
The Reptile algorithm has been proposed as an improvement to MAML by OpenAI. It's simple and easier to implement. We know that, in MAML, we calculate second order derivatives—that is, the gradient of gradients. But computationally, this isn't an efficient task. So, OpenAI came up with an improvement over MAML called Reptile. The algorithm of Reptile is very simple. Sample some n number of tasks and run Stochastic Gradient Descent (SGD) for fewer iterations on each of the sampled tasks and then update our model parameter in a direction that's common to all of the tasks. Since we're performing SGD for fewer iterations on each task, it indirectly implies we're calculating the second order derivative over the loss. Unlike MAML, it's computationally effective as we're not calculating the second order derivative directly nor unrolling the computational graph, and so it is easier to implement.
Let's say we sampled two tasks,  and
and  , from the task distribution and we randomly initialize the model parameter
, from the task distribution and we randomly initialize the model parameter  . First, we take task
. First, we take task 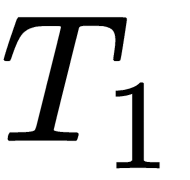 and perform SGD for some n iterations and get the optimal parameter
and perform SGD for some n iterations and get the optimal parameter  . Then we take next task
. Then we take next task  , perform SGD for n iterations and get the optimal parameter
, perform SGD for n iterations and get the optimal parameter  . So, we have two optimal sets of parameters:
. So, we have two optimal sets of parameters:  . Now we need to move our parameter
. Now we need to move our parameter  in a direction that's closer to both of these optimal parameters as shown in the following diagram:
in a direction that's closer to both of these optimal parameters as shown in the following diagram:

But how can we move our randomly initialized model parameter  in a direction closer to the optimal parameter
in a direction closer to the optimal parameter  ? First, we need to find the distance between our randomly initialized model parameter and optimal set of parameters
? First, we need to find the distance between our randomly initialized model parameter and optimal set of parameters  . So we use Euclidean distance
. So we use Euclidean distance  as our distance measure for finding this distance. Once we find the distance between and , we need to minimize them:
as our distance measure for finding this distance. Once we find the distance between and , we need to minimize them:

Minimizing the distance between and essentially moves our randomly initialized model parameter in a direction closer to the optimal parameter . But how can we minimize this distance? We basically compute gradients of the distance  for minimizing and it can be written as follows:
for minimizing and it can be written as follows:

So, after calculating gradients, our final update equation becomes the following:

By updating our model parameter  using the previous equation, we essentially minimize the distance between the initial parameter
using the previous equation, we essentially minimize the distance between the initial parameter  and optimal parameter values
and optimal parameter values  . So, we find the optimal parameter for each task by performing SGD for n number of iterations. Once we get this optimal set of parameters, we update our model parameter
. So, we find the optimal parameter for each task by performing SGD for n number of iterations. Once we get this optimal set of parameters, we update our model parameter  using the previous equation.
using the previous equation.