
Now we'll see how to use Meta-SGD in reinforcement learning. Meta-SGD is compatible with any RL algorithm that can be trained with gradient descent.
- Let's say we have a model
 parameterized by a parameter
parameterized by a parameter  and we have a distribution over tasks
and we have a distribution over tasks  . First, we randomly initialize the model parameter
. First, we randomly initialize the model parameter  and we randomly initialize
and we randomly initialize  whose shape is the same as
whose shape is the same as  .
. - Sample some batch of tasks
 from a distribution of tasks:
from a distribution of tasks:  . Say, we have sampled three tasks,
. Say, we have sampled three tasks,  .
. - Inner loop: For each task (
 ) in tasks (
) in tasks ( ), we sample
), we sample  trajectories, calculate the loss and minimize the loss using gradient descent and get the optimal parameters
trajectories, calculate the loss and minimize the loss using gradient descent and get the optimal parameters 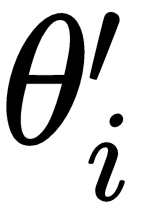 :
: .So for each of the tasks, we sample trajectories, minimize the loss and get the optimal parameters
.So for each of the tasks, we sample trajectories, minimize the loss and get the optimal parameters  . As we sampled three tasks, we'll have three optimal parameters
. As we sampled three tasks, we'll have three optimal parameters  for all of the three tasks. Next, we'll sample another set of trajectories called
for all of the three tasks. Next, we'll sample another set of trajectories called  for meta update.
for meta update. - Outer loop: Now, we perform meta optimization in the trajectory. We minimize the loss by calculating the gradient with respect to our optimal parameter
 obtained in the previous step, update our randomly initialized parameter
obtained in the previous step, update our randomly initialized parameter  and
and  :
:


- We repeat steps 2 to step 4 for n number of iterations.