
The linear models we studied in Chapters 7, Linear Models and Chapter 8, Time Series Models, learn a set of parameters to predict the outcome using a linear combination of the input variables, possibly after transformation by an S-shaped link function in the case of logistic regression.
Decision trees take a different approach: they learn and sequentially apply a set of rules that split data points into subsets and then make one prediction for each subset. The predictions are based on the outcome values for the subset of training samples that result from the application of a given sequence of rules. As we will see in more detail further, classification trees predict a probability estimated from the relative class frequencies or the value of the majority class directly, whereas regression models compute prediction from the mean of the outcome values for the available data points.
Each of these rules relies on one particular feature and uses a threshold to split the samples into two groups with values either below or above the threshold with respect to this feature. A binary tree naturally represents the logic of the model: the root is the starting point for all samples, nodes represent the application of the decision rules, and the data moves along the edges as it is split into smaller subsets until arriving at a leaf node where the model makes a prediction.
For a linear model, the parameter values allow for an interpretation of the impact of the input variables on the output and the model's prediction. In contrast, for a decision tree, the path from the root to the leaves creates transparency about how the features and their values lead to specific decisions by the model.
The following figure highlights how the model learns a rule. During training, the algorithm scans the features and, for each feature, seeks to find a cutoff that splits the data to minimize the loss that results from predictions made using the subsets that would result from the split, weighted by the number of samples in each subset:
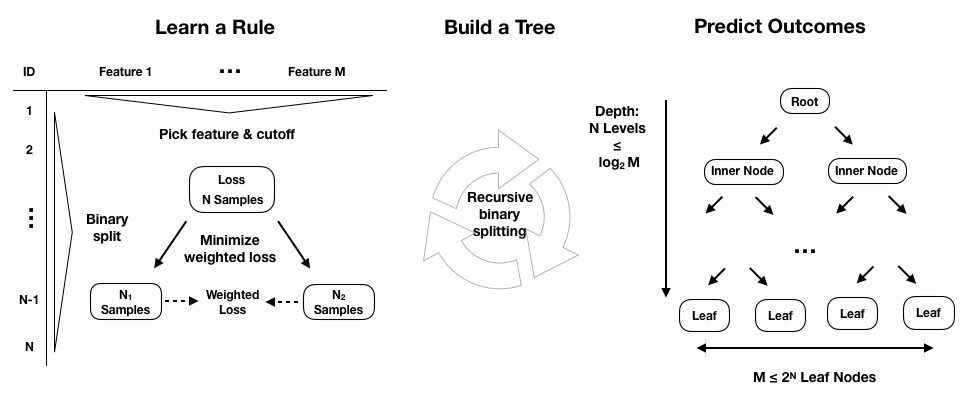
To build an entire tree during training, the learning algorithm repeats this process of dividing the feature space, that is, the set of possible values for the p input variables, X1, X2, ..., Xp, into mutually-exclusive and collectively-exhaustive regions, each represented by a leaf node. Unfortunately, the algorithm will not be able to evaluate every possible partition of the feature space given the explosive number of possible combinations of sequences of features and thresholds. Tree-based learning takes a top-down, greedy approach, known as recursive binary splitting to overcome this computational limitation.
This process is recursive because it uses subsets of data resulting from prior splits. It is top-down because it begins at the root node of the tree, where all observations still belong to a single region and then successively creates two new branches of the tree by adding one more split to the predictor space. It is greedy because the algorithm picks the best rule in the form of a feature-threshold combination based on the immediate impact on the objective function rather than looking ahead and evaluating the loss several steps ahead. We will return to the splitting logic in the more specific context of regression and classification trees because this represents the major difference.
The number of training samples continues to shrink as recursive splits add new nodes to the tree. If rules split the samples evenly, resulting in a perfectly balanced tree with an equal number of children for every node, then there would be 2n nodes at level n, each containing a corresponding fraction of the total number of observations. In practice, this is unlikely, so the number of samples along some branches may diminish rapidly, and trees tend to grow to different levels of depth along different paths.
To arrive at a prediction for a new observation, the model uses the rules that it inferred during training to decide which leaf node the data point should be assigned to, and then uses the mean (for regression) or the mode (for classification) of the training observations in the corresponding region of the feature space. A smaller number of training samples in a given region of the feature space, that is, in a given leaf node, reduces the confidence in the prediction and may reflect overfitting.
Recursive splitting would continue until each leaf node contains only a single sample and the training error has been reduced to zero. We will introduce several criteria to limit splits and prevent this natural tendency of decision trees to produce extreme overfitting.