
CHAPTER 9: SECURITY AND INFRASTRUCTURE AS A SERVICE
In this chapter, I describe how the security services defined within the SRM, shown in Figure 7, can be delivered by those implementing an application upon an IaaS Cloud.
There are many IaaS providers offering a variety of different types of service. A non-exhaustive list of the different types of IaaS currently available is provided below:
•Compute as a Service
•Storage as a Service
•Backup and Recovery/Disaster Recovery as a Service
•Virtual Desktop Infrastructure (VDI) as a Service
•Container Management as a Service
And here is a partial list of public Cloud providers offering IaaS services:
•Amazon (https://aws.amazon.com/)
•Azure (https://azure.microsoft.com/en-gb/)
•Google (https://cloud.google.com/)
•Digital Ocean (www.digitalocean.com/)
•UKCloud (https://ukcloud.com/)
Many traditional systems integrators also offer Cloud services; some, such as IBM, offer their own Cloud technology for use as a public Cloud, whilst others, such as Capgemini, focus more on the integration of the public Cloud services offered by dedicated Cloud service providers. Many traditional enterprise vendors are also adopting their software to make it Cloud native; a good example of this approach is VMware which has worked with AWS to offer the ‘VMware Cloud on AWS’99 service – this allows their customers to operate across both on-premises and AWS using their familiar VMware tooling.
Cloudian (https://cloudian.com/solutions/cloud-storage/storage-as-a-service/) is a good example of an IaaS provider offering a specific infrastructure service; it offers SaaS that enables enterprises, and others, to store their data in the Cloud.
In many ways the task of securing IaaS services is extremely similar to that of securing traditional on-premises services. The prime differences being that the services are hosted by the CSP and that the underlying networks, compute and storage resources are most likely shared with other consumers to a greater degree than seen in traditional outsourcing models.
IaaS and the SRM
The rest of this chapter is dedicated to explaining how the services described within the SRM can be delivered when deploying services on an IaaS Cloud. Please remember that the SRM refers to the security services associated with an application to be hosted on a Cloud service; bear this in mind when you consider the scope of the services discussed next.
Secure development
Within the SRM, the secure development services remain the primary responsibility of the consumer as shown in Figure 8. After all, the CSP is only providing an infrastructure for the consumer to build upon.
One of the major drivers for organisations adopting Cloud services is the need to enable wider digital transformation: typically a move towards more agile development processes and aligning with DevOps ways of working. This book uses the term DevSecOps to refer to the inclusion of security considerations within the DevOps process, but other authors may prefer the term SecDevOps. The traditional security approach – providing a set of requirements at the beginning of an application development lifecycle and then coming back immediately before go-live to conduct a full penetration test – simply does not scale in the digital, Mode 2, environment. It is plainly impractical to conduct a full penetration test of every application release if your DevOps teams are pushing multiple releases per day. Similarly, security should not be viewed as a blocker, acting as a chokepoint at various points during the development lifecycle, e.g. architecture review, design review, code review, secure build review, operations review, penetration test, et cetera. Few organisations have the quantity or quality of security resources to be able to fulfil all of these requirements in a reasonable time frame. DevSecOps is one approach to address those issues.
DevSecOps is all about embedding security controls as close to the start of the development lifecycle as possible, which is often referred to as ‘shifting left’ because we move security controls towards the start of a project timeline. For example, if security teams are able to embed code analysis tools earlier in the process, this can reduce the risk associated with not being able to conduct a full penetration test at go-live time, whilst it also takes pressure off the developers by giving them more time to fix identified issues. Nobody wants to be the developer receiving a vulnerability report from the penetration testers brought in on the day the application was due to go live. Similarly, if the security team is able to pre-approve deployment environments and build templates (e.g. CloudFormation, Terraform or Azure Resource Manager templates and EC2 images, et cetera.), then they can leave the developer teams to get on with their project without needing to get in the way. Security teams can move towards a strategy of ‘trust, but verify’ and focus more on strategic security issues and incident resolution rather than spending time on tactical issues relating to project-specific builds.
The major IaaS Cloud providers are aware of this need to support secure ways of working and the deployment of ‘secure by default’ environments. AWS, for example, has the concepts of the Control Tower100 and the Landing Zone,101 with the former representing a means of deploying the preconfigured, deployable and secure multi-account architecture represented by the latter. Azure is not as mature as AWS in terms of preconfigured secure deployable templates; however, Microsoft has documented its concept of an Azure Scaffold,102 which is essentially a guide to putting in place the structures (e.g. account hierarchies) needed to operate securely in the Cloud. The Azure Blueprints103 service will likely allow Microsoft to copy the AWS Landing Zone concept in the near future, whilst the Lighthouse104 service allows consistent management across accounts (similar in some ways to AWS Control Tower). In the meantime, enterprises are able to make use of the Azure Blueprints service to create their own in-house standard secure environments.
Figure 20 illustrates what a secure, repeatable AWS environment may look like; it is derived from the AWS Landing Zone approach but is not the default Landing Zone.

Figure 20: Example AWS architecture
This example architecture adopts the approach of account-level segmentation, i.e. every single application is deployed into its own AWS account so as to limit the impact (‘blast radius’) of any compromise to that single application and account. The NotPetya outbreak of 2017 highlighted the need to improve internal segmentation in order to avoid the kind of catastrophic spread of malware suffered by the likes of Maersk.105
The segmentation offered by account-level segregation is a massive security improvement compared to the traditional flat network architecture found in many enterprises. Other key features of the architecture shown in Figure 20 include the use of a shared services account; this enables the various applications to use a common set of services and to avoid having to duplicate these services across each account. Depending on your preference, some of these shared services may be better exposed to relying parties via the AWS PrivateLink service; this can help you avoid having to peer across VPCs or having to use the AWS Transit Gateway service. This architecture has also separated security logs into their own dedicated account. This approach allows us to use the Service Control Policies106 (SCP) feature of AWS Organizations to limit the actions of the root user within the logs account, i.e. we can use SCPs to prevent even the root user from being able to tamper with the security log information stored within the account.
Now, pre-approved configurable environments are only one element of an overall DevSecOps approach. It is fairly traditional to represent the DevSecOps approach in the form of an infinity diagram, and I see no need to break that tradition. Figure 21 illustrates the overall DevSecOps approach.
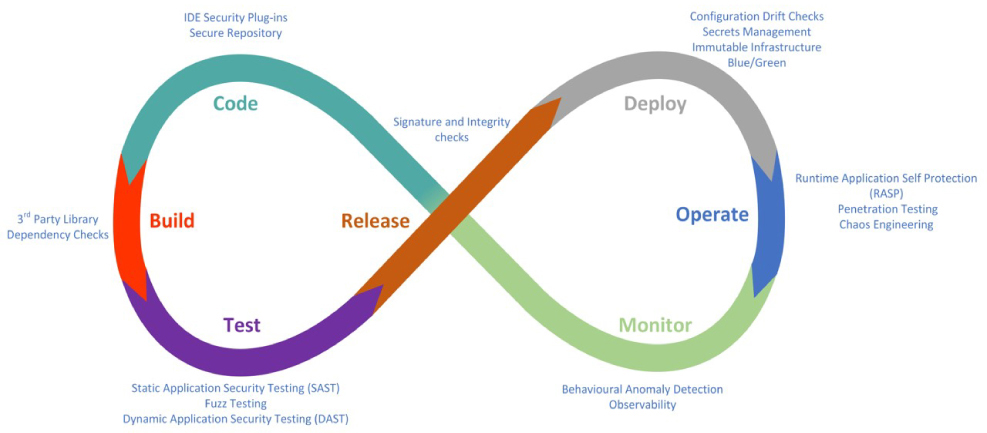
Figure 21: The DevSecOps approach
Let’s describe each element of the approach in turn, beginning with ‘code’. An Integrated Development Environment (IDE), such as Eclipse or Visual Studio, is used by developers to code their applications. IDEs will typically include code editors (with code completion and syntax checking) and debuggers and they allow the inclusion of a variety of other plug-ins. These plug-ins can, and should, include plug-ins relating to security functionality. Examples may include plug-ins that natively identify known programming weaknesses or that call out to the code analysis tools available in the ‘deploy’ and ‘test’ elements of the cycle. Thinking back to the SRM (Figure 7), the code element of the cycle needs to consider the coding standards, code review and repository security services. It is imperative that organisations do not forget to secure their code repository; as we move towards infrastructure-as-code, it is apparent that a compromise of the code repository is equivalent to a compromise of the infrastructure that code describes. In an ideal world the code repository will be located in an environment at least as secure as the relevant application and infrastructure for which it stores information. Cloud-based code repositories, such as those offered by GitHub and BitBucket, can be adequately secured; however, organisations should make sure that they enforce multi-factor authentication: no organisation should find itself in the position of being only the compromise of a single username/password combination away from losing their entire infrastructure.
Once a developer is ready to commit and build their application, we can move on to the ‘build’ phase of the cycle (and of the SRM). The build phase will see the various components of the application being linked, or incorporated, into an executable, which will likely include a variety of third-party code libraries. Organisations should ensure that these third-party code libraries do not include any nasty surprises such as known security vulnerabilities or unwanted licence conditions. Tools such as those offered by Black Duck107 and WhiteSource108 can be used to identify known weaknesses in open source components and to highlight associated licence concerns.
Once the code is built, the developer can run a series of security tests prior to pushing the code through to deployment. This test stage is very important in the DevSecOps approach which often lacks the capability to provide a full penetration test of every release prior to go- live. Tests should include the use of both static code analysis tools (whereby the application code is checked without executing the application itself) and dynamic code analysis tools (which check the application whilst it is running).Organisations may also wish to consider making use of fuzzing tools. Fuzzing tools, such as American Fuzzy Lop (AFL), mutate application inputs to check that the application handles these inputs appropriately. Fuzzing tools are particularly recommended for those applications accepting input from outside a trusted environment.
Third-party dependency checkers, SAST, fuzzers and DAST tools can all be incorporated into automated CI/CD (continuous integration/continuous delivery) pipelines; this ensures that if they highlight high priority issues, the CI/CD tool (e.g. Jenkins) will fail the build and send the findings back to the developer for remediation.
Once any security issues have been remediated, the process moves on to the ‘release’ stage. In this stage, it is necessary to check that the code about to be deployed is actually the code that the developer believes it to be! These checks can take the form of digital signature or simple hash-based integrity checks of the code about to be deployed. If those checks complete successfully, the code can be deployed.
The ‘deploy’ stage of the cycle includes a consideration of the SRM’s secrets management service. Applications and infrastructure components will often need to authenticate themselves to other elements of the overall environment. A good example may be the need for an application to authenticate itself to a back-end database, possibly in the form of a SQL connection string. It is extremely bad security practice to embed such security credentials in the application code because compromise of the code would also see the database itself compromised. Instead, developers should use a secrets management tool as a secure vault for application secrets; these can then be retrieved at run-time or deployment, depending on the nature of the secret. There are a variety of options available for secrets management; these depend on the IaaS in use and on third-party tooling that can be used across a variety of IaaS services. HashiCorp's Vault109 is a particularly popular third-party secrets management tool, whilst those working with Azure will typically make use of Azure Key Vault110 for the storage of secrets. AWS offers a variety of secrets management approaches for use in different circumstances, including Secrets Manager111 and Systems Manager Parameter Store.112 Users of the Google Cloud Platform will typically need to adopt a more manual process via the use of encryption services provided by Cloud Key Management Service (KMS).113
The remaining elements of the DevSecOps cycle will be described as we get to the appropriate elements of the SRM as they are not solely applicable to secure development and DevSecOps.
Integration
The integration set of services exists to support working across a diverse Cloud environment, commonly referred to as a ‘multi-Cloud’ environment. As described earlier, it is commonly the case that organisations select discrete Cloud services to deliver discrete types of workloads rather than looking for true portability of workloads across Cloud services. However, there are some organisations that do seek to deliver such portability of workloads across Cloud providers, usually when driven by strict regulatory requirements relating to business continuity and exit planning. If such portability is deemed to be a requirement, this will often be implemented through the use of containerisation, e.g. through the use of Docker, Kubernetes, OpenShift and related technologies which essentially abstract away the underlying hosting environment. In theory, this approach allows organisations to move containerised workloads between, for example, Kubernetes environments hosted on-premises and Kubernetes environments hosted on AWS, Azure or GCP. A downside of this approach is the additional complexity – which is the perpetual enemy of security – and the loss of access to the Cloud-native capabilities. Organisations find themselves essentially working primarily in Kubernetes environments rather than in Cloud environments. It is the API service within the integrity set of services that allows workloads to be moved via calls to the relevant APIs within both the Cloud provider and the containerised environment.
Cloud Access Security Brokers (CASBs) are described fully in chapter 11 but, in essence, they can be used as a form of proxy between Cloud users and the Cloud services that they access, providing a consistent point of control and monitoring across the Cloud environment.
Cloud Workload Protection Platforms (CWPPs) allow Cloud consumers to apply consistent security controls to their Cloud-hosted workloads; they typically provide controls at the Cloud control plane, network, operating system and container level. CWPPs offer two main advantages:
1.They allow controls to be applied across on-premises and a variety of CSPs via a single user interface; and
2.They help to enable portability of workloads through the CWPP abstraction layer.114
However, as with previous discussions of Cloud portability, the use of tools like CWPPs also abstracts away some of the ability to directly use the tooling available within the Cloud platforms. Even so, those organisations implementing multiple services across multiple Clouds in a hybrid environment can benefit from the ability to consistently enforce microsegmentation via CWPP tooling. A few examples of such tooling are provided below:
•Guardicore (www.guardicore.com/)
•Twistlock (www.twistlock.com/)
•Aqua (www.aquasec.com/)
Integrity
In SRM terms, the integrity service grouping is all about maintaining trust in the systems and data used to implement an application. The non-repudiation service is designed to ensure that actions can be attributed to the correct individual, organisation or process; it works to maintain trust in the provenance of the application or data. The content check service is there to ensure that the information object to be processed does not contain any nasty surprises such as corruption, unauthorised modification or inclusion of malware. The snapshot service is there to enable (almost) instant backup to a known good image. The snapshot service can also be used to capture the contents of a virtual machine image thought to be compromised in order to perform a forensic analysis.
The non-repudiation service would typically be delivered using a combination of services defined elsewhere within the SRM. For example, identity management services would provide identity information, monitoring services would provide event information and the non-repudiation services would provide the binding between the user and the event. The non-repudiation services could then make use of the cryptographic services to provide true non-repudiation, or simply rely on the strength of the auditing if true, legally binding, non-repudiation is not required. Why might non-repudiation be an important service for those working with Cloud services? Consider the pay-as-you-go nature of Cloud services. You really want to be quite certain of who fired up the virtual servers for which you've just been billed. Consumers should ensure that their providers offer appropriate audit trails; as a minimum, these should indicate the users that have requested new or additional resources. Similarly, consumers should ensure that there is an adequate audit trail of the release of resources, e.g. to ensure that a basic denial of service attack of simply shutting down a virtual infrastructure can also be captured.
The content check service grouping describes a vital collection of security capabilities. It encompasses traditional antivirus mechanisms and file integrity mechanisms, together with higher-level mechanisms, to ensure that application level traffic does not contain malicious content. In order to make this a little more real, consider the situation whereby our application in the Cloud processes significant amounts of XML-encoded data. How can you ensure that this XML-encoded data is safe to store and process and does not in fact include any malicious embedded content or include any entities containing SQL injection or cross-site scripting attacks? I have come across systems in the past whereby attackers could supply XML that was stored in a back-end database and then later passed from the database to a web browser. Stored cross-site scripting can be fun. What is specific about content check and IaaS though? Not an awful lot; in general, many of the best practices associated with traditional application deployments still apply:
•Do not trust user-supplied input;
•Do not trust information sourced from outside of your trusted domain;
•Do not assume that information has not been modified since it was created or last accessed; and
•Do not allow code to run unless you know what it's going to do.
Many of the tools used on a traditional deployment are equally suitable115 for use on an IaaS deployment; your antimalware system of choice, for example, can be used to protect your IaaS-hosted application (subject to licensing).
As one option, Cloud consumers may wish to consider using Cloud-based content check services, e.g. web application firewalls (WAFs) with associated malware-checking/sandboxing capabilities such as those offered by Akamai Kona or Imperva Incapsula. Figure 22 shows how this approach can be used to isolate an organisation's Cloud environment from the hostile Internet.

Figure 22: Cloud WAF
Another advantage of the approach illustrated in Figure 22 is that, in some circumstances, it allows you to limit your secure environment’s inbound traffic to the source addresses of your Cloud-based WAF service, substantially reducing your overall attack surface.
The move to Cloud is often associated with a move to more loosely coupled service-oriented applications (aka microservices) and away from monolithic applications. This will typically involve exposing a number of service interfaces – each of which will (ideally) require some form of validation of the input passed to them. There are a number of third-party security tools that can be used to perform such security validation/content checking, for example:
•Axway AMPLIFY (www.axway.com/en/products/api-management)
•CA API Gateway (www.ca.com/gb/products/ca-api-gateway.html)
•Forum Systems (www.forumsys.com)
I should note that such products typically call out to an external antivirus engine to perform traditional checks for malware. These tools are necessary if you need to parse the XML being passed between your applications and your users and ensure that this XML does not include malicious content. If you can't parse the XML, you can't check the content. The requirements and risks underlying your security architecture will dictate whether such tools are necessary or whether you can rely upon the schema validation capabilities of more standard XML parsers. The Cloud providers themselves also offer API management/gateway capabilities, e.g. AWS API Gateway, Azure API Management and Google Apigee. These Cloud-native capabilities are often not as fully featured as the dedicated third-party API security products but they will likely be suitable for some less sensitive workloads.
Cloud consumers also have a number of choices when it comes to the provision of traditional anti-malware capabilities for use on their IaaS environments. Consumers of Azure have access to Microsoft Antimalware for Azure116 (built on the same platform as Windows Defender) as part of the Azure suite of services. Users of other major IaaS vendors will need to look to third-party tooling to provide anti-malware capability. One of the more popular options is TrendMicro's Deep Security tool which offers a variety of end point protection capabilities (e.g. file system integrity monitoring and host IPS) in addition to traditional anti-malware protection. Deep Security, and other similar tools designed for deployment on the Cloud, tend to be API-driven; this means that they can be configured and articulated as code just like the rest of the Cloud infrastructure.
In addition to this traditional mechanism of checking content for malware and then removing it if identified, a more recent innovation is the approach of content re-writing. Using this approach, content such as a Word document or a PDF document is analysed and then re-rendered in a new document. This approach strips out any macros or other potentially malicious code and the new, re-rendered document is known to be clean. This capability can be delivered using tools from vendors such as Deep Secure117 or Menlo Security118.
Another driver for an increased awareness of content checking within IaaS deployments is that the data to be stored and processed on your application is likely to be stored within shared storage systems. Depending on the level of trust you have in those shared storage mechanisms, and the level of risk that you are willing to accept, you may wish to perform some level of integrity checking prior to processing any information objects retrieved from such storage. For example, one of the classes of information objects stored in an IaaS environment will include virtual machine images – you really would not want to fire up a Trojaned image.
Now, this is where the security requirements underlying the snapshot service become apparent. There is a need to capture a snapshot of an information object at a specific point in time and then be able to verify that the information object matches the snapshot when it is next accessed. The conceptual snapshot service within the SRM would typically require the use of cryptographic services to provide a signed hash of the information object in an actual implementation. There would also need to be technical services to generate the snapshot to validate the signed hash. These capabilities are typically offered natively by the Cloud platform. Such services would reside within the encryption conceptual service grouping of the SRM.
Availability
One of the perceived strengths of the Cloud model is the ability to deploy highly available systems without the need to invest in multiple data centres complete with fully replicated technology stacks, diverse communications links and data mirroring.
However, CSPs are not immune to availability issues themselves and, being high profile, outages of Cloud services such as Office 365 and Amazon EC2 are well publicised. The downdetector119 website provides an independent service for tracking the issues of specific Cloud providers, which is useful if you do not wish to place complete trust in the availability status pages of the Cloud providers themselves. The status pages of the main IaaS Cloud providers are listed below:
•AWS: https://status.aws.amazon.com/
•Azure: https://status.azure.com/en-us/status
•GCP: https://status.cloud.google.com/
•Digital Ocean: https://status.digitalocean.com/
•UKCloud: https://status.ukcloud.com/
The major Cloud providers tend to be very transparent in their write-ups of any incidents because they recognise the importance of trust: Cloud consumers will not place the well-being of their business in the care of an IaaS provider that they cannot trust to meet their availability requirements.
In terms of maintaining the availability of a hosted service, you should consider whether your CSP has multiple data centres and whether these data centres are appropriately isolated from each other. If so, then you could consider hosting your services across the CSPs data centres so as to provide redundancy or resilience (or both) depending upon your architecture.120 You should, however, bear in mind that any replication traffic between the two data centres may entail having to pay for the traffic to leave one data centre, traverse the Internet Cloud and then enter the other data centre –such replication does not always go over the Cloud provider's own wide area network. Given that most CSPs charge to transfer data into their Clouds and/or out of their Clouds (usually more for the latter) replication of data between data centres is usually viewed as two independent data transfers and charged accordingly. Consumers looking to implement their application using the IaaS model could consider hosting their services on two or more different IaaS platforms to provide their redundant service rather than just using two data centres from the same provider. Some Cloud consumers may face regulatory pressures to demonstrate this level of multi-Cloud business continuity in the event of Cloud service provider failure or contract exit, particularly in the financial services sector. This can lead to Cloud consumers looking to achieve levels of workload portability that may adversely impact their ability to make use of native Cloud provider functionality due to a need to avoid lock-in. For example, a number of financial services organisations have been driven towards building their own containerised microservices architectures that may allow workloads to move across the major Cloud providers. This level of cross-provider failover may help to address regulatory concerns but it comes at the cost of increased complexity. Added complexity may also adversely affect the overall availability goals and it will definitely abstract the consumer away from the benefits offered by rapidly evolving Cloud provider native capabilities.
Another issue related to the inconvenience of working across Cloud providers is the necessity of mastering the intricacies of the management tooling and APIs of each Cloud provider; even though using containers can make workload portability more straightforward, it is still necessary to design, provision and operate the hosting infrastructure. The pain of having to deal with two sets of management APIs could be mitigated through the use of tools such as Rightscale (www.rightscale.com), which enable the management of multiple Clouds from a single interface or through contractually handing that pain over to a third-party to manage via a Cloud service brokering arrangement. Consumers do have options for moving their workloads across Clouds in the event of a failure at their main provider; however, in most circumstances, it is uncertain whether the resulting increase in complexity provides more benefits than a reliance upon the resilience available within a single Cloud provider.
Cloud providers do tend to build resilience, including geographic separation, into their offers. Amazon, for example, host separate instances of their services in different regions, based on their geographical locations. Example regions include US East, US West, EU (Ireland), EU (London), Asia-Pacific (Tokyo) and South America (São Paulo). Each region is then split into separate Availability Zones. Availability Zones are designed to be insulated from failure within other Availability Zones. For example, should Amazon's Simple Storage Service (S3) fail in one Availability Zone, clients using other Availability Zones in the same region should not be affected. At least that was the theory. Unfortunately an incident in 2011 showed that the levels of isolation between Availability Zones were not sufficient to prevent an incident in one Availability Zone spilling over into an effect on the wider region. To their credit, Amazon provided an extensive review of the incident that led to this outage (essentially a configuration management error during a scheduled upgrade which rapidly snowballed into a major outage). This review can be found at:
https://aws.amazon.com/message/65648/.
There is an interesting related blog entry from Don MacAskill of SmugMug (customer of AWS) at:
https://don.blogs.smugmug.com/2011/04/24/how-smugmug-survived-the-amazonpocalypse/.
This blog entry provides an interesting perspective on how the AWS outage referred to above looked to a customer who was able to keep their service running, and provides some insight into how they were able to stay up whilst others were not.
There have, of course, been other outages since 2011. The S3 outage of 27 February 2017 not only took out Amazon's US-East-1 Region, it also adversely affected a number of well-known web services that rely upon S3 for back-end storage, including Netflix, Reddit and The Associated Press. This latter incident was found to be due to simple human error; it occurred when an operator mistakenly removed too many S3 servers from the available pool as part of a business as usual hardware refresh.121 The number of websites affected by this incident shows how the major Cloud providers are becoming a systemic risk to our digital way of life; it also partly explains the wariness of financial services regulatory bodies when it comes to maintaining the stability of the wider financial environment.
I should point out that Amazon have taken steps to resolve the process and technology issues that led to these outages. The use of Availability Zones should not, therefore, be discounted to provide a certain amount of resilience. For true resilience however, consumers of AWS should consider running their service across different Regions rather than relying upon Availability Zones. As noted earlier in this section, this would have cost implications, particularly if you need to transfer significant quantities of data between regions. The link below provides further information on AWS regions and Availability Zones:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-regions-availability-zones.html.
Amazon are not the only IaaS CSP able to provide discrete Cloud services hosted within different data centres. Azure recently implemented their own version of availability zones, functioning very similarly to those of AWS with a minimum of three such zones within each region offering the capability. Further detail on the Azure version of availability zones can be found here:
https://docs.microsoft.com/en-us/azure/availability-zones/az-overview.
The Google Cloud Platform also offers zones to deliver the same kind of fault and update domain separation as documented here:
https://cloud.google.com/compute/docs/regions-zones/.
The implementation of availability zones is one feature that significantly differentiates the hyper scale Cloud providers, such as Azure, GCP and AWS, from the smaller players. Whilst UKCloud does have a concept of zones, they are not as discrete or isolated as the equivalent functionality offered by the Big 3; for example, the different zones within UKCloud may share network infrastructure and power122 and offer increased resilience but they are not true isolated fault domains. At the time of writing, Digital Ocean do not offer functionality akin to the availability zones described in this section.
Regardless of the mechanisms that you decide are the most appropriate for your application, e.g. hosting across multiple CSP data centres, hosting across multiple CSPs or hosting across on-premise and the Cloud, you must still test that the failover mechanisms work as anticipated. There's very little worse than only finding out that your business continuity and disaster recovery plans are worthless at the time they are invoked. Better to test them regularly and fine-tune them such that, in the event of a serious incident, you are able to continue to serve your users.
As an aside, remember to adopt some of the traditional best practices around resilience and redundancy from the on-premises world when designing your virtual infrastructure. Avoid single points of failure. Build in resilience where necessary. Design to handle the failure of individual components gracefully. As with your business continuity plans (BCPs) and disaster recovery plans (DRPs), test your infrastructure to ensure that failures are handled as expected. It is important to remember that even if you do make the wise decision to split your applications across availability zones, this does not happen automatically; consumers still need to design and build in the necessary capability, e.g. through implementation of Elastic Load Balancers (ELBs) to split load across zones.
Technical failure at a CSP data centre aside, the other major potential availability issue facing Cloud consumers is a commercial one. What happens if your CSP goes out of business? Or is acquired by a competitor who then closes down the service? This is not an unprecedented situation; Coghead were a PaaS provider who closed down in 2009 with their intellectual property being acquired by SAP. Coghead customers had a matter of weeks to make alternative provision for the operation of their services; a task made even more problematic as services designed to run on the Coghead platform could not be easily ported to a different platform. There is currently a significant amount of consolidation in the Cloud and security industry, e.g. the purchase of Duo Security by Cisco in 2018, or the acquisition of Skyhigh Networks by McAfee in 2017. Whilst I do not expect either of those products or services to be adversely impacted by their acquisitions, it is not uncommon for enterprises to have their own ‘bogeymen’ vendors that they refuse to do business with, either because of a past commercial dispute or a simple dislike. The acquisition of an organisation's favoured Cloud-based service by such a ‘bogeyman’ vendor creates an uncomfortable situation. Cloud consumers must ensure that financial stability and the potential for acquisition factor into their due diligence of prospective Cloud providers.
The latest iteration of the SRM introduces two services that merit further discussion: evergreen and reliability & chaos.
Evergreen
In this context, Evergreen refers to a mechanism for keeping your Cloud-based workloads up to date with the latest security patches without the pain of deploying such patches into a live environment. This approach goes by a number of other names, notably ‘blue/green’ (as noted earlier) and ‘red/black’; the latter term is used in the context of Netflix and Netflix-related Cloud deployment tooling such as Spinnaker.123 The concepts remain similar regardless of terminology.

Figure 23: The blue/green approach
Figure 23 illustrates the concept of blue/green deployments at a high level. A Cloud consumer can deploy two application stacks, one which is currently used for production (live environment/blue) and one which is continually refreshed with security patches and the latest releases from the application stack (staging environment/green). At their chosen frequency, the Cloud consumer can switch traffic/load from the blue environment to the green environment via the ‘load director’ component. The load director is a conceptual service but it can be delivered in a number of ways, including load balancers, proxies and DNS. Once the load has switched, the formerly blue environment becomes green and is continually refreshed. This approach offers a number of advantages:
•Servers and code do not need to be updated in the live environment, which reduces the risk of service outage and of requiring downtime in which to apply patches;
•The blue stack can be made immutable once in production, which reduces the risk of human error; and
•A simple rollback to the old blue is possible in the event of issues during deployment.
The dashed lines in Figure 23 demonstrate that organisations do not have to do blue/green in monolithic chunks: different elements of the stack could be deployed as individual components in a blue/green manner.
Whilst blue/green can offer a number of operational advantages, as described above, there are some complexities that also need to be considered. For example, the handling of information and live databases can be problematic in terms of the synchronisation across blue/green, particularly during switch-over. Similarly, the implementation of the load director component can be problematic; for example, when using DNS there may be a period in which load is being directed to both blue and green prior to the expiry of previously cached DNS entries. As with most matters of architecture and design, blue/green comes with trade-offs between risks and benefits.
Reliability & chaos
One of the major developments in the Cloud world over the last decade or so has been the emergence of chaos engineering approaches and the wider field of Site Reliability Engineering (SRE). SRE is a wide topic and worthy of a book in its own right – fortunately Google have produced just such a book and have made it available for free download. Those interested in how to architect, deliver and operate reliable systems at scale are strongly encouraged to read Google's thinking, available from:
https://landing.google.com/sre/sre-book/toc/index.html.
Chaos engineering is a discipline that has been both helped and hindered by its nomenclature. The use of the term ‘chaos’ has certainly garnered a lot of interest amongst technical staff, but it also raises concerns among business stakeholders when such approaches are discussed. The idea behind chaos engineering is to introduce deliberate errors within systems to ensure that they can recover and maintain service. One of the first manifestations of this approach was the Chaos Monkey tool published by Netflix as part of their wider, now retired, Simian Army124 tool-set. The Simian Army tools enabled organisations to purposefully introduce errors into AWS environments, from the deliberate removal of EC2 instances through to the emulation of an entire AWS Region failure. The aim of this being to engineer the overall service to survive any such outage.
The key point, which sometimes gets missed in discussions of chaos engineering, is the absolute imperative of agreeing on the failure domain, the scope of testing and the rollback plan. Whilst the introduced failures may be ‘random’ within the agreed scope, organisations must be able to limit the blast radius associated with the testing via appropriate containment and recovery/rollback approaches. Organisations should on no account begin applying chaos approaches to production systems without a view as to how to prevent any leakage outside the agreed test scope.
So, given the dangers, why would any organisation consider chaos approaches? The clear answer relates to a need to be able to support always-on digital services. Netflix developed the Simian Army tool-set because its business model depends on it being able to deliver content on demand. The introduction of random failures identifies potential failure conditions that may not have been considered during architecture and design meetings and, as a result, encourages the incorporation of additional self-healing or failover capabilities. On which note, organisations should certainly hold desk-based chaos assessments of their architectures and designs prior to conducting such activities on live services. There is less risk associated with breaking and fixing designs than production systems, even if only from a career management perspective.
Chaos engineering is clearly more suited to some organisations than others. It definitely has great potential benefits for those offering digital services targeted at the consumer market; it is, however, unlikely to be an approach suitable for ICS environments where errors have potential real-world consequences that cannot be reverted.
Cryptography
In terms of cryptography, IaaS consumers have the flexibility to build in (within reason) whatever levels of cryptographic protection they feel their application merits. This can be a benefit, or simply an extra development and/or implementation overhead, depending upon your perspective. PaaS providers may well offer their own cryptographic services within their platform. SaaS providers will either offer encryption of data at rest or they will not; SaaS consumers have little room for manoeuvre.
The hyperscale Cloud providers have adopted similar mechanisms to enable encryption within their platforms – both AWS and GCP have key management systems (KMS), whilst Azure offers similar capabilities through the Azure Key Vault, which makes it possible to generate, store, rotate, revoke and present cryptographic keys for consumption by other services. The keys produced by KMS services are used by Cloud provider native services, e.g. for encrypting data at rest in services like AWS S3, GCP Cloud Storage or Azure Storage (both GCP and Azure Storage are encrypted by default, and S3 buckets can be configured to become encrypted by default). The keys produced by KMS services can also be used by applications hosted on the Cloud provider systems – Cloud consumers do not have to implement their own key management services and, indeed, they should not attempt to unless they have a very high level of implementation abilities. Cryptographic systems are notoriously difficult to implement without introducing weaknesses, and organisations are well-advised to avoid ‘rolling their own’.
There is one important difference between on-premises and in-Cloud when it comes to cryptographic services: the issue of trust. If your Cloud provider is responsible for the generation and management of the cryptographic keys, then CSP staff are, in theory, capable of decrypting consumer data encrypted using those keys. Cloud consumers that are uncomfortable placing such trust in their Cloud providers have options available to them. The hyperscale Cloud providers also offer tamper-proof hardware-based key storage capabilities, e.g. AWS CloudHSM, Google CloudHSM or Azure Dedicated HSM; these use hardware security modules to secure key storage under the control of the Cloud consumer. However, whilst using HSMs does provide more assurances concerning the security of cryptographic keys, it does not necessarily address the core question of trust. Consumers must still place a degree of trust in the Cloud provider and HSM vendor that these Cloud-based services function as claimed, even if they are within the scope of independent assurance activities such as ISO 27001 certification.
Those Cloud consumers with an extremely low appetite for risk are able to implement their own HSMs on-premises for the purposes of key management. Such consumers can then either encrypt all data prior to upload to Cloud services or else, if they are slightly more trusting, import the generated keys into the appropriate Cloud-based KMS for use by their Cloud-hosted services (commonly referred to as bring your own key (BYOK)). BYOK scenarios do introduce a degree of risk: consumers are responsible for key generation, rotation and revocation and must bear responsibility for the availability of those keys, including for backup and archive purposes. A loss of encryption keys will result in a loss of access to data and, consequently, to service.
Now, one of the major categories of IaaS provision is Storage as a Service – either as a service in its own right or as part of wider provision, e.g. S3. With Storage as a Service, consumers trust the CSPs with the secure storage of their data. Typical use cases for Storage as a Service include data storage for the purposes of archive, backup and disaster recovery. More generic IaaS implementations will also require the use of persistent storage mechanisms; for example, these may be required to store virtual machine images or to function as the back-end storage for database systems. In both cases, when the consumer is sending sensitive data to the Cloud, it is likely that this data will need to be encrypted, both in transit and at rest.
Encryption in transit is a fairly easily solved problem: most CSPs will support the upload of data via TLS encrypted communications. In addition, the hyperscale CSPs all support dedicated links between a consumer's on-premises data centre and their Cloud environments. Each provider has a different name for this service: AWS calls it Direct Connect, Azure calls it ExpressRoute and GCP calls it Dedicated Interconnect. Dedicated connections can reduce the number of encryption requirements when the data requiring transfer is no longer traversing the Internet. Consumers can, therefore, send their data into the Cloud relatively safely via TLS (always bearing in mind the increasingly shaky foundations of the trust infrastructure underlying the protocol), or other VPN link or dedicated connection. As noted earlier, once on the Cloud, the hyperscale CSPs will typically enable encryption of that data by default. Consumers of other, smaller Cloud providers, must assure themselves of the data-at-rest encryption capabilities of their chosen providers as they may not offer the same levels of protection.
There is an approach that can enable you to store your sensitive data in the Cloud without needing to trust your Cloud providers; on-premises encryption using your own encryption keys. If you perform your encryption on-premises, and only transfer the encrypted data, then you will never be sending your sensitive data out of your secure environment in the clear. This approach is suitable for the archiving and off-site storage for backup and disaster recovery use cases. It is less suitable for more transactional systems whereby you want to actually process the data once it is in the Cloud. Later in this book, we will touch upon tokenisation and order-preserving encryption approaches, and using these to enable SaaS services to process sensitive data (see chapter 11).
In summary, if you are performing encryption activities and view CSP staff as a threat actor, then perform as much of your data encryption (including key management) on-premises as you possibly can. However, the encryption and key management facilities offered by the major Cloud providers should be viewed as sufficient for all but the most sensitive use cases.
Access management
The SRM includes a significant number of services relating to access management (AM):
•Identity management (IdM)
![]() Registration
Registration
![]() Provisioning
Provisioning
![]() Privilege management
Privilege management
![]() Directory
Directory
•Validate
![]() Authorise
Authorise
•Federate
•Reputation
•Policy
•Filter
These services are shown in Figure 24, which is an extract from the SRM.

Figure 24: Access management
The SRM is primarily there to guide us in the development of services relating to a hosted application; however, it would be remiss if we did not use the same conceptual services to secure the administration of the infrastructure hosting the application. I will, therefore, talk a little about the identity management services offered by some example IaaS providers in addition to those relevant to hosted applications.
Identity management
The identity management grouping includes the registration, provisioning, privilege management and directory services.
The identity management services provide the underlying capabilities needed to facilitate the creation of users within your application, and to then assign those users with the appropriate privileges and store all of this information securely in a directory. Some of these services will be implemented outside of your organisation if you are following a federated approach to identity management. I will expand upon this more fully when I talk about the federate service later in this chapter. For now, just remember that your application needs users, users will often need to be able to perform tasks according to their levels of authorisation, and that you need a mechanism to manage these users and tasks during the lifetime of your application.
How are such services impacted by hosting an application within a public IaaS Cloud? The procedures governing registration are likely to be independent of whether an application is being hosted on-premises or in the Cloud. The requirements for the amount of proof a new user needs to provide to confirm their identity and then gain access your application will typically be driven from compliance requirements. Registration requirements can vary from practically zero (provision of an email address for example), to more invasive information requests (name, address, date of birth, credit card details, etc.) all the way through to a requirement to conduct a physical inspection of official documentation such as passports. Whilst the requirements regarding registration are independent of delivery model, you must remember any compliance requirements dictating where you may store any personal data obtained during the registration procedure. This is particularly relevant where you are dealing with information relating to EU citizens or PCI-compliant data.
The provisioning service relates to the creation, amendment and deletion of user accounts within the application, together with the mechanisms used to distribute credentials to the end users. The provisioning service can be viewed as the next step in the process of granting users access to your application, once you are content that they have provided sufficient proof of their identify via the registration service. How you provision users is very dependent upon your application and the underlying technologies that you choose to provide the directory services (e.g. an on-premises Windows Active Directory, the Cloud-based Azure Active Directory or perhaps a managed directory service). I am not going to detail the processes for creating, amending and deleting users across these different products as that's a level of detail too low for me to hope to cover in this book. However, I will comment upon the credential distribution aspect.
Clouds tend to be viewed as being quite insubstantial. You don't need your own physical data centre or physical hardware, rather everything takes place in a virtualised environment in a CSP data centre. However, if your application requires strong authentication, it is possible that you will have to distribute physical tokens such as those offered by RSA SecurID or Gemalto. These tokens tend to generate random sequences of numbers either upon request (usually after entry of a Personal Identification Number (PIN)) or at set intervals (e.g. every 60 seconds). These random sequences must then be entered as part of the process of authenticating to an application – this form of authentication represents the classic two-factor authentication (2FA) model, i.e. something you know (the PIN and the password associated with the account) and something you hold (the physical token generating the random number sequences). A consequence of implementing token-based authentication is that, even if the application itself is hosted in a CSP data centre, you must still have the facilities to store, configure and then distribute the tokens used to authenticate users to your application.
However, there are alternative approaches. The use of hardware tokens outside of the most sensitive environments is declining in favour of soft token technologies based on the Time-based One-Time Password (TOTP)125 and FIDO U2F (Universal 2nd Factor) schemes.126 Soft tokens are implemented in software rather than hardware so they can be installed on mobile devices, effectively turning the mobile device into a second factor. The Google Authenticator application is a popular implementation of a TOTP-based authentication provider – it is also the default second factor authentication provider for a variety of Cloud-based service providers, such as Service Now.
There are a number of companies offering Identity as a Service, for example Okta (https://www.okta.com/), as well as authorisation and Authentication as a Service (AaaS) providers like Duo Security (https://duo.com/), which was acquired by Cisco in 2018. Such providers offer a number of different authentication mechanisms including token-based (hard and soft), SMS-token (whereby the random number sequence is sent to a mobile device via SMS) and simple password-based authentication (which is not recommended). The major Cloud providers also offer multi-factor authentication services that can be consumed by hosted services, e.g. AWS Cognito or Azure MFA. Such authentication services can then be integrated into a Cloud consumer's application using established protocols and standards such as OpenID Connect or SAML. There are two obvious advantages to using an AaaS provider:
1.You no longer need to concern yourself with the problems of implementing your own provisioning or directory services for the application; and
2.You no longer need to worry about storing, configuring and distributing physical access tokens.
The obvious disadvantage of using an AaaS provider is that you are now entrusting the task of controlling access to your application to a third party. The capability for trusting third parties is dependent upon organisational culture; the purpose of this book is to provide you with options for securing your Cloud applications; the choice of which option to adopt for your application depends upon your particular situation.
I have outlined some of the options available for the logical elaboration and physical implementation of the conceptual identity management services for a hosted application; but what options are available to provide identity management services at the IaaS management plane level? Valid concerns could be raised that the effort expended to implement strong authentication for an application could be undermined by weak authentication to the hosting infrastructure.
AWS and identity
Let us begin with Amazon Web Services. Amazon offers a number of mature mechanisms for managing identity and access entitlements; these are centred on the AWS Identity and Access Management (IAM) service. The AWS IAM service (https://aws.amazon.com/iam/) enables their customers to provision multiple users, each with their own unique password, and to then define the AWS APIs and resources they can access. AWS consumers can also choose to continue to manage their users and their entitlements by using an existing Windows Active Directory via the AD Connect tool. AWS IAM enables customers to group their users according to their access needs and to add conditional aspects to their access, e.g. by providing the option to restrict the times of day that they can access the services. AWS customers can, therefore, implement segregation of duties, for example by having one group of users able to manage the virtual compute resources hosted upon AWS EC2 whilst having another group of users responsible for managing the storage services hosted upon S3.127 Best practice however is to make use of IAM Roles rather than groups, with users assuming the role with the access rights that they need at time of use. AWS IAM policies generally use the AWS Account as the default security boundary, though customers can choose to trust identities in other accounts. Furthermore, AWS introduced the concept of AWS Organizations in 2017 to enable cross-account policy management, and this led to the introduction of the Service Control Policy (SCP) capability.128 SCPs can be applied to limit what users can do within accounts, e.g. an SCP could be applied to prevent the root user within an account being able to delete an S3 bucket containing security logs. SCPs are useful for enforcing dual control in secure environments.
As well as AWS IAM, Amazon also offer the capability to implement two-factor authentication (2FA) via the AWS Multi-Factor Authentication service, AWS MFA (https://aws.amazon.com/iam/features/mfa). AWS MFA supports 2FA via either physical tokens, in the form of Gemalto hardware tokens or Yubikey U2F tokens, or via software installed on to a physical device such as a smartphone or tablet which can also generate one-time passwords. This effectively makes the smartphone or tablet the equivalent of the physical token. Each user defined using AWS IAM can be allocated their own authentication token using AWS MFA. MFA can be used to secure both AWS Management Console users and AWS API users.
Azure and identity
Users of Microsoft Azure can manage their identities via Azure Active Directory (AAD).129 Microsoft uses the ‘tenant’ concept to refer to a dedicated AAD instance. A tenant can be used by multiple Azure subscriptions, but each subscription can only trust one tenant. In summary, a consuming organisation will have an account (for billing), at least one tenant and one or more subscriptions. Subscriptions act as a security boundary but do rely on AAD for identity services. Where AWS has Organizations and SCPs, Azure offers similar capabilities through Management Groups130 and Azure Policy131. Subscriptions can be added to Management Groups, with Azure Policy then being used to enforce consistent controls/policy guardrails across the Management Group hierarchy.
AAD borrows a lot of the concepts and terminology associated with Microsoft’s traditional, on-premises Active Directory; however, there are some fundamental differences:
•The available authentication mechanisms: AAD supports web-friendly mechanisms such as SAML, OAuth, OpenID and WS-Federation, but not traditional AD mechanisms such as Kerberos and NTLM.
•There are no Group Policies and Group Policy Objects (GPOs) in AAD: it focuses on user identity rather than machine management (although limited capability to managed Windows 10 devices via AAD Join is available). AAD Domain Services (AAD DS) must be used if an organisation has a requirement for traditional domain joins and management by GPO.
•It is flat in structure: there are no domains, Organisational Units (OUs) or ‘forests’ in AAD, and organisations would need to look to AAD DS to maintain more familiar structures.
Users can be created directly within AAD or via synchronisation with existing identity repositories. The AD Connect tool offers a variety of options for synchronising AAD identities with on-premises identities. Once within AAD, users can be allocated the access rights that they require via groups. It should be noted that the synchronisation of identities between on-premises AD and AAD stores a hash of the AD password hash within AAD and not the actual password hash, i.e. compromise of the AAD hash would not support pass the hash132 attacks targeting on-premises resources. However, having the authentication hashes within AAD would provide Azure consumers with a backup authentication mechanism if they are currently using on-premises AD as their authentication provider. Indeed, the NCSC goes further and recommends the use of Cloud-native authentication via AAD over the use of ADFS, including password synchronisation, for hybrid environments, as documented here (albeit in the context of Office 365):
www.ncsc.gov.uk/blog-post/securing-office-365-with-better-configuration.
As with AWS, Azure supports Multi-Factor Authentication (MFA) as part of its wider conditional access capability. Azure offers a variety of MFA options including SMS tokens, other forms of soft tokens and OATH133 hardware tokens (in preview at the time of writing). Conditional access134 enables organisations to move towards ‘zero trust’ approaches; it does this by supplementing authentication decisions with additional considerations, including the nature and location of the device from which the user is requesting access.
AAD offers some advanced capabilities relating to the management of machine identities including managed identities.135 Managed identities abstract away the problem of having to create and manage identities for Azure resources (e.g. virtual machines) by automatically creating such identities within AAD alongside the associated credentials. The managed identities service takes away the pain associated with creating and managing credentials for nonhuman actors, but the consumer must be willing to place complete trust in the strength of the identities and passwords created for those identities by the Azure platform.
AAD also offers other identity services for Business to Consumer (B2C) and Business to Business (B2B) purposes that make use of the underlying AAD technology; AAD can, therefore, also offer identity management services for your hosted applications.
Google Cloud platform and identity
GCP uses Google Accounts as the main identity store to provide user identities to those developing for, or operating on, the GCP. The Google accounts for an organisation's users are then added to their GCP Organization via the Google Cloud Identity service.
Identities can be synchronised from an existing identity repository through the use of the Google Cloud Directory Synchronisation (GCDS) capability.136
Cloud IAM137 is the mechanism used to manage the access of those Google Accounts granted access to the relevant GCP resources via Cloud IAM policies. Cloud IAM allows policies to be applied at all levels of the GCP hierarchy: ‘organisations’, ‘folders’, ‘projects’ and ‘resources’.
GCP supports a variety of multi-factor authentications via the Cloud Identity service, including U2F hardware security keys, the Google technology-focused Titan Security Key and the Google Authenticator application. If a GCP consumer decides to use a third-party identity provider service, the authentication mechanism will be determined by the authentication mechanisms supported by that identity provider. It should be noticed that the Cloud Identity service can also be used to manage end user identities, i.e. the identities of those using an application hosted on the GCP.
This section has highlighted that the identity management capabilities offered by the hyperscale IaaS providers are mature and that they offer flexible, configurable approaches towards the provisioning and management of user identities relating to both the Cloud platforms themselves and their use by the applications hosted on those platforms.
Validate
The validate service grouping is responsible for checking that a user's claim to be able to access a service is legitimate. The validate service grouping contains two conceptual services: authenticate and authorise. The authenticate service validates that the user credentials presented in an access request (e.g. a password or a token-generated number sequence) matches the credentials associated with the user. The authorise service validates that a user has been granted permission to access the resource (e.g. data, system or function) that the user is attempting to access. So, authentication is focussed on validating the user whereas authorisation is focussed on validating their access.
Authenticate
When it comes to the application that you are choosing to host on an IaaS service, you have free rein to decide upon the most appropriate authentication mechanism. Example mechanisms could include traditional username/password authentication, certificate-based authentication, token-based authentication, or the use of federated identity management techniques such as OpenID. I provide more detail about OpenID in the section describing the federate service.
However, from a security purist perspective, you could question the true merit of implementing an application-level authentication mechanism that is stronger than the authentication mechanism protecting the operating system and underlying infrastructure. If you lose trust in the underlying infrastructure, then you can have little faith in the operating systems and applications it hosts.
So, from an authentication perspective, you have a number of areas to address: authentication to the Cloud platform (covered in the previous section), authentication to the operating system on the virtual machines on that platform and, finally, authentication to the application and/or APIs that you have built upon this stack.
Concerning the operating system, there is little to prevent you from implementing whatever strength of authentication control you require; for example, you could choose single factor, multi-factor or SSH authentication mechanisms. This is one of the strengths of the IaaS model: consumers can choose what they need based on their own appetite for risk and compliance requirements. However, one risk that must be considered is the unfortunate tendency of IaaS consumers to embed security credentials within their virtual machine images, particularly where those machine images include processes that need to communicate with other services. This can become a major issue if an IaaS consumer decides to share a machine image with other Cloud platform users. Do not embed your security credentials within your machine images; instead, make use of secret management solutions like those previously described in the secure development section.
Authorise
The authorise service is responsible for authorising access to a resource. In the context of a hosted application, the authorise service dictates the requirements for authorisation to data or functionality. In the context of the underlying IaaS, the authorise service dictates the requirements for authorisation to add, delete or modify IaaS resources (compute, storage, etc.) or users.
In order to perform authorisation, you would normally require:
•A set of resources that will be protected;
•A set of authorised users to whom access will be granted;
•A directory in which to store users and their access privileges;
•A policy that dictates who can access resources and what levels of access will be granted, e.g. create, read, update and delete (CRUD); and
•A filter service to enforce that policy.
I've used the conceptual services from the SRM in the above bullets. From a logical service perspective, you would expect to use more common industry terms associated with identity and access management such as policy information points, policy decision points and policy enforcement points.

Figure 25: Authorisation flow
Figure 25 shows a typical authorisation sequence. The steps shown in this example sequence are:
1.An authenticated user requests access to an information resource and the request is intercepted by a policy enforcement point (PEP).
2.The PEP queries a policy decision point (PDP) as to whether the access request is authorised.
3.The PDP queries a directory service to obtain details of the authenticated user, such as group membership, access privileges et cetera.
4.The PDP queries a policy information point (PIP) to request information on the access policy to the resource concerned (for example, to obtain the list of groups allowed to access the resource, any time-based or IP-address constraints etc.).
5.The PDP applies the policy based on the information it has obtained and informs the PEP of the access decision.
6.The PEP now allows the user to access the resource (or not if the request has not been authorised).
From a technology perspective, these interactions would likely involve a number of different HTTP(S) requests transporting SAML tokens backwards and forwards. I am not going to go into further detail of the technologies providing authorisation capabilities – there are enough textbooks dedicated to identity and access management that I could not possibly do the topic justice in one short section.
However, there is a Cloud-specific element to the authorisation process described in Figure 25. Whilst it is not necessary to host each of the PEP, PDP, PIP, et cetera on separate servers, hosting certain functions on separate servers can provide Cloud consumers with additional flexibility. For example, if you have concerns about hosting the personal data contained within a directory on a Cloud server, then you could host the directory, PIP and PDP on-premises. In this scenario only the PEP and the resource itself are hosted within the Cloud – and they may not require knowledge of the sensitive personal data that you are keeping on-premises.
Similarly, you could host the directory, PIP, and PDP services on one Cloud and then manage access to all your other Cloud services from this single (although I would suggest replicated) authorisation Cloud. There are a number of Cloud-based security as a service offers that could deliver this logical capability, e.g. Okta.
Another option for delivering authorisation services would be to adopt a federated approach, e.g. through the use of protocols such as OAuth.
Federate
Federation has already been mentioned a number of times in this chapter, primarily relating to authentication and authorisation, but without much detail of what it means. Federated identity management is a trust-based approach to identity management whereby an organisation trusts the authentication and/or authorisation decisions made by another organisation. Federation can be useful to prevent users constantly having to re-enter their credentials every time they begin to interact with a new service. Similarly, federation can be useful to enable smoother interaction across services. For example, to provide one service with access to information held by a separate service.
When talking about federated authentication, two terms that commonly occur are ‘identity provider (IdP)’ and ‘relying party (RP)’. Relying parties are sometimes known as ‘service providers’ (SPs). The relying party is the application or service to which a user is attempting to authenticate. If the service incorporates a federated authentication scheme then, at this point, the RP will ask its IdP whether or not the user is authenticated. If so, the RP will now provide the user with access. If not, the user will typically be prompted to authenticate using the RP's own authentication mechanisms.
Federation can be used to deliver a number of benefits in addition to providing single sign-on (SSO) across services. Consider the case of a community Cloud hosting a shared application. One approach to delivering identity management for such an application would be to have a centralised directory containing accounts for each user from the community requiring access to the service. However, this approach has some negative implications:
•The community needs to find someone to administer this directory;
•The users now have yet another set of credentials to either remember or, in the case of a physical token, keep safe; and
•Access management processes will be laborious, requiring authorisation from within the source organisation and then actioning (possibly via another authorisation step) at the centre.
An alternative would be to adopt a federated approach, whereby the shared application trusts the authentication decisions made at each of the organisations that comprise the community. So, the shared application becomes an RP and each member of the community becomes an IdP. This approach has a number of advantages:
•Authentication decisions are made by each community organisation;
•There is no central user directory – each community organisation controls the user information it allows to leave its secure domain; and
•Access management processes occur at a faster rate – accounts can be created at the IdP and then replicated to the RP using, for example, SPML138 or SCIM.139
Of course, there are some compromises associated with this approach; e.g. members of the community must trust that the other members implement appropriately strong authentication mechanisms. There can also be a degree of pain involved in the implementation of the cryptographic services needed to establish the technical trust between the different parties. Finally, significant effort needs to be expended to establish the governance structures needed to establish the trust infrastructure, e.g. to set appropriate standards for authentication. However, overall I prefer this federated approach to the more centralised model due to the greater flexibility it offers to the users and the ability of the community organisations to retain control of their own information.
Two commonly implemented federation technologies in the web space are OpenID140 (which provides federated authentication) and OAuth141 (which provides federated authorisation). You may well find that you already have an OpenID Identity without necessarily realising it; Google, Facebook, Microsoft, Twitter, PayPal and others all make use of OpenID. As OpenID is a federated authentication protocol, it enables you to use an OpenID IdP to sign in to other services that have signed up to trust your OpenID IdP. The link below provides guidance on how you can use Google as an OpenID IdP for your application, i.e. you can enable users to log in to your application with their Gmail credentials via OpenID Connect and OAuth 2.0.:
https://developers.google.com/identity/protocols/OpenIDConnect.
OpenID Connect solves similar problems to the previous version of the protocol (OpenID 2.0); however, this newer iteration has moved towards the use of JSON Web Tokens (JWT) and REST-based approaches and has moved away from the more complex XML-based structures of the previous version.
Before implementing OpenID you will need to make sure that you are comfortable that the registration and authentication capabilities on offer through your OpenID provider of choice are in-line with your requirements for these services. This is one of the advantages of the security architecture approach that I introduced earlier – you should have service contracts for the authentication and registration services that provide the relevant functional and non-functional requirements to inform your decision. If you are not content with the registration processes on offer at the OpenID IdP, then you could consider adding additional registration checks when users first access your application. You could also consider the use of a secondary authentication mechanism to supplement OpenID authentication should you wish to avoid placing complete trust in OpenID.
OAuth 2.0 is a complementary, but different, protocol to OpenID Connect. OpenID Connect is, in fact, a build upon OAuth 2.0; as stated on the openid.net website, "OpenID Connect 1.0 is a simple identity layer on top of the OAuth 2.0 protocol."142 OAuth 2.0 provides a framework for delegated authorisation but it does not specify how to achieve authentication or require specific formats for the access tokens that are passed via OAuth. This is where OpenID Connect comes in: it defines the format of the access tokens and authentication requirements.
OAuth 2.0 is used to provide access to specific services within a wider application; for example, allowing another application to access your Facebook status updates but without providing that application with your Facebook password, or with access to other aspects of Facebook. As with OpenID, OAuth has been widely adopted by the major web companies; OAuth service providers include Facebook, Google and Microsoft. As an example, Figure 26 illustrates how Google have adopted OAuth and OpenID within their accounts service.
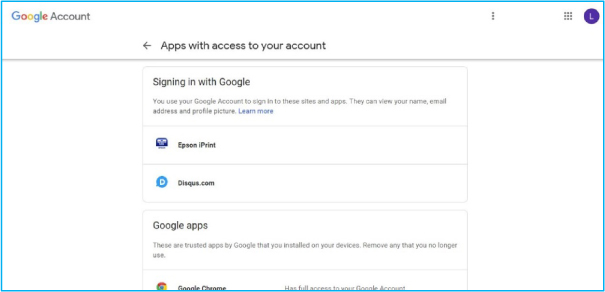
Figure 26: Google account
From Figure 26, you can see that I have allowed both Epson iPrint and Disqus to use Google as an identity provider, i.e. they will allow me access provided I am currently logged into my Google account.
Figure 27 outlines this process from the perspective of a web service that relies upon Google for account sign-up and authentication (in this case Disqus).

Figure 27: Disqus
From the login/sign-up screen, if the user clicks on the ‘G’ button (for Google), they will be presented with the following screen (Figure 28); from there, the user must choose which of their Google accounts they wish to use (there may be multiple options).

Figure 28: Selecting a sign-in account
Once an account has been selected, the user is required to authenticate to Google prior to the services being linked for authentication services as shown in Figure 29.

Figure 29: Creation of Disqus account
At this point, Disqus sends an email to the selected Google email account with a confirmation link that must be accessed to finalise the process. The Disqus account is now created, and the linkage between Disqus and the selected identity providers is available within the account settings, as shown in Figure 30.

Figure 30: Disqus “Connected Accounts”
OAuth 2.0 allows users to share access to specific information and functionality at their own discretion; this is a benefit for users and, potentially, for their application providers if they are subject to privacy regulations that require the demonstration and management of user consent.
Currently, OpenID is probably the most widely implemented federated authentication solution, but it is not the only solution.
Okta – mentioned earlier in the section on authentication service – is able to act as an IdP through its support for security assertion markup language (SAML).143 Consumers can, therefore, implement multi-factor authentication by using federation across all of their applications via a Cloud-based service. Okta is not the only service space of this kind, and competition is heating up as enterprises look to adopt approaches based on zero trust networking; in this model, access to services is based on the identity of the user and their access device rather than on the network from which the access is being requested. The Google BeyondCorp whitepapers144 arguably set the standard for zero trust networking (building on the Jericho Forum principles relating to de-perimeterisation), and the GCP is able to support this approach via Google Identity and the Google Identity Aware Proxy. Other implementations of the zero trust networking approach towards authentication and authorisation are also available from the likes of Duo Security145 and Ping Identity.146
Cloud consumers can also implement federated authentication solutions to allow their users to authenticate to Cloud-based services using an on-premises identity provider. In this scenario the Cloud-based applications are the relying parties. This can enable Cloud consumers to make use of existing investments in authentication and identity management technologies. At the same time, such an approach also enables Cloud consumers to present their users with transparent access to services, whether they are hosted on-premises or on-Cloud. Furthermore, by hosting the IdP on-premises, organisations are effectively keeping the keys to their Cloud-based applications and data within their secure domain (although this protection could be bypassed should the underlying Cloud infrastructure suffer from a weakness lower down the technology stack, e.g. in the hypervisor). This approach to federated identity management is most common when implementing SaaS delivery models, particularly if the consumer makes use of multiple SaaS providers. An increasingly popular option for those organisations moving towards an Azure-based future is to make use of Azure AD as the main identity repository and then control access to SaaS services via Cloud App Security (other Cloud Access Security Brokers can also be used) and to on-premises applications via the AAD App Proxy.
So far I have written about how the federation service may be implemented within an application that you may wish to host on an IaaS Cloud. Some IaaS providers also support federated identity management such that you can manage your virtual infrastructures whilst authenticated via federation. Amazon allow you to create temporary security credentials that you can then distribute to users that have been authenticated via your existing authentication service. Once your users are in possession of these temporary security credentials, they can then access the AWS Management Console directly without being prompted for a password. The lifetime of the temporary security credentials are defined at the time of creation. The link below describes how to create temporary security credentials using the Amazon Security Token Service (STS):
https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_temp.html.
Once you have understood the nature of AWS temporary security credentials (and also the AWS services that support such credentials), you can consider using this approach to secure access to AWS resources, including via the AWS Command Line Interface (CLI) and APIs. The link below provides a description of this approach:
https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_temp_use-resources.html.
As Amazon themselves note, just because the security credentials are temporary it does not mean that the actions of those with such credentials will not be permanent. For example, should a user with temporary credentials, e.g. via assuming a privileged IAM Role, start a new Amazon Machine Image, this virtual server will continue to run (and be charged) even after the temporary credentials of the user have expired.
Similar temporary credential approaches can be used on the GCP,147 whilst Azure adopts a different route and allows temporary access via the Just in Time access controls offered by the Azure Privileged Identity Management (PIM) service.148
Policy
The policy service (within the access management grouping) of the SRM is responsible for the setting of policy for access management decisions. Policies are required to dictate which users (individuals, application accounts, service accounts, etc.) are allowed access to an information resource (data, function, server, etc.) and what privileges they are allowed to that resource (e.g. create, read, update and delete, etc.). PIP were mentioned during the section on authorisation which explained their role in the authorisation process. At the logical and physical levels, policy may be stored centrally on a PIP; however, in many cases policies will be physically implemented at a more local level. For example, firewall policies are more than likely (and recommended) to be stored separately to access management policies at the application level.
There is little more to be said about policy in this context – your policies for access to information resources must be dictated by your business requirements. The business requirements must indicate which types of users require access to which information resources and at what level this access should be granted.
The policy service interacts with a number of other SRM services, notably authentication, authorisation and filter to perform many of the tasks commonly associated with information security, i.e. preventing unauthorised access to information, or, in a positive light, enabling authorised access to information.
Filter
The filter service within the SRM serves as a good illustration of what is meant by a conceptual service. The filter service enforces the policy requirements. As it's a conceptual service, it does not dictate how filters should be delivered at the logical or physical level. Why is it a good illustration? Because the filter service tells you what you need to do – deny or allow access – but does not tell you how to do it, or how to enforce it. Although it may not look it at first sight, this is a good thing. Consider the many different areas where you need to control access, e.g.:
•Data centre
•Storage
•Operating system
•Database
•Application
•Container
•API
•Cloud service
•Network
•Hypervisor
Each of these aspects will require their own physical set of filtering technologies. At the lowest level, data centres will require suitable mechanisms to prevent unauthorised access to the equipment that they host. With a public Cloud this is an issue for the CSP; with community and private Clouds this issue may be one for the Cloud consumer. Similarly, physical and administrative access to the low-level storage devices is typically within the purview of the CSP in the context of a public Cloud.
When you get to the data level, e.g. which users (including applications) are allowed access to which data, things start to become more complicated. For example, Amazon offers a number of different storage services including the Simple Storage Service (S3) and Elastic Block Storage (EBS). Access to data stored within the AWS S3 storage can be secured in a number of ways as highlighted at:
https://docs.aws.amazon.com/AmazonS3/latest/dev/access-control-overview.html.
In summary, access can be controlled at an S3 bucket level or at an object level basis and these controls can be applied in a number of ways to enable sharing either just within your AWS account or across different AWS accounts. In response to the number of reported incidents in which consumers have accidentally opened access to their S3 buckets up to the Internet, AWS has also implemented some specific options to block public access to S3 buckets.149 AWS released Access Analyzer150 at re:Invent 2019, a tool that enables AWS users to more easily identify those with access to S3 buckets and to then remediate any excessive or unexpected access.
The key point here is that the enforcement point is still within the realm of the CSP (in this case, AWS). The consumer gets to decide which users can access the device (via the policy), but the enforcement of that access control (via the filter) sits with the CSP.
Now, Cloud consumers also require logical and physical filter services at levels other than those concerning data. What about the network? The majority of the network access controls in the IaaS environment are provided by the CSP. The CSP infrastructure is directly connected to the Internet; it is the responsibility of the CSP to ensure that Internet-based attackers cannot compromise the underlying infrastructure. They must implement appropriate firewalling and intrusion prevention technologies.
However, what about your virtual servers? Once you have your Cloud server instance, you may be placed directly onto the Internet. If you do not have a host-based firewall then you are now at the mercy of whatever network-based controls the CSP may have implemented. From an AWS EC2 perspective, this is a relatively safe position to be in as the AWS firewall capability offered as part of the standard AWS service adopts a default deny position, i.e. all network traffic to the instance will be dropped. This means that it is the responsibility of the consumer to open up access to the network ports required to run their service.
Azure Virtual Machines are in a similar position as the default Network Security Groups (NSGs) block inbound Internet traffic; however, implementors should be aware that all outbound traffic is allowed by default. GCP takes a somewhat different approach, and the pre-populated firewall rules associated with the default network of new virtual machines allow inbound access for both SSH and RDP to all instances by default. GCP users should look to tighten up these default rules during implementation. GCP does offer other mechanisms for enforcing a perimeter around Cloud-hosted resources via VPC Service Controls151 functionality, and this complements the controls offered by their more identity-centred IAM capabilities. Once again though, this question of network access control is really a policy question, with the filter aspect being implemented by the relevant CSP(s).
Once you reach the level of the operating system (OS), the responsibility for implementation of filter services sits firmly with any consumer working with IaaS Clouds. Consumers can implement host-based firewalls, host-based intrusion prevention systems, operating system ACLs on file system objects and any other traditional operating system-level access control mechanism. Given that the servers are operating within the Cloud, it is worth considering what controls are available over and above those that would be installed in an on-premises environment. A good example may be the potential to implement your own virtual private Cloud using a tool such as Cohesive Networks VNS3.152 VNS3 enables a Cloud consumer to implement an SSL-encrypted overlay network that effectively prevents CSP staff from being able to access or view the consumer's data whilst it is within the encrypted overlay. CSP staff would still have the ability to close down instances should they wish, and to see data entering and leaving the overlay, be that to and from the Internet or to and from the underlying storage devices, although they would not have access to the traffic flowing across the overlay network itself. Such tools can be a useful filter with regard to CSP staff who are otherwise fairly impervious to the controls available to Cloud consumers. VNS3 could be viewed as a form of a Cloud Workload Protection Platform (CWPP).
At the application level, you can consider the use of a WAF to provide a filter if you are using an IaaS Cloud to host a web service. There is little difference here between applications hosted on-premises and those hosted within a Cloud; at the application level, the WAF is there to filter out malicious traffic lurking within the HTTP(S) communications. Figure 22 illustrated the potential of using a Cloud-based WAF service to protect your IaaS-hosted web applications. Cloud consumers can, of course, choose to implement their own WAFs as virtualised network appliances within their IaaS environments; alternatively, they can consider using any WAF capabilities offered by the Cloud platforms themselves, such as AWS WAF153 or Azure Application Gateway.154 The benefit of using the services offered by the Cloud provider is that the consumer no longer needs to concern themselves with building and operating their own redundant, resilient WAF solutions; the downside is that the CSP offers may not be as fully featured as the best-in-breed WAF solutions.
One of the issues to bear in mind when considering the logical elaboration, and subsequent physical implementation, of the conceptual filter service is that any such controls must be appropriate to the task at hand. Consider a traditional firewall. Most firewalls are very good at controlling the network communications that traverse them; dictating allowed sources, the allowed destinations, the allowed types of traffic between the sources and destinations and, often, ensuring that the traffic adheres to the relevant protocol specifications. Unfortunately, this is often insufficient for today's complex applications. Consider a web application processing XML-encoded information transported via SSL/TLS encrypted communications. A traditional firewall will be blind to the nature of the traffic flowing over the encrypted channel; even if it could see the XML on the network, it most likely would not be able to parse the XML so as to understand whether the traffic was malicious. A more appropriate choice for a filter service would be an XML firewall that is designed to parse XML, perform basic checks (such as schema validation) and to spot more elaborate attacks, such as embedded malicious binaries. XML firewalls are particularly relevant where a Cloud consumer is building a web services based information system. I mentioned a number of such XML firewalls products in the section on the integrity service earlier in this chapter, namely:
•Axway AMPLIFY (www.axway.com/en/products/api-management)
•CA API Gateway (www.ca.com/gb/products/ca-api-gateway.html)
•Forum Systems (www.forumsys.com)
At the database level, consumers should consider the use of specific database security products. Such products are able to understand the queries and commands being passed back and forth between the database server, application servers and administrators. The database firewall – also known as database activity monitoring (DAM) – market is now mature, with many of the early market leaders having been acquired by more established entities. Examples include:
•Guardium (purchased by IBM: https://www.ibm.com/security/data-security/guardium);
•Secerno (purchased by Oracle: www.oracle.com/us/products/database/security/index.html); and
•Sentrigo (purchased by McAfee: www.mcafee.com/us/products/database-security/index.aspx).
Where you have a need to monitor the activities of your database administrators, or you wish to lock down the database access available to application accounts, then you should be looking towards database activity monitoring products as part of your filter service. As with other potential realisations of the filter service, the major CSPs are now also starting to deliver some basic DAM capabilities within their Cloud services, e.g. Azure SQL Database Threat Detection155 and the more manual approach that AWS Aurora offers via integration with CloudWatch for monitoring.156
One of the major differences between a physical deployment and a virtual deployment is the addition of a new attack surface – the hypervisor. In a public Cloud environment the security of the hypervisor is firmly within the realm of the CSP. In a private or community Cloud, the consumer is in the position to be able to specify the security controls protecting the hypervisor and controlling the inter virtual machine traffic flowing across it. In a VMware environment, there are a number of different options for providing this capability, e.g.:
•VMware vSphere Platinum and AppDefense (www.vmware.com/uk/products/appdefense.html)
•Trend Micro Deep Security (www.trendmicro.co.uk/products/deep-security/index.html)
•HyTrust (www.hytrust.com)
Understandably, the VMware AppDefence and software-defined security products only work with the VMware hypervisor. These products make use of the visibility available within the hypervisor to identify known good application traffic and, subsequently, to flag and/or block traffic that falls outside of its baseline. Neither Deep Security nor Hytrust actually sit within the hypervisor so their available visibility is quite limited when compared with that available to VMware tooling.
In essence, the VMware tooling sits beside the hypervisor, monitoring and controlling the traffic flows between the hosted virtual machines and can also be used to control the network to and from the hypervisor, protecting the hypervisor itself. These products typically allow you to group virtual machines into zones (or application stacks) and then control the network traffic between these zones (although they also work on an individual virtual machine basis). This approach allows you to mimic a more traditional n-tier architecture by using different zones rather than different physically separate network segments. Concerns have been raised by some, including the UK government’s National Technical Authority for Information Assurance (NCSC), that little assurance should be placed in these products. The primary reason for such concerns relates to the fact that compromise of the hypervisor itself would render these controls worthless; they could be bypassed through reconfiguration at the hypervisor level. As such, NCSC and others would not recommend using these tools to provide a security barrier between domains at different levels of trust, but that they may be used within a security domain.
Another valid concern is that, whilst with a traditional n-tier architecture you may consider implementing different firewall products at the different tiers, with a virtualised environment you will be limited to one selected product. Figures 31 and 32 below illustrate the differences between a traditional n-tier application architecture and a virtualised alternative making use of a hypervisor-based firewall.

Figure 31: Traditional n-tier architecture
Figure 32: A zoning approach
Figure 31 shows that the traditional approach makes use of three different firewall products (to guard against the failure of a single product) and that it has the ability to control traffic across each tier boundary. Figure 32 shows that, instead of physically separate firewalls and servers, we now have a set of virtualised servers grouped into different zones with the separation (filter) being provided by hypervisor-based firewalls.
My guidance is to consider your levels of risk and act accordingly – do you believe that the assets within your virtual environment are valuable enough to merit an attacker 'giving away' a valuable zero day (i.e. unpublished) hypervisor exploit? If so, then you need to invest in suitable levels of physical separation within your application (e.g. implement a physically separate demilitarised zone). If not, then you may be willing to rely upon the filter services that hypervisor-based technologies can deliver.
Similar considerations exist within the public Cloud world. Cloud consumers can choose to rely upon the CSP-provided firewalling and network segmentation capabilities that are equivalent to VMware protections (e.g. Security Groups and VPCs in the AWS world, or Network Security Groups and VNets in the Azure world) or else look to implement their own virtualised network appliances (VNAs) such as firewalls. There are a number of trade-offs to be considered regarding this choice between Cloud-native capability and VNAs. The two main considerations are:
1.Complexity: relying upon the CSP-native capabilities can lead to a complex mesh of security groups that require ongoing maintenance; consequently, organisations may view the relative simplicity of a VNA within a transit VPC/VNet as a more straightforward proposition from a management perspective. This may be particularly true if that firewall is API-enabled because this means that the rule-base and policy can be articulated as code as easily as the CSP-native controls.
2.Defence in depth: implementing a separate VNA on top of the Cloud provider native capability could be viewed as providing an extra level of security (although, in reality, should the inter-virtual private Cloud networking be compromised, it is questionable whether the VNA would provide any extra defence in practice).
Either way, the Cloud consumer has a number of options regarding the realisation of the filter service for controlling access into and out of their IaaS-hosted application.
Security governance
With the IaaS service model, the primary delivery responsibility for security governance remains with the Cloud consumer. The Cloud consumer retains primary delivery responsibility for the security management, risk management and coordinate services. The personnel security service is a joint delivery responsibility, reflecting that CSP staff have access to the infrastructure whilst consumer personnel have access to the virtualised environment. The security governance services from the SRM are shown in Figure 33.
Figure 33: Security governance services
Security management
The security management service provides many of the traditional concepts and functions of an IT security practice. These include:
•Determining overall security strategy;
•Conducting the mandated privacy activities that impact upon policy;
•Setting policy to meet the strategy and privacy needs;
•Disseminating policy;
•Enforcing policy; and
•Assuring policy implementation within technical design and operational procedures.
The SRM’s strategy service is key to determining the wider shape of the overall security solution and for aligning the shape of that solution to the wider needs of the business. This includes the shaping of the security function itself, e.g. deciding whether to use traditional centralisation or a more distributed and delegated structure that suits more agile ways of working. The strategy service interacts with the ownership service to ensure that ownership of the strategy is allocated and that the residual risks associated with the strategy are also appropriately owned and tracked by stakeholders within the wider business.
The privacy services relate to the requirements of the GDPR and other similar regulations. The GDPR has a requirement for organisations to consider "privacy by design", i.e. to consider privacy issues at the very start of application design in order to guide the development of that application. The output of a privacy impact assessment157 will provide a set of high priority requirements relating to strategy and policy for a Cloud-hosted application.
The SRM’s policy service has two aspects: policy research and policy design. The policy research service provides the capability to research recent developments regarding compliance (including any outputs from the privacy services), technology and evolving business requirements concerning any application that will be hosted on an IaaS Cloud. The output from the research capability can then be passed to the policy design service which outputs security policies relevant to the application. Policy design is likely to be something of an iterative process. For example, an initial security policy may help to dictate which IaaS providers are suitable to host your application, perhaps based on their geographical locations. The next iteration of the application security policy may then incorporate some specific aspects relating to the CSP, e.g. which of the individual offerings of the CSP are approved for implementation, which are not judged suitable, et cetera. These security policies can then be used to drive more technical policies such as those required for access management purposes, personnel security vetting, encryption standards, et cetera.
Unfortunately, one of the areas where information security often fails is in the translation from information security policy through to actual implementation. The SRM includes two services aimed at ensuring that all relevant individuals are aware of the policy requirements (disseminate) and that the policy requirements are enforced (enforce). Dissemination can be achieved via security awareness training (for consumer personnel) and via provision of appropriate guidance documentation. The goal of the dissemination service is to ensure that everyone understands their security obligations and, as importantly, to try and convince them that following the policy is in their own best interests. The enforcement capability is necessary to shepherd those elements of the organisation (or user community) that may not buy into the message that is promulgated via the disseminate service. Enforcement can be achieved centrally or through the deployment of local security champions to the business units and project teams implementing on Cloud services. Placing security champions within agile scrum teams can be a very effective way of embedding security into the products near the beginning of the development lifecycle. The enforcement capability must have appropriate links to personnel functions, in particular the discipline service, to ensure that adequate and proportional sanctions are in place for those that may choose not to adhere to policy. The enforcement function also requires explicit support from authoritative figures within the consumer to provide policy implementation with the necessary impetus.
The final capability provided by the security management service grouping is that of assurance. From a security management perspective, assurance refers to assuring that the requirements of the relevant security policies have been adopted within the technical design of the application and the associated operating procedures. Wider security assurance testing activities are covered elsewhere (e.g. compliance and vulnerability management). The assurance capabilities require sufficient expertise in the Cloud technologies in question in order to be effective. The staff involved must be able to understand whether a proposed technical architecture meets the policy requirements. A lack of understanding will likely equate to failure to meet policy and so increase the possibility of a security or compliance breach. Whilst I am of the view that Cloud computing is an evolution rather than a revolution, the security impacts of this evolution on underlying technical delivery, service-oriented design and global compliance requirements are significant. Organisations should consider the training requirements of any existing assurance function. An ‘old-school’ security assurance function could de-rail any number of Cloud deployments based on misunderstanding of the underlying technologies or an overly risk averse approach. The cost of training and up-skilling of security personnel should be outweighed by the benefits of enabling a risk-managed (rather than risk-averse) approach to adopting Cloud services.
Risk management
I do not intend to write reams of text describing the risk management service grouping. Most organisations should have adopted a preferred approach to risk management and there is little reason why such approaches should not be extended to the Cloud. At a high level, a risk management approach should consist of the following steps:
1.Threat model
Identify the threat sources and threat actors looking to compromise the application and/or data. Document the threats (competitors, hackers, governments, employees, CSP staff, journalists, environmental threats, accidental threats, etc.) to your assets. A number of different threat actor catalogues are available including the IRAM v2 Common Threat List and the Intel Threat Agent Library.
Classify your assets in terms of their value to the business. Value could be measured in terms of confidentiality, integrity and availability for example. Value could also be measured in monetary terms.
3.Inform
Involve the relevant organisation personnel. Asset owners should be involved in assessing and agreeing the classifications associated with their assets. Suitable safeguards should be built into the process to ensure that the human tendency to overvalue your own assets is adequately managed (e.g. through involving higher levels of management with sight across the assets concerned).
4.Assess
Assess the attack surface of your application. Consider which potential vulnerabilities could realistically be exploited by each previously identified threat. Consider the business impacts of a vulnerability being exploited by a threat actor. Bear in mind that the business impact may be dependent upon the threat actor concerned. For example, a well-meaning customer may identify a potential vulnerability in your application and inform you through a published notification process. A black-hat hacker may identify the same vulnerability and post an exploit on the Internet. The same asset, the same vulnerability but the impact is different because of the actions of the threat actor. Document your risks (e.g. asset, vulnerabilities, threats, impacts) in an accessible manner. There are a number of published risk analysis methodologies such as IRAM2158, FAIR159 and OCTAVE.160
5.Treat
Using the risk register produced by the assess service, treat each risk in turn appropriately. Standard treatments would include accept, transfer, mitigate or avoid. It is perfectly acceptable to simply accept risks that fall within the tolerance of your organisation. Not every risk must be mitigated or avoided. Document the proposed treatment of each risk in a risk treatment plan – ensure that any mitigations are explained to a level of detail sufficient to allow the overall risk owner to judge the suitability of the mitigation.
6.Accredit
An appropriate figure within the organisation should review the risk analysis and associated risk treatment plan and confirm that they are content that all relevant risks have been identified and appropriately treated. This final sign-off effectively provides a security accreditation for the application. Some organisations may wish to extend this process such that formal accreditation is only offered after penetration testing has been completed and the necessary remediation undertaken.
This type of formal accreditation is unlikely to be effective in a digital (Mode 2) environment. A more appropriate mechanism in this environment would be to develop a pre-approved set of templates (e.g. machine images, AWS Landing Zones et cetera) – perhaps made available within a mandated service catalogue161 – and a development pipeline (e.g. code analysis tools); projects should be allowed to progress as long as they operate within the pre-approved security guardrails. In this model, the accreditation process is much more of a ‘trust, but verify’ function – should any subsequent audits or penetration tests indicate that the pre-approved processes were avoided or ignored, then appropriate action should be taken; however, the default posture is one of trusting your teams to do the right thing. Spot checks should, of course, be conducted to verify that the authorised processes are being followed and indeed, such checks may well be mandated by other compliance requirements.
Personnel security
Within the SRM, I have marked personnel security as being a joint delivery responsibility when considering the IaaS service model. This reflects the fact that CSPs must hire, manage and release staff in a manner that does not place the security of their customers' data or service at undue risk. By the same token, IaaS consumers must also ensure that their users, application developers, system administrators, database administrators, et cetera are also appropriately managed.
I suggested three main services within the SRM:
1.Vetting;
2.Discipline; and
3.Training.
The vetting service (in combination with compliance and other services via associated service contracts) dictates the levels of background checking needed prior to employing personnel or moving personnel from a less sensitive role to a more sensitive role. The UK Centre for the Protection of National Infrastructure offers some useful guidance on pre-employment checks (at www.cpni.gov.uk/content/security-pre-screening), whilst there is a British Standard on security vetting (BS 7858:2012); the latter was originally targeted for those organisations working in the security industry but is, in fact, more widely applicable.162 Background checks can vary in intrusiveness from simple identity verification through to extensive interviews with acquaintances of the individual concerned together with financial and criminal record checks.
From a consumer perspective, vetting processes for their users accessing Cloud-based resources should be no different to those used elsewhere within their organisation. Consumers must, however, content themselves that the vetting processes adopted by the IaaS providers match the levels of rigour that they themselves require, or else accept a known residual risk.
The discipline service ensures that appropriate sanctions can be enforced against users and/or employees who fail to meet their security obligations. As with the vetting process, consumers should simply adopt their existing disciplinary processes when implementing services in the Cloud.
The final personnel security service within the SRM relates to training. As noted earlier in this chapter, it is vital that your users receive appropriate training in order to make the best use of the new ways of working offered by Cloud computing. This is as true for security professionals as it is true for other IT professionals. Developers should receive training on the implications of working with their chosen IaaS provider, e.g. how they should secure Cloud storage, the appropriate forms of API authentication and authorisation, which form of database service is the most appropriate for their current needs, et cetera. If you do not train your developers on the security implications of working in a multi-tenant environment, do not be surprised if they leave your application, and so your organisation, exposed.
Security operations
The security operations service grouping is the last of the major elements of the SRM to be considered. Figure 34 shows the security operations section of the SRM.

Figure 34: Security operations
As can be seen from Figure 34, the security operations grouping includes a number of different capabilities:
•Monitoring
•Administration
•Incident management
•Threat intelligence
•Asset management
•Vulnerability management
•Change management
•Problem management
Within the IaaS SRM, monitoring is assigned to be a joint delivery responsibility. Whilst the consumer is responsible for security monitoring of everything from the operating system upwards, the CSP is responsible for security monitoring of the underlying physical infrastructure. The monitoring service grouping includes a number of different services to provide a cohesive approach to security monitoring. The log service is conceptually responsible for capturing the information required to identify (and then investigate) any security incident or to meet compliance-driven auditing requirements. Information must be captured at all relevant levels; this includes those areas within the control of the CSP such as that relating to the physical infrastructure (firewalls, network IPS, storage, etc.) and those areas that are the responsibility of the consumer (cloud provider API use, operating system, host-based IPS and firewalls, database, application, etc.). Historically, Cloud providers have limited the ability of their consumers to log network traffic, with consumers usually only able to capture packet headers of network traffic using tools such as VPC Flowlogs and Azure Network Security Group flow logs.
The providers have recognised that some consumers require more insight into the network traffic, including full packet capture, and now offer capabilities to support such packet capture namely:
•AWS VPC Traffic Mirroring163
•Azure Virtual Network TAP164
•GCP Packet Mirroring165
Consumers can now use these capabilities to copy network to traditional network intrusion detection solutions should they wish. I would recommend that consumers try to ascertain the levels of logging undertaken by their CSPs so that the entirety of the logging capabilities of a cloud solution is understood– the most likely source for this information is the ISO 27001 statement of applicability, output from a SOC2 Type II assessment, a CSA STAR entry or a ‘trust’ artefact produced by the CSP themselves.
Logging is only the beginning of a true security monitoring capability, the logged information must then also be securely stored166 in a forensically sound manner where possible (in case it must later be relied upon in court). The analyse service is responsible for identifying events of interest within the logged information. This is likely to involve the collection, normalisation and correlation of the logs from the different sources mentioned in the preceding paragraph. One advantage of the IaaS model, compared to the PaaS and SaaS models, is that consumers can often use the same security monitoring agents within their Cloud-based virtualised environment as they use within their own data centres. Depending on your willingness to accept security event information coming from outside of your trusted domain, you could also simply reuse existing collation and analysis points within your on-premises security architecture. If your posture is more risk averse, a separate collation point for information sourced from Cloud systems could be implemented, either on-premise or on-Cloud. To reduce costs, it may be prudent to implement a single collation and analysis point (subject to scalability) that is able to monitor events across all of your Cloud-based services. This logging and analysis point should be separated from your secure, trusted domain.
One of the challenges of Cloud monitoring relates to noise and data egress costs: the major CSPs charge for the transfer of data outside of their environments, and consumers can find themselves paying to export a lot of worthless data from their IaaS environments. This is leading some of the traditional security information and event management (SIEM) vendors to adopt more distributed and delegated approaches towards security monitoring; consequently, in many cases, local agents installed on the monitored IaaS environments only pass on a subset of the total information generated to the central stations. Cloud consumers now have the choice between more fully centralised logging and monitoring solutions and distributed solutions that are potentially more cost-effective.
Once the information has been collated, whether centrally or in a more distributed manner, it will usually need to be normalised in a common form to enable more effective correlation and analysis. The analyse service must then examine the logged and normalised information and highlight any events of interest – be these potential security incidents or other preconfigured events. The analyse service is increasingly making use of machine learning approaches whereby activity on the monitored environments is baselined, and anomalies from that baseline are identified as potentially malicious activities. Behavioural anomaly detection is a growing market and may be the most effective way of monitoring security in large Cloud-based environments. The major CSPs offer a degree of behavioural anomaly based detection and threat intelligence capabilities natively (e.g. AWS GuardDuty and Azure Advanced Threat Protection); these can then be aggregated into wider reporting solutions, such as AWS Security Hub or Azure Sentinel and the Azure Security Centre.
Once an anomaly, or other suspicious event, has been identified then the event management services should kick in. The purpose of the event management service is to recognise the next point of escalation for an event; this could be a case of no action required or escalation to either the incident management (for security issues) or problem management services. The final service within this pipeline is the report service and this service is as simple as it sounds – enable reports to be produced from the monitoring service. Both the raw log information and the output from the analyse service should be able to be securely produced and exported from the monitoring service via report. Threat hunting is also incorporated in the monitoring set of services. Threat hunting refers to the more advanced approach of identifying indicators of compromise (IOCs) for potential compromises and then looking for those IOCs within the collected log information; working on this basis of assumed compromise allows for an earlier detection of threats within your environments than is possible with more reactive approaches. AWS Detective, Azure Sentinel and GCP Backstory are useful sources of information for threat hunting purposes.
There are some IaaS-specific elements to the monitoring service grouping that consumers should consider:
•Communication channels must be available both to and from the CSP in the event of a security incident requiring one party to notify the other;
•Tools such as VMware AppDefense and others can be used to log and monitor the information flows across the hypervisor in private Cloud approaches;
•Traditional security agents(e.g. anti-malware), can also be configured and reused in the IaaS environment;
•Consumers need to investigate the logging options available within the specific Cloud services that they are adopting. Log information may be available beneath the operating system level. For example, whilst consumers cannot install physical network taps into Cloud provider environments, logging capabilities similar to these technologies may be available as outlined earlier, e.g. Azure virtual network TAP. For those consumers that do not require full packet capture, other capabilities are available to monitor traffic flows – both AWS and GCP offer a capability known as VPC Flow Logs, whilst Azure has the NSG Flow Logs option within the Network Watcher tool, and all of these monitor traffic flows. Separate logging information may also be available from the other ‘as a Service’ elements of the IaaS platform as well, e.g. storage. IaaS consumers should not consider themselves limited to the monitoring capabilities that they implement themselves at the operating system level.
Security monitoring is a vital part of any security regime. I view it as even more important where the services and data are hosted outside of your secure, trusted, domain.
Administration
The administration service grouping includes those activities typically associated with system administration roles – deploying new services, managing those services whilst in operation and then decommissioning and disposing of the relevant kit when the service reaches end of life. As the SRM reflects an application security architecture, the majority of these administrative tasks remain the primary delivery responsibility of the consumer in an SRM context. Whilst CSP staff are responsible for the physical deployment and management of the physical hardware, the consumer retains responsibility for the management and deployment from the operating system upwards (including their virtual networking). The administration service grouping includes the following services:
Secure channel
The secure channel service provides a secure communications path between the relevant system administrator and the server, database or application that they manage. In many cases, with IaaS services access to the console will likely be physically implemented via SSH. Some providers will also provide the ability to rent dedicated virtual private network connections into their virtualised environments, e.g. Azure ExpressRoute. From the operating system upwards it is the responsibility of the consumer to implement suitable secure communication channels for their administrators; I recommend the use of TLS or SSH encryption as a minimum for such activities. In many circumstances, Cloud consumers do not actually need to expose their administration ports, such as SSH and RDP, to the Internet. The AWS Systems Manager capability allows administrators to run operating system commands via the Systems Management Agent167; alternatively, Azure Security Centre's just-in-time168 administration feature can be used to automatically open up network access to the necessary management ports, following a request from an authenticated user who holds the necessary roles. The ability to remove Internet-facing SSH and RDP management ports significantly reduces the attack surface of IaaS-hosted virtual machines.
Manage
The manage service delivers the capabilities for the day-to-day administration activities, e.g. patching, with regard to operating systems, applications, et cetera. Consumers should consider how they wish to manage their Cloud-based services; do they wish to simply extend their existing processes or do they wish to adopt some more tailored services for operating with IaaS-based servers? I strongly advise against the simple lifting and shifting of tooling and processes from on-premises data centres into the Cloud; this can severely limit the ability of Cloud consumers to move towards DevSecOps approaches. Instead, consumers should consider automated Cloud management approaches, e.g. the use of AWS Config and Lambda to identify and automatically remediate configuration drift.
Deploy
The deploy service, much like the manage service, requires a number of underlying logical services to deliver the conceptual functionality of deploying new services on to a Cloud service. Many of these services would be drawn from other areas of the SRM including the risk management, testing, configuration management and architecture services. In addition to the deployment of virtual machine images, the deploy service would also be responsible for the deployment of application code on to the Cloud. This entails the usual processes around release management so as to ensure a smooth migration to a new or updated version of code.
Orchestrate
The orchestrate service relates to the need to coordinate change across different elements when operating on Cloud environments, particularly when moving towards automated deployment approaches through the use of an appropriate balance of Cloud-native capabilities and third-party tooling, such as Terraform, Puppet, Chef, Ansible, Packer, Spinnaker and Jenkins.
Given the ease with which virtual servers can be initiated, great care must be taken to manage the proliferation of unnecessary running images. This is similar to the well-known issue of image sprawl in virtualised environments. The difference in the Cloud environment is that unnecessary images will all be charged back to the consumer – pay-as-you-go is only advantageous if you are actually using the resources you have active.
Decommission
The decommission service is the polar opposite of the deploy service. Once an application or server has reached the end of its usefulness it should be decommissioned. The increased ease of releasing resources like storage and compute is one of the strengths of the Cloud model (and of other virtualisation models) over physical environments. However, decommissioning is a joint delivery responsibility. Consumers need to ensure that they have implemented formal procedures governing the decommissioning of Cloud-based applications and virtual servers. Given the simplicity of shutting down virtual servers in an IaaS environment it is easy to mistakenly take down a virtual environment which is still in use, either through accident or through misunderstanding of other applications making use of the same virtual infrastructure. Decommission is a joint delivery responsibility as it is only the CSP that can ensure that virtualised resources are released cleanly and that no information will leak from the releasing consumer to the next consumer making use of the same physical resources.
Consumers should content themselves with the statements provided by their CSPs regarding how they prevent information leakage when resources are released or when consumers decide to terminate their relationship with the CSP. If Cloud consumers are unwilling to simply trust the decommissioning approach of their CSP, then they can adopt the technique of ‘cryptoshredding’. Cryptoshredding refers to the encryption of data prior to its deletion, with the encryption key then being destroyed. Cryptoshredding mitigates the risk of the consumer's data being inadvertently made available to other tenants; as even if their data is not adequately destroyed, it is still unavailable to any other tenant due to its encrypted status.
Dispose
The dispose service is firmly within the domain of the CSP. In a private Cloud environment, the CSP and consumer may be one and the same. The purpose of the dispose service is to securely dispose of hardware or media when necessary, e.g. upon failure or reaching end of life. Consumers should be comfortable that their data will not risk entry into the public domain when, for example, their CSP disposes of, or recycles, their storage devices.
Change management
The change management service, at both the consumer and CSP levels, should follow normal established best practice as documented within ITIL®169 and elsewhere for more static Cloud-based environments. However, given the potentially volatile nature of Cloud services, e.g. rapid provisioning and subsequent release of resources, consumers adopting Cloud services must have change management processes that are capable of reacting to such change requests efficiently and effectively. The need to manage change does not disappear when moving to the Cloud; the challenge becomes managing change at a speed that does not compromise the flexibility and agility that the Cloud model offers. This necessity is one of the factors driving organisations towards the SecDevOps processes described in the secure development section of this chapter.
Problem management
As with change management, Cloud consumers and CSPs should adopt accepted best practices with regard to problem management. It is vital that appropriate communications mechanisms are in place to enable the appropriate allocation of responsibilities in the event of a problem. For example, many CSPs maintain web pages and Twitter feeds dedicated to the status of their services (as described in the section on availability).
Such information feeds enable their consumers to identify when a problem is within their remit to fix or when the problem is wider, affecting the IaaS as a whole. CSPs must also offer adequate support contacts to enable their consumers to raise new problems as and when they occur.
Vulnerability management
The vulnerability management service is responsible for delivering a cohesive and comprehensive approach to managing the vulnerabilities associated with a Cloud-based application. In terms of the remediation activities that may result from vulnerability management processes, such activities will be passed to the relevant risk management and then change management services elsewhere within the SRM. The vulnerability management service in the SRM is primarily targeted at identifying appropriate vulnerability management approaches and then implementing such approaches to actively identify vulnerabilities.
The potential for embedding some of your vulnerability assessment activities into the development lifecycle was explored within the secure development lifecycle. It should be noted that the Cloud providers also offer tooling that can help to inform the vulnerability management process; for example, the AWS Inspector170 service allows virtual machine images to be instrumented to report configuration issues, whilst the GCP Security Scanner171 can detect common web application security issues in applications hosted on the App Engine, Compute Engine or Kubernetes Engine. Azure Secure Score allows similar vulnerabilities in configuration to be identified in the Azure environment, whilst Azure Compliance Manager172 will identify deviations from set compliance standards (e.g. ISO 27001, CIS benchmarks or NIST 800-53) from both the provider and consumer perspectives.
It is also possible to run traditional vulnerability assessment tools, such as those from Tenable and Qualys, across the Cloud-hosted environment. Using this established tooling has the advantage that it also tends to integrate with the Cloud provider security consoles such as Security Hub, Security Center and Command Center.173
At a high level, similar vulnerability management strategies should be adopted whether an application is being hosted on-premises or on the Cloud. Ideally, applications should be tested during development, prior to entering production and then again at regular intervals (depending upon criticality of the application) and after any major changes to the application or underlying components, such as databases or operating systems. The problem with this approach when working with public Cloud providers is the potential need to obtain specific permission to conduct vulnerability assessments, or more intrusive penetration testing, of your application. This may delay your ability to conduct testing depending on how slick the penetration authorisation process is at your CSP.
The CSPs are gradually relaxing requirements concerning the pre-approval of penetration testing activities; however, this is definitely an area in which Cloud consumers need to check the latest guidance prior to commencing any such testing. The latest guidance for the major CSPs can be found at the links below:
•AWS: https://aws.amazon.com/security/penetration-testing/
•Azure: www.microsoft.com/en-us/msrc/pentest-rules-of-engagement
Google take a more relaxed approached to penetration testing by their clients:
If you plan to evaluate the security of your Cloud Platform infrastructure with penetration testing, you are not required to contact us. You will have to abide by the Cloud Platform Acceptable Use Policy and Terms of Service, and ensure that your tests only affect your projects (and not other customers’ applications). If a vulnerability is found, please report it via the Vulnerability Reward Program.174
If organisations are more interested in simple configuration checks (e.g. checking for missing patches and common misconfigurations, both of the Cloud platform and the hosted operating systems), such checks could be performed via Cloud-specific tooling to avoid having to notify the CSP. For example, the major CASB vendors offer the capability to check Cloud platform configurations against the relevant CIS benchmarks.175 There are a variety of other open-source Cloud-specific vulnerability assessment tools available to supplement more traditional tooling; these include: Azucar,176 for testing Azure environments;
•Prowler177 and Scout2,178 for testing AWS environments; and
•CloudCustodian179 for checking against all three main providers.
The major Cloud providers all offer native solutions to perform checks against the relevant CIS benchmarks, namely:
•AWS Security Hub180;
•Azure Security Center Regulatory Compliance; Dashboard181; and
•GCP Security Health Analytics182.
Once vulnerabilities have been identified, the vulnerability management must then route these vulnerabilities, via the coordinate service, to those other services in the SRM that are able to decide on the most appropriate course of action.
Incident management
Consumer incident management services for Cloud-based applications should follow traditional processes. Within the SRM, I have defined five services relating to incident management:
1.Respond
2.Investigate
3.Action
4.Close
5.Exercise
The respond service represents the initial triage aspect of incident response. The event management service identifies events of interest, and, if they are suspected of indicating a security incident, these are passed on to the incident response service. The incident response service should also take feeds from CSP status updates and wider industry alerts (e.g. widespread virus or worm activity) and respond appropriately. The respond service must, therefore, incorporate an appropriate communications mechanism to receive and obtain notifications, pass these notifications on to the relevant staff and initiate the creation of an incident log.
The other main responsibility of the respond service is the establishment of an appropriate group of incident response personnel drawn from the relevant technical areas (e.g. operating system, database and application) and an appropriate business stakeholder authorised to make decisions on behalf of the business. Any decision regarding closing down an affected service, or leaving it running pending an investigation, must be made with full knowledge of any business impacts; these decisions should be at the discretion of the business and not the technology function. In the DevSecOps world, it may be possible to automate certain incident response activities based on predefined runbooks. This automation could be performed via SOC Orchestration and Automated Response (SOAR) tooling, such as IBM Resilient183 and Demisto,184 or through more bespoke automation via AWS Lambda or Cloud Functions. In the latter approach, certain event types could trigger an automated response function that could, in turn, alter API-enabled security tooling; for example, a function could automatically add an IP address to a block list within a DDoS prevention tool or firewall. This situation also serves as a good example of why automation needs to be applied in an informed manner: no organisation would want to accidentally blacklist all their customers because of an overactive incident response function.
The investigate service forms the main part of the overall incident response service in which automation is not deemed to be an appropriate response. The initial tasks of the investigate service are to contain the incident and then gather sufficient evidence to enable an informed investigation to take place. In order to contain an incident you must have thorough knowledge of the application at hand and the systems with which the application interacts – each of which may also have been compromised. How can you obtain such knowledge? Examine logs for indications of unusual activity; conduct passive (i.e. non-interactive) investigations where you can (e.g. output from network monitoring tools or native tooling such as AWS Detective) so as not to tip-off an attacker that their activities have been detected. All aspects of this initial investigation must be recorded in the incident log. Once you have an idea of the likely scope of the compromise, you can make a more informed decision as to how the incident should be contained. For example, whether or not the service should be taken down, whether certain communication lines should be cut to prevent further contamination or whether everything should be left as-is to enable further monitoring of the activities of the attacker. Once you have decided upon your containment approach it is time to begin a more thorough investigation.
Where possible, evidence should be obtained in a forensically sound manner; this may not be possible in an IaaS environment without extensive cooperation from your CSP. Whilst working in an IaaS environment may make obtaining forensically sound evidence more problematic, there is a definite advantage to being able to snapshot a virtual machine image that is suspected of being compromised and then analysing the captured image. As ever with incident response you need to be aware of the consequences of your activities: keep an eye out for a change in behaviour from the attacker that may indicate a realisation that they have been detected. A deeply embedded attacker may be quite destructive in their attempts to cover their tracks if they believe they have been spotted which could lead to a longer down-time and more drawn-out investigation. Ensure that you capture all of your activities in the incident log – such logs are vital evidence should you wish to pursue criminal charges against the attacker. The purpose of the analyse phase is to identify exactly which information assets have been affected, the attack vector(s) used to infiltrate the service and then to identify how to remediate the exploited vulnerabilities to enable clean-up to begin without fear of the service being immediately re-hacked when it is brought back online. This is where the benefit of the virtual image snapshot really comes into its own. The snapshot should contain volatile aspects, e.g. process address spaces in memory that can be difficult to obtain in a physical server without destroying the evidence. Once you are content that you have obtained all of the information you need about the compromise, then it is time to pass the relevant information across to the action service.
The action service is responsible for implementing the activities needed to recover from an incident. This will include working with other services within the SRM, e.g. problem and change management, vulnerability management, and others, to make the necessary changes in a managed manner. Likely activities will include the restoration of data from backups known to be good (i.e. dating from before the compromise), application of security patches to operating systems or vulnerable applications and the conducting of some penetration testing to ensure that the system is no longer vulnerable to the identified attack vector(s). In an IaaS scenario, those recovering from an incident may have other options available to them; for example, if it was running a blue/green model, an organisation could switch to the stack it believed to be clean.
Similarly, organisations could simply decide to close down an infected environment and bring up an entirely new stack using fresh images. Cloud-based organisations also have the option to regularly tear down and rebuild their IaaS environments as a precautionary measure: attackers do not like having their operations continually disrupted.
The close service is responsible for ensuring that the incident log has been completed satisfactorily and storing the log in a secure manner. Furthermore, the close service must also capture any lessons learned during the incident response process; this helps to avoid making the same mistakes twice, but also helps to spread good practice where certain activities have been shown to work well.
The exercise service provides organisations with the opportunity to practice their incident response preparedness. Exercises can range from tabletop discussions of the plans through to intense full-on real-time incident simulations. When running incident simulations, it is essential to involve all of the stakeholders required in a genuine incident response; such response teams may range from a service desk user all the way to the CEO and include external support from legal services and public relations experts, depending on the nature of the incident. These incident simulations work best when the required stakeholders are unaware of what is happening until they are brought into the simulated response.
However, it is critical that such responses are contained; respondents should not take actions on live systems, and no news of the simulated incident should end up in the media. The Cloud does offer an opportunity for a very realistic incident simulation; it has the ability to spin up a replica of the production environment, and a cyber test range can be established within this for running such exercises. These test ranges can be short to contain costs but they can provide much better insight into the capabilities available to incident responders and, even more importantly, insight into the gaps in those capabilities.
Asset management
The asset management service grouping reflects the need for a consumer to account for its information assets, even where those assets reside in an IaaS Cloud.
The first aspect of the asset management service grouping is the catalogue service. The purpose of the catalogue service is to establish an asset register containing the information assets relevant to the application; this register should include references to the relevant virtual machine images, relevant storage locations, relevant software images, et cetera. Identifying Cloud-based assets can be a challenge if Shadow IT has been allowed to flourish within an organisation and it may be necessary to use tools like Cloudmapper185 to obtain better visibility of your Cloud-based environment. Cloud provider native tools, such as AWS Trusted Advisor186 and Azure Advisor,187 can also help consuming organisations obtain better visibility of their Cloud-based assets and, subsequently, to optimise associated costs, usage and security.
A variety of enterprise asset management tools now include cloud provider plug-ins and/or connectors to enable asset discovery within cloud environments, e.g. both ServiceNow and JIRA Service Desk (via the Insight plug-in) can identify and catalogue cloud assets.
The next aspect of the asset management is the license service – many software vendors offer specific licensing terms for implementation in Cloud services. Consumers must ensure that they have the correct licenses for operating their software in a virtualised Cloud environment. Consumers should carefully investigate the terms and conditions of software that they plan to implement to examine whether or not the license terms are appropriate for a Cloud implementation. For example, how do the terms and conditions account for the elasticity inherent in the Cloud? Do your vendors charge for maximum peak usage or on a pay-as-you-go basis? Do your vendors charge on a per virtual machine or virtual core basis? Do your vendors even support implementation in a Cloud environment?
Configuration management is as important in an IaaS (or other virtualised) environment as it is when dealing with physical hardware. One aspect that must not be forgotten when dealing with IaaS Clouds is that of patching of currently redundant images. Given the elastic nature of Cloud services it may be that machine images are de-activated and then stored for future use after a spike in usage. Alternatively, those using Cloud services for development and test purposes may not require their images to be constantly active. The issue here is that these currently inactive images could present a security risk to your virtualised infrastructure when they are activated if they contain unpatched vulnerabilities. From this configuration management perspective, the adoption of blue/green style approaches may help because, in these methods, patches are continually applied and tested and the environments are only switched over when stability has been proven.
However, configuration management is not just about patching. It is important to know the overall state and usage of your IaaS services not only from a security perspective but also from a billing reconciliation perspective. Cloud is normally charged on a pay per use basis, consumers should check every so often that these charges are accurate.
Information Rights Management (IRM) and Data Loss Prevention (DLP) are different but closely related services. IRM enables providers to control what users can do with the information that they are entitled to access; for example, IRM could be used to prevent the printing of documents or the opening of documents on certain classes of devices. DLP enables providers to prevent data leaking out of the selected environment. IRM can form an element of an overall DLP solution. One example of an IRM is the Azure Information Protection (AIP)188 solution which is a Cloud-native way of delivering information rights. AIP allows organisations to scan their information assets and, if they hold the correct licence (currently E5), to automatically apply a classification to the scanned information. Controls of usage, such as the prevention of distribution via email, can then be applied to that information to provide a completely Cloud-based IRM solution.189
Conclusion
This chapter has provided some practical advice with respect to the implementation of the security services described within the SRM in an IaaS environment. In addition to the guidance provided in this book, consumers should also consider the guidance provided by the CSPs themselves. Most CSPs now offer whitepapers or sections of their website describing their security capabilities, for example:
•https://aws.amazon.com/security/
•https://cloud.google.com/security/overview/whitepaper
I recommend that those considering the use of a CSP closely examine the information that they provide on their security processes and that they take advantage of any offers to provide further detail, even if they are under an NDA.
99 https://aws.amazon.com/vmware/.
100 https://aws.amazon.com/controltower/.
101 https://aws.amazon.com/solutions/aws-landing-zone/.
102 https://docs.microsoft.com/en-gb/azure/cloud-adoption-framework/reference/azure-scaffold.
103 https://azure.microsoft.com/en-gb/services/blueprints/.
104 http://azure.microsoft.com/en-gb/services/azure-lighthouse/.
105 www.wired.com/story/notpetya-cyberattack-ukraine-russia-code-crashed-the-world/.
106 https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_policies_scp.html.
107 www.blackducksoftware.com/.
108 www.whitesourcesoftware.com/.
110 https://azure.microsoft.com/en-gb/services/key-vault/.
111 https://aws.amazon.com/secrets-manager/.
112 https://docs.aws.amazon.com/systems-manager/latest/userguide/systems-manager-parameter-store.html.
113 https://cloud.google.com/secret-manager/docs/overview.
114 This is why CWPP sits within the Integration element of the SRM.
115 Although some security products have undergone more transformation towards becoming Cloud-native than others.
116 https://docs.microsoft.com/en-gb/azure/security/fundamentals/antimalware.
118 www.menlosecurity.com/weaponized-documents.
119 https://downdetector.com/.
120 The Azure Site Recovery service can be used to automate the cross-region (or on-premises to cloud) failover of virtual machines, https://docs.microsoft.com/en-gb/azure/site-recovery/site-recovery-overview.
121 https://aws.amazon.com/message/41926/.
122 https://docs.ukcloud.com/articles/other/other-ref-sites-regions-zones.html?q=availability%20zone#introduction.
124 https://github.com/Netflix/SimianArmy.
125 https://tools.ietf.org/html/rfc6238.
126 Now rebranded as CTAP1 (Client-to-Authenticator Protocol) https://fidoalliance.org/specifications/.
127 In reality, some users will likely require access to both EC2 and S3 in order to configure persistent storage for EC2 services.
128 https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_policies_scp.html.
129 https://azure.microsoft.com/en-gb/services/active-directory/.
130 https://azure.microsoft.com/en-gb/features/management-groups/.
131 https://azure.microsoft.com/en-gb/services/azure-policy/.
132 https://attack.mitre.org/techniques/T1075/.
133 https://openauthentication.org/.
134 https://docs.microsoft.com/en-gb/azure/active-directory/conditional-access/concept-conditional-access-conditions.
135 https://docs.microsoft.com/en-us/azure/active-directory/managed-identities-azure-resources/overview.
136 https://support.google.com/a/answer/106368.
137 https://cloud.google.com/iam/docs/overview.
138 www.oasis-open.org/committees/tc_home.php?wg_abbrev=provision.
139 https://tools.ietf.org/html/rfc7644.
142 https://openid.net/connect/.
143 www.oasis-open.org/committees/tc_home.php?wg_abbrev=security.
144 https://cloud.google.com/beyondcorp/#researchPapers.
145 https://duo.com/docs/beyond-overview.
146 www.pingidentity.com/en/platform/platform-overview.html.
147 https://cloud.google.com/iam/docs/creating-short-lived-service-account-credentials.
148 https://docs.microsoft.com/en-us/microsoft-identity-manager/pam/privileged-identity-management-for-active-directory-domain-services.
149 https://docs.aws.amazon.com/AmazonS3/latest/dev/access-control-block-public-access.html.
150 https://docs.aws.amazon.com/AmazonS3/latest/user-guide/access-analyzer.html.
151 https://cloud.google.com/vpc-service-controls/.
152 www.cohesive.net/products/vns3net.
153 https://aws.amazon.com/waf/.
154 https://azure.microsoft.com/en-us/services/application-gateway/.
155 https://docs.microsoft.com/en-us/azure/sql-database/sql-database-threat-detection.
156 https://aws.amazon.com/about-aws/whats-new/2017/09/amazon-aurora-enables-database-activity-monitoring-with-cloudwatch-logs/.
157 Also commonly referred to as a Data Protection Impact Assessment.
158 www.securityforum.org/tool/information-risk-assessment-methodology-iram2/.
161 For example, https://aws.amazon.com/servicecatalog/ or https://azure.microsoft.com/en-gb/services/managed-applications/.
162 https://shop.bsigroup.com/ProductDetail/?pid=000000000030237324.
163 https://aws.amazon.com/blogs/aws/new-vpc-traffic-mirroring/.
164 https://docs.microsoft.com/en-us/azure/virtual-network/virtual-network-tap-overview.
165 https://cloud.google.com/vpc/docs/packet-mirroring.
166 The storage service resides within the hosting service grouping in the SRM.
167 https://docs.aws.amazon.com/systems-manager/latest/userguide/execute-remote-commands.html.
168 https://docs.microsoft.com/en-us/azure/security-center/security-center-just-in-time.
169 www.axelos.com/best-practice-solutions/itil/what-is-itil.
170 https://docs.aws.amazon.com/inspector/latest/userguide/inspector_introduction.html.
171 https://cloud.google.com/security-scanner/.
172 https://servicetrust.microsoft.com/ComplianceManager/V3.
173 https://docs.microsoft.com/en-us/azure/security-center/security-center-secure-score.
174 https://support.google.com/cloud/answer/6262505?hl=en.
175 www.cisecurity.org/cis-benchmarks/.
176 www.nccgroup.trust/uk/about-us/newsroom-and-events/blogs/2018/april/introducing-azucar/.
177 https://github.com/toniblyx/prowler.
178 https://github.com/nccgroup/Scout2.
179 https://cloudcustodian.io/.
180 https://aws.amazon.com/security-hub/.
181 https://azure.microsoft.com/en-gb/updates/regulatory-compliance-dashboard-in-azure-security-center-now-generally-available/.
182 https://cloud.google.com/security-command-center/docs/how-to-manage-security-health-analytics.
183 www.ibm.com/security/intelligent-orchestration/resilient.
185 https://duo.com/blog/introducing-cloudmapper-an-aws-visualization-tool.
186 https://aws.amazon.com/premiumsupport/technology/trusted-advisor/.
187 https://azure.microsoft.com/en-gb/services/advisor/.
188 https://azure.microsoft.com/en-gb/services/information-protection/.
189 An on-premises component is available to extend AIP to legacy data centres.