
The following sections will describe and illustrate a couple of ways of extending, and customizing searches in Solr.
Sometimes, as a part of your search results, you may want to have data that is not managed by Solr but retrieved from a real-time source, such as a database.
Think of an e-commerce application; when you search for something, you will see two pieces of information beside each item:
- Price: This could be the result of some kind of frequently updated marketing policy. Non-real-time information could cause problem on the vendor side (for example, a wrong price policy could be applied).
- Availability: Here, wrong information could cause an invalid claim from customers; for example, "I bought that book because I saw it as available, but it isn't!"
This is a good scenario for developing a search component. We will create our search component and associate it with a given RequestHandler.
A search component is basically a class that extends (not surprisingly) org.apache.solr.handler.component.SearchComponent:
public class RealTimePriceComponent extends SearchComponent
The initialization of the component is done in a method called init. Here, most probably we will get the JNDI name of the target data source from the configuration. This source is where the prices must be retrieved from:
public void init(NamedList args) {
String dsName = SolrParams.toSolrParams(args).get("ds-name");
Context ctx = new InitialContext();
this.datasource = (DataSource) ctx.lookup(dName);
}Now we are ready to process the incoming requests. This is done in the process method, which receives a ResponseBuilder instance, the object we will use to add the component contribution to the search output. Since this component will run after the query component, it will find a list containing query results in ResponseBuilder. For each item within those results, our component will query the database in order to find a corresponding price:
public void process(ResponseBuilder builder) throws IOException {
SolrIndexSearcher searcher = builder.req.getSearcher();
// holds the component contribution
NamedList contrib = new SimpleOrderedMap();
for (DocIterator it = builder.getResults().docList.iterator(); iterator.hasNext();) {
// This is the Lucene internal document id
int docId = iterator.nextDoc();
Document ldoc = searcher.doc(docId, fieldset);
// This is the Solr document Id
String id = ldoc.get("id");
// Get the price of the item
BigDecimal price = getPrice(id);
// Add the price of the item to the component contribution
result.add(id, price);
}
// Add the component contribution to the response builder
builder.rsp.add("prices", result);
}In solrconfig.xml, we must declare the component in two places. First, we must declare and configure it in the following manner:
<searchComponent name="prices" class="a.b.c. RealTimePriceComponent">
<str name="ds-name">jdbc/prices</str>
</searchComponent>Then it has to be enabled in request handlers (as shown in the following snippet). Since this component is supposed to contribute to a set of query results, it must be placed after the query component:
<requestHandler name="/xyz" …> … <arr name="last-components"> <str>prices</str> </arr> </requestHandler>
Done! If you run a query invoking the /xyz request handler you will see after query result a new section called prices (the name we used for the search component). This reports the document id and the corresponding price for each document in the search results.
Tip
You can find the source code of the entire example in the src folder of the project associated with this chapter, under the org.gazzax.labs.solr.ase.ch3.sp package.
If you want to start Solr with that component, just run the following command from the command line or from Eclipse:
mvn clean install cargo:run –P custom-search-component
In a project I was working on, we implemented the autocomplete feature, that is, a list of suggestions that quickly appears under the search field each time a user types a key. Thus, the search string is gradually composed. The following screenshot shows this feature:
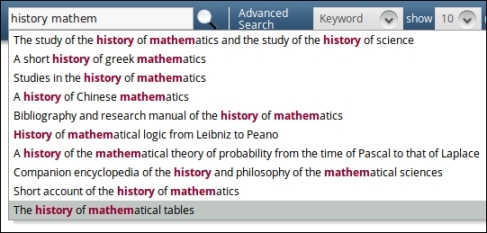
A new response writer was implemented because the user interface widget had already been built by another company, and the exchange format between that widget and the search service had been already defined.
Doing that in Solr is very easy. A response writer is a class that extends org.apache.solr.response.QueryResponseWriter. Like all Solr components, it can be optionally initialized using an init callback method, and it provides a write method where the response should be serialized according to a given format:
public void write(
Writer writer,
SolrQueryRequest request,
SolrQueryResponse response) throws IOException {
// 1. Get a reference to values that compound the current response
NamedList elements = response.getValues();
// 2. Use a StringBuilder to build the output
StringBuilder builder = new StringBuilder("{")
.append("query:'")
.append(request.getParams().get(CommonParams.Q))
.append("',");
// 3. Get a reference to the object which
// hold the query result
Object value = elements.getVal(1);
if (value instanceof ResultContext)
{
ResultContext context = (ResultContext) value;
// The ordered list (actually the page subset)
// of matched documents
DocList ids = context.docs;
if (ids != null)
{
SolrIndexSearcher searcher = request.getSearcher();
DocIterator iterator = ids.iterator();
builder.append("suggestions:[");
// 4. Iterate over documents
for (int i = 0; i < ids.size(); i++)
{
// 5. For each document we need to get the "label" attr
Document document = searcher.doc(iterator.nextDoc(), FIELDS);
if (i > 0) { builder.append(","); }
// 6. Append the label value to writer output
builder
.append("'")
.append(((String) document.get("label")))
.append("'");
}
builder.append("]").append("}");
}
}
// 7. and finally write out the result.
writer.write(builder.toString());
}That's all! Now try issuing a query like this:
http://127.0.0.1:8983/solr/example/auto?q=ma
Solr will return the following response:
{
query:'ma',
suggestions:['Marcus Miller','Michael Manring','Got a match','Nigerian Marketplace','The Crying machine']
}Tip
You can find the source code of the entire example under the org.gazzax.labs.solr.ase.ch3.rw package of the source folder in the project associated with this chapter.
If you want to start Solr with that writer, run the following command from the command line or from Eclipse:
mvn clean install cargo:run –P custom-response-writer