
The least squares method is the original method to learn the parameters of the hyperplane that best approximates the output from the input data. As the name suggests, the best approximation minimizes the sum of the squared distances between the output value and the hyperplane represented by the model.
The difference between the model's prediction and the actual outcome for a given data point is the residual (whereas the deviation of the true model from the true output in the population is called error). Hence, in formal terms, the least squares estimation method chooses the coefficient vector  to minimize the residual sum of squares (RSS):
to minimize the residual sum of squares (RSS):
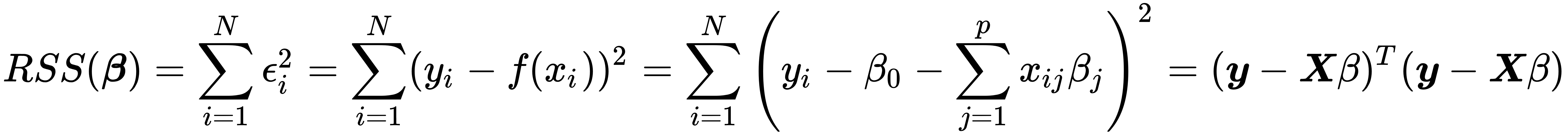
Hence, the least-squares coefficients  are computed as:
are computed as:

The optimal parameter vector that minimizes RSS results from setting the derivatives of the preceding expression with respect to  to zero. This produces a unique solution, assuming X has full column rank, that is, the input variables are not linearly dependent, as follows:
to zero. This produces a unique solution, assuming X has full column rank, that is, the input variables are not linearly dependent, as follows:

When y and X have been de-meaned by subtracting their respective means, represents the ratio of the covariance between the inputs and the outputs  and the output variance
and the output variance  . There is also a geometric interpretation: the coefficients that minimize RSS ensure that the vector of residuals
. There is also a geometric interpretation: the coefficients that minimize RSS ensure that the vector of residuals  is orthogonal to the subspace of
is orthogonal to the subspace of  spanned by the columns of X, and the estimates
spanned by the columns of X, and the estimates  are orthogonal projections into that subspace.
are orthogonal projections into that subspace.