
In its early days, Node.js was mainly a non-blocking web server; its original name was in fact web.js. Its creator, Ryan Dahl, soon realized the potential of the platform and started extending it with tools to enable the creation of any type of server-side application on top of the duo JavaScript/non-blocking paradigm. The characteristics of Node.js were perfect for the implementation of distributed systems, made of nodes orchestrating their operations through the network. Node.js was born to be distributed. Unlike other web platforms, the word scalability enters the vocabulary of a Node.js developer very early in the life of an application, mainly because of its single-threaded nature, incapable of exploiting all the resources of a machine, but often there are more profound reasons. As we will see in this chapter, scaling an application does not only mean increasing its capacity, enabling it to handle more requests faster; it's also a crucial path to achieving high availability and tolerance to errors. Amazingly, it can also be a way to split the complexity of an application into more manageable pieces. Scalability is a concept with multiple faces, six to be precise, as many as the faces of a cube—the scale cube.
In this chapter, we will learn the following topics:
- What the scale cube is
- How to scale by running multiple instances of the same application
- How to leverage a load balancer when scaling an application
- What a service registry is and how it can be used
- How to design a microservice architecture out of a monolithic application
- How to integrate a large number of services through the use of some simple architectural patterns
Before we dive into some practical patterns and examples, it is worth saying a few words about the reasons for scaling an application and how it can be achieved.
We already know that most of the tasks of a typical Node.js application run in the context of a single thread. In Chapter 1, Welcome to the Node.js Platform , we learned that this is not really a limitation but rather an advantage, because it allows the application to optimize the usage of the resources necessary to handle concurrent requests, thanks to the non-blocking I/O paradigm. A single thread fully exploited by non-blocking I/O works wonderfully for applications handling a moderate number of requests per second, usually a few hundred per second (this greatly depends on the application). Assuming we are using commodity hardware, the capacity that a single thread can support is limited no matter how powerful a server can be, therefore, if we want to use Node.js for high-load applications, the only way is to scale it across multiple processes and machines.
However, workload is not the only reason to scale a Node.js application; in fact, with the same techniques, we can obtain other desirable properties such as availability and tolerance to failures. Scalability is also a concept applicable to the size and the complexity of an application; in fact, building architectures that can grow big is another important factor when designing software. JavaScript is a tool to be used with caution, the lack of type checking and its many gotchas can be an obstacle to the growth of an application, but with discipline and an accurate design, we can turn this into an advantage. With JavaScript, we are often pushed to keep the application simple and split it into manageable pieces, making it easier to scale and distribute.
When talking about scalability, the first fundamental principle to understand is load distribution, the science of splitting the load of an application across several processes and machines. There are many ways to achieve this, and the book The Art of Scalability by Martin L. Abbott and Michael T. Fisher proposes an ingenious model to represent them, called the scale cube. This model describes scalability in terms of the following three dimensions:
- x-axis: Cloning
- y-axis: Decomposing by service/functionality
- z-axis: Splitting by data partition
These three dimensions can be represented as a cube, as shown in the following figure:
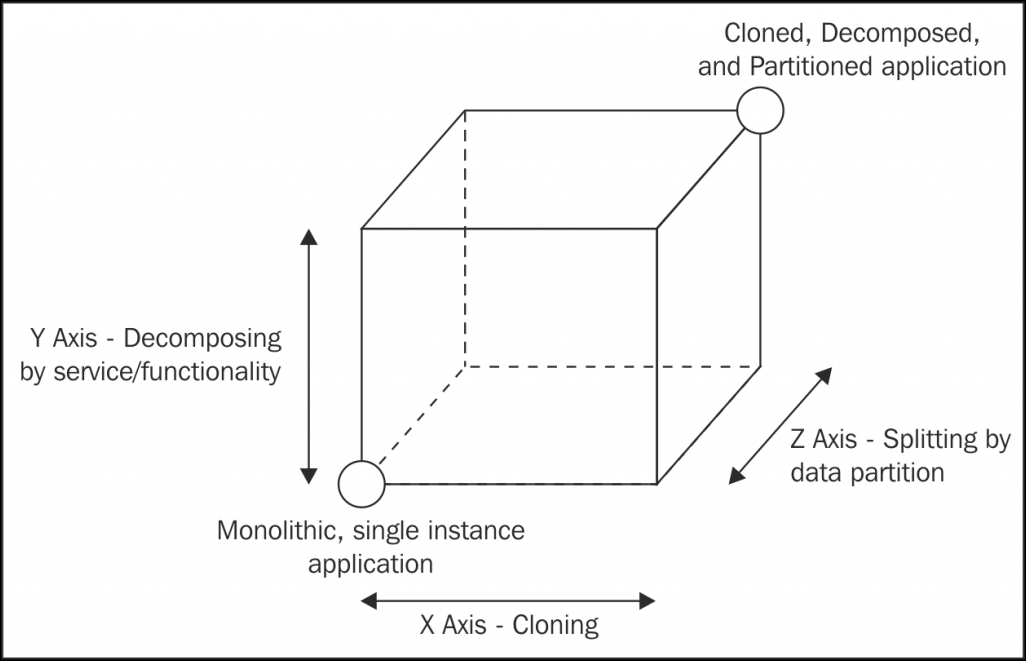
The bottom-left corner of the cube represents the applications having all their functionalities and services in a single codebase (monolithic applications) and running on a single instance. This is a common situation for applications handling small workloads or at the early stages of development.
The most intuitive evolution of a monolithic, unscaled application is moving right along the x- axis, which is simple, most of the time inexpensive (in terms of development cost), and highly effective. The principle behind this technique is elementary, that is, cloning the same application n times and letting each instance handle 1/nth of the workload.
Scaling along the y-axis means decomposing the application based on its functionalities, services, or use cases. In this instance, decomposing means creating different, standalone applications, each with its own codebase, sometimes with its own dedicated database, or even with a separate UI. For example, a common situation is separating the part of an application responsible for the administration from the public-facing product. Another example is extracting the services responsible for user authentication, creating a dedicated authentication server. The criteria to split an application by its functionalities depend mostly on its business requirements, the use cases, the data, and many other factors, as we will see later in this chapter. Interestingly, this is the scaling dimension with the biggest repercussions, not only on the architecture of an application, but also on the way it is managed from a development perspective. As we will see, microservice is a term that at the moment is most commonly associated with a fine-grained y-axis scaling.
The last scaling dimension is the z-axis, where the application is split in such a way that each instance is responsible for only a portion of the whole data. This is a technique mainly used in databases and also takes the name of horizontal partitioning or sharding. In this setup, there are multiple instances of the same application, each of them operating on a partition of the data, which is determined using different criteria. For example, we could partition the users of an application based on their country (list partitioning), or based on the starting letter of their surname (range partitioning), or by letting a hash function decide the partition each user belongs to (hash partitioning). Each partition can then be assigned to a particular instance of our application. The use of data partitions requires each operation to be preceded by a lookup step to determine which instance of the application is responsible for a given datum. As we said, data partitioning is usually applied and handled at the database level because its main purpose is overcoming the problems related to handling large monolithic datasets (limited disk space, memory, and network capacity). Applying it at the application level is worth considering only for complex, distributed architectures or for very particular use cases as, for example, when building applications relying on custom solutions for data persistence, when using databases not supporting partitioning, or when building applications at Google scale. Considering its complexity, scaling an application along the z-axis should be taken into consideration only after the x-and y-axes of the scale cube have been fully exploited.
In the next sections, we will focus on the two most common and effective techniques to scale Node.js applications, namely, cloning and decomposing by functionality/service.