
To highlight the synergies between man and machine, AI is sometimes referred to as Augmented Intelligence (AI), putting the emphasis on the system to augment our abilities rather than replacing us altogether.
One area that is becoming increasingly popular—and of particular interest to myself—is assisted creation systems, an area that sits at the intersection of the fields of human-computer interaction (HCI) and ML. These are systems created to assist in some creative tasks such as drawing, writing, video, and music.
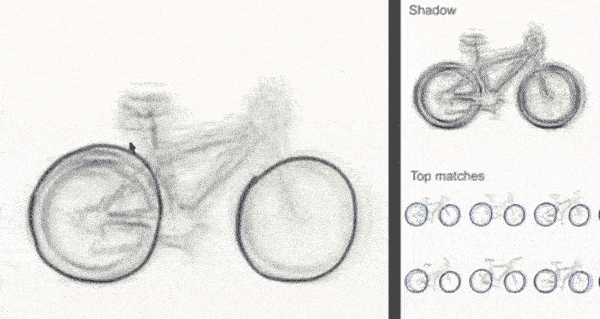
The example we will discuss in this section is shadow draw, a research project undertaken at Microsoft in 2011 by Y.J. Lee, L. Zitnick, and M. Cohen. Shadow draw is a system that assists the user in drawing by matching and aligning a reference image from an existing dataset of objects and then lightly rendering shadows in the background to be used as guidelines for the user. For example, if the user is predicted to be drawing a bicycle, then the system would render guidelines under the user's pen to assist them in drawing the object, as illustrated in this diagram:
As we did before, let's walk through how we might approach this, focusing specifically on classifying the sketch; that is, we'll predict what object the user is drawing. This will give us the opportunity to see new types of data, algorithms, and applications of ML.
The dataset used in this project consisted of 30,000 natural images collected from the internet via 40 category queries such as face, car, and bicycle, with each category stored in its own directory; the following diagram shows some examples of these images:

After obtaining the raw data, the next step, and typical of any ML project, is to perform data preprocessing and feature engineering. The following diagram shows the preprocessing steps, which consist of:
- Rescaling each image
- Desaturating (turning black and white)
- Edge detection

Our next step is to abstract our data into something more meaningful and useful for our ML algorithm to work with; this is known as feature engineering, and is a critical step in a typical ML workflow.
One approach, and the approach we will describe, is creating something known as a visual bag of words. This is essentially a histogram of features (visual words) used to describe each image, and collectively to describe each category. What constitutes a feature is dependent on the data and ML algorithm; for example, we can extract and count the colors of each image, where the colors become our features and collectively describe our image, as shown in the following diagram:

But because we are dealing with sketches, we want something fairly coarse—something that can capture the general strokes directions that will encapsulate the general structure of the image. For example, if we were to describe a square and a circle, the square would consist of horizontal and vertical strokes, while the circle would consist mostly of diagonal strokes. To extract these features, we can use a computer vision algorithm called histogram of oriented gradients (HOG); after processing an image you are returned a histogram of gradient orientations in localized portions of the image. Exactly what we want! To help illustrate the concept, this process is summarized for a single image here:

After processing all the images in our dataset, our next step is to find a histogram (or histograms) that can be used to identify each category; we can use an unsupervised learning clustering technique called K-means, where each category histogram is the centroid for that cluster. The following diagram describes this process; we first extract features for each image and then cluster these using K-means, where the distance is calculated using the histogram of gradients. Once our images have been clustered into their groups, we extract the center (mean) histogram of each of these groups to act as our category descriptor:

Once we have obtained a histogram for each category (codebook), we can train a classifier using each image's extracted features (visual words) and the associated category (label). One popular and effective classifier is support vector machines (SVM). What SVM tries to find is a hyperplane that best separates the categories; here, best refers to a plane that has the largest distance between each of the category members. The term hyper is used because it transforms the vectors into high-dimensional space such that the categories can be separated with a linear plane (plane because we are working within a space). The following diagram shows how this may look for two categories in a two-dimensional space:

With our model now trained, we can perform real-time classification on the image as the user is drawing, thus allowing us to assist the user by providing them with guidelines for the object they are wanting to draw (or at least, mention the object we predicted them to be drawing). Perfectly suited for touch interfaces such as your iPhone or iPad! This assists not just in drawing applications, but anytime where an input is required by the user, such as image-based searching or note taking.
In this example, we showed how feature engineering and unsupervised learning are used to augment data, making it easier for our model to sufficiently perform classification using the supervised learning algorithm SVM. Prior to deep neural networks, feature engineering was a critical step in ML and sometimes a limiting factor for these reasons:
- It required special skills and sometimes domain expertise
- It was at the mercy of a human being able to find and extract meaningful features
- It required that the features extracted would generalize across the population, that is, be expressive enough to be applied to all examples
In the next example, we introduce a type of neural network called a convolutional neural network (CNN or ConvNet), which takes care of a lot of the feature engineering itself.