
Let's start our discussion of multi-threading in Python with the example of a program used to generate thumbnails of image URLs.
In the example, we are using Pillow, a fork of the Python Imaging Library (PIL) to perform this operation:
# thumbnail_converter.py
from PIL import Image
import urllib.request
def thumbnail_image(url, size=(64, 64), format='.png'):
""" Save thumbnail of an image URL """
im = Image.open(urllib.request.urlopen(url))
# filename is last part of the URL minus extension + '.format'
pieces = url.split('/')
filename = ''.join((pieces[-2],'_',pieces[-1].split('.')[0],'_thumb',format))
im.thumbnail(size, Image.ANTIALIAS)
im.save(filename)
print('Saved',filename)The preceding code works very well for single URLs.
Let's say we want to convert five image URLs to their thumbnails:
img_urls = ['https://dummyimage.com/256x256/000/fff.jpg', 'https://dummyimage.com/320x240/fff/00.jpg', 'https://dummyimage.com/640x480/ccc/aaa.jpg', 'https://dummyimage.com/128x128/ddd/eee.jpg', 'https://dummyimage.com/720x720/111/222.jpg'] for url in img_urls: thumbnail_image(urls)
Let's see how such a function performs with respect to time taken in the following screenshot:
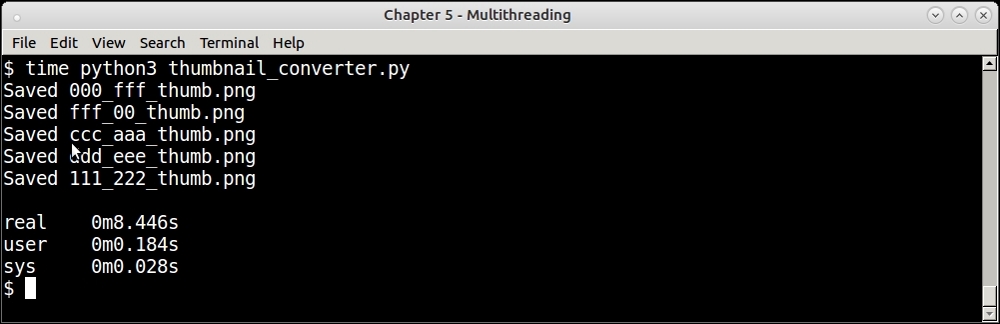
Response time of serial thumbnail converter for 5 URLs
The function took approximately 1.7 seconds per URL.
Let's now scale the program to multiple threads so we can perform the conversions concurrently. Here is the rewritten code to run each conversion in its own thread:
import threading
for url in img_urls:
t=threading.Thread(target=thumbnail_image,args=(url,))
t.start()The timing that this last program now gives is shown in this screenshot:
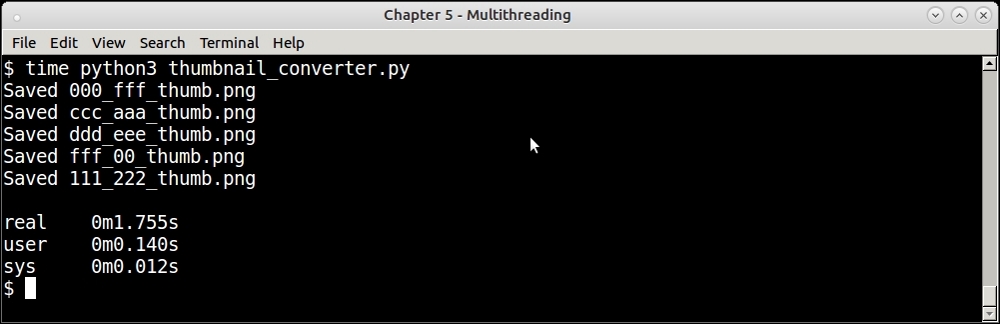
Response time of threaded thumbnail converter for 5 URLs
With this change, the program returns in 1.76 seconds, almost equal to the time taken by a single URL in serial execution before. In other words, the program has now linearly scaled with respect to the number of threads. Note that, we had to make no change to the function itself to get this scalability boost.
In the previous example, we saw a set of image URLs being processed by a thumbnail generator function concurrently by using multiple threads. With the use of multiple threads, we were able to achieve near linear scalability as compared to serial execution.
However, in real life, rather than processing a fixed list of URLs, it is more common for the URL data to be produced by some kind of URL producer. It could be fetching this data from a database, a comma separated value (CSV) file or from a TCP socket for example.
In such a scenario, creating one thread per URL would be a tremendous waste of resources. It takes a certain overhead to create a thread in the system. We need some way to reuse the threads we create.
For such systems that involve a certain set of threads producing data and another set of threads consuming or processing data, the producer/consumer model is an ideal fit. Such a system has the following features:
- Producers are a specialized class of workers (threads) producing the data. They may receive the data from a specific source(s), or generate the data themselves.
- Producers add the data to a shared synchronized queue. In Python, this queue is provided by the
Queueclass in the aptly namedqueuemodule. - Another set of specialized class of workers, namely consumers, wait on the queue to get (consume) the data. Once they get the data, they process it and produce the results.
- The program comes to an end when the producers stop generating data and the consumers are starved of data. Techniques like timeouts, polling, or poison pills can be used to achieve this. When this happens, all threads exit, and the program completes.
We have rewritten our thumbnail generator to a producer consumer architecture. The resulting code is given next. Since this is a bit detailed, we will discuss each class one by one.
First, let's look at the imports—these are pretty self-explanatory:
# thumbnail_pc.py import threading import time import string import random import urllib.request from PIL import Image from queue import Queue
Next is the code for the producer class:
class ThumbnailURL_Generator(threading.Thread):
""" Worker class that generates image URLs """
def __init__(self, queue, sleep_time=1,):
self.sleep_time = sleep_time
self.queue = queue
# A flag for stopping
self.flag = True
# choice of sizes
self._sizes = (240,320,360,480,600,720)
# URL scheme
self.url_template = 'https://dummyimage.com/%s/%s/%s.jpg'
threading.Thread.__init__(self, name='producer')
def __str__(self):
return 'Producer'
def get_size(self):
return '%dx%d' % (random.choice(self._sizes),
random.choice(self._sizes))
def get_color(self):
return ''.join(random.sample(string.hexdigits[:-6], 3))
def run(self):
""" Main thread function """
while self.flag:
# generate image URLs of random sizes and fg/bg colors
url = self.url_template % (self.get_size(),
self.get_color(),
self.get_color())
# Add to queue
print(self,'Put',url)
self.queue.put(url)
time.sleep(self.sleep_time)
def stop(self):
""" Stop the thread """
self.flag = FalseLet's analyze the producer class code:
- The class is named
ThumbnailURL_Generator. It generates the URLs (by using the service of a website named http://dummyimage.com) of different sizes, foreground, and background colors. It inherits from thethreading.Threadclass. - It has a
runmethod, which goes in a loop, generates a random image URL, and pushes it to the shared queue. Every time, the thread sleeps for a fixed time, as configured by thesleep_timeparameter. - The class exposes a
stopmethod, which sets the internal flag toFalsecausing the loop to break and the thread to finish its processing. This can be called externally by another thread, typically, the main thread.
Now we have the URL consumer class that consumes the thumbnail URLs and creates the thumbnails:
class ThumbnailURL_Consumer(threading.Thread):
""" Worker class that consumes URLs and generates thumbnails """
def __init__(self, queue):
self.queue = queue
self.flag = True
threading.Thread.__init__(self, name='consumer')
def __str__(self):
return 'Consumer'
def thumbnail_image(self, url, size=(64,64), format='.png'):
""" Save image thumbnails, given a URL """
im=Image.open(urllib.request.urlopen(url))
# filename is last part of URL minus extension + '.format'
filename = url.split('/')[-1].split('.')[0] + '_thumb' + format
im.thumbnail(size, Image.ANTIALIAS)
im.save(filename)
print(self,'Saved',filename)
def run(self):
""" Main thread function """
while self.flag:
url = self.queue.get()
print(self,'Got',url)
self.thumbnail_image(url)
def stop(self):
""" Stop the thread """
self.flag = False Here's the analysis of the consumer class:
- The class is named
ThumbnailURL_Consumer, as it consumes URLs from the queue, and creates thumbnail images of them. - The
runmethod of this class goes in a loop, gets a URL from the queue, and converts it to a thumbnail by passing it to thethumbnail_imagemethod. (Note that this code is exactly the same as that of thethumbnail_imagefunction we created earlier.) - The
stopmethod is very similar, checking for a stop flag every time in the loop, and ending once the flag has been unset.
Here is the main part of the code—setting up a couple of producers and consumers each, and running them:
q = Queue(maxsize=200)
producers, consumers = [], []
for i in range(2):
t = ThumbnailURL_Generator(q)
producers.append(t)
t.start()
for i in range(2):
t = ThumbnailURL_Consumer(q)
consumers.append(t)
t.start()Here is a screenshot of the program in action:
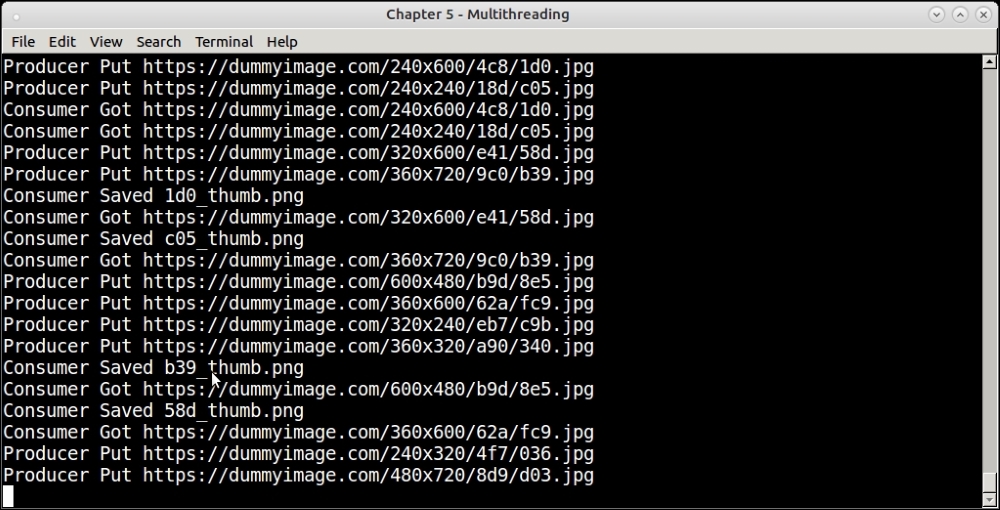
Running the thumbnail producer/consumer program with 4 threads, 2 of each type
In the above program, since the producers keep generating random data without any end, the consumers will keep consuming it without any end. Our program has no proper end condition.
Hence, this program will keep running until the network requests are denied or timed out or the disk space of the machine runs out because of thumbnails.
However, a program solving a real world problem should end in some way that is predictable.
This could be due to a number of external constraints
- It could be a timeout introduced where the consumers wait for data for a certain maximum time, and then exit if no data is available during that time. This, for example, can be configured as a timeout in the
getmethod of the queue. - Another technique would be to signal program end after a certain number of resources are consumed or created. In this program, for example, it could be a fixed limit to the number of thumbnails created.
In the following section, we will see how to enforce such resource limits by using threading synchronization primitives such as Locks and Semaphores.
Note
You may have observed that we start a thread using its start method, though the overridden method in the Thread subclass is run. This is because, in the parent Thread class, the start method sets up some state, and then calls the run method internally. This is the right way to call the thread's run method. It should never be called directly.
In this section, we will see how to modify the program using a Lock, a synchronization primitive to implement a counter that will limit the number of images created as a way to end the program.
Lock objects in Python allows exclusive access by threads to a shared resource.
The pseudo-code would be as follows:
try: lock.acquire() # Do some modification on a shared, mutable resource mutable_object.modify() finally: lock.release()
However, Lock objects support context-managers via the with statement, so this is more commonly written as follows:
with lock: mutable_object.modify()
To implement a fixed number of images per run, our code needs to be supported to add a counter. However, since multiple threads would check and increment this counter, it needs to be synchronized via a Lock object.
This is our first implementation of the resource counter class using Locks.
class ThumbnailImageSaver(object):
""" Class which saves URLs to thumbnail images and keeps a counter """
def __init__(self, limit=10):
self.limit = limit
self.lock = threading.Lock()
self.counter = {}
def thumbnail_image(self, url, size=(64,64), format='.png'):
""" Save image thumbnails, given a URL """
im=Image.open(urllib.request.urlopen(url))
# filename is last two parts of URL minus extension + '.format'
pieces = url.split('/')
filename = ''.join((pieces[-2],'_',pieces[-1].split('.')[0],'_thumb',format))
im.thumbnail(size, Image.ANTIALIAS)
im.save(filename)
print('Saved',filename)
self.counter[filename] = 1
return True
def save(self, url):
""" Save a URL as thumbnail """
with self.lock:
if len(self.counter)>=self.limit:
return False
self.thumbnail_image(url)
print('Count=>',len(self.counter))
return TrueSince this modifies the consumer class as well, it makes sense to discuss both changes together. Here is the modified consumer class to accommodate the extra counter needed to keep track of the images:
class ThumbnailURL_Consumer(threading.Thread):
""" Worker class that consumes URLs and generates thumbnails """
def __init__(self, queue, saver):
self.queue = queue
self.flag = True
self.saver = saver
# Internal id
self._id = uuid.uuid4().hex
threading.Thread.__init__(self, name='Consumer-'+ self._id)
def __str__(self):
return 'Consumer-' + self._id
def run(self):
""" Main thread function """
while self.flag:
url = self.queue.get()
print(self,'Got',url)
if not self.saver.save(url):
# Limit reached, break out
print(self, 'Set limit reached, quitting')
break
def stop(self):
""" Stop the thread """
self.flag = FalseLet's analyze both of these classes. First, we'll look at the new class, ThumbnailImageSaver:
- This class derives from the
object. In other words, it is not aThread. It is not meant to be one. - It initializes a lock object and a counter dictionary in its initializer method. The lock is for synchronizing access to the counter by threads. It also accepts a
limitparameter equal to the number of images it should save. - The
thumbnail_imagemethod moves to here from the consumer class. It is called from asavemethod, which encloses the call in a synchronized context using the lock. - The
savemethod first checks if the count has crossed the configured limit; when this happens, the method returnsFalse. Otherwise, the image is saved with a call tothumbnail_image, and the image filename is added to the counter, effectively incrementing the count.
Next, we'll consider the modified ThumbnailURL_Consumer class:
- The class's initializer is modified to accept an instance of the
ThumbnailImageSaveras asaverargument. The rest of the arguments remain the same. - The
thumbnail_imagemethod no longer exists in this class, as it is moved to the new class. - The
runmethod is much simplified. It makes a call to thesavemethod of the saver instance. If it returnsFalse, it means the limit has been reached, the loop breaks, and the consumer thread exits. - We have also modified the
__str__method to return a unique ID per thread, which is set in the initializer using theuuidmodule. This helps to debug threads in a real-life example.
The calling code also changes a bit, as it needs to set up the new object, and configure the consumer threads with it:
q = Queue(maxsize=2000)
# Create an instance of the saver object
saver = ThumbnailImageSaver(limit=100)
producers, consumers = [], []
for i in range(3):
t = ThumbnailURL_Generator(q)
producers.append(t)
t.start()
for i in range(5):
t = ThumbnailURL_Consumer(q, saver)
consumers.append(t)
t.start()
for t in consumers:
t.join()
print('Joined', t, flush=True)
# To make sure producers don't block on a full queue
while not q.empty():
item=q.get()
for t in producers:
t.stop()
print('Stopped',t, flush=True)
print('Total number of PNG images',len(glob.glob('*.png')))The following are the main points to be noted here:
- We create an instance of the new
ThumbnailImageSaverclass, and pass it on to the consumer threads when creating them. - We wait on consumers first. Note that, the main thread doesn't call
stop, butjoinon them. This is because the consumers exit automatically when the limit is reached, so the main thread should just wait for them to stop. - We stop the producers after the consumers exit—explicitly so—since they would otherwise keep working forever, since there is no condition for the producers to exit.
We use a dictionary instead of an integer as because of the nature of the data.
Since the images are randomly generated, there is a minor chance of one image URL being the same as another one created previously, causing the filenames to clash. Using a dictionary takes care of such possible duplicates.
The following screenshot shows a run of the program with a limit of 100 images. Note that we can only show the last few lines of the console log, since it produces a lot of output:
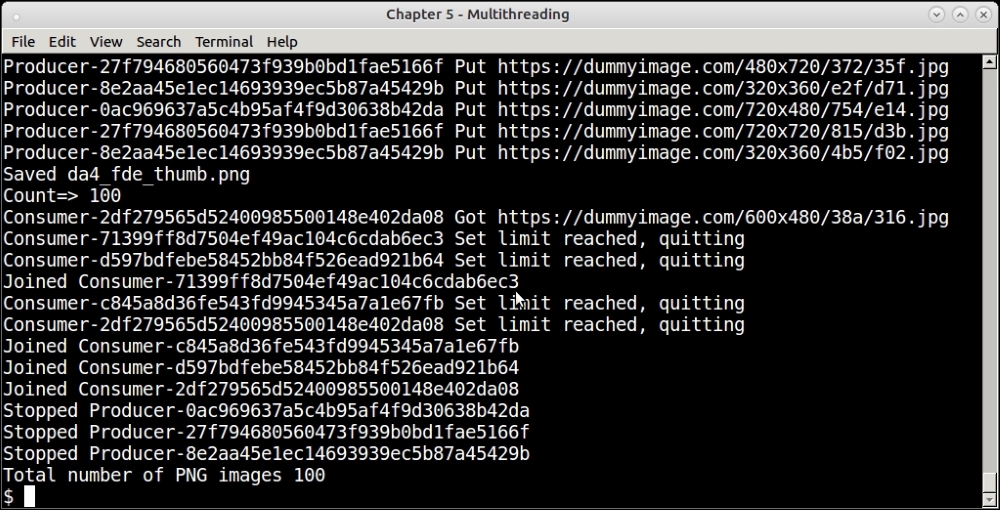
Run of the thumbnail generator program with a limit of 100 images using a Lock
You can configure this program with any limit of the images, and it will always fetch exactly the same count—nothing more or less.
In the next section, we will familiarize ourselves with another synchronization primitive, namely semaphore, and learn how to implement a resource limiting class in a similar way using the semaphore.
Locks aren't the only way to implement synchronization constraints and write logic on top of them in order to limit resources used/generated by a system.
A semaphore, one of the oldest synchronization primitives in computer science, is ideally suited for such use cases.
A semaphore is initialized with a value greater than zero:
- When a thread calls
acquireon a semaphore that has a positive internal value, the value gets decremented by one, and the thread continues on its way. - When another thread calls
releaseon the semaphore, the value is incremented by 1. - Any thread calling
acquireonce the value has reached zero is blocked on the semaphore until it is woken up by another thread callingrelease.
Due to this behavior, a semaphore is perfectly suited for implementing a fixed limit on shared resources.
In the following code example, we will implement another class for resource limiting our thumbnail generator program, this time using a semaphore:
class ThumbnailImageSemaSaver(object):
""" Class which keeps an exact counter of saved images
and restricts the total count using a semaphore """
def __init__(self, limit = 10):
self.limit = limit
self.counter = threading.BoundedSemaphore(value=limit)
self.count = 0
def acquire(self):
# Acquire counter, if limit is exhausted, it
# returns False
return self.counter.acquire(blocking=False)
def release(self):
# Release counter, incrementing count
return self.counter.release()
def thumbnail_image(self, url, size=(64,64), format='.png'):
""" Save image thumbnails, given a URL """
im=Image.open(urllib.request.urlopen(url))
# filename is last two parts of URL minus extension + '.format'
pieces = url.split('/')
filename = ''.join((pieces[-2],'_',pieces[-1].split('.')[0],format))
try:
im.thumbnail(size, Image.ANTIALIAS)
im.save(filename)
print('Saved',filename)
self.count += 1
except Exception as e:
print('Error saving URL',url,e)
# Image can't be counted, increment semaphore
self.release()
return True
def save(self, url):
""" Save a URL as thumbnail """
if self.acquire():
self.thumbnail_image(url)
return True
else:
print('Semaphore limit reached, returning False')
return FalseSince the new semaphore-based class keeps the exact same interface as the previous lock-based class—with a save method—there is no need to change any code on the consumer!
Only the calling code needs to be changed.
This line in the previous code initialized the ThumbnailImageSaver instance:
saver = ThumbnailImageSaver(limit=100)
The preceding line needs to be replaced with the following one:
saver = ThumbnailImageSemaSaver(limit=100)
The rest of the code remains exactly the same.
Let's quickly discuss the new class using the semaphore before seeing this code in action:
- The
acquireandreleasemethods are simple wrappers over the same methods on the semaphore. - We initialize the semaphore with a value equal to the image limit in the initializer.
- In the save method, we call the
acquiremethod. If the semaphore's limit is reached, it will returnFalse. Otherwise, the thread saves the image and returnsTrue. In the former case, the calling thread quits.
This class behaves in a way similar way to the previous one, and limits resources exactly. The following is an example with a limit of 200 images:

Run of the thumbnail generator program with a limit of 200 images using a Semaphore
We saw two competing versions of implementing a fixed resource constraint in the previous two examples—one using Lock and another using Semaphore.
The differences between the two versions are as follows:
- The version using Lock protects all the code that modifies the resource—in this case, checking the counter, saving the thumbnail, and incrementing the counter—to make sure that there are no data inconsistencies.
- The Semaphore version is implemented more like a gate—a door that is open while the count is below the limit, and through which any number of threads can pass, and that only closes when the limit is reached. In other words, it doesn't mutually exclude threads from calling the thumbnail saving function.
Hence, the effect is that the semaphore version would be faster than the version using Lock.
How much faster? The following timing example for a run of 100 images gives an idea.
This screenshot shows the time it takes for the Lock version to save 100 images:
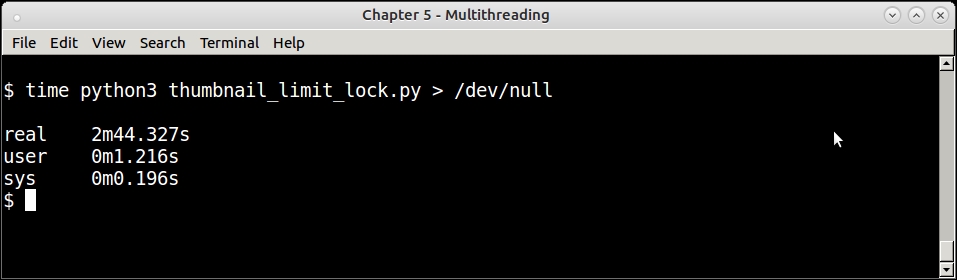
Timing the run of the thumbnail generator program—the Lock version—for 100 images
The following screenshot shows the time for the semaphore version to save a similar number:
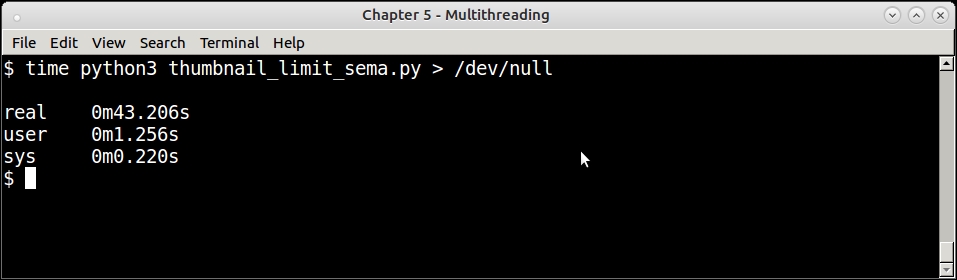
Timing the run of the thumbnail generator program—the semaphore version—for 100 images
By a quick calculation you can see that the semaphore version is about 4 times faster than the lock version for the same logic. In other words, it scales 4 times better.
In this section, we will briefly see the application of another important synchronization primitive in threading, namely the Condition object.
First, we will get a real life example of using a Condition object. We will implement a throttler for our thumbnail generator to manage the rate of URL generation.
In the producer/consumer systems in real life, the following three kinds of scenario can occur with respect to the rate of data production and consumption:
- Producers produce data at a faster pace than consumers can consume. This causes the consumers to always play catch up with the producers. Excess data by the producers can accumulate in the queue, which causes the queue to consume a higher memory and CPU usage in every loop causing the program to slow down.
- Consumers consume data at a faster rate than producers. This causes the consumers to always wait on the queue—for data. This, in itself, is not a problem as long as the producers don't lag too much. In the worst case, this leads to half of the system, that is, the consumers, remaining idle, while the other half—the producers—try to keep up with the demand.
- Both producers and consumers work at nearly the same pace keeping the queue size within limits. This is the ideal scenario.
There are many ways to solve this problem. Some of them are as follows:
- Queue with a fixed size: Producers would be forced to wait until data is consumed by a consumer once the queue size limit is reached. However this would almost always keep the queue full.
- Provide the workers with timeouts plus other responsibilities: Rather than remain blocked on the queue, producers and/or consumers can use a timeout to wait on the queue. When they time out they can either sleep or perform some other responsibilities before coming back and waiting on the queue.
- Dynamically configure the number of workers: This is an approach where the worker pool size automatically increases or decreases upon demand. If one class of workers is ahead, the system will launch just the required number of workers of the opposite class to keep the balance.
- Adjust the data generation rate: In this approach, we statically or dynamically adjust the data generation rate by the producers. For example, the system can be configured to produce data at a fixed rate, say, 50 URLs in a minute or it can calculate the rate of consumption by the consumers, and adjust the data production rate of the producers dynamically to keep things in balance.
In the following example, we will implement the last approach—to limit the production rate of URLs to a fixed limit using Condition objects.
A Condition object is a sophisticated synchronization primitive that comes with an implicit built-in lock. It can wait on an arbitrary condition till it becomes true. The moment the thread calls wait on the condition, the internal lock is released, but the thread itself becomes blocked:
cond = threading.Condition()
# In thread #1
with cond:
while not some_condition_is_satisfied():
# this thread is now blocked
cond.wait()Now, another thread can wake up this preceding thread by setting the condition to True, and then calling notify or notify_all on the condition object. At this point, the preceding blocked thread is woken up, and continues on its way:
# In thread #2
with cond:
# Condition is satisfied
if some_condition_is_satisfied():
# Notify all threads waiting on the condition
cond.notify_all()Here is our new class namely ThumbnailURLController which implements the rate control of URL production using a condition object.
class ThumbnailURLController(threading.Thread):
""" A rate limiting controller thread for URLs using conditions """
def __init__(self, rate_limit=0, nthreads=0):
# Configured rate limit
self.rate_limit = rate_limit
# Number of producer threads
self.nthreads = nthreads
self.count = 0
self.start_t = time.time()
self.flag = True
self.cond = threading.Condition()
threading.Thread.__init__(self)
def increment(self):
# Increment count of URLs
self.count += 1
def calc_rate(self):
rate = 60.0*self.count/(time.time() - self.start_t)
return rate
def run(self):
while self.flag:
rate = self.calc_rate()
if rate<=self.rate_limit:
with self.cond:
# print('Notifying all...')
self.cond.notify_all()
def stop(self):
self.flag = False
def throttle(self, thread):
""" Throttle threads to manage rate """
# Current total rate
rate = self.calc_rate()
print('Current Rate',rate)
# If rate > limit, add more sleep time to thread
diff = abs(rate - self.rate_limit)
sleep_diff = diff/(self.nthreads*60.0)
if rate>self.rate_limit:
# Adjust threads sleep_time
thread.sleep_time += sleep_diff
# Hold this thread till rate settles down with a 5% error
with self.cond:
print('Controller, rate is high, sleep more by',rate,sleep_diff)
while self.calc_rate() > self.rate_limit:
self.cond.wait()
elif rate<self.rate_limit:
print('Controller, rate is low, sleep less by',rate,sleep_diff)
# Decrease sleep time
sleep_time = thread.sleep_time
sleep_time -= sleep_diff
# If this goes off < zero, make it zero
thread.sleep_time = max(0, sleep_time)Let's discuss the preceding code before we discuss the changes in the producer class that will make use of this class:
- The class is an instance of
Thread, so it runs in its own thread of execution. It also holds aConditionobject. - It has a
calc_ratemethod, which calculates the rate of generation of URLs by keeping a counter and using timestamps. - In the
runmethod, the rate is checked. If it's below the configured limit, the condition object notifies all threads waiting on it. - Most importantly, it implements a
throttlemethod. This method uses the current rate, calculated viacalc_rate, and uses it to throttle and adjust the sleep times of the producers. It mainly does these two things:- If the rate is more than the configured limit, it causes the calling thread to wait on the condition object until the rate levels off. It also calculates an extra sleep time that the thread should sleep in its loop to adjust the rate to the required level.
- If the rate is less than the configured limit, then the thread needs to work faster and produce more data, so it calculates the sleep difference and lowers the sleep limit accordingly.
Here is the code of the producer class to incorporate the changes:
class ThumbnailURL_Generator(threading.Thread):
""" Worker class that generates image URLs and supports throttling via an external controller """
def __init__(self, queue, controller=None, sleep_time=1):
self.sleep_time = sleep_time
self.queue = queue
# A flag for stopping
self.flag = True
# sizes
self._sizes = (240,320,360,480,600,720)
# URL scheme
self.url_template = 'https://dummyimage.com/%s/%s/%s.jpg'
# Rate controller
self.controller = controller
# Internal id
self._id = uuid.uuid4().hex
threading.Thread.__init__(self, name='Producer-'+ self._id)
def __str__(self):
return 'Producer-'+self._id
def get_size(self):
return '%dx%d' % (random.choice(self._sizes),
random.choice(self._sizes))
def get_color(self):
return ''.join(random.sample(string.hexdigits[:-6], 3))
def run(self):
""" Main thread function """
while self.flag:
# generate image URLs of random sizes and fg/bg colors
url = self.url_template % (self.get_size(),
self.get_color(),
self.get_color())
# Add to queue
print(self,'Put',url)
self.queue.put(url)
self.controller.increment()
# Throttle after putting a few images
if self.controller.count>5:
self.controller.throttle(self)
time.sleep(self.sleep_time)
def stop(self):
""" Stop the thread """
self.flag = FalseLet's see how the preceding code works:
- The class now accepts an additional controller object in its initializer. This is the instance of the controller class given earlier.
- After putting a URL, it increments the count on the controller. Once the count reaches a minimum limit (set as 5 to avoid early throttling of the producers), it calls
throttleon the controller, passing itself as the argument.
The calling code also needs quite a few changes. The modified code is shown as follows:
q = Queue(maxsize=2000)
# The controller needs to be configured with exact number of
# producers
controller = ThumbnailURLController(rate_limit=50, nthreads=3)
saver = ThumbnailImageSemaSaver(limit=200)
controller.start()
producers, consumers = [], []
for i in range(3):
t = ThumbnailURL_Generator(q, controller)
producers.append(t)
t.start()
for i in range(5):
t = ThumbnailURL_Consumer(q, saver)
consumers.append(t)
t.start()
for t in consumers:
t.join()
print('Joined', t, flush=True)
# To make sure producers dont block on a full queue
while not q.empty():
item=q.get()
controller.stop()
for t in producers:
t.stop()
print('Stopped',t, flush=True)
print('Total number of PNG images',len(glob.glob('*.png')))The main changes here are the ones listed next:
- The controller object is created with the exact number of producers that will be created. This helps the correct calculation of sleep time per thread.
- The producer threads, themselves, are passed the instance of the controller in their initializer.
- The controller is started as a thread before all other threads.
Here is a run of the program configured with 200 images at the rate of 50 images per minute. We show two images of the running program's output, one at the beginning of the program and one towards the end.

Starting the thumbnail program with URL rate controller—at 50 URLs per minute
You will find that, when the program starts, it almost immediately slows down, and nearly comes to a halt, since the original rate is high. What happens here is that the producers call on the throttle method, and since the rate is high, they all get blocked on the condition object.
After a few seconds, the rate comes down to the prescribed limit, since no URLs are generated. This is detected by the controller in its loop, and it calls notify_all on the threads, waking them up.
After a while you will see that the rate is getting settled around the set limit of 50 URLs per minute.
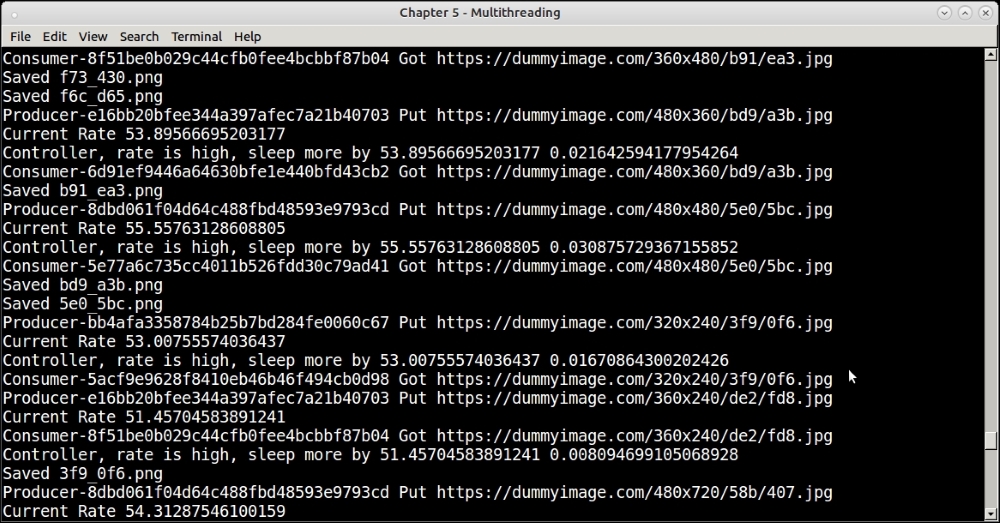
The thumbnail program with URL rate controller 5-6 seconds after start
Towards the end of the program, you will see that the rate has almost settled to the exact limit:

The thumbnail program with URL rate controller towards the end
We are coming towards the end of our discussion on threading primitives and how to use them in improving the concurrency of your programs and in implementing shared resource constraints and controls.
Before we conclude, we will look at an aspect of Python threads which prevents multi-threaded programs from making full use of the CPU in Python—namely the GIL or Global Interpreter Lock.