
The previous Chapter 16, Parallelism with Scala and Akka, provided the reader with different options to make computing-intensive applications scalable. These solutions are generic and do not address the specific needs of the data scientist. Optimization algorithms such as minimization of loss function or dynamic programming methods such as the Viterbi algorithm require support for caching data and broadcasting of model parameters. The Apache Spark framework addresses these shortcomings.
This chapter describes the key concepts behind the Apache Spark framework and its application to large scale machine learning problems. The reader is invited to dig into the wealth of books and papers on this topic. This last chapter describes four key characteristics of the Apache Spark framework:
- MLlib functionality as illustrated with the K-means algorithm
- Reusable ML pipelines, introduced in Spark 2.0
- Extensibility of existing Spark functionality using Kullback-Leibler divergence as an example
- Spark streaming library
Apache Spark is a fast and general-purpose cluster computing system, initially developed as AMPLab / UC Berkeley as part of the Berkeley Data Analytics Stack (BDAS), http://en.wikipedia.org/wiki/UC_Berkeley. It provides high-level APIs for the following programming languages that make large, concurrent parallel jobs easy to write and deploy [17:01]:
The core element of Spark is the resilient distributed dataset (RDD), which is a collection of elements partitioned across the nodes of a cluster and/or CPU cores of servers. An RDD can be created from a local data structure such as a list, array, or hash table, from the local filesystem or the Hadoop distributed file system (HDFS) [17:02].
The operations on an RDD in Spark are very similar to the Scala higher-order methods. These operations are performed concurrently over each partition. Operations on RDD can be classified as follows:
- Transformation: This operation converts, manipulates, and filters the elements of an RDD on each partition
- Action: This operation aggregates, collects, or reduces the elements of the RDD from all partitions
An RDD can persist, be serialized, and be cached for future computation. Spark is written in Scala and built on top of Akka libraries. Spark relies on the following mechanisms to distribute and partition RDDs:
- Hadoop/HDFS for the distributed and replicated filesystem
- Mesos or Yarn for management of cluster and shared pool of data nodes
The Spark ecosystem can be represented as stacks of technology and frameworks, as seen in the following diagram:
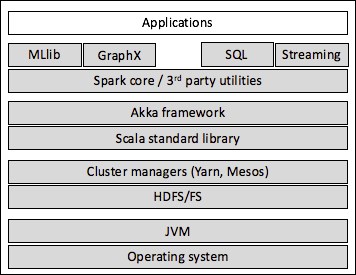
Apache Spark framework ecosystem
The Spark ecosystem has grown to support some machine learning algorithms out of the box, MLlib; a SQL-like interface to manipulate datasets with relational operators, SparkSQL; a library for distributed graphs, GraphX; and a streaming library [17:12].