
In C, a string is an array with two special properties. First, a string is made up of only characters. Second, the string must conclude with an essential terminating character—the null character. While some would say strings are one of C's weakest features, I disagree with that assessment. Because strings build on already-established mechanisms, I believe that they are rather elegant in an unexpected way.
Not all values that we might want to manipulate in a program are numbers. Often, we need to manipulate words, phrases, and sentences; these are built from strings of characters. We have been performing output using simple strings in printf() statements. In order to perform the input of strings and numbers, we need to be able to further manipulate strings to convert them into values. In this chapter, the elements and building blocks of C strings will be explored, as well as various ways to use and manipulate C strings.
Chapter 11, Working with Arrays, Chapter 13, Using Pointers, and Chapter 14, Understanding Arrays and Pointers, are essential to understanding the concepts presented here. Please do not skip those chapters, particularly Chapter 14, Understanding Arrays and Pointers, before reading this one.
The following topics will be covered in this chapter:
- Characters – the building blocks of strings
- Exploring C strings
- Understanding the strengths and weaknesses of C strings
- Declaring and initializing a string
- Creating and using an array of strings
- Using the standard library for common operations on strings
- Preventing some pitfalls of strings – safer string operations
Throughout this chapter, we will introduce the programming technique of iterative program development. We will start with a very simple but small program and repeatedly add capabilities to it until we reach our desired complete result.
Technical requirements
Continue to use the tools you chose from theTechnical requirements section of Chapter 1, Hello, World!.
The source code for this chapter can be found at https://github.com/PacktPublishing/Learn-C-Programming.
Characters – the building blocks of strings
In C, each array element in a string is a character from a character set. In fact, the C character set, also called American Standard Code for Information Interchange (ASCII), is made up of printable characters—those that appear on the screen—and control characters.
Control characters allow digital devices to communicate, control the flow of data between devices, and control the flow data layout and spacing. The following control characters alter how characters are displayed, providing simple character-positioning functions:
- Horizontal tab (moves the position forward by a number of spaces on the same line)
- Vertical tab (moves the position to the next line but keeps the current horizontal position)
- Carriage return (returns the position to the first column)
- Line feed (advances to the next line)
- Form feed (advances to the next page)
- Backspace (moves back one space)
One special control character is NUL, which has a value of 0. This is known as the null character, or '�'. It is this special character value that terminates a properly formed C string. Omitting this character will cause the C string to be formed improperly.
The other control characters have to do with communication between devices. Others serve as data separators for blocks of data from large blocks (files) down to records and, finally, units.
Printable characters are those that appear on the screen or can be printed. These include numerals, upper and lowercase letters, and punctuation marks. Whitespace, or characters that print nothing but alter the position of other characters, consists of the space character and a positioning control character.
The C language requires the following characters:
- The 52 Latin upper and lowercase letters: A B C D E F G H I J K L M N O P Q R S T U V W X Y Z and
a b c d e f g h i j k l m n o p q r s t u v w x y z - The 10 digits: 0 1 2 3 4 5 6 7 8 9
- Whitespace characters: SPACE, horizontal tab (HT), vertical tab (VT), form feed (FF),line feed (LF), and carriage return (CR)
- The NUL character
- The bell (BEL), escape (ESC), backspace (BS), and delete (DEL) characters are sometimes called destructive backspace.
- 32 graphic characters: ! # % ^ & * ( ) - + = ~ [ ] " ' and _ | ; : { } , . < > / ? $ @ `
Any character set is a somewhat arbitrary correlation of values to characters. There have been many different character sets in use since the invention of computers. Many computer system manufacturers had their own character sets; or, if they were not completely unique, they extended standard character sets in non-standard ways. Any of these extended character sets were extended differently than any others and would, therefore, be unique. Before computers, older teleprinters used the first standard digital code invented in 1870. Before teleprinters, the telegraph, invented in 1833, used various non-digital coding systems. Thankfully, there are now only a few character sets in common use today. ASCII, as a subset of Unicode Transformation Format 8-Bit (UTF-8), is one of them.
A character set could be ordered in nearly any fashion. However, it makes sense to order a character set in a manner that makes using and manipulating characters in that set convenient. We will see how this is done with the ASCII character set in the next section.
The char type and ASCII
ASCII was based on older standards and was developed around the same time that C was invented. It consists of 128 character values, which can be represented with a single signed char value. The lowest valid ASCII value is 0 and the highest valid ASCII value is 127 (there's that off-by-one thing again that we first saw in Chapter 7, Exploring Loops and Iteration). Each value in this range has a single, specific character meaning.
When we talk specifically about a C character (such as a control character, a digit, an uppercase letter, a lowercase letter, or punctuation), we are really talking about a single byte value that is correlated to a specific position in the character set.
Any unsigned char property that has a value greater than 127 or any signed char property that has a value that is less than 0 is not a valid ASCII character. It may be some other kind of character, possibly part of a non-standard ASCII extension or a Unicode character, but it is not valid ASCII.
In ASCII, there are four groupings of characters. Each group has 32 characters, with a total of 128 characters in the set. They are grouped as follows:
- 0-31: Control characters
- 32-63: Punctuation and numerals
- 64-95: Uppercase letters and additional punctuation
- 96-127: Lowercase letters, additional punctuation, and delete (DEL)
Observe each of the four column groups in the following ASCII table:
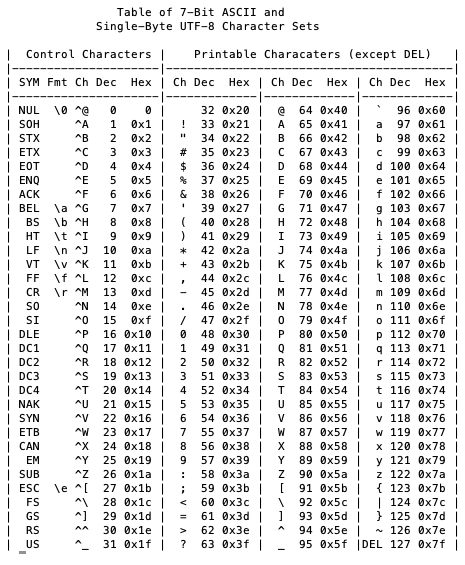
We will fully develop a program to output this table later in this chapter. Before we create that program, let's look through the table for a moment.
Group 1 consists of control characters. This group has five columns that show the following:
- Column 1 is the mnemonic symbol for each control key.
- Column 2 shows its printf() format sequence, if it has one (some don't).
- Column 3 shows its keyboard equivalent, where ^ represents the Ctrl key on the keyboard, which is pressed simultaneously with the given character key.
- Column 4 shows the control key value in decimal form (base-10).
- Column 5 shows the control key value in hexadecimal form (base-16).
A terminal window is a program that is designed to work exactly like a hardware terminal device but without the hardware. Terminal devices, which are now nearly extinct, consist of an input device—typically a keyboard—and an output device—typically a CRT screen. A terminal used for both input and output is sometimes called an I/O device. These were clunky, heavy pieces of equipment that were connected to a central computer or mainframe. They had no computing capability of their own and served only to input commands and data via the keyboard and echo keyboard entries and the results of commands via the CRT screen.
Note that the decimal and hexadecimal values are shown for each key. As a convention, hexadecimal numbers are preceded by0xto indicate that they are not decimal numbers. Hexadecimal numbers are made up of digits 0–9 and a–f or A–F for a total of 16 hexadecimal digits.
While we have not focused on binary (base-2), octal (base-8), or hexadecimal (base-16) number systems, this might be a good opportunity for you to familiarize yourself with the hexadecimal format. In my experience, you encounter and use hexadecimal far more often than you ever use octal or even binary. Compare the decimal value to its hexadecimal equivalent.
Each group has three columns that show the printable character, the value of the character in decimal form (base-10), and the value of the character in hexadecimal form (base-16):
- Group 2 consists of numerals and punctuation.
- Group 3 consists of all uppercase letters and some punctuation.
- Group 4 consists of all lowercase letters, some punctuation, and the delete (DEL) character.
There are a few things to notice about the organization of this character set, which includes the following:
- All of the control characters but one are in the first 32 values. DEL appears as the very last control character in the character set.
- Printable characters have values from 32 to 126 (groups 2, 3, and 4).
- The uppercase A character differs in value from the lowercase a character by 32, as do all the upper and lowercase characters. This was done to make converting characters between upper and lowercase simple. The bit pattern for any uppercase letter and its lowercase equivalent differs by only a single bit.
- Punctuation is mostly scattered about. While this may appear random, there is some rationale to it, primarily for collating/sorting—certain punctuation marks sort before digits, digits sort before uppercase letters, and lowercase letters sort last.
- Lastly, the entire character set uses only 7 bits of the 8-bit char data type. This is intentional because ASCII dovetails directly into UTF-8 and Unicode. This means that any single-byte character whose value is less than 127 (0 or greater) is an ASCII character. Because of this, if a character (byte value) is outside of that range, we can then test to see whether it is a part of a valid Unicode character.
It should come as no surprise that C requires the ASCII character set to fully represent itself. Of course, C does not need all of the control characters in this character set.
Beyond ASCII – UTF-8 and Unicode
The greatest advantage of 7-bit ASCII is that each character in the character set for English can be represented in a single byte. This makes storing text efficient and compact. The greatest disadvantage of 7-bit ASCII is that it represents a character set that is only suitable for English. ASCII can't properly represent other Romance languages based on the Roman alphabet, such as French, Spanish, German, the Scandinavian languages, or the Eastern European languages. For those, we must consider a more comprehensive character-encoding method—Unicode.
If we catalog all of the characters and ideograms for all of the languages on Earth—past and present—we find that 1,112,064 code points are needed to represent all of them with unique values. The term code point is used here instead of character because not all of the positions in this enormous code set are characters; some are ideograms. To represent a code set (think of a character set but much, much larger), we'll need to use 2-byte and 4-byte values for all of the code points.
Unicode is an industry-standard encoding system that represents all of the world's writing systems and consists of UTF-8 (1 byte), UTF-16 (2 bytes), UTF-32 (4 bytes), and several other encodings. Unicode is also known as a Universal Coded Character Set (UCS). Out of the enormity of Unicode, UTF-8 is the most widely used encoding. Since 2009, UTF-8 has been the dominant encoding of any kind. UTF-8 is able to use one to four bytes to encode the full 1,112,064 valid code points of Unicode.
The best thing about UTF-8 is that it is completely backward-compatible with 7-bit ASCII. Because of this, UTF-8 is widely used (by around 95% of the World Wide Web, in fact).
When UTF-16 or UTF-32 code sets are used, each and every character in that code set is either 2 bytes or 4 bytes, respectively. Another advantage of UTF-8 is that it provides a mechanism to intermix 1-, 2-, 3-, and 4-byte code points. By doing so, only the bytes that are needed for a code point are used, saving both storage space and memory space.
Covering programming in Unicode, UTF-16, UTF-32, wide characters, or any other encoding is beyond the scope of this book. Before we can master more complex code sets in C, we will focus primarily on the single-byte encoding of UTF-8 (ASCII). Where appropriate, we'll point out where ASCII and Unicode can coexist. For now, our focus will be on ASCII. The Appendix is where we will see Unicode provides some introductory strategies and the C standard library routines for dealing with multibyte code sets.
Operations on characters
Even though characters are integer values, there are only a few meaningful things we want to do with or to them. The first two things are declaration and assignment. Let's declare some character variables with the following code:
signed char aChar;
char c1 , c2, c3 , c4;
unsigned char aByte;
In C, char is the intrinsic data type that is one byte (8 bits). aChar is a variable that holds a signed value between -128 and 127 (inclusive). We explicitly use the signed keyword, even though it is unnecessary. Next, we declare four single-byte variables, each also having the -128 to 127range. Variables are assumed to besignedunless explicitly specified asunsigned. Finally, we declare an unsigned single-byte variable,aByte, which can hold a value between 0 to 128.
We can also assign values at the declaration, as follows:
signed char aChar = 'A';
char c1 = 65 ;
char c2 = 'a';
char c3 = 97 ;
char c4 = '7';
unsigned char aByte = 7;
These declarations and assignments can be understood as follows:
- First, aChar is declared and initialized with a character set value of A. This is indicated by the ' and ' characters.
- Next, c1 is assigned a literal integer value of 65. This value corresponds to the character set value for 'A'. For reference, see the table provided earlier in this chapter. Using 'A' is far easier than memorizing all the values of the ASCII table. The C compiler converts the 'A' character into its character set value, 65.
- Likewise, c2 is assigned the 'a' character value and c3 is assigned the 97 literal integer value, which happens to correspond to the character set value for 'a'.
- Finally, we examine the difference between the '7' character (seven) and the 7 integer value. These are very different things in the character set. The character set value for '7' is 55 while the literal 7 integer value corresponds to the BEL control character. BEL will make the terminal make a simple beep sound. The point of these two assignments is to highlight the difference between the character 7 ('7')and the literal value 7 (7).
To verify this behavior, let's prove it to ourselves. The following program makes the preceding declarations and then calls showChar() for each variable:
#include <stdio.h>
void showChar( char ch );
int main( void ) {
signed char aChar = 'A';
char c1 = 65 ;
char c2 = 'a';
char c3 = 97 ;
char c4 = '1';
unsigned char aByte = 1;
showChar( aChar );
showChar( c1 );
showChar( c2 );
showChar( c3 );
showChar( c4 );
showChar( aByte );
}
The main() function simply declares and initializes six variables. The real work of the program is in the showChar()function, which is shown as follows:
void showChar( char ch ) {
printf( "ch = '%c' (%d) [%#x]
" , ch , ch , ch );
}
The showChar()function takes char as its parameter and then prints out that value in three different forms—%c prints the value as a character, %d prints the value as a decimal number, and %x prints the value as a hexadecimal number. %x is modified with # to prepend 0x to the output hexadecimal number; it now appears in the printf() format specifier as %#x.
With your chosen editor, create a new file called showChar.c and enter the main() and showChar() functions. Compile and run the program. You should see the following output and you may hear a bell sound:

In the output, we see the character, its decimal value, and finally, its hex value.
Let's consider the showChar()functionfor Unicode compatibility. Currently, it takeschar, or a single byte value, as its input parameter. This function works for ASCII but it won't work for multi-byte Unicode. Fortunately, this can be easily fixed to handle both ASCII and Unicode by changing the type of the input parameter fromchartoint, as follows:
void showChar( int ch) ...
When the input is a single byte (char), the function will coerce it to fill the 4-byte int variable and printf() will then handle it as if it were a single-byte char variable. When the input is a multi-byte Unicode character, it will also be coerced to fill the 4-byte int variable and printf() will also handle it properly.
Getting information about characters
The next thing we might want to do to individual characters has to do with figuring out what kind of character it is. Given a character from an input source, we may want to determine one or more of the following properties of that character:
- Is it a control character?
- Is it whitespace? (that is, does it include SPACE, TAB, LF, CR, VT, or HT?)
- Is it a digit or a letter?
- Is it in uppercase or not?
- Is it even ASCII?
Now, reflecting on the four groups of ASCII characters and how they are laid out, you might consider how you would write functions to test these properties. For instance, to see whether a character is a decimal digit, you could write the following:
bool isDigit( int c ) {
bool bDigit = false;
if( c >= '0' && c <= '9' )
bDigit = true;
return bDigit;
}
This function checks to see whether the value of the given character is greater than or equal to the value of the '0'characterand whether it is less than or equal to the value of the'9'character. If it is, then this character is one of those digits, andtrueis returned. Otherwise, it is not in that range andfalseis returned. As a mental exercise, you might want to think through what the logic might be to check each of the preceding properties.
A function that checks for whitespace might look as follows:
bool isWhitespace( int c) {
bool bSpace = false;
switch( c ) {
case ' ': // space
case ' ': // tab
case '
': // line feed
case 'v': // vertical tab
case 'f': // form feed
case '
': // carriage return
bSpace = true;
break;
default:
bSpace = false;
break;
}
return bSpace;
}
In the isWhiteSpace()function, a switch()… statement is used. Each case variable of the switch()… statement compares the given character to one of the whitespace characters. Even though some of the whitespace characters appear as if they are two characters (a backslash () and a character), the backslash escapes from the standard character meaning and indicates that the next character is a control character. If we wanted to assign the backslash character, we'd have to do so as follows:
aChar = '' ; // Backslash character
Notice how this fallthrough mechanism of switch()… works—if any of the cases are true, bSpace is set to true and then we break out of switch()…. Remember that it is a safe practice to always provide a default: condition for any switch()… statement.
For a final set of operations on characters, we may want to convert an uppercase character into a lowercase one or vice versa. Alternatively, we might want to convert a digit into its internal numerical value. To convert an uppercase letter into a lowercase one, we'd first check to see whether the character is an uppercase letter and if it is, add 32 to it; otherwise, do nothing, as follows:
int toUpper( int c ) {
if( c >= 'A' && c <= 'Z' ) c += 32;
return c;
]
To convert a lowercase character into uppercase, we'd likewise check to see whether it is a lowercase character and if so, subtract 32 from it.
To convert the character value of a digit to its numerical value, we add the following function:
int digitToInt( int c) {
int i = c;
if( c >= '0' && c <= '9' ) i = c - '0';
return i;
}
In digitToInt(), we first check to see that we have a digit. Then, we subtract the character value of '0' from the given character. The result is the digit's numeric value. Otherwise, the character is not a digit and we simply return the character value that was given.
While it is possible and even tempting to create your own methods/functions to perform these operations, many of them are already provided in the CStandard Library. For these, we look to thectypes.h, the C standard library header file. There, you will find handy functions to perform character tests and conversions on a given character. The following functions perform simple tests on the given character,c:
intisalnum(int c); // alphabets or numbers
intisalpha(int c); // alphabet only
intisascii(int c); // in range of 0..127
intiscntrl(int c); // in range 0..31 or 127
int isdigit(int c); // number ('0'..'9')
int islower(int c); // lower case alphabet
intisnumber(int c); // number ('0'..'9')
int isprint(int c); // printable character
int ispunct(int c); // punctuation
int isspace(int c); // space
int isupper(int c); // upper case alphabet
These functions return 0 for FALSE and non-zero for TRUE. Note that the given character is presented as anintvariable because it may be a Unicode 1-, 2-, 3-, or 4-byte code point. int allows the character, whether a single-byte or 4-byte character, to properly hold any of those character values. Therefore, we can expect these functions to work with any UTF-8 or Unicode characters.
Manipulating characters
The following functions alter a given character:
int digittoint(int c); // convert char to its number value
int tolower(int c); // convert to lower case
int toupper(int c); // convert to upper case
These functions return the changed character, or the original character if the conversion is not necessary or not valid.
There are also other functions available in ctype.h. They have been omitted for simplicity. Some deal with non-ASCII characters; others deal with eclectic groupings of characters. If you are interested in learning more, you can explore ctype.h on your computer system.
We will see some of these functions in action later in this chapter after we introduce strings. However, before we move on to strings, let's take a first pass at creating the ASCII table shown earlier in this chapter. We will write a program that prints a single column of a table of printable characters. The program is surprisingly simple. To start, our approach will be to use a for()… loop to print a single grouping from the ASCII table. The basic loop is as follows:
#include <stdio.h>
int main( void ) {
char c2;
for( int i = 32 ; i < 64 ; i++ ) {
c2 = i;
printf( "%c %3d %#x" , c2 , c2 ,c2 );
printf( " " );
}
}
This loop prints the second group of ASCII characters in the range of 32 to 63—which is punctuation and digits. The printf() statement does three things—first, it prints c2 as a character with the %c format specifier, then it prints c2 as a decimal value with the %d format specifier, and finally, it prints c2 as a hexadecimal, or hex, value with the %x format specifier. # in this format specifier prepends the hex number with 0x; this convention clearlytells us that it is a hex number.
The concept of interpreting a value in different ways, as printf() does in this code statement, should not be new. If you recall from Chapter 3, Working with Basic Data Types, any value is simply a series of 0 and 1. The format specifiers embedded in the string parameter to printf() tell the function how to interpret the given values. In this case, we are printing the same value but in three different ways—as a character, as a decimal number, and as a hex number.
Create a file called printASCII.c and open the program. Compile and run the program. You should see the following output:
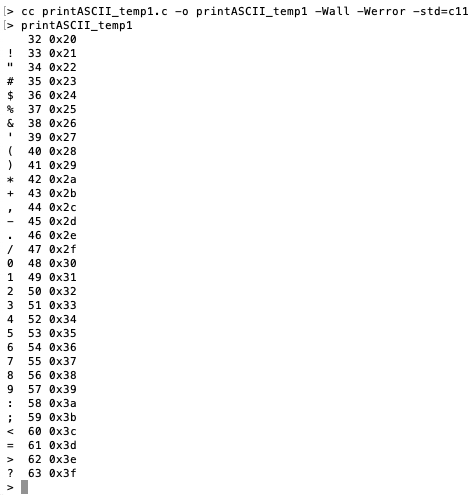
We have one column printed. This is our starting point. To get the full ASCII table, we will modify this basic program several times until we get to our finished and complete ASCII table.
In the next iteration of printASCII.c, we want to add printing of groups 3 and 4 and add column heading lines to indicate what each column represents:
- The code for the heading lines look like this:
printf( "| Ch DecHex | Ch DecHex | Ch DecHex |
" );
printf( "|-------------|-------------|-------------|
" );
We use the vertical bar (|) as a visual guide to separate the groups. Each group has a character, its decimal value, and its hex value.
- Next, we need to add some character variables for each of the groups:
char c1 , c2 , c3 , c4;
c1 will hold values for group 1 characters, c2 will hold values for group 2 characters, and so on. Note that we've added c1 for the group 1 control characters, even though we will ignore this capability for now.
- Next, we need to change the for()… loop to go from 0 to 31. By doing this, we can simply add an offset to the character for the proper group, as follows:
for( int i = 0 ; i < 32; i++) {
c1 = i;// <-- Not used yet (a dummy assignment for now).
c2 = i+32;
c3 = i+64;
c4 = i+96;
- Lastly, the printf() statement needs to print the characters for each group on a single line, as follows:
printf( "| %c %3d %#x | %c %3d %#x | %c %3d %#x |" ,
c2 , c2 , c2 ,
c3 , c3 , c3 ,
c4 , c4 , c4 );
printf( " " );
}
This may appear more complex than before, but it's really just the same format sequence repeated three times, with variables to fill each format specifier.
If you made those changes to your version of printASCII.c, you will see the following output:
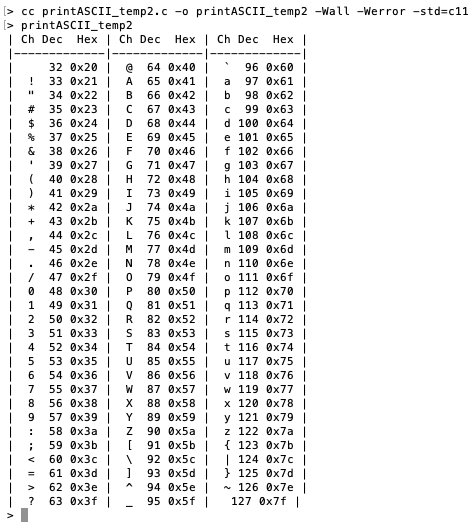
Not bad—but wait! There is that pesky DEL character that has a value of 127. How might we deal with that?
The easiest solution is to add an if()… statement that checks whether c4 is the DEL character. If not, print the line out as before. If it is, then instead of printing c4 as a character, which actually deletes a character on the terminal, print the "DEL"stringinstead. Theprintf()format specifiers will need a slight change to reflect this, as follows:
printf("|%c %3d %#x |%c %3d %#x |%s %3d %#x |" ,
c2 , c2 , c2 ,
c3 , c3 , c3 ,
"DEL" , c4 , c4 );
Now, your printASCII.c program should look as follows:
#include <stdio.h>
int main( void ) {
char c1 , c2 , c3 , c4;
printf("| Ch DecHex | Ch DecHex | Ch DecHex | " );
printf("|-------------|-------------|-------------| " );
for( int i = 0 ; i < 32; i++)
{
c1 = i;// <-- Not used yet (a dummy assignment for now).
c2 = i+32;
c3 = i+64;
c4 = i+96;
if( c4 == 127 ) {
printf( "|%c %3d %#x |%c %3d %#x |%s %3d %#x |" ,
c2 , c2 , c2 ,
c3 , c3 , c3 ,
"DEL" , c4 , c4 );
} else {
printf( "|%c %3d %#x |%c %3d %#x |%c %3d %#x |" ,
c2 , c2 , c2 ,
c3 , c3 , c3 ,
c4 , c4 , c4);
}
printf( " " );
}
}
You might notice that each part of the if()… else… statement consists of only one statement. Nevertheless, even though the { and }block statementsare not necessary since the logic is currently very simple, they are there for if or when this logic is altered and becomes more complicated. Also, notice how the spacing for each line clarifies what is happening.
Edit printASCII.c so that it looks like the preceding code. Compile and run it. You should now see the following:

At this point, we have printed out the printable characters and their values and we have dealt with the rather out-of-place "DEL" control character to properly appear in our table. Before we can complete our ASCII table to print control characters without actually sending those control characters to our terminal, we need to learn a bit more about strings.
Remember, printing control characters to a terminal window actually controls that window's behavior as if it were a real terminal device. We don't want to do that without understanding more about why we'd even need to control the device.
Exploring C strings
We have explored individual characters and various operations on them. Dealing with individual characters is useful but more often, we will want to create words and sentences and operate on them. For this, we need a string of characters—or more simply, we need a string.
An array with a terminator
A string is an array of characters with one special property. This special property is that the element after the last character of the C string must itself be a special character—theNULcharacter. NUL has a value of 0. This character indicates the end of the string.
To implement a string, we extend the concept of an array to be a specially formatted array of characters; an array with an extra terminating NUL character. The terminating character is sometimes called a sentinel. This is a character or condition that signals the end of a group of items. The NUL character will be used as a sentinel when we loop through string elements; the sentinel will indicate that we have encountered every element of the string. Because of this, we must be careful to ensure that each string ends with NUL.
Where we use 'x' (single quotes) to indicate a single character, we use "Hello" (double quotes) to indicate a string literal, which is constant and cannot be changed. When double quotes are used to define a string, the null terminator is automatically added to and included in the array of characters. This also means that the string array always has one more element (for NUL) than the number of characters that are in the string. So, the "Hello"stringis an array of six elements (five printable characters and theNULcharacter).
Without the terminatingNULcharacter, we either have just an array of characters or we have an invalid string. In either case, we do not have a string. Furthermore, when we try to use standard string operations on an invalid string, mayhem will result. Mayhem also results when we loop through an array like this but the NULsentinelis not present. For an array to be a string, theNULterminator must be present.
Strengths of C strings
One of the greatest strengths of C strings is that they are simple, in the sense that they are built upon existing mechanisms—characters, arrays, and pointers. All of the considerations we have for arrays, pointers to arrays, and pointers to array elements also apply to strings. All of the ways we loop through arrays also apply to strings.
Another strength of C strings is thatthe C standard librarycomes with a rich set of functions with which to operate on strings. These functions make creating, copying, appending, extracting, comparing, and searching strings relatively easy and consistent.
Weaknesses of C strings
Unfortunately, C strings also have some great weaknesses. The foremost of these is the inconsistent application of the NUL terminator. Sometimes, the NUL terminator is automatically added, but at other times, the responsibility of adding it is left to the programmer. This inconsistency makes creating strings somewhat error-prone so that special attention must be given to correctly forming a valid string with the terminating NUL character.
A minor weakness of C strings is that they are not always efficient. To get the size of a string, for instance, the entire string must be traversed to find its end. In fact, this is how the strlen()function works; it traverses the entire string, counting each character before the first '�' character it encounters. Often, this traversal may be done multiple times. This performance penalty is not quite as important on fast computing devices, but it remains a concern for slower, simpler computing devices and embedded devices.
For the remainder of this chapter and all the subsequent chapters, we will continue to use C strings so that you gain familiarity with using them. If, after working with C strings for some time, you find them too cumbersome, or you find it too easy to misuse them, causing instability in your programming projects, you may want to consider alternatives to C strings. One alternative is The Better String Library—bstrlib. bstrlib is stable, well-tested, and suitable for any software production environment. bstrlib is described briefly in the Appendix section of this book.
Declaring and initializing a string
There are a number of ways to declare and initialize a string. We will explore the various ways to both declare and initialize strings.
String declarations
We can declare a string in several ways. The first way is to declare a character array with a specified size, as follows:
char aString[8];
This creates an array of 8 elements, capable of holding seven characters (don't forget the terminating NUL character).
The next way to declare a string is similar to the first method but instead, we don't specify the size of the array, as follows:
char anotherString[];
This method is not useful unless we initialize anotherString, which we will see in the next section. If you recall from Chapter 14, Understand Arrays and Pointers, this declaration looks like a pointer in the form of an array declaration. In fact, without initialization, it is.
The last way to declare a string is to declare a pointer to char, as follows:
char * pString;
Again, this method not useful until pString is either initialized or actually points a string literal or string array, both of which must have already been declared. The last two methods, both without initialization, are useful as function parameter declarations to refer to a string that has already been declared and initialized.
All of these methods are more useful when the string is both declared and initialized in the same statement.
Initializing strings
When we declare and initialize a string array, there are a few more possibilities that must be understood. We will explore them now:
- We can declare an empty string—that is, a string with no printable characters—as follows:
charstring0[8] = { 0 };
string0 is an array of 8 elements, all of which are initialized to NULL, the nul character, or simply 0.
- Next, we can declare a string and initialize the array with individual characters, as follows:
charstring1[8] = { 'h' , 'e' , 'l' , 'l', 'o' , '�' };
When doing this, we must remember to add the nul character, or '�'. Note that even though the array is declared to have 8 elements, we have onlyinitialized six of them. This method is rather tedious.
- Thankfully, the creators of C have given us an easier way to initialize a string, as follows:
charstring2[8] = "hello";
In this declaration, string2 is declared to have 8 elements and is initialized with the "hello"string literal. Each character of the string literal is copied into the corresponding array element, including the terminatingnulcharacter ('�'). By specifying an array size, we have to make certain that the array declaration is large enough to hold all the characters (plus thenulcharacter) of the string literal. If we use an array size that is less than the length of the string literal (plus thenulcharacter), a compiler error will occur. This is also tedious.
- The creators of C didn't stop there. Again, thankfully, they provided an easier way to do this, as follows:
charstring3[]= "hello";
In this declaration, by giving string3 an unspecified size, we are telling the C compiler to allocate exactly the number of characters (plus the nul character) that is copied from the string literal, "hello". The string3arraynow has six elements, but we didn't have to count them beforehand.
In each of the preceding array initializations, each element/character of the array can be accessed using the []arraynotation or pointer traversal. Furthermore, each element/character of the array can be changed. The methods for doing this are identical to those shown inChapter 14,Understanding Arrays and Pointers.
Declaring and initializing a character array of an unspecified size with a string literal is very different than declaring a pointer to character and initializing that with the address of that string literal. String literals—like literal numbers, say 593—are strings, but they cannot be changed.
A pointer to character is declared and initialized with a string literal, as follows:
char* string4= "hello";
string4 is a pointer that points to the first character of the "hello"string literal. No characters are copied.string4can later be reassigned to point to some other string literal or string array. Furthermore,"hello"is a constant. So, while we can traverse this string, accessing each character element, we cannot change any of them.
We can manipulate string elements (characters) in a string array, but not in a string literal, in the same way that we would an array of any other data type. The following program illustrates both initializing strings in various ways and then changing the first character of each string:
#include <stdio.h>
#include <ctype.h>
int main( void )
{
charstring0[8] = { 0 };
charstring1[8] = { 'h' , 'e' , 'l' , 'l', 'o' , '�' };
charstring2[8] = "hello";
charstring3[]= "hello";
char* string4= "hello";
printf( "A) 0:"%s" 1:"%s" 2:"%s" 3:"%s"4:"%s" " ,
string0 , string1 , string2 , string3 , string4 );
string0[0] = 'H';
string1[0] = 'H';
string2[0] = toupper( string2[0]);
string3[0] = toupper( string3[0]);
//string4[0] = 'H';// Can't do this because its a pointer
// to a string literal (constant).
char* string5 = "Hello"; // assign pointer to new string
printf( "B) 0:"%s"1:"%s"2:"%s"3:"%s"4:"%s" " ,
string0 , string1 , string2 , string3 , string5 );
}
Let's examine each part of this program, as follows:
- First, the character arrays are declared and initialized. string0 is a string containing no printable characters or an empty string; it is also an array of 8 elements, as are string1 and string2. These arrays are larger than they need to be. string3 is an array of exactly the required size for the "hello" string, or, 6 elements (6, not 5—don't forget the terminating nul character). string4 is a pointer to a string literal.
- Next, these strings are printed using a single printf() function. To get a double quote mark (") to appear in the output, " is used in the format string before and after each string specifier.
- Finally, the first letter of each string array is changed to its uppercase letter. The first two strings are changed by assigning 'H' to that element. The next two strings are changed using the toupper() standard library function.
Create the simpleStrings.cfile and type in the preceding program. Save it, then compile and run it. You should see the following output:

You can now use this program for further experimentation. For instance, what happens when you try to change the first letter of string4? What happens when you try to initialize string1 to, say, "Ladies and gentlemen" (a string much longer than 8)? You might also try adding a loop by using strlen() or by checking for '�' and converting each character of string2 into uppercase. The strlen()function can be used by including <string.h>, described in the last section of this chapter. Solutions to these experiments can be found in the source file in the repository.
Passing a string to a function
Just as with arrays and pointers, there are a number of ways to pass a string to a function:
- The first way is to pass the string explicitly, giving the array size of the string, as follows:
Func1( char[8] aStr );
This parameter declaration allows a string of up to seven characters, as well as the terminating nul character ('�'), to be passed into Func1(). The compiler will verify that the array being passed in has exactly 8 char elements. This is useful when we are working with strings of limited size.
- The next way is to pass the string without specifying the char array size, as follows:
Func2( char[] aStr );
Func3( int size, char[] aStr );
In Func2(), only the string name is passed. Here, we are depending on the fact that there is '�', a nul character in aStr. To be safer, the size of the string, as well as the string itself, can be passed into the function, as is done in Func3().
- Lastly, we can pass a pointer to the beginning of the string. The pointer may point to either an array of characters or it may point to a string literal:
Func4( char* pStr );
- If in any of the functions you need to ensure that the string is not modified, you can use the const qualifier in any of the methods, as follows:
Func1_Immutable( const char[8] aStr );
Func2_Immutable( const char[] aStr );
Func3_Immutable(int size, const char[] aStr );
Func4_Immutable( const char* pStr );
Each of these function declarations indicates that the string characters passed into the body of function definition cannot be modified.
Empty strings versus null strings
When a string contains no printable characters, it is called an empty string. The following declarations are empty strings:
char* emptyString1[1] = { '�' };
char* emptyString2[100] = { 0 };
char* emptyString3[8] = { '�' , 'h' , 'e' , 'l' , 'l' , 'o' , '�' } ;
The first empty string is a character array of a single element—the nul character, or '�'. The second empty string is a character array of 100 elements, all of which are '�', the nul characters. The third empty string is also an empty string; even though it has printable characters, the nul character ('�') in the zeroth element signifies the end of the string, thereby making it empty. After the first nul character, '�', is encountered, it doesn't matter what comes after it; it is still seen as an empty string.
When an array reference or pointer to a string is null (nothing), it is called a null string. A null string points to nothing at all. The following declarations are null strings:
char nullString1[];
char* pNullString2 = NULL;
The first null string is an uninitialized character array declaration. The second null string is a pointer to the character where the pointer value is NULL. pNullString2 will be a null string until a valid string address is assigned to it.
An empty string and a null string are not the same! One is an array with at least one '�', the nul character; the other is nothing at all—nothing has been allocated or the null string reference is NULL (points to nothing).
The distinction between an empty string and a null string is particularly important when we create or use functions that expect a valid string (even if it is empty) but are given a null string. Mayhem will occur. To avoid mayhem, when you create string functions, be sure to check for the null string. When you use string functions, either verify a null string could be passed to it or check for the null string before calling the function.
Hello, World! revisited
There is one final way to pass a string into a function, which is to pass a string literal as a function parameter, as follows:
Func5( "Passing a string literal" );
In this function declaration, the "Passing a string literal" string literal is the string that is passed into Func5() when it is called. Func5() can be declared in any of the following ways:
void Func5( char[] aStr );
void Func5( char* aStr );
void Func5( const char[] aStr );
void Func5( const * aStr );
The first two declarations take a non-constant array name or pointer parameter, while the last two declarations take a constant array name or pointer parameter. Because the parameter string being passed into Func5() is a string literal, it remains a constant and its elements cannot be changed within the function body.
This is another kind of initialization and it is rather subtle. However, we have already seen this done many times. We first saw it in our very first program, Hello, World!, in Chapter 1, Running Hello, World!, with the following statement:
printf( "Hello, World! " );
Let's examine what is happening in this call to printf(). In this statement, the "Hello, World! "string literal, as well as a pointer, is allocated. The pointer points to the first character of this string and is passed into the function body. Within the function body, the string is accessed like any other array (either via a pointer or using array notation). However, in this case, each element of the array is constant—having been created from a string literal—and cannot be changed. When the function returns, both the string literal and the pointer to it are deallocated.
If we want to create a string and use it more than once or alter it before using it again, we would have to declare and initialize it, as follows:
char greeting[] = "hello, world!";
We could then use it in printf(), as follows:
printf( "%s " , greeting );
Then, perhaps, we might change it to all uppercase and print it again, as follows:
int i = 0;
while( greeting[i] != '�' ) {
greeting[i] = toupper( greeting[i] );
}
printf( "%s " , greeting );
In these series of statements, we created a string and used it in multiple printf() statements, modifying the string between calls. Create a file called greet.c and put the previous statements in the main() function block. Remember to include ctype.h as well as stdio.h so that you can use the toupper()function. Compile and run the program. You should see the following output:
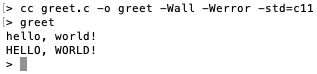
As you can see, first the greeting string of lowercase letters is printed. It is converted into uppercase letters and then printed. Notice how only characters that can be converted into uppercase are actually converted; the comma (,) and exclamation mark (!) remain unchanged.
Also, notice how we could have found the length of the string and used a for()… statement. However, because the string has a sentinel value, �, which indicates the endpoint, we can more easily use a while()…statement.
Creating and using an array of strings
Sometimes, we need to create a table of related string values. This table, in one form or another, is often called a lookup table. Once we construct this table, we can then look up string values based on an index into the table. To declare a one-dimensional lookup table for the days of the week, where the array index is equal to the day of the week, we would make the following declaration:
char* weekdays[] = { "Sunday" ,
"Monday" ,
"Tuesday" ,
"Wednesday" ,
"Thursday" ,
"Friday" ,
"Saturday" };
Notice that the strings are of different sizes. Also, notice that they are all string literals; this is acceptable because these names won't change. We can then use this table to convert a numerical day of the week to print the day, as follows:
int dayOfWeek = 3;
printf( "Today is a %s " , weekdays[ dayOfWeek ] );
A value of 3 for dayOfWeek will print the "Wednesday"string.
With a simple lookup table, we can create an array of string literals that represent the mnemonics of control characters to complete our ASCII table. We can create our control character lookup table as follows:
char* ctrl[] = { "NUL","SOH","STX","ETX","EOT","ENQ","ACK","BEL",
" BS"," HT"," LF"," VT"," FF"," CR"," SO"," SI",
"DLE","DC1","DC2","DC3","DC4","NAK","SYN","ETB",
"CAN"," EM","SUB","ESC"," FS"," GS"," RS"," US" };
Notice that each string literal is the same length; this is so that our table's columns align nicely, even though some mnemonics are two characters and some are three characters.
We are now ready to add the control characters to our ASCII table. Copy the printASCII.cfiletoprintASCIIwithControl.cand make the following changes:
- Add the ctrl[] lookup table either before or after the declarations for c1 through c4.
- Before the first printf() function, add the following:
printf("| %s ^%c %3d %#4x ",
ctrl[i] , c1+64 , c1 , c1 );
- Before the second print() function, add the following:
printf("| %s ^%c %3d %#4x ",
ctrl[i] , c1+64 , c1 , c1 );
- The printf() statements are getting rather long. You can choose to simplify the printf() function in the if()… else… statement.
- Your program should now look like the following:
#include <stdio.h>
int main( void ) {
char* ctrl[] = { "NUL","SOH","STX","ETX","EOT","ENQ","ACK","BEL",
" BS"," HT"," LF"," VT"," FF"," CR"," SO"," SI",
"DLE","DC1","DC2","DC3","DC4","NAK","SYN","ETB",
"CAN"," EM","SUB","ESC"," FS"," GS"," RS"," US" };
char c1 , c2 , c3 , c4;
printf( "|-----------------" );
printf( "|-----------------------------------------| " );
printf( "| SYM Ch DecHex " );
printf( "| Ch DecHex | Ch DecHex | Ch DecHex | " );
printf( "|-----------------" );
printf( "|-------------|-------------|-------------| " );
for( int i = 0 ; i < 32; i++)
{
c1 = i;
c2 = i+32;
c3 = i+64;
c4 = i+96;
printf( "| %s ^%c %3d %#4x " ,
ctrl[i] , c1+64 , c1 , c1 );
printf( "|%c %3d %#x " ,
c2 , c2 , c2 );
printf( "|%c %3d %#x " ,
c3 , c3 , c3 );
if( c4 != 127 ) {
printf( "|%c %3d %#x " ,
c4 , c4 , c4);
} else {
printf( "|%s %3d %#x | " ,
"DEL" , c4 , c4 );
}
}
c1 = 0x7;
printf("%c%c%c", c1 , c1 , c1);
}
- Save this program, then build and run it. You should see the following output:
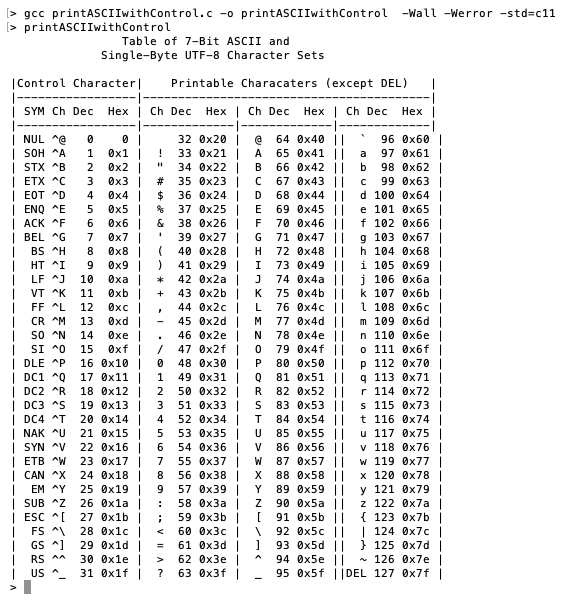
You should also hear three system bell tones. We have added to our table a column grouping of ASCII control characters that shows the following:
- The control character mnemonic
- The control character's keyboard equivalent
- The decimal value of the control character
- The hex value of the control character
If you compare this output to the table given at the beginning of this chapter, you may find that we need to add just one more column to our control character group. That column is the printf() format string escape character for printable control characters. Recall that not all control characters are printable since they control other aspects of computer devices. To print this final column, we have to add another lookup table, as follows:
char format[] = {'0', 0 , 0,0, 0, 0, 0, 'a' ,
'b','t' ,'n' ,'v' ,'f' , 'r' , 0, 0 ,
0, 0, 0, 0, 0, 0, 0, 0 ,
0, 0, 0,'e' , 0, 0, 0, 0};
Notice that this is an array of single characters. To print the escape sequence for each control character that is printable, we'll need to build a string with the backslash () and that control character's key equivalent, as follows:
char fmtStr[] = " ";
if( format[i] )
{
fmtStr[1] = '';
fmtStr[2] = format[i];
}
This snippet of code should appear within thefor()...loop just before the firstprintf()function. At each iteration through the loop, fmtStr is reallocated and initialized to a string of three spaces. If its corresponding lookup table value is not NULL, then we modify fmtStr to have a backslash () and the appropriate character.
Then, the first printf() function needs to be modified, as follows:
printf( "| %s %s ^%c %3d %#4x " ,
ctrl[i] , fmtStr , c3 , c1 , c1 );
Finally, we have to adjust the table's header lines to match. Copy the printACIIwithControl.cfile to the file named printASCIIwithControlAndEscape.c. Make the following changes:
- Add the format[] lookup table.
- Add logic to build fmtStr.
- Alter the printf() routine to include fmtStr.
- Adjust the heading printf() functions to match the added column.
Compile and run printASCIIwithControlAndEscape.c. You should see the following output:
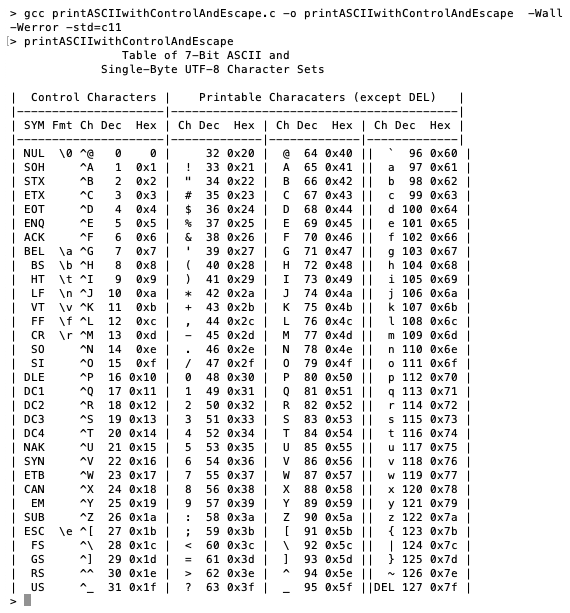
You may have to fiddle with your printf() statements to get the headings just right. You now have your own table of the ASCII character set, which you can execute as needed.
As an added experiment, you might want to modify printASCII.cto print the characters from 128 to 255. Since these are extended ASCII characters, they are not expected to be identical from one operating system to the next. There is no standard for extended ASCII characters. After you try this yourself, which I urge you to do, you can find the printExtendedASCII.c program in the code repository to compare with your version.
Common operations on strings – the standard library
Just as for characters, the C standard library provides some useful operations on strings. These are declared in the string.hheader file. We will take a brief look at these functions here and then incorporate them into working programs in later chapters to do various interesting things.
Common functions
If you carried out one of the experiments in the earlier sections of this chapter, you will have already encountered the strlen()function, which counts the number of characters (excluding the terminating nul character) in a given string. The following is a list of some useful functions and what they do:
- Copy, append, and cut strings:
- strcat(): Concatenates two strings. This appends a copy of one null-terminated string to the end of a target null-terminated string, then adds a terminating `�' character. The target string must have sufficient space to hold theresult.
- strcpy(): Copies one string to another (including the terminating `�' character).
- strtok(): Breaks a string into tokens or sub-strings.
- Compare strings:
- strcmp(): Compares two strings. Lexicographically compares two null-terminated strings.
- Search characters in strings:
- strchr(): Locates a character in a string. This finds the first occurrence of the desired character in a string.
- strrchr(): Locates a character in a string in reverse. This finds the last occurrence of the desired character in a string.
- strpbrk(): Locates any set of characters in a string.
- Search for one string in another string:
- strstr(): Locates a substring in a string.
In these functions, it is imperative that null-terminated strings are supplied. Therefore, some care must be exercised when using these functions to avoid mayhem.
Safer string operations
Sometimes, it is not possible to ensure that a null-terminated array of characters is provided. This is especially common when strings are read from a file, read from the console, or dynamically created in unusual ways. To prevent mayhem, a few string functions have a built-in limiter that only operates on the first N characters of the string array. These are considered safer operations and are described in the following list:
- Copy and append strings:
- strncat(): Concatenates two strings. This appends a copy of up to N characters of one null-terminated string to the end of a target null-terminated string, then adds a terminating `�'character.The target string must have sufficient space to hold theresult.
- strncpy(): Copies up to N characters of one string to another. Depending on the size of the destination, the destination string may either be filled with the nul characters or may not be null-terminated.
- Compare strings:
- strncmp(): Compares two strings. Lexicographically, it compares no more than N characters of two null-terminated strings.
To see how these functions operation, create a file called saferStringOps.c and enter the following program:
#include <stdio.h>
#include <string.h>
#include <ctype.h>
void myStringNCompare( char* s1 , char* s2 , int n);
int main( void ) {
char salutation[] = "hello";
char audience[] = "everybody";
printf( "%s, %s! ", salutation , audience );
int lenSalutation = strlen( salutation );
int lenAudience = strlen( audience );
int lenGreeting1 = lenSalutation+lenAudience+1;
char greeting1[lenGreeting1];
strncpy( greeting1 , salutation , lenSalutation );
strncat( greeting1 , audience , lenAudience );
printf( "%s " , greeting1 );
char greeting2[7] = {0};
strncpy( greeting2 , salutation , 3 );
strncat( greeting2 , audience , 3 );
printf( "%s " , greeting2 );
In the first part of this program, we are using strncpy() and strncat() to build strings from other strings. What is significant is that using these functions forces us to consider string lengths, as well as whether the resulting string will be large enough to hold to combined strings.
The remainder of the program is as follows:
myStringNCompare( greeting1 , greeting2 , 7 );
myStringNCompare( greeting1 , greeting2 , 3 );
char* str1 = "abcde";
char* str2 = "aeiou";
char* str3 = "AEIOU";
myStringNCompare( str1 , str2 , 3 );
myStringNCompare( str2 , str3 , 5 );
}
void myStringNCompare( char* s1 , char* s2 , int n)
{
int result = strncmp( s1 , s2 , n );
char* pResultStr;
if( result < 0 )pResultStr = "less than (come before)";
else if( result > 0 ) pResultStr = "greater than (come after)";
elsepResultStr = "equal to";
printf( "First %d characters of %s are %s %s " ,
n, s1 , pResultStr , s2 );
}
In this part of the program, we use strncmp() in our own wrapper function, myStringNCompare(), to compare the sort order of the various pairs of strings. A wrapper function is a function that performs a desired simple action as well as wraps additional actions around it. In this case, we are adding a printf() statement to indicate whether one string is less than, equal to, or greater than another string. Less than means that the first string comes alphabetically before the second string. In each string comparison, we limit the comparison to the first N characters of the string. Note also that lowercase letters are greater than (come after) uppercase letters; this implies that care must be taken when comparing strings of mixed cases.
Save, compile, and run the program. You should see the following output:

Notice in these examples how strncmp() compares only the first N characters of each string and ignores the rest. I would encourage you to further experiment with the copy, concatenation, and comparison operations on various strings of your choosing to get a good feel for how these functions operate.
There are a number of other string functions, but their use is highly specialized. They are as follows:
- stpcpy(): Like strcpy() but returns a pointer to the terminating '�' character of dst.
- strpncpy(): Like man but returns a pointer to the terminating '�' character of dst.
- strchr(): Locates the first occurrence of a character in a string from the left.
- strrchr(): Locates the first occurrence of a character in a string from the right.
- strspn(): Finds the first character in a string that is not in the given character set.
- strcspn(): Finds the first character in a string that is in the given character set.
- strpbrk(): Finds the first occurrence in a string of any character in the given character set.
- strsep(): Finds the first occurrence in the given character set and replaces it with a '�' character.
- strstr(): Finds the first occurrence of a string in another string.
- strcasestr(): Like strstr() but ignores cases of both strings.
- strnstr(): Finds the first occurrence of a string in another string searching no more than N characters.
- strtok(): Isolates tokens in a string. Tokens are separated by any character in the given delimiter character set.
- strtok_r(): Similar to strtok().
Further explanation about the use of these functions is beyond the scope of this book. They are listed for completeness only.
Summary
In this chapter, we explored the elements of strings—characters. In particular, we explored the details of ASCII characters and how they are organized by developing a program in several iterations to print out a complete ASCII table. We also explored some simple operations on characters using the C standard library.
From there, we saw how C strings are special arrays made up of characters and a terminating NUL character. The NUL terminating character is something to which we must pay particular attention to when we create and manipulate strings. We explored how strings and string operations are built on other existing C concepts of arrays and pointers. We explored the difference between string literals, which are constant and modifiable strings. We further saw how to pass both of them to functions. All of these string concepts have been employed in the program we've developed to print the full 7-bit ASCII character set table. Finally, we introduced some basic string functions from the C standard library; these will be further explored in later chapters.
Even though characters and strings are built upon existing C concepts, there is quite a bit to absorb in this chapter. I urge you to work through each of the programs and attempt the experiments on them on your own before proceeding to the following chapters.
One of the most important programming skills demonstrated in this chapter is the process of iterative program development. That is, with a rather complex end result in mind, we started by creating a simple program to produce a small but essential part of the result. In the first iteration, we printed just a single column of characters. Each time we revisited that program, we added more functionality until we achieved our desired end result—we printed more columns. Then, we considered the DEL character. Finally, we took two iterations to print control character symbols and their printf() forms.
With the completion of this chapter, we have covered the essentials of C programming syntax. In subsequent chapters, we will explore thevarious ways that we can use C to solve useful and interesting problems. In each chapter, we will build upon all of the concepts introduced up to this point, as well as introduce the important, yet somewhat abstract, programming concepts that will make our programs robust and reliable.