
The gensim.models.doc2vec class processes documents in the TaggedDocument format that contains the tokenized documents alongside a unique tag that permits accessing the document vectors after training:
sentences = []
for i, (_, text) in enumerate(sample.values):
sentences.append(TaggedDocument(words=text.split(), tags=[i]))
The training interface works similar to word2vec with additional parameters to specify the Doc2vec algorithm:
model = Doc2vec(documents=sentences,
dm=1, # algorithm: use distributed memory
dm_concat=0, # 1: concat, not sum/avg context vectors
dbow_words=0, # 1: train word vectors, 0: only doc
vectors
alpha=0.025, # initial learning rate
size=300,
window=5,
min_count=10,
epochs=5,
negative=5)
model.save('test.model')
You can also use the train() method to continue the learning process and, for example, iteratively reduce the learning rate:
for _ in range(10):
alpha *= .9
model.train(sentences,
total_examples=model.corpus_count,
epochs=model.epochs,
alpha=alpha)
As a result, we can access the document vectors as features to train a sentiment classifier:
X = np.zeros(shape=(len(sample), size))
y = sample.stars.sub(1) # model needs [0, 5) labels
for i in range(len(sample)):
X[i] = model[i]
We will train a lightgbm gradient boosting machine as follows:
- Create lightgbm Dataset objects from the train and test sets:
train_data = lgb.Dataset(data=X_train, label=y_train)
test_data = train_data.create_valid(X_test, label=y_test)
- Define the training parameters for a multiclass model with five classes (using defaults otherwise):
params = {'objective' : 'multiclass',
'num_classes': 5}
- Train the model for 250 iterations and monitor the validation set error:
lgb_model = lgb.train(params=params,
train_set=train_data,
num_boost_round=250,
valid_sets=[train_data, test_data],
verbose_eval=25)
- Lightgbm predicts probabilities for all five classes. We obtain class predictions using np.argmax() to obtain the column index with the highest predicted probability:
y_pred = np.argmax(lgb_model.predict(X_test), axis=1)
- We compute the accuracy score to evaluate the result and see an improvement of more than 100% over the baseline of 20% for five balanced classes:
accuracy_score(y_true=y_test, y_pred=y_pred)
0.44955063467061984
- Finally, we take a closer look at predictions for each class using the confusion matrix:
cm = confusion_matrix(y_true=y_test, y_pred=y_pred)
cm = pd.DataFrame(cm / np.sum(cm), index=stars, columns=stars)
- And visualize the result as a seaborn heatmap:
sns.heatmap(cm, annot=True, cmap='Blues', fmt='.1%')
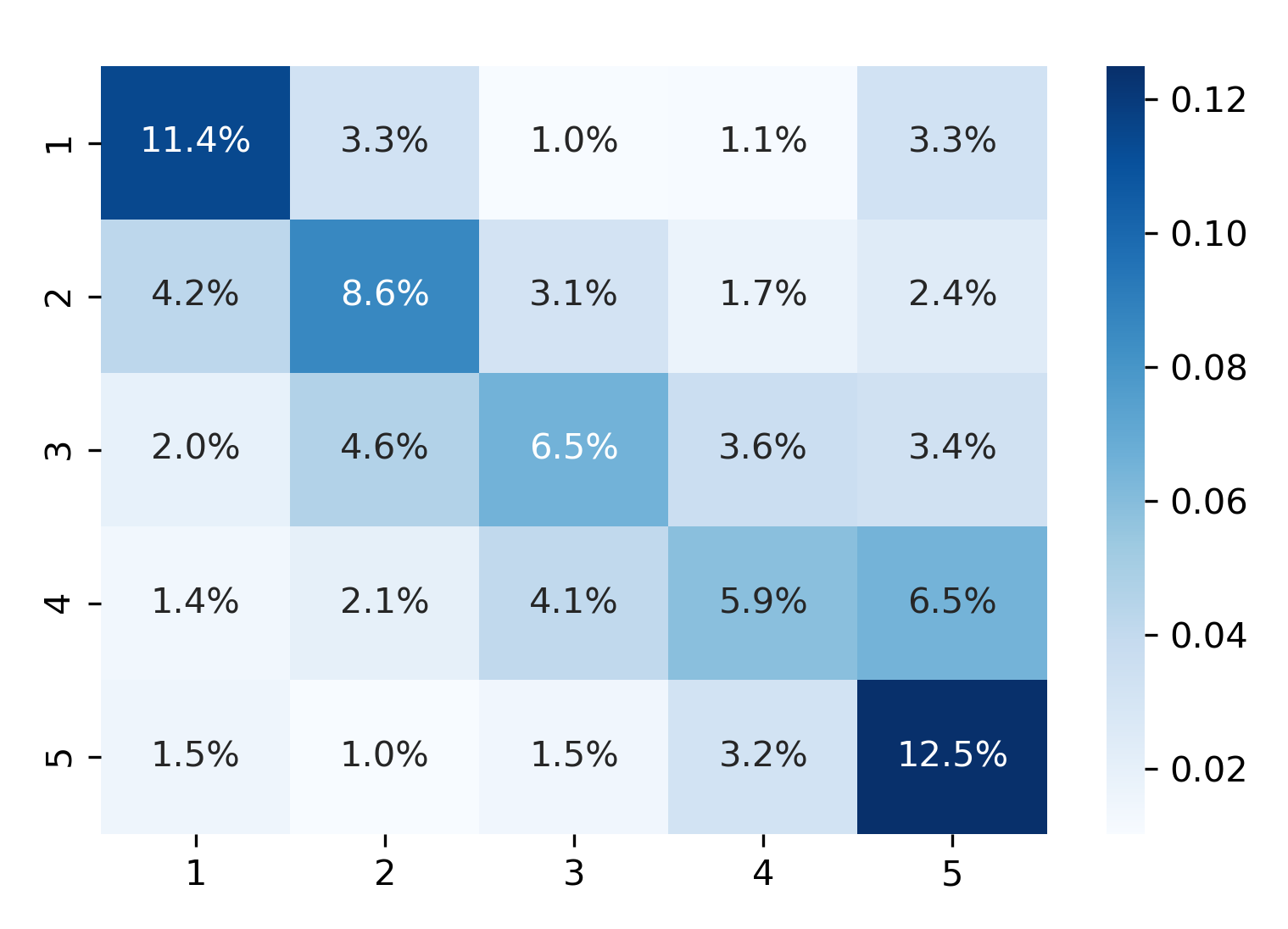
In sum, the doc2vec method allowed us to achieve a very substantial improvement in test accuracy over a naive benchmark without much tuning. If we only select top and bottom reviews (with five and one stars, respectively) and train a binary classifier, the AUC score achieves over 0.86 using 250,000 samples from each class.