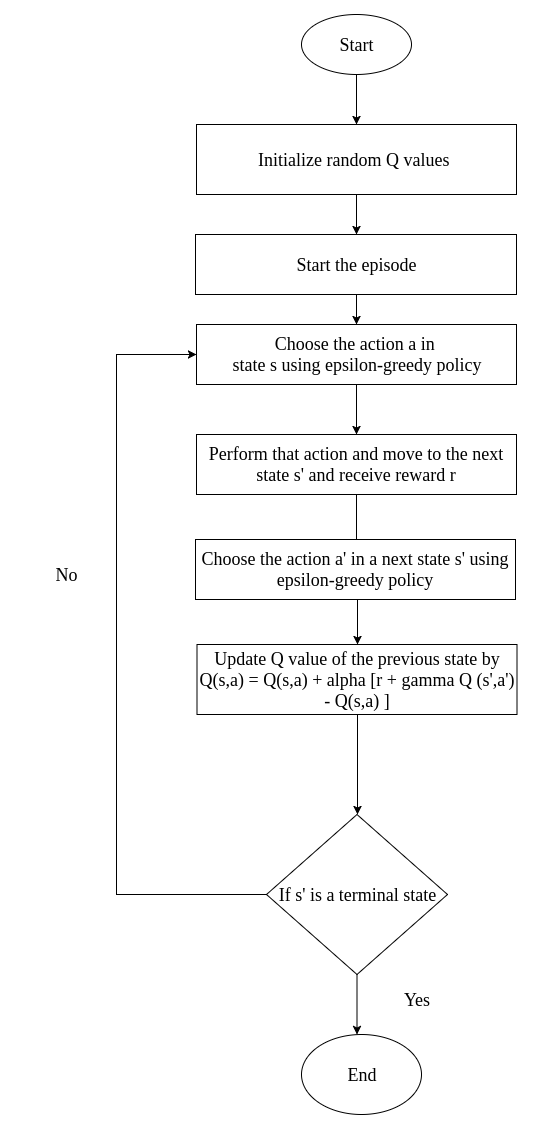
State-Action-Reward-State-Action (SARSA) is an on-policy TD control algorithm. Like we did in Q learning, here we also focus on state-action value instead of a state-value pair. In SARSA, we update the Q value based on the following update rule:
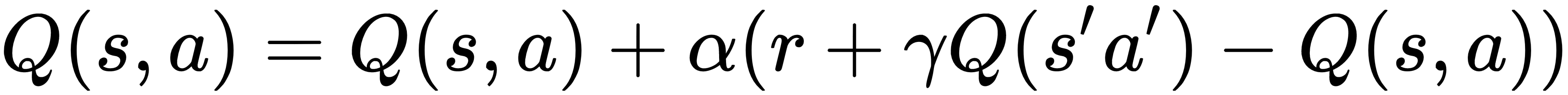
In the preceding equation, you may notice that there is no max Q(s',a'), like there was in Q learning. Here it is simply Q(s',a'). We can understand this in detail by performing some steps. The steps involved in SARSA are as follows:
- First, we initialize the Q values to some arbitrary values
- We select an action by the epsilon-greedy policy (
 ) and move from one state to another
) and move from one state to another - We update the Q value previous state by following the update rule
 , where a' is the action selected by an epsilon-greedy policy (
, where a' is the action selected by an epsilon-greedy policy ( )
)
Now, we will understand the algorithm step by step. Let us consider the same frozen lake example. Let us say we are in state (4,2). We decide the action based on the epsilon-greedy policy. Let us say we use a probability 1- epsilon and select the best action, which is right:

Now we are in state (4,3) after performing an action right in state (4,2). How do we update a value of the previous state (4,2)? Let us consider the alpha as 0.1, the reward as 0.3, and discount factor 1:

Q( (4,2), right) = Q( (4,2),right) + 0.1 ( 0.3 + 1 Q( (4,3), action)) - Q((4,2) , right)
How do we choose the value for Q (4,3), action)? Here, unlike in Q learning, we don't just pick up max ( Q(4,3), action). In SARSA, we use the epsilon-greedy policy.
Look at the Q table that follows. In state (4,3) we have explored two actions. Unlike Q learning, we don't select the maximum action directly as down:

We follow the epsilon-greedy policy here as well. We either explore with a probability epsilon or exploit with a probability 1-epsilon. Let us say we select probability epsilon and explore a new action. We explore a new action, right, and select that action:
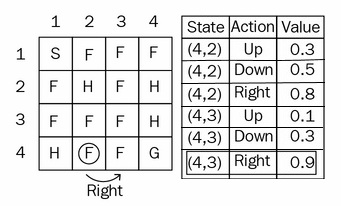
Q ( (4,2), right) = Q((4,2),right) + 0.1 (0.3 + 1 (Q (4,3), right) - Q ((4,2), right )
Q ( (4,2), right) = 0.8 + 0.1 (0.3 + 1(0.9) - 0.8)
= 0.8 + 0.1 (0.3 + 1(0.9) - 0.8)
= 0.84
So, this is how we get the state-action values in SARSA. We take the action using the epsilon-greedy policy and also, while updating the Q value, we pick up the action using the epsilon-greedy policy.
The following diagram explains the SARSA algorithm: