
Latent Semantic Indexing (LSI, also called Latent Semantic Analysis) sets out to improve the results of queries that omitted relevant documents containing synonyms of query terms. It aims to model the relationships between documents and terms to be able to predict that a term should be associated with a document, even though, because of variability in word use, no such association was observed.
LSI uses linear algebra to find a given number, k, of latent topics by decomposing the DTM. More specifically, it uses Singular Value Decomposition (SVD) to find the best lower-rank DTM approximation using k singular values and vectors. In other words, LSI is an application of the unsupervised learning techniques of dimensionality reduction we encountered in Chapter 12, Unsupervised Learning to the text representation that we covered in Chapter 13, Working with Text Data. The authors experimented with hierarchical clustering but found it too restrictive to explicitly model the document-topic and topic-term relationships, or capture associations of documents or terms with several topics.
In this context, SVD serves the purpose of identifying a set of uncorrelated indexing variables or factors that permit us to represent each term and document by its vector of factor values.
The following figure illustrates how SVD decomposes the DTM into three matrices, two containing orthogonal singular vectors and a diagonal matrix with singular values that serve as scaling factors. Assuming some correlation in the original data, singular values decay in value so that selecting only the largest T singular values produces a lower-dimensional approximation of the original DTM that loses relatively little information. Hence, in the reduced version the rows or columns that had N items only have T<N entries.
This reduced decomposition can be interpreted as illustrated next, where the first M x T matrix represents the relationships between documents and topics, the diagonal matrix scales the topics by their corpus strength, and the third matrix models the term-topic relationship:
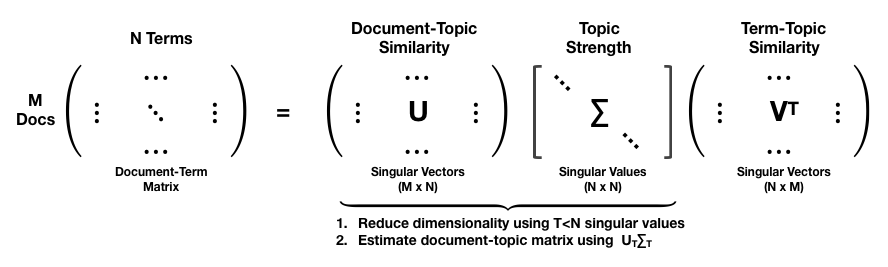
The rows of the matrix that results from the product of the first two matrices, UTΣT, corresponds to the locations of the original documents projected into the latent topic space.