
Now, we define a class called ADML where we implement the ADML algorithm. In the __init__ method, we will initialize all of the necessary variables. Then, we define our sigmoid function and we define our train function.
We will see this step-by-step and later see the final code as a whole:
class ADML(object):
We define the __init__ method and initialize necessary variables:
def __init__(self):
We initialize a number of tasks—that is, the number of tasks we need in each batch of tasks:
self.num_tasks = 2
We initialize a number of samples—that is, a number of shots—a number of data points (k) we need to have in each task:
self.num_samples = 10
We initialize a number of epochs—that is, training iterations:
self.epochs = 100
The hyperparameter for the inner loop (inner gradient update) is as follows:
#for clean sample
self.alpha1 = 0.0001
#for adversarial sample
self.alpha2 = 0.0001
The hyperparameter for the outer loop (outer gradient update), which is meta optimization, is as follows:
#for clean sample
self.beta1 = 0.0001
#for adversarial sample
self.beta2 = 0.0001
We randomly initialize our model parameter, theta:
self.theta = np.random.normal(size=50).reshape(50, 1)
We define our sigmoid activation function:
def sigmoid(self,a):
return 1.0 / (1 + np.exp(-a))
Now, let's see how to train the network:
def train(self):
For the number of epochs:
for e in range(self.epochs):
#theta' of clean samples
self.theta_clean = []
#theta' of adversarial samples
self.theta_adv = []
For task i in batch of tasks:
for i in range(self.num_tasks):
We sample k data points and prepare our training data. First, we sample the clean data points, that is,  :
:
XTrain_clean, YTrain_clean = sample_points(self.num_samples)
Feed the clean samples to FGSM and get adversarial samples  :
:
XTrain_adv, YTrain_adv = FGSM(XTrain_clean,YTrain_clean)
Now, we compute  and store it in theta_clean. Predict the output y using the single layer network:
and store it in theta_clean. Predict the output y using the single layer network:
a = np.matmul(XTrain_clean, self.theta)
YHat = self.sigmoid(a)
Since we are performing classification, we use cross entropy loss as our loss function:
loss = ((np.matmul(-YTrain_clean.T, np.log(YHat)) - np.matmul((1 -YTrain_clean.T), np.log(1 - YHat)))/self.num_samples)[0][0]
We minimize the loss by calculating the gradients:
gradient = np.matmul(XTrain_clean.T, (YHat - YTrain_clean)) / self.num_samples
We update the gradients and find the optimal parameter for clean samples, :
:
self.theta_clean.append(self.theta - self.alpha1*gradient)
Now, we compute 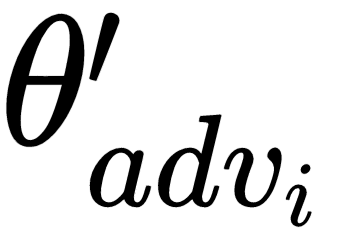 for adversarial samples and store it in theta_adv:
for adversarial samples and store it in theta_adv:
#predict the output y
a = (np.matmul(XTrain_adv, self.theta))
YHat = self.sigmoid(a)
#calculate cross entropy loss
loss = ((np.matmul(-YTrain_adv.T, np.log(YHat)) - np.matmul((1 -YTrain_adv.T), np.log(1 - YHat)))/self.num_samples)[0][0]
#minimize the loss by calculating gradients
gradient = np.matmul(XTrain_adv.T, (YHat - YTrain_adv)) / self.num_samples
We update the gradients and find the optimal parameter for adversarial samples,
 :
:
self.theta_adv.append(self.theta - self.alpha2*gradient)
We initialize meta gradients for clean samples and adversarial samples:
meta_gradient_clean = np.zeros(self.theta.shape)
#initialize meta gradients for adversarial samples
meta_gradient_adv = np.zeros(self.theta.shape)
For i in number of tasks:
for i in range(self.num_tasks):
We sample k data points and prepare our clean and adversarial test sets (meta-train sets) for meta training—that is,  and
and  :
:
#first, we sample clean data points
XTest_clean, YTest_clean = sample_points(self.num_samples)
#feed the clean samples to FGSM and get adversarial samples
XTest_adv, YTest_adv = sample_points(self.num_samples)
First, we compute meta gradients for clean samples:
#predict the value of y
a = np.matmul(XTest_clean, self.theta_clean[i])
YPred = self.sigmoid(a)
#compute meta gradients
meta_gradient_clean += np.matmul(XTest_clean.T, (YPred - YTest_clean)) / self.num_samples
Now, we compute meta gradients for adversarial samples:
#predict the value of y
a = (np.matmul(XTest_adv, self.theta_adv[i]))
YPred = self.sigmoid(a)
#compute meta gradients
meta_gradient_adv += np.matmul(XTest_adv.T, (YPred - YTest_adv)) / self.num_samples
We update our randomly initialized model parameter θ with the meta gradients of both clean and adversarial samples:


self.theta = self.theta-self.beta1*meta_gradient_clean/self.num_tasks
self.theta = self.theta-self.beta2*meta_gradient_adv/self.num_tasks
We print the loss for every 10 epochs:
if e%10==0:
print "Epoch {}: Loss {} ".format(e,loss)
print 'Updated Model Parameter Theta '
print 'Sampling Next Batch of Tasks '
print '--------------------------------- '
The whole code for ADML class is as follows:
class ADML(object):
def __init__(self):
#initialize number of tasks i.e number of tasks we need in each batch of tasks
self.num_tasks = 2
#number of samples i.e number of shots -number of data points (k) we need to have in each task
self.num_samples = 10
#number of epochs i.e training iterations
self.epochs = 100
#hyperparameter for the inner loop (inner gradient update)
#for clean sample
self.alpha1 = 0.0001
#for adversarial sample
self.alpha2 = 0.0001
#hyperparameter for the outer loop (outer gradient update) i.e meta optimization
#for clean sample
self.beta1 = 0.0001
#for adversarial sample
self.beta2 = 0.0001
#randomly initialize our model parameter theta
self.theta = np.random.normal(size=50).reshape(50, 1)
#define our sigmoid activation function
def sigmoid(self,a):
return 1.0 / (1 + np.exp(-a))
#now let's get to the interesting part i.e training
def train(self):
#for the number of epochs,
for e in range(self.epochs):
#theta' of clean samples
self.theta_clean = []
#theta' of adversarial samples
self.theta_adv = []
#for task i in batch of tasks
for i in range(self.num_tasks):
#sample k data points and prepare our training data
#first, we sample clean data points
XTrain_clean, YTrain_clean = sample_points(self.num_samples)
#feed the clean samples to FGSM and get adversarial samples
XTrain_adv, YTrain_adv = FGSM(XTrain_clean,YTrain_clean)
#1. First, we computer theta' for clean samples and store it in theta_clean
#predict the output y
a = np.matmul(XTrain_clean, self.theta)
YHat = self.sigmoid(a)
#since we are performing classification, we use cross entropy loss as our loss function
loss = ((np.matmul(-YTrain_clean.T, np.log(YHat)) - np.matmul((1 -YTrain_clean.T), np.log(1 - YHat)))/self.num_samples)[0][0]
#minimize the loss by calculating gradients
gradient = np.matmul(XTrain_clean.T, (YHat - YTrain_clean)) / self.num_samples
#update the gradients and find the optimal parameter theta' for clean samples
self.theta_clean.append(self.theta - self.alpha1*gradient)
#2. Now, we compute theta' for adversarial samples and store it in theta_clean
#predict the output y
a = (np.matmul(XTrain_adv, self.theta))
YHat = self.sigmoid(a)
#calculate cross entropy loss
loss = ((np.matmul(-YTrain_adv.T, np.log(YHat)) - np.matmul((1 -YTrain_adv.T), np.log(1 - YHat)))/self.num_samples)[0][0]
#minimize the loss by calculating gradients
gradient = np.matmul(XTrain_adv.T, (YHat - YTrain_adv)) / self.num_samples
#update the gradients and find the optimal parameter theta' for adversarial samples
self.theta_adv.append(self.theta - self.alpha2*gradient)
#initialize meta gradients for clean samples
meta_gradient_clean = np.zeros(self.theta.shape)
#initialize meta gradients for adversarial samples
meta_gradient_adv = np.zeros(self.theta.shape)
for i in range(self.num_tasks):
#sample k data points and prepare our test set for meta training
#first, we sample clean data points
XTest_clean, YTest_clean = sample_points(self.num_samples)
#feed the clean samples to FGSM and get adversarial samples
XTest_adv, YTest_adv = sample_points(self.num_samples)
#1. First, we computer meta gradients for clean samples
#predict the value of y
a = np.matmul(XTest_clean, self.theta_clean[i])
YPred = self.sigmoid(a)
#compute meta gradients
meta_gradient_clean += np.matmul(XTest_clean.T, (YPred - YTest_clean)) / self.num_samples
#2. Now, we compute meta gradients for adversarial samples
#predict the value of y
a = (np.matmul(XTest_adv, self.theta_adv[i]))
YPred = self.sigmoid(a)
#compute meta gradients
meta_gradient_adv += np.matmul(XTest_adv.T, (YPred - YTest_adv)) / self.num_samples
#update our randomly initialized model parameter theta
#with the meta gradients of both clean and adversarial samples
self.theta = self.theta-self.beta1*meta_gradient_clean/self.num_tasks
self.theta = self.theta-self.beta2*meta_gradient_adv/self.num_tasks
if e%10==0:
print "Epoch {}: Loss {} ".format(e,loss)
print 'Updated Model Parameter Theta '
print 'Sampling Next Batch of Tasks '
print '--------------------------------- '
We create an instance to our ADML class:
model = ADML()
Then, we start training the model:
model.train()
You can notice how the loss is decreasing over epochs:
Epoch 0: Loss 100.25943711532 Updated Model Parameter Theta Sampling Next Batch of Tasks --------------------------------- Epoch 10: Loss 2.13533264312 Updated Model Parameter Theta Sampling Next Batch of Tasks --------------------------------- Epoch 20: Loss 0.426824910313 Updated Model Parameter Theta Sampling Next Batch of Tasks