
Data lake is undoubtedly one of the most popular architecture patterns to land all types of data at a single place. The key points are:
- Combine the power of traditional RDBMS with Hadoop to process data
- Use traditional data RDBMS to process low-volume high-value data
- Use Hadoop for high-volume and new types of data sources—semistructured and unstructured data sources, such as legal documents, e-mails, web data, and machine log data
The following screenshot is from the Hortonworks website and shows how a co-existing traditional RDBMS and Hadoop provides a good balance to process all types of data:
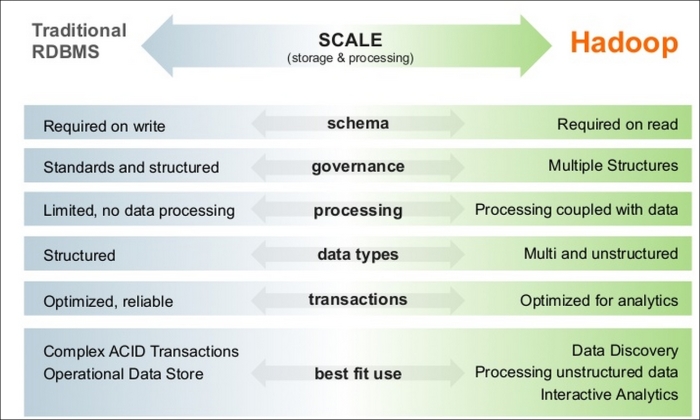
The analytics and visualization of data needs to be scalable as well. The unstructured and semi-structured text will be stored on Hadoop and processed using the Hadoop tools. With further analytic steps performed on the unstructured and semistructured data, it will be refined and will become more structured, and eventually, it can be migrated to databases for visualization.
So, data analysis and visualization tools such as SAS, Tableau, and SAP work on both traditional databases such as EDW, CRM as well Hadoop processed data.
The end-to-end architecture of a typical large financial organization looks like the following screenshot from the Hortonworks website:
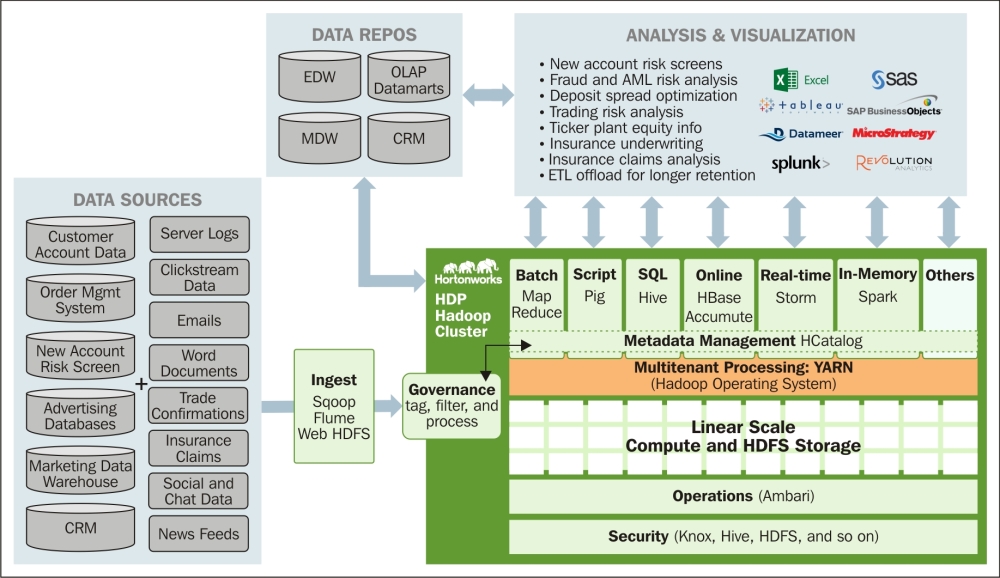
As shown in the preceding screenshot, the data sources will be a combination of structured data (customer accounts, orders, risk, and CRM) and unstructured/semi-structured data (logs, e-mails, clickstream, and social media), which can be ingested using Sqoop, Flume, or a direct copy.
The good news is that even database vendors are integrating with Hadoop. For example, Teradata has created a transparency layer using the analytic engine and HDFS filesystem called Teradata QueryGrid™ that allows data in Hadoop to be explored through queries issued by Teradata.
The path to create an enterprise data lake is as follows:
- Stage 1: Acquire data from various sources with basic transformation. The data is at scale in one place.
- Stage 2: Transform data using skills, tools, and technologies that are practical for your organization. There is no pressure to use Hadoop; use it only if there is any value added.
- Stage 3: Analyze data using tools and technologies that are practical for your organization. Again, no pressure to use Hadoop; use it only if there is any value added.
- Stage 4: All data governance principles of compliance, security, audit, dictionary, and data traceability hold for data on both Hadoop and non-Hadoop platforms. So, follow all data governance rules.