
In financial organizations, as we are in the year 2015, business is almost always demanding analytics in real time.
As discussed in the previous chapter, Hadoop can process data in memory using Storm or Spark, but what a business really needs is the ability to combine the full historical dataset on disk with real-time in-memory data.
Lambda architecture addresses this requirement. The concept is very simple, yet powerful: Use both, the batch layer and the speed layer, using a shared serving layer, as shown next:
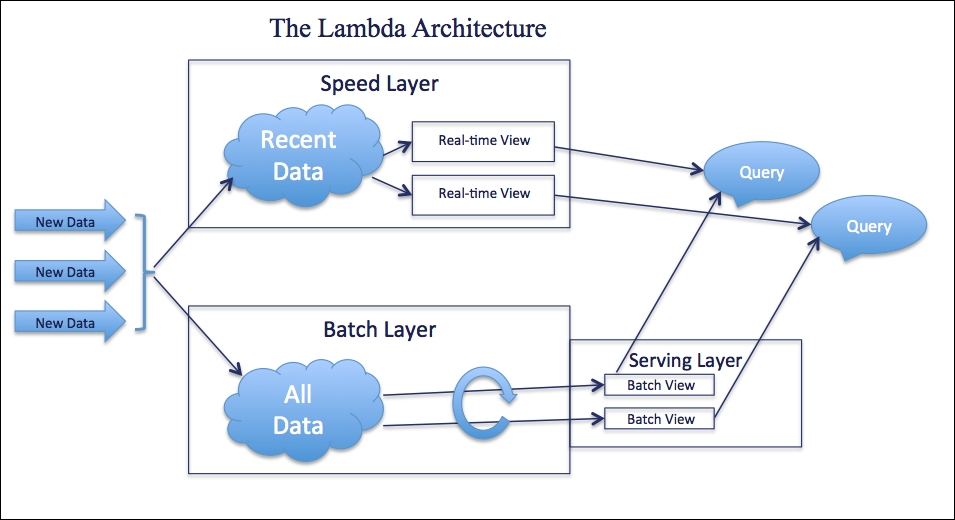
We already know which technologies are suited for batch layer and which ones for speed layer.
- Incoming data: This enters both batch layer and speed layer, and each layer will process it at its own pace
- Batch layer: The data is written as append only and read in high latency on HDFS:
- MapReduce jobs are used to precompute batch views periodically
- Master dataset is the complete master dataset that includes full data history
- Speed layer: Storm or Spark will ingest real-time data from queues or publish-subscribe systems:
- Updates are possible and the data is stored in a read/write database, such as HBase, Cassandra, or Redis
- Real-time views are stored on read/write database
- Query and serving layer: This simply queries the batch and real-time views and merges them:
- The batch views are indexed and stored on HBase or ElephantDB for faster ad hoc queries
- Real-time data can be accessed from speed layer
- Apache Drill is a good ANSI-SQL-2003-compliant data access query engine
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.