduce the processing time to less than an hour.
First, they will have to upload the client portfolio data into Amazon S3. Then they will apply the same algorithm, but using MapReduce programs and with a very large number of parallel iterations using Amazon EMR, and write back the results to S3.
It is a classic example of elastic capacity—the customer data can be partitioned and each partition can be processed independently. The execution time will drop almost linearly with the number of parallel executions. They will spawn hundreds of nodes to accommodate hundreds of iterations in parallel and release resources as soon as the execution is complete.
The following diagram is courtesy of the AWS website. I recommend you visit http://aws.amazon.com/elasticmapreduce/ for more details.
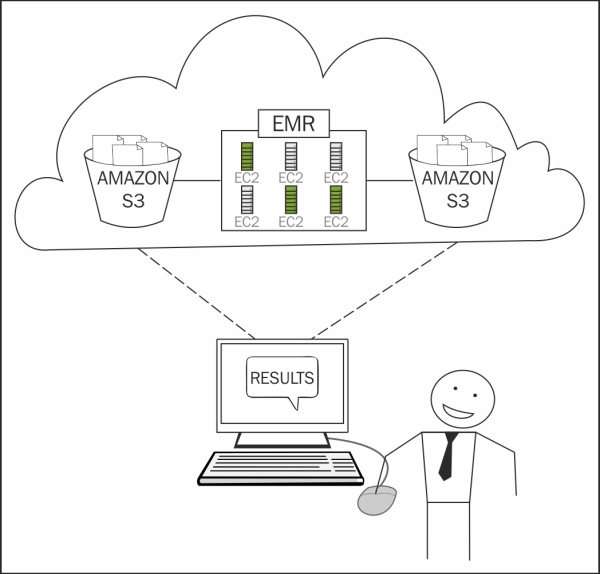
The data storage for this project is Amazon S3 (where S3 stands for Simple Storage Service). It can store anything, has unlimited scalability, and has 99.999999999 percent durability.
If you have a little more money and want better performance, go for storage on:
- Amazon DynamoDB: This is a NoSQL database with unlimited scalability and very low latency.
- Amazon Redshift: This is a relational parallel data warehouse with the scale of data in Petabytes and should be used if performance is your top priority. It will be even more expensive in comparison to DynamoDB and in the order of $1,000/TB/year.
Please visit http://docs.aws.amazon.com/ElasticMapReduce/latest/DeveloperGuide/emr-what-is-emr.html for full documentation and relevant screenshots.
Amazon Elastic Compute Cloud (EC2) is a single data processing node. Amazon Elastic MapReduce is a fully managed cluster of EC2 processing nodes that uses the Hadoop framework. Basically, the configuration steps are:
- Sign up for an account with Amazon.
- Create a Hadoop cluster with the default Amazon distribution.
- Configure the EC2 nodes with high memory and CPU configuration, as the risk simulations will be very memory-intensive operations.
- Configure your user role and the security associated with it.
Now you have to upload the client portfolio and parameter data into Amazon S3 as follows:
- Create an input bucket on Amazon S3, which is like a directory and must have a unique name, something like <organization name + project name + input>.
- Upload the source files using a secure corporate Internet.
I recommend you use one of the two Amazon data transfer services, AWS Import/Export and AWS Direct Connect, if there is any opportunity to do so.
The AWS Import/Export service includes:
- Export the data using Amazon format into a portable storage device—hard disk, CD, and so on and ship it to Amazon.
- Amazon imports the data into S3 using its high-speed internal network and sends you back the portable storage device.
- The process takes 5–6 days and is recommended only for an initial large data load—not an incremental load.
- The guideline is simple—calculate your data size and network bandwidth. If the upload takes time in the order of weeks or months, you are better off not using this service.
The AWS Direct Connect service includes:
- Establish a dedicated network connection from your on-premise data center to AWS using anything from 1 GBps to 10 GBps
- Use this service if you need to import/export large volumes of data in and out of the Amazon cloud on a day-to-day basis
Rewrite the existing simulation programs into Map and Reduce programs and upload them into S3. The functional logic will remain the same; you just need to rewrite the code using the MapReduce framework, as shown in the following template, and compile it as MapReduce-0.0.1-VarRiskSimulationAWS.jar.
The mapper logic splits the client portfolio data into partitions and applies iterative simulations for each partition. The reducer logic aggregates the mapper results, value, and risk.
package com.hadoop.Var.MonteCarlo;
import <java libraries>;
import <org.apache.hadoop libraries>;
public class VarMonteCarlo{
public static void main(String[] args) throws Exception{
if (args.length < 2) {
System.err.println("Usage: VAR Monte Carlo <input path> <output path>");
System.exit(-1);
}
Configuration conf = new Configuration();
Job job = new Job(conf, "VaR calculation");
job.setJarByClass(VarMonteCarlo.class);
job.setMapperClass(VarMonteCarloMapper.class);
job.setReducerClass(VarMonteCarloReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(RiskArray.class);
FileInputFormat.addInputPath(job, new Path(args[1]));
FileOutputFormat.setOutputPath(job, new Path(args[2]));
job.waitForCompletion(true);
}
public static class VarMonteCarloMapper extends Mapper<LongWritable, Text, Text, Text>{
<Implement your algorithm here>
}
public static class VarMonteCarloReducer extends Reducer<Text, Text, Text, RiskArray> {
<Implement your algorithm here>
}
}Once the Map and Reduce code is developed, please follow these steps:
- Create an output bucket on Amazon S3, which is like a directory and must have a unique name, something like <organization name + project name + results>.
- Create a new job workflow using the following parameters:
- Input Location: This inputs the S3 bucket directory with client portfolio data files
- Output Location: This outputs the S3 bucket directory to write the simulation results
- Mapper: The textbox should be set to
java -classpath MapReduce-0.0.1-VarRiskSimulationAWS.jar com.hadoop.Var.MonteCarlo.JsonParserMapper - Reducer: The textbox should be set to
java -classpath MapReduce-0.0.1-VarRiskSimulationAWS.jar com.hadoop.Var.MonteCarlo.JsonParserReducer - Master EC2 instance: This selects the larger instances
- Core Instance EC2 instance: This selects the larger instances and selects a lower count
- Task Instance EC2 instance: This selects the larger instances and selects a very high count, which must be in line with the number of risk simulation iterations
- Execute the job workflow and monitor the progress.
- The job is expected to complete much faster and should be done in less than an hour.
- The simulation results are written to the output S3 bucket.