
One of the biggest problems in the financial industry is the payment card fraud, and as of 2013, is reportedly at $14 billion globally and $7.1 billion within the U.S.
It is very common for retailers to store customers' credit card details, either due to recurring payments or for ease of frequent transactions. There have been many cases when, due to inadequate security standards, the card details have been stolen by hackers. I will not discuss how the card details are stolen and fraudulent transaction are done, but it is a huge cost to financial organizations in investigating the fraud and awarding compensations to customers.
Most retail banks are facing a similar problem of frequent credit/debit card fraud and are trying to implement a cost-effective solution to identify the suspicious transactions and deactivate the card, before more such transactions are made.
The proposed solution to this problem is to build a detection and monitoring model using Hadoop to identify the pattern of fraudulent transactions on the large set of transaction data. The principle is to identify outliers. For example, any transaction that is not normal is a sign of fraud; for example, a transaction of $50 in New York followed by another of $400 in Miami, just 10 minutes later.
There are many algorithms to identify outliers, such as Bayesian filters, Neural networks, data distance, clustering, relative density, and so on, but that is a separate statistical subject and beyond the scope of this book.
The bank has an expensive licensed in-memory system to identify fraudulent transactions. But with increasing volumes of data and more channels, by the time they are identified, it is too late. Often, these system are not flexible enough to accommodate social media data sources; for example, if a customer is holidaying abroad, then a transaction in another country would not suspicious and therefore should not be blocked by the bank.
The bank will use historical transaction data to build a model, using a single algorithm or combination of algorithms. The model needs to be refreshed with new transactions on a periodic basis, so that it is up-to-date with the emerging buying trends.
As discussed in the previous chapter, it will use batch MapReduce to develop the model and reuse the already developed code.
Apache Kafka is a good source for persistent real-time distributed messaging, which will be used to collect the real-time transactions.
Once the model is developed, it will use either Storm or Spark to process the incoming data and predict outliers or fraudulent transactions in real time by using the Hadoop parallel processing framework.
The new architecture should be like this:
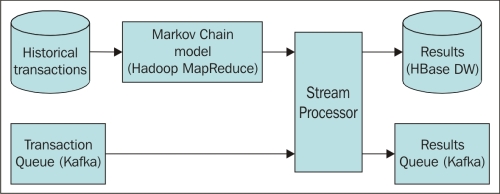
The steps to execute the model developed in the previous chapter are:
- Copy the historical transaction data on HDFS (if not already present) at
/<user directory>/txndata/input. - Generate transaction sequence data with Java MapReduce—transactions grouped by customer ID and in sequence of time. There is no harm in using Hive or Pig as well:
JAR_NAME=<app path>/<txnSequence>.jar CLASS_NAME=org.fraud.mr.txnSequence echo "running MapReduce" IN_PATH=/<user directory>/txndata/input OUT_PATH=/<user directory>/txndata/sequence echo "input $IN_PATH output $OUT_PATH" hadoop fs -rmr $OUT_PATH echo "removed output dir" hadoop jar $JAR_NAME $CLASS_NAME -Dconf.path=/<user app directory>/fraud/txndata.properties $IN_PATH $OUT_PATH
- Generate Markov Chain Model with MapReduce, using the following code:
JAR_NAME=<app path>/<StateTransitionModel>.jar CLASS_NAME=org.fraud.mr.StateTransitionModel echo "running MapReduce" IN_PATH=/<user directory>/txndata/sequence OUT_PATH=/<user directory>/txndata/model echo "input $IN_PATH output $OUT_PATH" hadoop fs -rmr $OUT_PATH echo "removed output dir" hadoop jar $JAR_NAME $CLASS_NAME -Dconf.path=/<user app directory>/fraud/txndata.properties $IN_PATH $OUT_PATH
- Write a basic Python script called
transaction_kafka_queue.pyto read and load the model results, read and write the new transactions to the Kafka queue, and so forth. The Python script will have two arguments—the first argument is the action (getModel,setModel,readQueue, orwriteQueue) and the second is the data file. - Copy the Markov Chain results locally:
hadoop fs -get /<user directory>/txndata/model/part-r-00000 txnmodel.txt - Load it to the Kafka queue, using the following Python script:
./transaction_kafka_queue.py setModel txnmodel.txt - Test the model by using some transaction data from the historical data on HDFS and copy the last 100 transactions into the queue:
hadoop fs -cat =/<user directory>/txndata/input/transaction.txt | head -100 | hadoop -put - =/<user directory>/txndata/input/txn_test.txt ./transaction_kafka_queue.py writeQueue txn_test.txt
Before we move on to the next sections on real-time processing, I will have to explain both Storm and Spark architecture briefly, but I expect you to start reading Apache documentation, should you need to understand it in more detail.
There have been discussions on the Web claiming that one is better than the other, but both have different architectures and many times are used for different use cases.
For our case, we can choose either, but in this chapter I will discuss both options in subsequent sections.
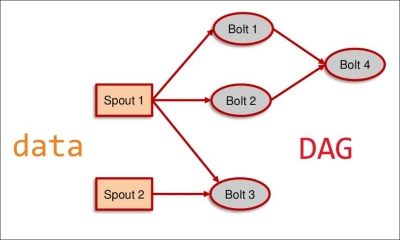
- Spout: This is a source of input data streams that can be any real-time data input, such as Twitter API or a transaction queue.
- Bolt: This consumes data streams from spouts, executes transformation functions, and potentially produces more streams to bolts. Kafka will be used to stream messages and HBase for persistent data storage.
- DAG: This is a workflow of data movement from one stream to another.
Storm is not restricted to only two stages—map and reduce. It can have multiple stages, as defined in the Storm topology.
The Storm topology is depicted in the following figure:
Let's briefly see how Storm will be configured for our project:
- One spout for ingesting the transaction stream from the Kafka queue and one bolt for processing.
- The incoming transaction stream is grouped by customer ID and fed to the bolt for processing.
- For each bolt, a window of transaction size is configured for each user. The bolt calculates the prediction metric using developed models and flags if the current sequence is suspicious.
- The bolt will calculate the total probability of all state transitions for the sequence of transactions in the window by using the probability metric from the model. If the transaction is not normal, it will have a lesser probability and a higher metric.
- If the metric exceeds the threshold, it is suspicious and will be written to the Kafka queue.
Spark is written in Scala and is the preferred language to program. I encourage you to learn a bit more about Scala at http://www.scala-lang.org.
The algorithm used in Storm will be same for Spark as well.
Let's briefly cover the key terms:
- RDD is a resilient, distributed dataset, and the fundamental unit of data in Spark. The programming revolves around operations on RDD.
- Just like Storm, Kafka will be used for streaming messages, and HBase will be used for persistent data storage.
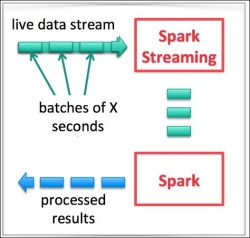
We will use the Spark Streaming component of Spark. As shown in the following figure, Spark streaming allows data to be read from most data sources and written to most data targets, which makes it very popular:

Spark Streaming runs on the Spark engine and splits the live data streams into micro batches (minimal 0.5 seconds), which are processed using Spark.
Selecting the correct micro batch window size is very important to keep a good balance between real time and a large enough batch size for a proper analysis.
As shown in the following figure, the batch window size can be anything from 0.5 seconds to a few minutes, depending on how quickly and accurately we would like to detect the fraud. If the window size is in the order of a few seconds, there may be false detection, but if it is too high and in the order of minutes, it may be too late to take action:
The bank's card systems will publish the transaction events to the Kafka queue.
I will discuss the processing of messages using both technologies—Storm and Spark—one by one.
Once the model is built, we can use it to process new data streams to detect outlier transactions.
The design is based on stateless functional programming—a new row of transaction doesn't depend on any other row or state, so it can be distributed across a cluster of Hadoop machines, to achieve extreme performance.
To read the real-time transaction data, all we have to do is build a Spout to read the data from Kafka using Java, as shown in the following code template, which needs to be customized as per our business needs:
package org.fraud.predictor;
import <java libraries>;
import kafka.message.Message;
import storm.kafka.PartitionManager.KafkaMessageId;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
public class KafkaSpout extends BaseRichSpout {
public static class MessageAndRealOffset {
public Message msg;
public long offset;
public MessageAndRealOffset(Message msg, long offset) {
this.msg = msg;
this.offset = offset;
}
}
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
<Implement Kafka configuration - Zookeper, connection details, etc.>
}
public void close() {
_state.close();
}
public void nextTuple() {
<loop through all partitions>
}
public void ack(Object msgId) {
// TODO Auto-generated method stub
}
public void fail(Object msgId) {
// TODO Auto-generated method stub
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("message"));
}
public boolean isDistributed() {
return false;
}
}Once the model is built, we can use it to process new data streams to detect outlier transactions.
The main assumption are:
- Stateless functional programming using Scala
- The real-time transactions are published using Kafka
The steps to read the real-time transaction data are:
- The incoming RDD data streams are also called DStream. As done in the following lines of code, we use the Spark interface utility to convert Kafka data streams into DStream:
val messages = KafkaUtils.createStream[String, SingleTransaction, StringDecoder, SingleTransactionDecoder](streamingContext, kafkaParams, topics, StorageLevel.MEMORY_ONLY)
- We will then group the incoming customer transactions as shown here:
val transactionByCustomer = messages.map(_._2).map { transaction => val key = transaction.customerId var tokens = transaction.tokens (key, tokens) }
I will discuss both options—Storm and Spark—one by one.
We will create one bolt class to process the queue:
package org.fraud.predictor;
import <java libraries>;
import backtype.storm.Config;
import backtype.storm.StormSubmitter;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
public class OutlierPredictor {
public static class PredictorBolt extends BaseRichBolt {
private OutputCollector collector;
private ModelBasedPredictor predictor;
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
predictor = new MarkovModelPredictor(stormConf);
//MarkovModelPredictor should be implemented separately
}
}
public void execute(Tuple input) {
String entityID = input.getString(0);
String record = input.getString(1);
double score = predictor.execute( entityID, record);
//write score to db
//ack
collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
public static void main(String[] args) throws Exception {
String topologyName = args[0];
String configFilePath = args[1];
FileInputStream fis = new FileInputStream(configFilePath);
Properties configProps = new Properties();
configProps.load(fis);
//intialize config
Config conf = new Config();
conf.setDebug(true);
for (Object key : configProps.keySet()){
String keySt = key.toString();
String val = configProps.getProperty(keySt);
conf.put(keySt, val);
}
//spout
TopologyBuilder builder = new TopologyBuilder();
int spoutThreads = Integer.parseInt(configProps.getProperty("predictor.spout.threads"));
builder.setSpout("predictorSpout", new PredictorSpout(), spoutThreads);
//detector bolt
int boltThreads = Integer.parseInt(configProps.getProperty("predictor.bolt.threads"));
builder.setBolt("predictor", new PredictorBolt(), boltThreads)
.fieldsGrouping("predictorSpout", new Fields("entityID"));
//submit topology
int numWorkers = Integer.parseInt(configProps.getProperty("num.workers"));
conf.setNumWorkers(numWorkers);
StormSubmitter.submitTopology(topologyName, conf, builder.createTopology());
}
}For persistent storage, the results can be written to HBase by simply amending the preceding template, using HBase bolts instead of BaseRichBolt as:
We will create an algorithm using Scala to calculate scores:
def apply(s: String, stateTranstionProb: Array[Array[Double]], states: Array[String], stateSeqWindowSize: Int): Scorer = {
if (s == "MissProbability") {
return new MissProbability(stateTranstionProb, states, stateSeqWindowSize)
} else if (s == "MissRate") {
return new MissRate(stateTranstionProb, states, stateSeqWindowSize)
} else {
return new entropyReduction(stateTranstionProb, states, stateSeqWindowSize)
}
}This Spark code can also be easily amended to write to HBase with the following code template:
val sparkContext = new SparkContext("local", "Simple App")
val hbaseConfiguration = (hbaseConfigFileName: String, tableName: String) => {
val hbaseConfiguration = HBaseConfiguration.create()
hbaseConfiguration.addResource(hbaseConfigFileName)
hbaseConfiguration.set(TableInputFormat.INPUT_TABLE, tableName)
hbaseConfiguration
}
val rdd = new NewHadoopRDD(
sparkContext,
classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[Result],
hbaseConfiguration("/path/to/hbase-site.xml", "table-with-data")
)
import scala.collection.JavaConverters._
rdd
.map(tuple => tuple._2)
.map(result => result.getColumn("columnFamily".getBytes(), "columnQualifier".getBytes()))
.map(keyValues => {
keyValues.asScala.reduceLeft {
(a, b) => if (a.getTimestamp > b.getTimestamp) a else b
}.getValue
})