
Now, let's add another feature to our model. Let's see whether adding the counts for words will help our model. We'll use a CountVectorizer to do this. Much like what we did with the site names, we'll be transforming individual words and n-grams into features:
from sklearn.feature_extraction.text import CountVectorizer vect = CountVectorizer(ngram_range=(1,3))
X_titles_all = vect.fit_transform(all_data['title']) X_titles_train = X_titles_all[train_index] X_titles_test = X_titles_all[test_index] X_test = pd.merge(X_test, pd.DataFrame(X_titles_test.toarray(), index=X_test.index), left_index=True, right_index=True) X_train = pd.merge(X_train, pd.DataFrame(X_titles_train.toarray(), index=X_train.index), left_index=True, right_index=True)
In the preceding lines, we have joined our existing features to our new n-gram features. Let's train our model and see whether we have any improvement:
clf.fit(X_train, y_train) y_pred = clf.predict(X_test) deltas = pd.DataFrame(list(zip(y_pred, y_actual, (y_pred - y_actual)/(y_actual))), columns=['predicted', 'actual', 'delta']) deltas
This code generates the following output:

And if we check our error again, we will see the following:
np.sqrt(np.mean((y_pred-y_actual)**2))/np.mean(y_actual)
The preceding code generates the following output:
![]()
So it appears that we have a modestly improved model. Let's add one more feature to our model—the word count of the title:
all_data = all_data.assign(title_wc = all_data['title'].map(lambda x: len(x.split(' '))))
X_train = pd.merge(X_train, all_data[['title_wc']], left_index=True, right_index=True)
X_test = pd.merge(X_test, all_data[['title_wc']], left_index=True, right_index=True)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
np.sqrt(np.mean((y_pred-y_actual)**2))/np.mean(y_actual)
This code generates the following output:
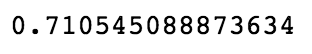
It appears that each feature has modestly improved our model. There are certainly more features we could add to it. For example, we could add the day of the week and the hour of the posting, we could determine whether the article is a listicle by running a regex on the headline, or we could examine the sentiment of each article. But this only just touches on the features that could be important for modeling virality. We would certainly need to go much further to continue reducing the number of errors in our model.
I should also note that we have done only the most cursory testing of our model. Each measurement should be run multiple times to get a more accurate representation of the actual error rate. It is possible that there is no statistically discernible difference between our last two models since we only performed one test.