
Streams are one of the most important components and patterns of Node.js. There is a motto in the community that says "stream all the things!" and this alone should be enough to describe the role of streams in Node.js. Dominic Tarr, a top contributor to the Node.js community, defines streams as node's best and most misunderstood idea. There are different reasons that make Node.js streams so attractive; again, it's not just related to technical properties, such as performance or efficiency, but it's more about their elegance and the way they fit perfectly into the Node.js philosophy.
In this chapter, you will learn about the following topics:
- Why streams are so important in Node.js
- Using and creating streams
- Streams as a programming paradigm: leveraging their power in many different contexts and not just for I/O
- Piping patterns and connecting streams together in different configurations
In an event-based platform such as Node.js, the most efficient way to handle I/O is in real time, consuming the input as soon as it is available and sending the output as soon as it is produced by the application.
In this section, we are going to give an initial introduction to Node.js streams and their strengths. Please bear in mind that this is only an overview, as a more detailed analysis on how to use and compose streams will follow later in the chapter.
Almost all the asynchronous APIs that we've seen so far in the book work using buffer mode. For an input operation, buffer mode causes all the data coming from a resource to be collected into a buffer; it is then passed to a callback as soon as the entire resource is read. The following diagram shows a visual example of this paradigm:
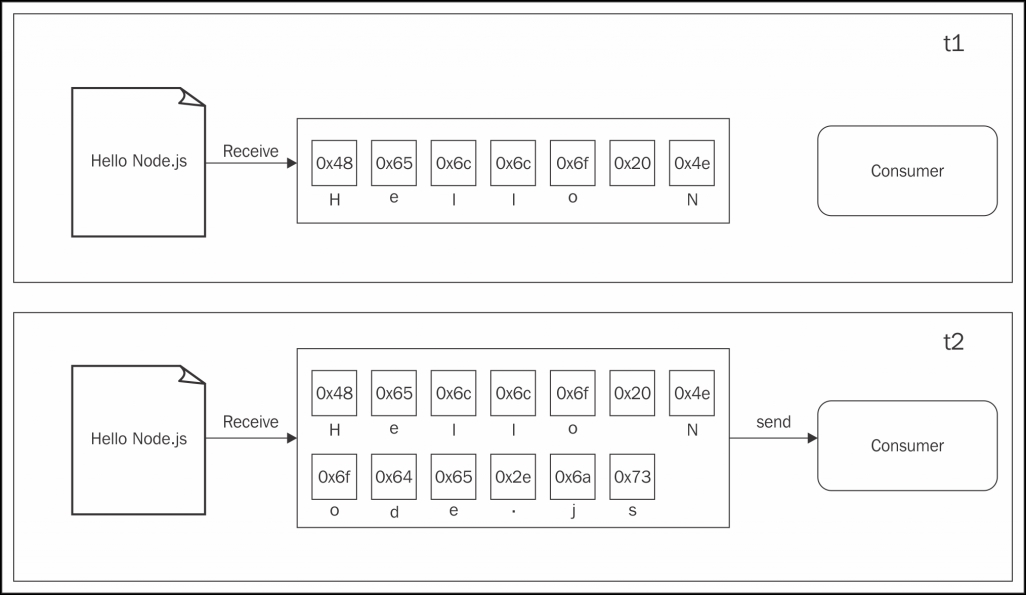
In the preceding figure, we can see that, at the time t1, some data is received from the resource and saved into the buffer. At the time t2, another data chunk is received—the final one—that completes the read operation and causes the entire buffer to be sent to the consumer.
On the other side, streams allow you to process the data as soon as it arrives from the resource. This is shown in the following diagram:

This time, the diagram shows you how each new chunk of data is received from the resource and is immediately provided to the consumer, who now has the chance to process it straight away without waiting for all the data to be collected in the buffer.
But what are the differences between the two approaches? We can summarize them in two major categories:
- Spatial efficiency
- Time efficiency
However, Node.js streams have another important advantage: composability. Let's now see what impact these properties have in the way we design and write our applications.
First of all, streams allow us to do things that would not be possible, by buffering data and processing it all at once. For example, consider the case in which we have to read a very big file, let's say, in the order of hundreds of megabytes or even gigabytes. Clearly, using an API that returns a big buffer when the file is completely read is not a good idea. Imagine reading a few of these big files concurrently; our application will easily run out of memory. Besides that, buffers in V8 cannot be bigger than 0x3FFFFFFF bytes (a little bit less than 1GB). So, we might hit a wall way before running out of physical memory.
To make a concrete example, let's consider a simple command-line interface (CLI) application that compresses a file using the Gzip format. Using a buffered API, such an application will look like the following in Node.js (error handling is omitted for brevity):
const fs = require('fs');
const zlib = require('zlib');
const file = process.argv[2];
fs.readFile(file, (err, buffer) => {
zlib.gzip(buffer, (err, buffer) => {
fs.writeFile(file + '.gz', buffer, err => {
console.log('File successfully compressed');
});
});
});
Now, we can try to put the preceding code in a file named gzip.js and then run it with the following command:
node gzip <path to file>
If we choose a file that is big enough, let's say a little bit bigger than 1GB, we will receive a nice error message saying that the file that we are trying to read is bigger than the maximum allowed buffer size, such as the following:
RangeError: File size is greater than possible Buffer: 0x3FFFFFFF bytes
That's exactly what we expected, and it's a symptom of using the wrong approach.
The simplest way we have to fix our Gzip application and make it work with big files is to use a streaming API. Let's see how this can be achieved; let's replace the contents of the module we just created with the following code:
const fs = require('fs');
const zlib = require('zlib');
const file = process.argv[2];
fs.createReadStream(file)
.pipe(zlib.createGzip())
.pipe(fs.createWriteStream(file + '.gz'))
.on('finish', () => console.log('File successfully compressed'));
"Is that it?" you may ask. Yes; as we said, streams are amazing also because of their interface and composability, thus allowing clean, elegant, and concise code. We will see this in a while in more detail, but for now the important thing to realize is that the program will run smoothly against files of any size, ideally with constant memory utilization. Try it yourself (but consider that compressing a big file might take a while).
Let's now consider the case of an application that compresses a file and uploads it to a remote HTTP server, which in turn decompresses it and saves it on the filesystem. If our client was implemented using a buffered API, the upload would start only when the entire file has been read and compressed. On the other hand, the decompression will start on the server only when all the data has been received. A better solution to achieve the same result involves the use of streams. On the client machine, streams allows you to compress and send the data chunks as soon as they are read from the filesystem, whereas on the server, it allows you to decompress every chunk as soon as it is received from the remote peer. Let's demonstrate this by building the application that we mentioned earlier, starting from the server side.
Let's create a module named gzipReceive.js containing the following code:
const http = require('http');
const fs = require('fs');
const zlib = require('zlib');
const server = http.createServer((req, res) => {
const filename = req.headers.filename;
console.log('File request received: ' + filename);
req
.pipe(zlib.createGunzip())
.pipe(fs.createWriteStream(filename))
.on('finish', () => {
res.writeHead(201, {'Content-Type': 'text/plain'});
res.end('That's it
');
console.log(`File saved: ${filename}`);
});
});
server.listen(3000, () => console.log('Listening'));
The server receives the data chunks from the network, decompresses them, and saves them as soon as they are received, thanks to Node.js streams.
The client side of our application will go into a module named gzipSend.js, and it looks like the following:
const fs = require('fs');
const zlib = require('zlib');
const http = require('http');
const path = require('path');
const file = process.argv[2];
const server = process.argv[3];
const options = {
hostname: server,
port: 3000,
path: '/',
method: 'PUT',
headers: {
filename: path.basename(file),
'Content-Type': 'application/octet-stream',
'Content-Encoding': 'gzip'
}
};
const req = http.request(options, res => {
console.log('Server response: ' + res.statusCode);
});
fs.createReadStream(file)
.pipe(zlib.createGzip())
.pipe(req)
.on('finish', () => {
console.log('File successfully sent');
});
In the preceding code, we are again using streams to read the data from the file, and then compressing and sending each chunk as soon as it is read from the filesystem.
Now, to try out the application, let's first start the server using the following command:
node gzipReceive
Then, we can launch the client by specifying the file to send and the address of the server (for example, localhost):
node gzipSend <path to file> localhost
If we choose a file big enough, we will see more easily how the data flows from the client to the server, but why exactly is this paradigm, where we have flowing data, more efficient compared to using a buffered API? The following diagram should give us a hint:

When a file is processed it goes through a set of sequential stages:
- [Client] Read from the filesystem.
- [Client] Compress the data.
- [Client] Send it to the server.
- [Server] Receive from the client.
- [Server] Decompress the data.
- [Server] Write the data to disk.
To complete the processing, we have to go through each stage like in an assembly line, in sequence, until the end. In the preceding figure, we can see that, using a buffered API, the process is entirely sequential. To compress the data, we first have to wait for the entire file to be read, then, to send the data, we have to wait for the entire file to be both read and compressed, and so on. When instead we are using streams, the assembly line is kicked off as soon as we receive the first chunk of data, without waiting for the entire file to be read. But more amazingly, when the next chunk of data is available, there is no need to wait for the previous set of tasks to be completed; instead, another assembly line is launched in parallel. This works perfectly because each task that we execute is asynchronous, so it can be parallelized by Node.js; the only constraint is that the order in which the chunks arrive in each stage must be preserved (and Node.js streams take care of this for us).
As we can see from the previous figure, the result of using streams is that the entire process takes less time, because we waste no time waiting for all the data to be read and processed all at once.
The code we have seen so far has already given us an overview of how streams can be composed thanks to the pipe() method, which allows us to connect the different processing units, each being responsible for one single functionality in perfect Node.js style. This is possible because streams have a uniform interface, and they can understand each other in terms of API. The only prerequisite is that the next stream in the pipeline has to support the data type produced by the previous stream, which can be either binary, text, or even objects, as we will see later in the chapter.
To take a look at another demonstration of the power of this property, we can try to add an encryption layer to the gzipReceive/gzipSend application that we built previously.
To do this, we only need to update the client by adding another stream to the pipeline; to be precise, the stream returned by crypto.createChipher(). The resulting code should be as follows:
const crypto = require('crypto');
// ...
fs.createReadStream(file)
.pipe(zlib.createGzip())
.pipe(crypto.createCipher('aes192', 'a_shared_secret'))
.pipe(req)
.on('finish', () => console.log('File succesfully sent'));
In a similar way, we can update the server so that the data is decrypted before being decompressed:
const crypto = require('crypto');
// ...
const server = http.createServer((req, res) => {
// ...
req
.pipe(crypto.createDecipher('aes192', 'a_shared_secret'))
.pipe(zlib.createGunzip())
.pipe(fs.createWriteStream(filename))
.on('finish', () => { /* ... */ });
});
With very little effort (just a few lines of code), we added an encryption layer to our application; we simply had to reuse an already available transform stream by including it in the pipeline that we already had. In a similar way, we can add and combine other streams, as if we were playing with Lego bricks.
Clearly, the main advantage of this approach is reusability, but as we can see from the code we presented so far, streams also enable cleaner and more modular code. For these reasons, streams are often used not just to deal with pure I/O, but also as a means to simplify and modularize the code.