
A search component is a reusable module that contributes to search results. While defining a search handler, that is, a controller for a given kind of search, you can customize its behavior by defining and configuring search components that will contribute to its output results.
Search components must be declared and used within solrconfig.xml, the main Solr configuration file. A component declaration requires a name, the implementation class, and a set of optional initialization parameters:
<searchComponent name="prices" class="a.b.c.MyComponent">
<str name="ds-jndi">jdbc/datasource</str>
<str name="service-uri">http://example.org#me</str>
</searchComponent>Once declared, these can be used within request handlers, which are the runtime controllers of the executions of requests (we will cover request handlers later in the chapter).
There are some predefined search components that mustn't be explicitly declared in solrconfig.xml.
The default components are those components that are responsible for absolving the fundamental or common steps of a query execution flow. This is the reason there's no need to declare them explicitly, unless you want to use a different configuration. In the following sections, we will illustrate these components.
The query component is responsible for parsing and executing a query. This is the component that accepts query and query parser parameters, gets a reference to the appropriate query parser, coordinates the parser in order to produce a query, executes that query, and outputs a corresponding response.
This component enables the so-called faceted search. It contributes to search results by adding a set of configurable aggregations called facets.
When you execute some search, you will get back a single page of results consisting of a certain number of matching documents. Enabling faceting allows you to get an additional perspective of the overall data, consisting of a set of aggregations. The following screenshot shows some Solr-powered facets in action on a website, on the right side:

The facet component can be activated by specifying a facet parameter with one of the following values: yes, true, or on.
Solr provides several types of facets: queries, fields, ranges, pivot, and interval. Each of them, whenever enabled, will add a dedicated section to the response.
The facet.query parameter declares a query (parsed by the Solr query parser) that will be used as a facet with the corresponding counts. The results (that is, counts) of this facet will be in a specific response section called facets_queries. The parameter can be repeated multiple times, allowing us to specify several queries. Using the example dataset, with Solr running, open a browser and type http://127.0.0.1:8983/solr/example/select?q=*:*&facet=true&facet.query=genre:jazz
In the XML response, you will see matching documents within the <result> tag, and an additional section dedicated to facets:
<lst name="facet_counts"> <lst name="facet_queries"> <int name="genre:Jazz">3</int> </lst> <lst name="facet_fields"/> <lst name="facet_dates"/> <lst name="facet_ranges"/> </lst>
Here, you can see that three documents match the facet query. The other facet sections are empty because we didn't ask for them.
Facet fields are surely the most popular kind of facets. They aggregate search results using a set of given and configurable fields.
Other than activating the facet feature for a given field, Solr has a rich set of parameters that can be used to tune and configure the field's faceting behavior. These settings can be specified for all fields or for a given field. For the first case, the following table illustrates the available parameters, their names, and meanings. For field-specific settings, the same parameters must be declared with the following convention:
f.<field>.<parameter> = <value>
In this way, the value associated with parameter will be valid only for the specific field.
Returning to our previous example, let's remove the facet query and use some additional parameters so that facet fields will be built (for simplicity, only the query string is reported):
q=*:*&facet=on&facet.field=genre&facet.minCount=1
In the facet sections, you will see the genre facets under the facet_fields subsection:
<lst name="facet_fields">
<lst name="genre">
<int name="Progressive Rock">10</int>
<int name="Rock">5</int><int name="Fusion">4</int>
<int name="Heavy Metal">4</int>
…
<int name="Pop metal">1</int></lst>
</lst>We asked for the genre facet and we set mincount to 1, which means that facets with no counts are excluded from the response. It is important to underline the fact that the displayed value for a facet field is its indexed value, and not the stored value (that is, the value that is copied verbatim as it arrives in input documents). In the previous example, the genre field is String, and therefore, it is not tokenized. This is the reason you see the compound term (Progressive Rock) as one of its values. If that field had been declared as TextField and tokenized with WhiteSpaceTokenizer, you would have seen two different values for that facet (assuming no further filtering): Progressive and Rock.
Facet ranges can be applied to numeric or date fields. As the name suggests, with facet ranges, Solr creates a facet classification based on ranges. The following parameters control this kind of faceting:
The following is a sample query that uses facet ranges for faceting albums by release date:
q=*:*&facet=on&facet.range=released&facet.range.start=1950&facet.range.end=2000&facet.range.gap=10
That will add another section within the facet_counts element:
<lst name="facet_ranges">
<lst name="released">
<lst name="counts">
<int name="1950">1</int>
<int name="1960">1</int>
<int name="1970">6</int>
<int name="1980">8</int>
<int name="1990">5</int>
</lst>
…
</lst>
</lst>We previously described facet fields; they provide the ability to aggregate search results by one or more categories. Pivot facets go a step ahead in that direction. They allow us to analyze data in multiple dimensions, breaking down the faceted values by subsequent, nested subcategories.
This kind of faceting can be activated through a request like this:
q=*:*&facet=on&facet=true&facet.pivot=genre,released
The facet.pivot parameter can be repeated multiple times. For each repetition, there will be a dedicated and aggregated result within the facet_pivot section of the response. Here, for simplicity, we put just one parameter with two categories, genre and released. The following example is an extract of the response you will get using the sample instance associated with this chapter:
<lst name="facet_pivot"> <arr name="genre,released"> <lst> <str name="field">genre</str> <str name="value">Progressive Rock</str> <int name="count">10</int> <arr name="pivot"> <lst> <str name="field">released</str> <int name="value">1992</int> <int name="count">2</int> </lst> <lst> <str name="field">released</str> <int name="value">1969</int> <int name="count">1</int> </lst> <lst> <str name="field">genre</str> <str name="value">Rock</str> <int name="count">5</int> <arr name="pivot"> <lst> <str name="field">released</str> <int name="value">1969</int> <int name="count">1</int> </lst> <lst> <str name="field">released</str> <int name="value">1986</int> <int name="count">1</int> </lst> …
As you can see, the genre facet is broken down by a nested released category. Note that the preceding nested structure is returned with just one request-response interaction. In order to get the same result with classic facet fields, you should query Solr several times with incremental filters. That's the reason the pivot facets feature, acting as a façade and hiding all of that interaction complexity, is very useful for navigating the hierarchy of those aggregations. However, it should be used carefully, as it could have an impact on performance.
Interval facets were introduced in Solr 4.10. They can be seen as an alternative to facet (range) queries because they allow you to set interval criteria for one or more fields, and count the number of matching documents that have values within those constraints.
Although the same result can be achieved with facet range queries, this implementation could provide performance improvement in several contexts. As suggested in the Solr reference guide, it is recommended that you try both the methods.
The highlight component contributes to search results by adding a section that contains (for each document in the current result page) a set of snippets highlighting the search terms that are in the document content (that is, in one or more fields of the document). The following screenshot shows a web application that uses the highlighting feature:
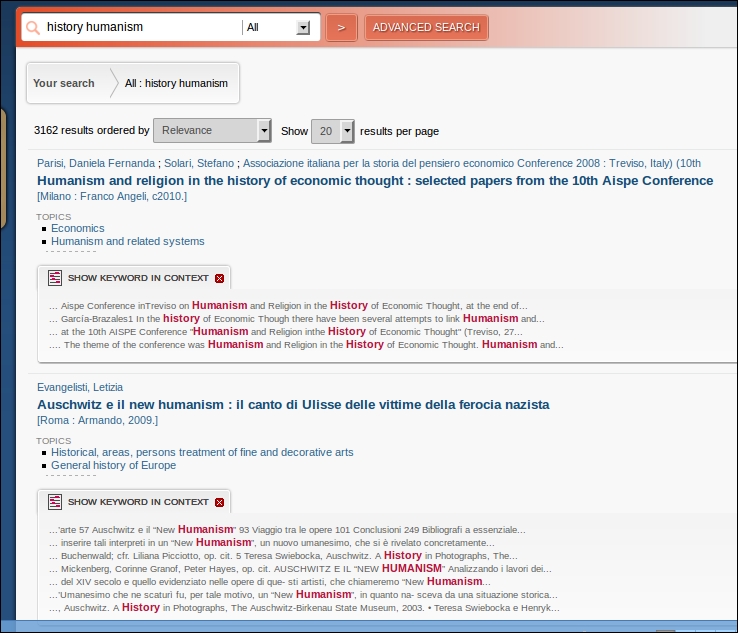
This feature is particularly useful when your data comes from rich documents such as PDFs or Microsoft Office documents (as shown in the preceding example). Using the highlighting feature, it's possible to give the end user an approximate idea of the context where, within the document, entered terms have been found.
The highlighting component can be tuned, or configured, with several parameters. Fortunately, the provided default values work well in many scenarios. Some of those parameters are described in the following table:
|
Parameter |
Description |
|---|---|
|
|
Turns highlighting off or on. The default value is |
|
|
Terms to be highlighted are taken from the main query unless this parameter, which itself requires a query, is specified. |
|
|
A space- or comma-separated list of fields that will be used for highlighting. Snippets will come only from these fields. |
|
|
The number of highlighting snippets that will be returned. The default value is |
|
|
The maximum number of characters that will be inspected (in a given field) to compute the snippets. |
|
|
Indicates text that should appear before and after a highlighted term. They default to |
Solr comes with three different kind of highlighters, described in the following sections.
This is the first highlighter that was introduced in Solr. Solr uses it by default. It is able to work on top of a lot of query types and doesn't have any special requirement on fields to be highlighted. However, in order to speed up its work, termVectors should be turned on (for those fields).
Fast vector highlighter is the second type of highlighter introduced in Solr. It requires that termVectors, termPositions, and termOffsets are turned on for each field that needs to be highlighted. That allows fast and scalable execution, especially with documents containing large amounts of text, but requires a lot of extra space for the index. However, it supports few query types.
The fast vector highlighter can be enabled by setting the hl.useFastVectorHighlighter parameter to true.
Note that, if the preceding flags are not set for target fields, Solr will continue to use StandardHighlighter.
This highlighter doesn't use term vectors, nor does it reanalyze the text to be highlighted. It only requires the storeOffsetsWithPositions flag set for the fields to be highlighted. Unlike the others, this highlighter must be explicitly declared in the solrconfig.xml file with the following declaration:
<searchComponent class="solr.HighlightComponent" name="highlight">
<highlighting class="org.apache.solr.highlight.PostingsSolrHighlighter"/>
</searchComponent>This is a good compromise, compared with the first two highlighters, in terms of performance and index space. The information (that is, the posting offsets) required by the storeOffsetsWithPositions flag is cheaper than term vectors in terms of memory and disk occupation. However, it is supposed to be used to highlight simple query terms, so it could have some unexpected or unwanted results with phrase queries.
The more like this search component allows us to find documents that have some kind of similarity with a given document. There are several ways to use this feature in Solr:
MoreLikeThisHandler: This is a front controller that is completely dedicated to "more like this" requests. It accepts a query that identifies a document, and looks for similar documents according to a configured criterion.MoreLikeThisHandler: This is similar toMoreLikeThisHandler, but instead of taking a document as the input (matched by a given query), the text used to compute similarity can be directly passed or fetched from a URL.MoreLikeThisSearchComponent: As a search component, it will execute the similar search for each document of the current result page, thus appending a more like this section to the Solr response, with a list of similar documents for each document. This is not really recommended because it could slow down overall query execution.
In general, the first type is the most widely used. MoreLikeThis doesn't have special requirements for fields that are to be used for the similarity computation. However, for best performance, TermVectors should be enabled for them.
The following table illustrates the parameters accepted by this component:
Other than the components we saw in the previous sections, there are other built-in search components that are part of the Solr framework. Remember that, if you want to use them, they will have to be explicitly declared and configured within the Solr configuration.
The following is a short and non-exhaustive list of additional components:
- Query elevation: This is used to give more importance to some results using a criterion that has nothing to do with the normal Solr scoring algorithm. The component lets you associate a given query with a corresponding list of most important results.
- Terms: This provides access to the Lucene internal term dictionary.
- Stats: This provides numeric fields statistics.
- Spellcheck: This provides spell checking capabilities by means of n-gram analysis of indexed documents or external dictionaries. From a functional point of view, this component is used to build the so-called "Did you mean?" feature, offering alternative search suggestions in case of user mistakes.
- Term Vector: This adds term vectors (that is, term, frequency, position, offset, and IDF) of the matching documents to a request.
- Debug: This adds debuging and explanatory information about the request execution.