
Given data on risk factors and portfolio returns, it is useful to estimate the portfolio's exposure, that is, how much the risk factors drive portfolio returns, as well as how much the exposure to a given factor is worth, that is, the what market's risk factor premium is. The risk premium then permits to estimate the return for any portfolio provided the factor exposure is known or can be assumed.
More formally, we will have i=1, ..., N asset or portfolio returns over t=1, ..., T periods and each asset's excess period return will be denoted  . The goals is to test whether the j=1, ..., M factors
. The goals is to test whether the j=1, ..., M factors 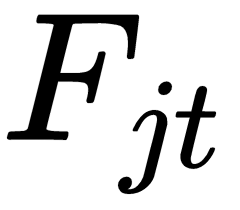 explain the excess returns and the risk premium associated with each factor. In our case, we have N=17 portfolios and M=5 factors, each with =96 periods of data.
explain the excess returns and the risk premium associated with each factor. In our case, we have N=17 portfolios and M=5 factors, each with =96 periods of data.
Factor models are estimated for many stocks in a given period. Inference problems will likely arise in such cross-sectional regressions because the fundamental assumptions of classical linear regression may not hold. Potential violations include measurement errors, covariation of residuals due to heteroskedasticity and serial correlation, and multicollinearity.
To address the inference problem caused by the correlation of the residuals, Fama and MacBeth proposed a two-step methodology for a cross-sectional regression of returns on factors. The two-stage Fama—Macbeth regression is designed to estimate the premium rewarded for the exposure to a particular risk factor by the market. The two stages consist of:
- First stage: N time-series regression, one for each asset or portfolio, of its excess returns on the factors to estimate the factor loadings. In matrix form, for each asset:

- Second stage: T cross-sectional regression, one for each time period, to estimate the risk premium. In matrix form, we obtain a vector
 of risk premia for each period:
of risk premia for each period:

Now we can compute the factor risk premia as the time average and get t-statistic to assess their individual significance, using the assumption that the risk premia estimates are independent over time: .
.
If we had a very large and representative data sample on traded risk factors we could use the sample mean as a risk premium estimate. However, we typically do not have a sufficiently long history to and the margin of error around the sample mean could be quite large. The Fama—Macbeth methodology leverages the covariance of the factors with other assets to determine the factor premia. The second moment of asset returns is easier to estimate than the first moment, and obtaining more granular data improves estimation considerably, which is not true of mean estimation.
We can implement the first stage to obtain the 17 factor loading estimates as follows:
betas = []
for industry in ff_portfolio_data:
step1 = OLS(endog=ff_portfolio_data[industry],
exog=add_constant(ff_factor_data)).fit()
betas.append(step1.params.drop('const'))
betas = pd.DataFrame(betas,
columns=ff_factor_data.columns,
index=ff_portfolio_data.columns)
betas.info()
Index: 17 entries, Food to Other
Data columns (total 5 columns):
Mkt-RF 17 non-null float64
SMB 17 non-null float64
HML 17 non-null float64
RMW 17 non-null float64
CMA 17 non-null float64
For the second stage, we run 96 regressions of the period returns for the cross section of portfolios on the factor loadings:
lambdas = []
for period in ff_portfolio_data.index:
step2 = OLS(endog=ff_portfolio_data.loc[period, betas.index],
exog=betas).fit()
lambdas.append(step2.params)
lambdas = pd.DataFrame(lambdas,
index=ff_portfolio_data.index,
columns=betas.columns.tolist())
lambdas.info()
PeriodIndex: 96 entries, 2010-01 to 2017-12
Freq: M
Data columns (total 5 columns):
Mkt-RF 96 non-null float64
SMB 96 non-null float64
HML 96 non-null float64
RMW 96 non-null float64
CMA 96 non-null float64
Finally, we compute the average for the 96 periods to obtain our factor risk premium estimates:
lambdas.mean()
Mkt-RF 1.201304
SMB 0.190127
HML -1.306792
RMW -0.570817
CMA -0.522821
The linear_models library extends statsmodels with various models for panel data and also implements the two-stage Fama—MacBeth procedure:
model = LinearFactorModel(portfolios=ff_portfolio_data,
factors=ff_factor_data)
res = model.fit()
This provides us with the same result:

The accompanying notebook illustrates the use of categorical variables by using industry dummies when estimating risk premia for a larger panel of individual stocks.