Big data governance is essential for maintaining the data quality and allowing analysts to make better decisions. It will enable financial organizations to avoid the costs associated with low-quality data re-work and reporting in compliance with regulations, such as Sarbanes-Oxley and Basel II/Basel III.
Big data governance should include at a minimum:
- Data definitions including metadata: Must know what is the data stored on the Hadoop platform.
- Full data process lineage: Must know where is the data coming from, what transformation has it gone through, and where has it eventually landed.
- NoSQL stores: These are flexible schema but that doesn't mean that we will store any junk. Even if we allow flexible schema, any changes to schema should be documented.
For any large big data program, I recommend a three-tiered approach on governance, as mentioned next:
- Low: Raw data received on the landing area such as machine log, documents, and so on only needs to be governed at a high level, such as who can access it, when was it received, and how long it needs to be retained.
- Medium: Once the raw data has gone through data quality validation, cleansed and transformed, it turns into information. It still needs to be governed at a high level, such as who can access it, when was it received, and how long it needs to be retained. Additionally, the data quality needs to be monitored.
- High: The data has gone through further transformation, aggregated, and turned into a golden trusted source. The data is structured with well-defined schema and metadata. It must be fully governed, that is, who can access it; what, how, and when will they access it; and everything should be recorded and controlled.
Once you have implemented couple of big data systems on Hadoop, your clusters can have hundreds to thousands of Oozie coordinator jobs and so many dataset and process definitions. This becomes too difficult to manage and results in common mistakes, such as duplicate datasets and processes, incorrect job execution, and lack of audit control and traceability.
Apache Falcon is one of the leading tools for administrators and data stewards to address the data governance challenges.
Note
I will provide a brief overview of this tool, but please visit http://falcon.apache.org for more details.
Hadoop distribution companies come up with their own data governance tools as well, with similar features. For example, Cloudera has its own data governance tool called Navigator. As Hortonworks is completely open source, they use Falcon in their distribution.
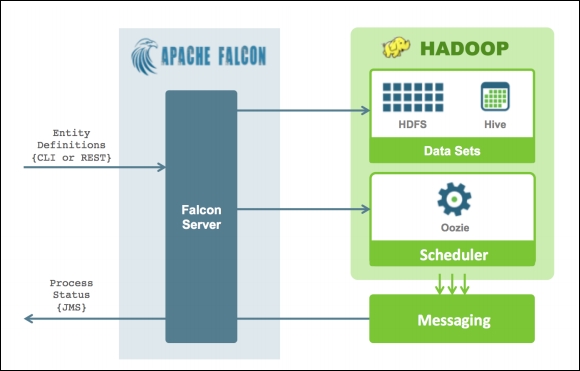
Apache Falcon is a data management tool that defines, schedules, and monitors data processing elements.
It defines three types of entities in a simple XML format that can be combined to describe data management policies.
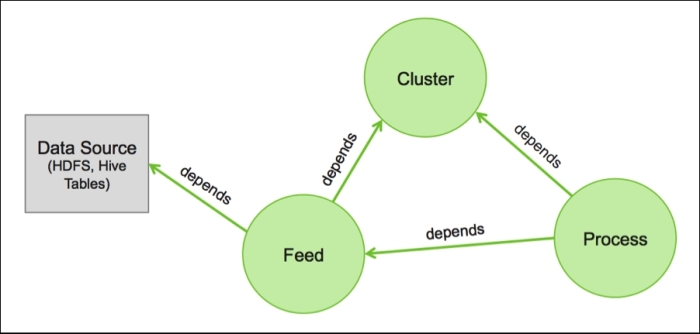
- Cluster: This is defined first, as both the feed and the process entity depend on it. Once configured, submit this cluster entity to Falcon using the following command:
falcon entity -type cluster -submit -file <cluster-entity>.xml - Feeds: This is defined for each feed on Hadoop with parameters such as feed frequency, cluster, data retention period, and HDFS location of the feed. For example, in a trade data warehouse, every set of trade and position files with shared characteristics will have a feed entity configuration XML. Once configured, submit and schedule each feed entity using the following command:
falcon entity -type feed -submit -file <feed-entity>.xml falcon entity -type feed -schedule -name <feed-entity>
- Process: This is defined for the Pig/Hive/bash scripts and Oozie workflows with parameters such as cluster, execution frequency, input feed entity, output feed entity, and retry attempt count. Once configured, submit and schedule each feed entity using the following command:
falcon entity -type feed -submit -file <process-entity>.xml falcon entity -type feed -schedule -name <process-entity>
The configuration parameters allow a rich set of data management polices, including late data arrival, replication across clusters, and so on.
Falcon is a distributed application and its servers can be deployed across multiple clusters, if needed. It transforms entity definitions into repeatable actions using Oozie as its scheduler and its high-level architecture is shown next: