
One popular technique to control overfitting is that of regularization, which involves the addition of a penalty term to the error function to discourage the coefficients from reaching large values. In other words, size constraints on the coefficients can alleviate the resultant potentially negative impact on out-of-sample predictions. We will encounter regularization methods for all models since overfitting is such a pervasive problem.
In this section, we will introduce shrinkage methods that address two motivations to improve on the approaches to linear models discussed so far:
- Prediction accuracy: The low bias but high variance of least squares estimates suggests that the generalization error could be reduced by shrinking or setting some coefficients to zero, thereby trading off a slightly higher bias for a reduction in the variance of the model.
- Interpretation: A large number of predictors may complicate the interpretation or communication of the big picture of the results. It may be preferable to sacrifice some detail to limit the model to a smaller subset of parameters with the strongest effects.
Shrinkage models restrict the regression coefficients by imposing a penalty on their size. These models achieve this goal by adding a term to the objective function so that the coefficients of a shrinkage model minimize the RSS plus a penalty that is positively related to the (absolute) size of the coefficients. The added penalty turns finding the linear regression coefficients into a constrained minimization problem that, in general, takes the following Lagrangian form:
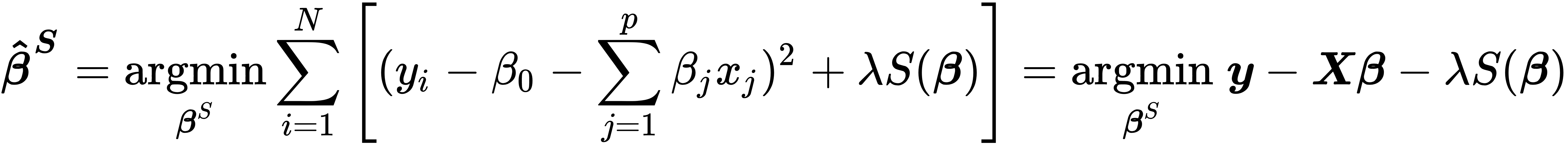
The regularization parameter λ determines the size of the penalty effect, that is, the strength of the regularization. As soon as λ is positive, the coefficients will differ from the unconstrained least squared parameters, which implies a biased estimate. The hyperparameter λ should be adaptively chosen using cross-validation to minimize an estimate of expected prediction error.
Shrinkage models differ by how they calculate the penalty, that is, the functional form of S. The most common versions are the ridge regression that uses the sum of the squared coefficients, whereas the lasso model bases the penalty on the sum of the absolute values of the coefficients.