
Python is a very readable language with simple syntax, and typically, one clearly stated way to do things. It comes with a set of well-tested and compact standard library modules. All of this seems to indicate that Python should be a very secure language.
But is it so?
Let's look at a few examples in Python, and try to analyze the security aspect of Python and its standard libraries.
For the purposes of usefulness, we will demonstrate the code examples shown in this section using both Python 2.x and Python 3.x versions. This is because a number of security vulnerabilities that are present in Python 2.x versions are fixed in the recent 3.x versions. However, since many Python developers are still using some form or the other of Python 2.x, the code examples would be useful to them, and also illustrate the importance of migrating to Python 3.x.
All examples are executed on a machine running the Linux (Ubuntu 16.0), x86_64 architecture:
$ python3 Python 3.5.2 (default, Jul 5 2016, 12:43:10) [GCC 5.4.0 20160609] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import sys >>> print (sys.version) 3.5.2 (default, Jul 5 2016, 12:43:10) [GCC 5.4.0 20160609]
$ python2 Python 2.7.12 (default, Jul 1 2016, 15:12:24) [GCC 5.4.0 20160609] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> import sys >>> print sys.version 2.7.12 (default, Jul 1 2016, 15:12:24) [GCC 5.4.0 20160609]
Note
Python 3.x version used for these examples are Python 3.5.2, and the Python 2.x version used is Python 2.7.12. All examples are executed on a machine running the Linux (Ubuntu 16.0), 64 bit x86 architecture.
Most of the examples will use one version of code, which will run both in Python 2.x and Python 3.x. In cases where this is not possible, two versions of the code will be listed.
Let's look at this program that is a simple guessing game. It reads a number from the standard input, and compares it with a random number. If it matches, the user wins, otherwise, the user has to try again:
# guessing.py
import random
# Some global password information which is hard-coded
passwords={"joe": "world123",
"jane": "hello123"}
def game():
"""A guessing game """
# Use 'input' to read the standard input
value=input("Please enter your guess (between 1 and 10): ")
print("Entered value is",value)
if value == random.randrange(1, 10):
print("You won!")
else:
print("Try again")
if __name__ == "__main__":
game()The preceding code is simple, except that it has some sensitive global data, which is the passwords of some users in the system. In a realistic example, these could be populated by some other functions, which read the passwords and cache them in memory.
Let's try the program with some standard inputs. We will initially run it with Python 2.7, as follows:
$ python2 guessing.py Please enter your guess (between 1 and 10): 6 ('Entered value is', 6) Try again $ python2 guessing.py Please enter your guess (between 1 and 10): 8 ('Entered value is', 8) You won!
Now, let's try a "non-standard" input:
$ python2 guessing.py
Please enter your guess (between 1 and 10): passwords
('Entered value is', {'jane': 'hello123', 'joe': 'world123'})
Try againNote how the preceding run exposed the global password data!
The problem is that in Python 2, the input value is evaluated as an expression without doing any check, and when it is printed, the expression prints its value. In this case, it happens to match a global variable, so its value is printed out.
Now let's look at this one:
$ python2 guessing.py Please enter your guess (between 1 and 10): globals() ('Entered value is', {'passwords': {'jane': 'hello123', 'joe' : 'world123'}, '__builtins__': <module '__builtin__' (built-in)>, '__file__': 'guessing.py', 'random': <module 'random' from '/usr/lib/python2.7/random.pyc'>, '__package__': None, 'game': <function game at 0x7f6ef9c65d70>, '__name__': '__main__', '__doc__': None}) Try again
Now, not only has it exposed the passwords, it has exposed the complete global variables in the code including the passwords. Even if there were no sensitive data in the program, a hacker using this approach can reveal valuable information about the program such as variable names, function names, packages used, and so on.
What is the fix for this? For Python 2, one solution is to replace input, which evaluates its contents by passing directly to eval, with raw_input, which doesn't evaluate the contents. Since raw_input doesn't return a number, it needs to be converted to the target type. (This can be done by casting the return data to an int.) The following code does not only that, but also adds an exception handler for the type conversion for extra safety:
# guessing_fix.py
import random
passwords={"joe": "world123",
"jane": "hello123"}
def game():
value=raw_input("Please enter your guess (between 1 and 10): ")
try:
value=int(value)
except TypeError:
print ('Wrong type entered, try again',value)
return
print("Entered value is",value)
if value == random.randrange(1, 10):
print("You won!")
else:
print("Try again")
if __name__ == "__main__":
game()Let's see how this version fixes the security hole in evaluating inputs
$ python2 guessing_fix.py Please enter your guess (between 1 and 10): 9 ('Entered value is', 9) Try again $ python2 guessing_fix.py Please enter your guess (between1 and 10): 2 ('Entered value is', 2) You won! $ python2 guessing_fix.py Please enter your guess (between 1 and 10): passwords (Wrong type entered, try again =>, passwords) $ python2 guessing_fix.py Please enter your guess (between 1 and 10): globals() (Wrong type entered, try again =>, globals())
The new program is now much more secure than the first version.
This problem is not there in Python 3.x as the following illustration shows. (We are using the original version to run this.)
$ python3 guessing.py Please enter your guess (between 1 and 10): passwords Entered value is passwords Try again $ python3 guessing.py Please enter your guess (between 1 and 10): globals() Entered value is globals() Try again
The eval function in Python is very powerful, but it is also dangerous, since it allows one to pass arbitrary strings to it, which can evaluate to potentially dangerous code or commands.
Let's look at this rather silly piece of code as a test program to see what eval can do:
# test_eval.py
import sys
import os
def run_code(string):
""" Evaluate the passed string as code """
try:
eval(string, {})
except Exception as e:
print(repr(e))
if __name__ == "__main__":
run_code(sys.argv[1])Let's assume a scenario where an attacker is trying to exploit this piece of code to find out the contents of the directory where the application is running. (For the time being, you can assume the attacker can run this code via a web application, but hasn't got direct access to the machine itself.)
Let's assume the attacker tries to list the contents of the current folder:
$ python2 test_eval.py "os.system('ls -a')" NameError("name 'os' is not defined",)
This preceding attack doesn't work, because eval takes a second argument, which provides the global values to use during evaluation. Since, in our code, we are passing this second argument as an empty dictionary, we get the error, as Python is unable to resolve the os name.
So does this mean, eval is safe? No it's not. Let's see why.
What happens when we pass the following input to the code?
$ python2 test_eval.py "__import__('os').system('ls -a')" . guessing_fix.py test_eval.py test_input.py .. guessing.py test_format.py test_io.py
We can see that we are still able to coax eval to do our bidding by using the built-in function __import__.
The reason why this works is because names such as __import__ are available in the default built-in __builtins__ global. We can deny eval this by specifically passing this as an empty dictionary via the second argument. Here is the modified version:
# test_eval.py
import sys
import os
def run_code(string):
""" Evaluate the passed string as code """
try:
# Pass __builtins__ dictionary as empty
eval(string, {'__builtins__':{}})
except Exception as e:
print(repr(e))
if __name__ == "__main__":
run_code(sys.argv[1])Now the attacker is not able to exploit via the built-in __import__:
$ python2 test_eval.py "__import__('os').system('ls -a')"
NameError("name '__import__' is not defined",)However, this doesn't still make eval any safer, as it is open to slightly longer, but clever attacks. Here is one such attack:
$ python2 test_eval.py "(lambda f=(lambda x: [c for c in [].__class__.__bases__[0].__subclasses__() if c.__name__ == x][0]): f('function')(f('code')(0,0,0,0,'BOOM',(), (),(),'','',0,''),{})())()"
Segmentation fault (core dumped)We are able to core dump the Python interpreter with a rather obscure looking piece of malicious code. How did this happen ?
Here is a somewhat detailed explanation of the steps.
First, let's consider this:
>>> [].__class__.__bases__[0] <type 'object'>
This is nothing but the base-class object. Since we don't have access to the built-ins, this is an indirect way to get access to it.
Next, the following line of code loads all the sub-classes of object currently loaded in the Python interpreter:
>>> [c for c in [].__class__.__bases__[0].__subclasses__()]
Among them, what we want is the code object type. This can be accessed by checking the name of the item via the __name__ attribute:
>>> [c for c in [].__class__.__bases__[0].__subclasses__() if c.__name__ == 'code']
Here is the same achieved by using an anonymous lambda function:
>>> (lambda x: [c for c in [].__class__.__bases__[0].__subclasses__() if c.__name__ == x])('code')
[<type 'code'>]Next, we want to execute this code object. However, code objects cannot be called directly. They need to be tied to a function in order for them to be called. This is achieved by wrapping the preceding lambda function in an outer lambda function:
>>> (lambda f: (lambda x: [c for c in [].__class__.__bases__[0].__subclasses__() if c.__name__ == x])('code'))
<function <lambda> at 0x7f8b16a89668Now our inner lambda function can be called in two steps:
>>> (lambda f=(lambda x: [c for c in [].__class__.__bases__[0].__subclasses__() if c.__name__ == x][0]): f('function')(f('code')))
<function <lambda> at 0x7fd35e0db7d0>We finally invoke the code object via this outer lambda function by passing mostly default arguments. The code-string is passed as the string BOOM, which is, of course, a bogus code-string that causes the Python interpreter to segfault, producing a core-dump:
>>> (lambda f=(lambda x:
[c for c in [].__class__.__bases__[0].__subclasses__() if c.__name__ == x][0]):
f('function')(f('code')(0,0,0,0,'BOOM',(), (),(),'','',0,''),{})())()
Segmentation fault (core dumped)This shows that eval in any context, even bereft of built-in module support, is unsafe, and can be exploited by a clever and malicious hacker to crash the Python interpreter, and thereby, possibly gain control over the system.
Note that the same exploit works in Python 3 as well, but we need some modification in the arguments to the code object, as in Python 3, code objects takes an extra argument. Also, the code-string and some arguments must be the byte type.
The following is the exploit running on Python 3. The end result is the same:
$ python3 test_eval.py "(lambda f=(lambda x: [c for c in ().__class__.__bases__[0].__subclasses__() if c.__name__ == x][0]): f('function')(f('code')(0,0,0,0,0,b'tx00x00jx01x00dx01x00x83x01x00x01dx00x00S',(), (),(),'','',0,b''),{})())()" Segmentation fault (core dumped)
In Python 2, the
xrange() function produces an overflow error if the range cannot fit into the integer range of Python:
>>> print xrange(2**63)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
OverflowError: Python int too large to convert to C longThe range() function also overflows with a slightly different error:
>>> print range(2**63)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
OverflowError: range() result has too many itemsThe problem is that xrange() and range() use plain integer objects (type <int>) instead of automatically getting converted to the long type, which is limited only by the system memory.
However, this problem is fixed in the Python 3.x versions, as types int and long are unified into one (int type), and the range() objects manage the memory internally. Also, there is no longer a separate xrange() object:
>>> range(2**63) range(0, 9223372036854775808)
Here is another example of integer overflow errors in Python, this time for the len function.
In the following examples, we try the len function on instances of two classes A and B, whose magic method __len__ has been over-ridden to provide support for the len function. Note that A is a new-style class, inheriting from object and B is an old-style class:
# len_overflow.py
class A(object):
def __len__(self):
return 100 ** 100
class B:
def __len__(self):
return 100 ** 100
try:
len(A())
print("OK: 'class A(object)' with 'return 100 ** 100' - len calculated")
except Exception as e:
print("Not OK: 'class A(object)' with 'return 100 ** 100' - len raise Error: " + repr(e))
try:
len(B())
print("OK: 'class B' with 'return 100 ** 100' - len calculated")
except Exception as e:
print("Not OK: 'class B' with 'return 100 ** 100' - len raise Error: " + repr(e))Here is the output of the code when executed with Python2:
$ python2 len_overflow.py Not OK: 'class A(object)' with 'return 100 ** 100' - len raise Error: OverflowError('long int too large to convert to int',) Not OK: 'class B' with 'return 100 ** 100' - len raise Error: TypeError('__len__() should return an int',)
The same code is executed in Python 3 as follows:
$ python3 len_overflow.py Not OK: 'class A(object)' with 'return 100 ** 100' - len raise Error: OverflowError("cannot fit 'int' into an index-sized integer",) Not OK: 'class B' with 'return 100 ** 100' - len raise Error: OverflowError("cannot fit 'int' into an index-sized integer",)
The problem in the preceding code is that len returns integer objects, and in this case, the actual value is too large to fit inside an int, so Python raises an overflow error. In Python 2, however, for the case when the class is not derived from object, the code executed is slightly different, which anticipates an int object, but gets long and throws a TypeError instead. In Python 3, both examples return overflow errors.
Is there a security issue with integer overflow errors such as this?
On the ground, it depends on the application code and the dependent module code used, and how they are able to deal with or mask the overflow errors.
However, since Python is written in C, any overflow errors which are not correctly handled in the underlying C code can lead to buffer overflow exceptions, where an attacker can write to the overflow buffer and hijack the underlying process, thereby gaining control over the application.
Typically, if a module or data structure is able to handle the overflow error and raise exceptions preventing further code execution, the chances of code exploitation are reduced.
It is very common for Python developers to use the pickle module and its C implementation cousin cPickle for serializing objects in Python. However, both these modules allow unchecked execution of code, as they don't enforce any kind of type check or rules on the objects being serialized to verify whether it is a benign Python object or a potential command that can exploit the system.
Here is an illustration via a shell exploit, which lists the contents of the root folder (/) in a Linux/POSIX system:
# test_serialize.py
import os
import pickle
class ShellExploit(object):
""" A shell exploit class """
def __reduce__(self):
# this will list contents of root / folder.
return (os.system, ('ls -al /',)
def serialize():
shellcode = pickle.dumps(ShellExploit())
return shellcode
def deserialize(exploit_code):
pickle.loads(exploit_code)
if __name__ == '__main__':
shellcode = serialize()
deserialize(shellcode)The previous code simply packages a ShellExploit class, which, upon pickling, returns the command for listing the contents of the root filesystem / by way of the os.system() method. The Exploit class thus masquerades malicious code into a pickle object, which, upon unpickling, executes the code, and exposes the contents of the root folder of the machine to the attacker. The output of the preceding code is shown here:
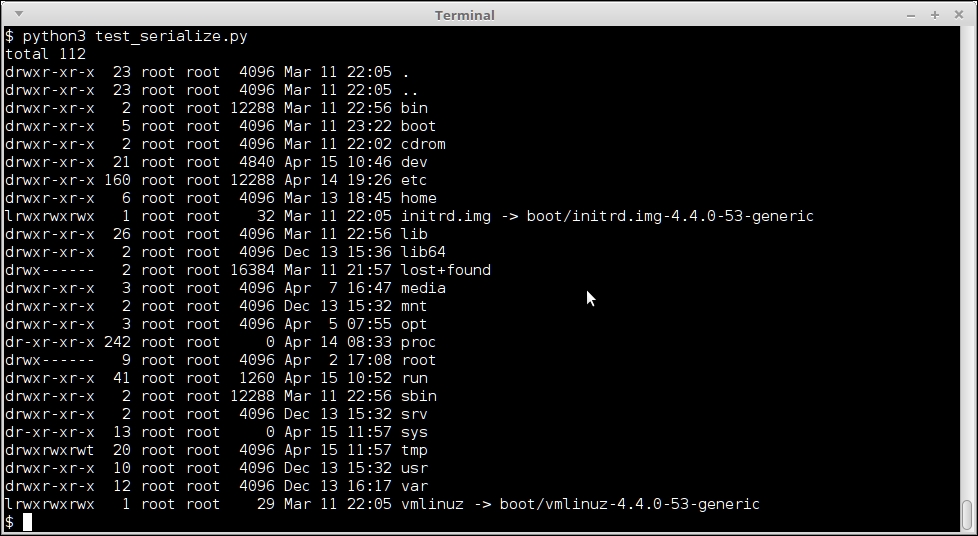
Output of the shell exploit code for serializing using pickle, exposing contents of / folder.
As you can see, the output clearly lists the contents of the root folder.
What is the work-around to prevent such exploits?
First of all, don't use an unsafe module like pickle for serialization in your applications. Instead, rely on a safer alternative like json or yaml. If your application really is dependent on using the pickle module for some reason, then use sand-boxing software or code jails to create safe environments that prevent execution of malicious code on the system.
For example, here is a slight modification of the earlier code, now with a simple chroot jail, which prevents code execution on the actual root folder. It uses a local safe_root/ subfolder as the new root via a context-manager hook. Note that this is a simple minded example. An actual jail would be much more elaborate than this:
# test_serialize_safe.py
import os
import pickle
from contextlib import contextmanager
class ShellExploit(object):
def __reduce__(self):
# this will list contents of root / folder.
return (os.system, ('ls -al /',))
@contextmanager
def system_jail():
""" A simple chroot jail """
os.chroot('safe_root/')
yield
os.chroot('/')
def serialize():
with system_jail():
shellcode = pickle.dumps(ShellExploit())
return shellcode
def deserialize(exploit_code):
with system_jail():
pickle.loads(exploit_code)
if __name__ == '__main__':
shellcode = serialize()
deserialize(shellcode)With this jail in place, the code executes as follows:

Output of the shell exploit code for serializing using pickle, with a simple chroot jail.
No output is produced now, because this is a fake jail, and Python cannot find the ls command in the new root. Of course, in order to make this work in a production system, a proper jail should be set up, which allows programs to execute, but at the same time, prevents or limits malicious program execution.
How about other serialization formats like JSON ? Can such exploits work with them? Let's see using an example.
Here is the same serialization code written using the json module:
# test_serialize_json.py
import os
import json
import datetime
class ExploitEncoder(json.JSONEncoder):
def default(self, obj):
if any(isinstance(obj, x) for x in (datetime.datetime, datetime.date)):
return str(obj)
# this will list contents of root / folder.
return (os.system, ('ls -al /',))
def serialize():
shellcode = json.dumps([range(10),
datetime.datetime.now()],
cls=ExploitEncoder)
print(shellcode)
return shellcode
def deserialize(exploit_code):
print(json.loads(exploit_code))
if __name__ == '__main__':
shellcode = serialize()
deserialize(shellcode)Note how the default JSON encoder has been overridden using a custom encoder named ExploitEncoder. However, as the JSON format doesn't support such serializations, it returns the correct serialization of the list passed as input:
$ python2 test_serialize_json.py [[0, 1, 2, 3, 4, 5, 6, 7, 8, 9], "2017-04-15 12:27:09.549154"] [[0, 1, 2, 3, 4, 5, 6, 7, 8, 9], u'2017-04-15 12:27:09.549154']
With Python3, the exploit fails as Python3 raises an exception.
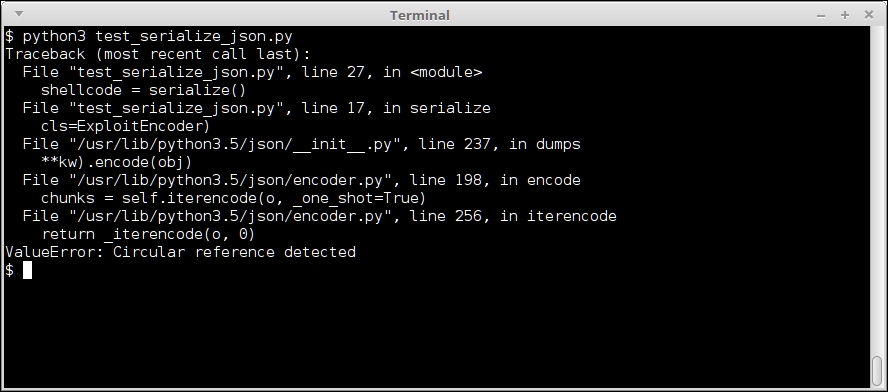
Output of the shell exploit code for serializing using json, with Python3