
In their paper, Understanding the difficulty of training deep feedforward neural networks, Xavier Glorot and Yoshua Bengio showed that if the weights at each layer are initialized from a uniform distribution  , where
, where 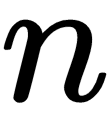 is the size of the previous layer, then for sigmoid activation function, the neurons of the top layers (closer to the output) quickly saturate to 0. We understand that due to the form of the sigmoid function, an activation value of 0 means very large weights and a backpropagated gradient approaching to zero. Extremely small gradient values slow down the learning process as the weights in earlier layers stop being updated or otherwise stop learning.
is the size of the previous layer, then for sigmoid activation function, the neurons of the top layers (closer to the output) quickly saturate to 0. We understand that due to the form of the sigmoid function, an activation value of 0 means very large weights and a backpropagated gradient approaching to zero. Extremely small gradient values slow down the learning process as the weights in earlier layers stop being updated or otherwise stop learning.
Therefore, what we want is to keep our weights uniformly distributed within the initially decided interval, that is, the variance of weights should remain unchanged as we travel from the bottom to top layers. This will allow the error to flow smoothly to the top layers and consequently, the network to converge faster during training.
In order to achieve that, Glorot and Bengio prove that for a symmetric activation function f with unit derivative at 0, the variance of weights at each layer must be as follows:
Here,  is the number of units to the layer under question, and
is the number of units to the layer under question, and  is the number of units at the following layer. This means that the weights must be sampled from the following uniform distribution:
is the number of units at the following layer. This means that the weights must be sampled from the following uniform distribution:

We can also sample the weights from a normal distribution with zero mean and the preceding variance.
For a ReLu activation function, it is proven by He et al. that the variances should instead be  .
.
Hence, the authors initialize their weights with a zero-mean Gaussian distribution, whose standard deviation (std) is  . This initialization is then called He initialization.
. This initialization is then called He initialization.
By default, TensorFlow uses the Glorot (xavier) initializer for most of its tf.layers, but we can override this and specify our own initialization. Here, we show an example of how to override the default initializer of the conv2d layer:
conv1 = tf.layers.conv2d(inputs=self.__x_, filters=64, kernel_size=[5, 5],
padding="same", activation=None,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
bias_initializer=tf.zeros_initializer())