
SolrCloud is a highly available, fault-tolerant cluster of Solr servers that provides distributed indexing and search capabilities. The following diagram illustrates a simple SolrCloud scenario:
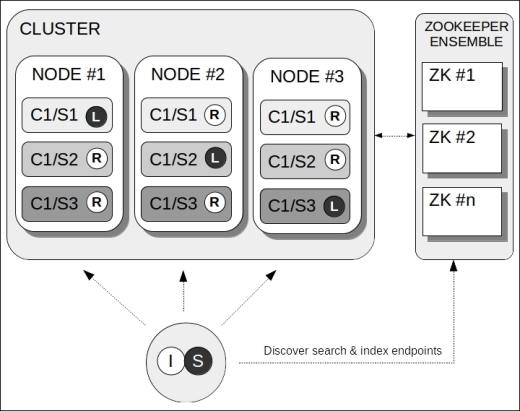
Although SolrCloud introduced a new terminology to define things in a distributed domain, the preceding diagram has been drawn with the same concepts that we saw in the previous scenarios, for better understanding.
Tip
Starting from Solr 4.10.0, the download bundle contains an interactive, wizard-like command-line setup for a sample SolrCloud installation. A step-by-step guide for this is available at https://cwiki.apache.org/confluence/display/solr/Getting+Started+with+SolrCloud.
The following sections will describe the relevant aspects of SolrCloud.
Apache Zookeeper was introduced in SolrCloud for cluster coordination and configuration. This means it is a central actor in this scenario, providing discovery, configuration, and lookup services for other components (including clients) to gather information about the Solr cluster.
Apache Zookeeper, being a central component, can be organized in a cluster itself (as depicted in the previous diagram) in order to avoid a single point of failure. A cluster of Zookeeper nodes is called ensemble.
Tip
For more information about Apache Zookeeper, visit http://zookeeper.apache.org, the project homepage.
In the preceding diagram, we have only one core (C1) with three shards (S1, S2, and S3). Now, the main difference between the previous distributed scenario (where we met shards) and this scenario is that here, there's a copy of each shard in every node. That copy is called a replica. In this example, we have three copies for each shard, but this is just for simplicity; you can have as many copies as you want.
More specifically, SolrCloud has a property called replication factor, that determines the total number of copies in the cluster for each shard. Among the copies, one is elected as the leader (the letter "L" on C1/S1 on the first node) while the remaining are replicas (the letter "R").
This replication feature satisfies three important nonfunctional requirements: load balancing, high availability, and backup. We have already described how the classic replication mechanism provides load balancing. Having the same data within more than one node allows a searcher to issue query requests to those nodes in a round-robin fashion, thus expanding the overall capacity of the system in terms of queries per second. Here, the context is the same; each shard, regardless of whether it is a leader or a replica, can be found on n nodes (where n is the replication factor); therefore, a client can use those nodes for load balancing requests.
High availability is a direct consequence of the redundancy introduced with shard replication. The presence of the same data (and the same search services) on several nodes means that, even if one of those node crashes, a client can continue to send requests to the remaining nodes.
The redundancy introduced with the replication also works as a backup mechanism. Having the same things in several places provides a better guarantee against data loss. After all, this is the underlying principle of the popular cloud data services (for example, Dropbox, ICloud, and Copy).
Each node maintains a write-ahead transaction log, where any change is recorded before being applied to the index. Therefore, the transaction log is available for leaders and replicas, and it will be used to determine which content needs to be part of a chosen replica during synchronization. For instance, when a new replica is created, it refers to its leader and its transaction log to know which content to get.
The transaction log will also be used when restarting a server that didn't shut down gracefully. Its content will be "replayed" in order to synchronize local leaders and replicas.
Tip
Write-ahead logging is widely used in distributed systems. For more information about it, see https://cwiki.apache.org/confluence/display/solr/NRT%2C+Replication%2C+and+Disaster+Recovery+with+SolrCloud.
The transaction log path can be configured in an appropriate section of the solconfig.xml file.
Now that the main features of SolrCloud have been explained, we can stop thinking about it as an evolution of the shard scenario and cover its own terminology:
|
Parameter |
Description |
|---|---|
|
Node |
This is a Java Virtual Machine running Solr. |
|
Cluster |
A set of Solr nodes that form a single unit of service. |
|
Shard |
We previously defined a shard as a vertical subset of the index, that is, a subset of all documents in the index. A shard is a single copy of that subset. In SolrCloud, it can be a leader or a replica. |
|
Partition/slice |
A subset of the whole index replicated on one or more nodes. A slice is basically composed of all shards (leader and replicas) belonging to the same subset. |
|
Leader |
Each shard has one node identified as its leader. This role is crucial for the update workflow. All the updates belonging to a partition route through the leader. |
|
Replica |
The replication factor determines the total number of copies each shard has. Among all of those copies, one is elected as the leader, while the others are called replicas. While querying can be done across all shards, updates are always directed (or forwarded by replicas) to leaders. |
|
Replication factor |
The number of copies of a shard (and hence, of a document) maintained by the cluster. |
|
Collection |
A core that is logically and physically distributed across the cluster. In our example, we have only one collection (C1). |
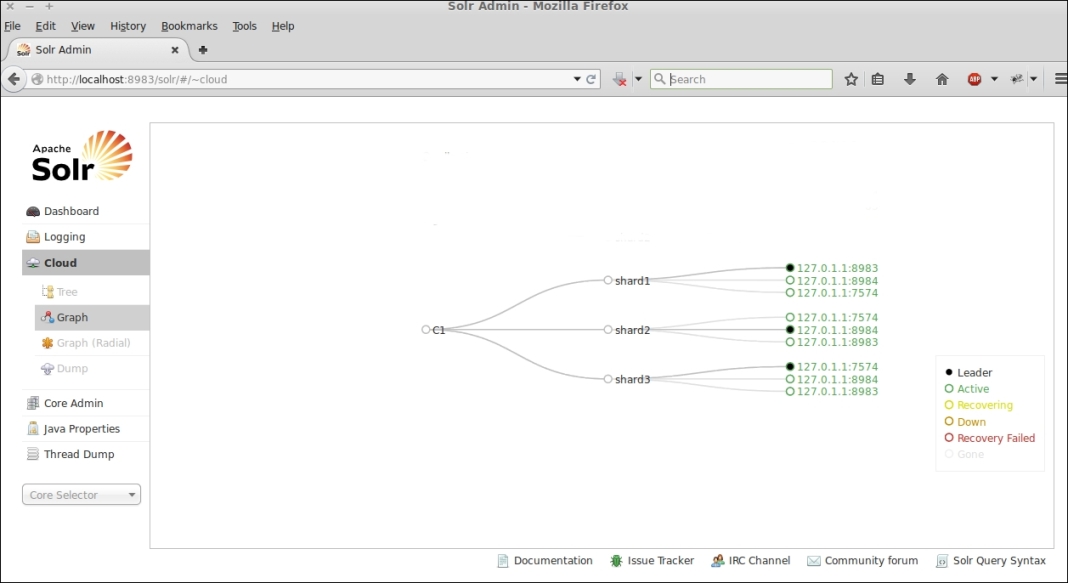
In a SolrCloud deployment, the administration console of each node will report an additional menu item called Cloud, where it's possible to get an overall view of the cluster. You can choose between several graphic representations of the cluster (tree, graph, and radial), but all of them have a common aim—giving an immediate overview of the cluster in terms of nodes, shards, and collections. This is a screenshot from the administration console of the SolrCloud used in this section:
The Collections API is used to manage the cluster, including collections, shards, and metadata about the cluster. This interface is composed of a single HTTP service endpoint located at http://<hostname>:<port>/<context root>/admin/collections.
The Collections API accepts an action parameter, which is a mnemonic code associated with the command that we want to execute. Each command has its own set of parameters that depend on the goal of the command. The following table lists the allowed values for the action parameter (that is, the available commands):
The complete list of parameters for each command is available at https://cwiki.apache.org/confluence/display/solr/Collections+API.
Queries can be sent to any node performing a full distributed search across the cluster with load balancing and failover. SolrCloud also allows partial queries, that is, queries executed against a group of shards, a list of servers, or a list of collections.
A drawback of the first distributed scenario we met (that is, shards) was that a client that wants to issue an update request needs to explicitly point to the target shard. This is no longer valid in a SolrCloud context because, for a given shard, there could be more than one copy (that is, a leader and zero or more copies). So the update path becomes the following:
- Updates can be sent to any node in the cluster
- If the target node is the leader of the shard owning the document, the update is executed there, and then it is forwarded to all replicas
- If the target node is a replica, then the update request is forwarded to its leader, and the flow described in the previous point applies